Redis面试题
Posted 兴趣使然的草帽路飞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis面试题相关的知识,希望对你有一定的参考价值。
- 临近秋招,备战暑期实习,祝大家每天进步亿点点!

1、Redis 怎么保证高可用、有哪些集群模式?
Redis 保证高可用可以通过:主从复制、哨兵模式、集群模式。
① 主从复制
- 将主库 Redis 的数据实时同步给从库 Redis。
② 哨兵
- 哨兵模式是由一个或多个哨兵(Sentinel) 实例组成的 Sentinel 系统可以监视任意多个主服务器,以及这些主服务器属下的所有从服务器。
- Sentinel 可以在被监视的主服务器进入下线状态时,自动将下线主服务器的某个从服务器升级为新的主服务器,然后由新的主服务器代替已下线的主服务器继续处理命令请求。
1)哨兵故障检测
- 检查主观下线状态:
在默认情况下,Sentinel 会以每秒一次的频率向所有与它创建了命令连接的实例(包括主服务器、从服务器、其他 Sentinel 在内)发送 PING 命令,并通过实例返回的 PING 命令回复来判断实例是否在线。
如果一个实例在 down-after-miliseconds 毫秒内,连续向 Sentinel 返回无效回复,那么 Sentinel 会修改这个实例所对应的实例结构,在结构的 flags 属性中设置 SRI_S_DOWN 标识,以此来表示这个实例已经进入主观下线状态。
- 检查客观下线状态:
当 Sentinel 将一个主服务器判断为主观下线之后,为了确定这个主服务器是否真的下线了,它会向同样监视这一服务器的其他 Sentinel 进行询问,看它们是否也认为主服务器已经进入了下线状态(可以是主观下线或者客观下线)。
当 Sentinel 从其他 Sentinel 那里接收到足够数量(quorum,可配置)的已下线判断之后,Sentinel 就会将服务器置为客观下线,在 flags 上打上 SRI_O_DOWN 标识,并对主服务器执行故障转移操作。
2)哨兵故障转移流程:
当哨兵监测到某个主节点客观下线之后,就会开始故障转移流程。核心流程如下:
- 发起一次选举,选举出领头 Sentinel
- 领头 Sentinel 在已下线主服务器的所有从服务器里面,挑选出一个从服务器,并将其升级为新的主服务器。
- 领头 Sentinel 将剩余的所有从服务器改为复制新的主服务器。
- 领头 Sentinel 更新相关配置信息,当这个旧的主服务器重新上线时,将其设置为新的主服务器的从服务器。
③ 集群模式
哨兵模式最大的缺点就是所有的数据都放在一台服务器上,无法较好的进行水平扩展。
为了解决哨兵模式存在的问题,集群模式应运而生。在高可用上,集群基本是直接复用的哨兵模式的逻辑,并且针对水平扩展进行了优化。
2、Redis 事务的实现
一个事务从开始到结束通常会经历以下3个阶段:
1)事务开始:multi 命令将执行该命令的客户端从非事务状态切换至事务状态,底层通过 flags 属性标识。
2)命令入队:当客户端处于事务状态时,服务器会根据客户端发来的命令执行不同的操作:
- exec、discard、watch、multi 命令会被立即执行
- 其他命令不会立即执行,而是将命令放入到一个事务队列,然后向客户端返回 QUEUED 回复。
3)事务执行:当一个处于事务状态的客户端向服务器发送 exec 命令时,服务器会遍历事务队列,执行队列中的所有命令,最后将结果全部返回给客户端。
不过 redis 的事务并不推荐在实际中使用,如果要使用事务,推荐使用 Lua 脚本,redis 会保证一个 Lua 脚本里的所有命令的原子性。
3、Redis 如何实现分布式锁?
① 加锁
加锁通常使用 set 命令来实现,伪代码如下:
set key value PX milliseconds NX
几个参数的意义如下:
key、value:键值对PX milliseconds:设置键的过期时间为 milliseconds 毫秒。NX:只在键不存在时,才对键进行设置操作。SET key value NX效果等同于SETNX key value。- PX、expireTime 参数则是用于解决没有解锁导致的死锁问题。因为如果没有过期时间,万一程序员写的代码有 bug 导致没有解锁操作,则就出现了死锁,因此该参数起到了一个“兜底”的作用。
NX参数用于保证在多个线程并发set下,只会有1个线程成功,起到了锁的“唯一”性。
② 解锁
解锁需要两步操作:
- 查询当前“锁”是否还是我们持有,因为存在过期时间,所以可能等你想解锁的时候,“锁”已经到期,然后被其他线程获取了,所以我们在解锁前需要先判断自己是否还持有“锁”
- 如果“锁”还是我们持有,则执行解锁操作,也就是删除该键值对,并返回成功;否则,直接返回失败。
由于当前 Redis 还没有原子命令直接支持这两步操作,所以当前通常是使用 Lua 脚本来执行解锁操作,Redis 会保证脚本里的内容执行是一个原子操作。
脚本代码如下,逻辑比较简单:
if redis.call("get",KEYS[1]) == ARGV[1]
then
return redis.call("del",KEYS[1])
else
return 0
end
两个参数的意义如下:
KEYS[1]:我们要解锁的 keyARGV[1]:我们加锁时的 value,用于判断当“锁”是否还是我们持有,如果被其他线程持有了,value 就会发生变化。
4、Redis 分布式锁过期了,还没处理完怎么办?
为了防止死锁,我们会给分布式锁加一个过期时间,但是万一这个时间到了,我们业务逻辑还没处理完,怎么办?
首先,我们在设置过期时间时要结合业务场景去考虑,尽量设置一个比较合理的值,就是理论上正常处理的话,在这个过期时间内是一定能处理完毕的。
之后,我们再来考虑对这个问题进行兜底设计。
关于这个问题,目前常见的解决方法有两种:
- 守护线程“续命”:额外起一个线程,定期检查线程是否还持有锁,如果有则延长过期时间。Redisson 里面就实现了这个方案,使用“看门狗”定期检查(每1/3的锁时间检查1次),如果线程还持有锁,则刷新过期时间。
- 超时回滚:当我们解锁时发现锁已经被其他线程获取了,说明此时我们执行的操作已经是“不安全”的了,此时需要进行回滚,并返回失败。
5、缓存穿透
- 访问一个缓存和数据库都不存在的 key(eg:
key = -1),此时请求会直接打到数据库上,并且数据库查不到数据,也没办法写入缓存,所以下一次请求同样会打到数据库上。 - 此时,缓存起不到作用,请求每次都会走到数据库,流量大时数据库可能会被打挂。此时缓存就好像被“穿透”了一样,起不到任何作用
解决方案:
- 接口校验,后端接口增加数据合理性校验,例如商品查询中,商品的ID是正整数,则可以直接对非正整数直接过滤。
- 缓存空值,当访问缓存和DB都没有查询到值时,可以将空值写进缓存,为其设置短点的过期时间,防止同一个 key 被一直攻击。
- 布隆过滤器,使用布隆过滤器存储所有可能访问的 key,不存在的 key 直接被过滤,存在的 key 则再进一步查询缓存和数据库。
6、缓存击穿
- 某一个热点 key,在缓存过期的一瞬间,同时有大量的请求打进来,由于此时缓存过期了,所以请求最终都会走到数据库,造成瞬时数据库请求量大、压力骤增,甚至可能打垮数据库。
解决方案:
- 设置热点数据不过期,或者定时任务定时更新缓存。
- 设置互斥锁,在并发的多个请求中,只有第一个请求线程能拿到锁并执行数据库查询操作,其他的线程拿不到锁就阻塞等着,等到第一个线程将数据写入缓存后,直接走缓存。(可以使用 Redis 分布式锁)
使用 redis 分布式锁的伪代码,仅供参考:
public Object getData(String key) throws InterruptedException {
Object value = redis.get(key);
// 缓存值过期
if (value == null) {
// lockRedis:专门用于加锁的redis;
// "empty":加锁的值随便设置都可以
if (lockRedis.set(key, "empty", "PX", lockExpire, "NX")) {
try {
// 查询数据库,并写到缓存,让其他线程可以直接走缓存
value = getDataFromDb(key);
redis.set(key, value, "PX", expire);
} catch (Exception e) {
// 异常处理
} finally {
// 释放锁
lockRedis.delete(key);
}
} else {
// sleep50ms后,进行重试
Thread.sleep(50);
return getData(key);
}
}
return value;
}
7、缓存雪崩
- 大量的热点 key 设置了相同的过期时间,导在缓存在同一时刻全部失效,造成瞬时数据库请求量大、压力骤增,引起雪崩,甚至导致数据库被打挂。
解决方案:
- **加互斥锁。**该方式和缓存击穿一样,按 key 维度加锁,对于同一个 key,只允许一个线程去计算,其他线程原地阻塞等待第一个线程的计算结果,然后直接走缓存即可。
- 热点数据不过期,该方式和缓存击穿一样。
- 过期时间打散,既然是大量缓存集中失效,那最容易想到就是让他们不集中生效。可以给缓存的过期时间时加上一个随机值时间,使得每个 key 的过期时间分布开来,不会集中在同一时刻失效。
8、布隆过滤器
布隆过滤器的特点是判断不存在的,则一定不存在;判断存在的,大概率存在,但也有小概率不存在。并且这个概率是可控的,我们可以让这个概率变小或者变高,取决于用户本身的需求。
布隆过滤器由一个 bitSet 和 一组 Hash 函数(算法)组成,是一种空间效率极高的概率型算法和数据结构,主要用来判断一个元素是否在集合中存在。
在初始化时,bitSet 的每一位被初始化为0,同时会定义 Hash 函数,例如有3组 Hash 函数:hash1、hash2、hash3。
写入流程
当我们要写入一个值时,过程如下,以“jionghui”为例:
1)首先将“jionghui”跟3组 Hash 函数分别计算,得到 bitSet 的下标为:1、7、10。
2)将 bitSet 的这3个下标标记为1。
假设我们还有另外两个值:java 和 diaosi,按上面的流程跟 3组 Hash 函数分别计算,结果如下:
java:Hash 函数计算 bitSet 下标为:1、7、11
diaosi:Hash 函数计算 bitSet 下标为:4、10、11

查询流程
当我们要查询一个值时,过程如下,同样以“jionghui”为例:
1)首先将“jionghui”跟3组 Hash 函数分别计算,得到 bitSet 的下标为:1、7、10。
2)查看 bitSet 的这3个下标是否都为1,如果这3个下标不都为1,则说明该值必然不存在,如果这3个下标都为1,则只能说明可能存在,并不能说明一定存在。
其实上图的例子已经说明了这个问题了,当我们只有值“jionghui”和“diaosi”时,bitSet 下标为1的有:1、4、7、10、11。
当我们又加入值“java”时,bitSet 下标为1的还是这5个,所以当 bitSet 下标为1的为:1、4、7、10、11 时,我们无法判断值“java”存不存在。
其根本原因是,不同的值在跟 Hash 函数计算后,可能会得到相同的下标,所以某个值的标记位,可能会被其他值给标上了。
这也是为啥布隆过滤器只能判断某个值可能存在,无法判断必然存在的原因。但是反过来,如果该值根据 Hash 函数计算的标记位没有全部都为1,那么则说明必然不存在,这个是肯定的。
降低这种误判率的思路也比较简单:
- 一个是加大 bitSet 的长度,这样不同的值出现“冲突”的概率就降低了,从而误判率也降低。
- 提升 Hash 函数的个数,Hash 函数越多,每个值对应的 bit 越多,从而误判率也降低。
布隆过滤器的误判率还有专门的推导公式,有兴趣的可以去搜相关的文章和论文查看。
9、如何保证数据库和缓存的数据一致性
由于数据库和缓存是两个不同的数据源,要保证其数据一致性,其实就是典型的分布式事务场景,可以引入分布式事务来解决,常见的有:2PC、TCC、MQ事务消息等。
但是引入分布式事务必然会带来性能上的影响,这与我们当初引入缓存来提升性能的目的是相违背的。
所以在实际使用中,通常不会去保证缓存和数据库的强一致性,而是做出一定的牺牲,保证两者数据的最终一致性。
如果是实在无法接受脏数据的场景,则比较合理的方式是放弃使用缓存,直接走数据库。
保证数据库和缓存数据最终一致性的常用方案如下:
1)更新数据库,数据库产生 binlog。
2)监听和消费 binlog,执行失效缓存操作。
3)如果步骤2失效缓存失败,则引入重试机制,将失败的数据通过MQ方式进行重试,同时考虑是否需要引入幂等机制。
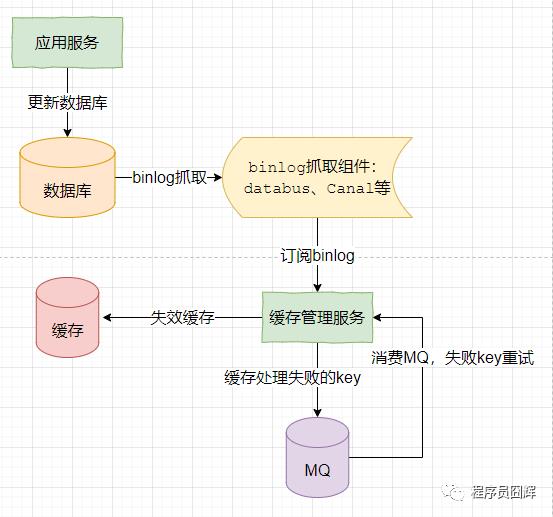
兜底:当出现未知的问题时,及时告警通知,人为介入处理。
人为介入是终极大法,那些外表看着光鲜艳丽的应用,其背后大多有一群苦逼的程序员,在不断的修复各种脏数据和bug。
10、为什么是让缓存失效,而不是更新缓存
1)更新缓存
案例如下,有两个并发的写请求,流程如下:

分析:数据库中的数据是请求B的,缓存中的数据是请求A的,数据库和缓存存在数据不一致。
2)失效(删除)缓存
案例如下,有两个并发的写请求,流程如下:
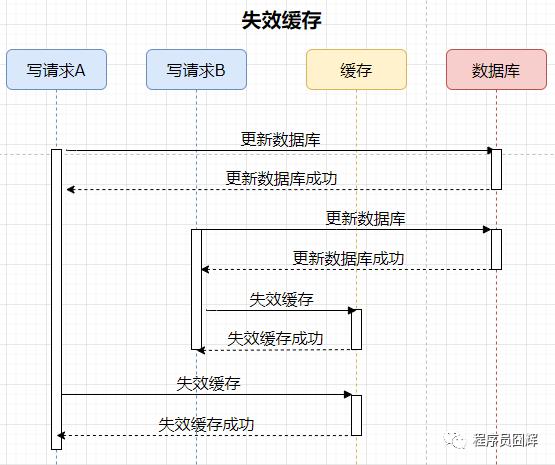
分析:由于是删除缓存,所以不存在数据不一致的情况。
结论:通过上述案例,可以很明显的看出,失效缓存是更优的方式。
总结的面试题也挺费时间的,文章会不定时更新,有时候一天多更新几篇,如果帮助您复习巩固了知识点,还请三连支持一下,后续会亿点点的更新!

为了帮助更多小白从零进阶 Java 工程师,从CSDN官方那边搞来了一套 《Java 工程师学习成长知识图谱》,尺寸 870mm x 560mm,展开后有一张办公桌大小,也可以折叠成一本书的尺寸,有兴趣的小伙伴可以了解一下,当然,不管怎样博主的文章一直都是免费的~

以上是关于Redis面试题的主要内容,如果未能解决你的问题,请参考以下文章