[新星计划]十年项目经验面试官亲传大数据面试__大数据面试独孤九剑
Posted ChinaManor
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[新星计划]十年项目经验面试官亲传大数据面试__大数据面试独孤九剑相关的知识,希望对你有一定的参考价值。
文章目录
引言
大家好,我是ChinaManor,直译过来就是中国码农的意思,俺希望自己能成为国家复兴道路的铺路人,大数据领域的耕耘者,平凡但不甘于平庸的人。
在萌新准备出去面试之前,需要针对每个大数据项目,
需整理一套属于自己基础知识,必须熟记于心,招式烂熟于心,方能无剑胜有剑!
(敲黑板) 面经源于真实10年开发经验的讲师所授,笔者只是将其写成了博客

=== 下面以某智慧物流大数据平台项目为例: ===
第一剑「总决式」功能概述(三句话左右概况,简明扼要)
本项目涉及的业务数据包括订单、运输、仓储、搬运装卸等物流环节中涉及的数据、信息。由于多年的积累、庞大的用户群,每日的订单数上千万,传统的数据处理技术已无法满足企业需求。因此通过大数据分析可以提高运输配送效率、减少物流成本,更有效地满足客户服务要求,并对数据结果分析,提出具有中观指导意义的解决方案。
第二剑「破剑式」、项目周期(开发时长和人员配置)
开发时长:
六个月左右
阶段划分
需求调研、评审(4周)
设计架构(1周)
编码、集成(12周)
测试(2周)
上线部署,试运行,调优(3周)
人员配置
开发人员: 6人
职责划分:
前端(JavaWeb+前端 2人)
大数据开发(3人)
运维(1人)

第三剑「破刀式」、技术架构(技术选项及框架版本)
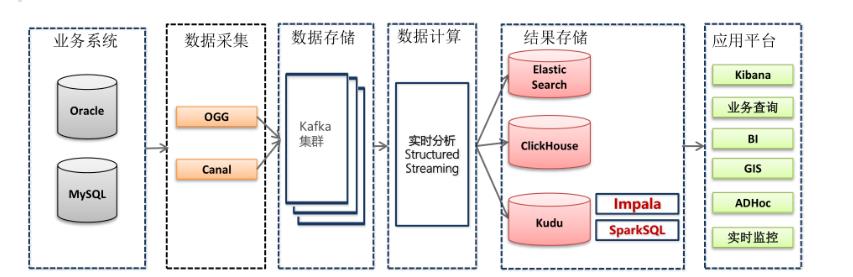
- 业务系统数据主要存放到Oracle和mysql数据库中,比如CRM系统数据在MySQL,OMS系统数据存放在Oracle中;
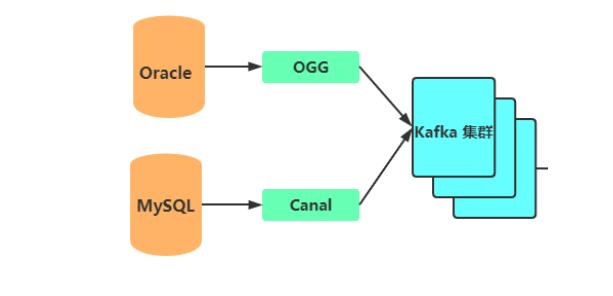
- OGG增量同步Oracle数据库的数据,Canal增量同步MySQL数据库的数据;
- OGG及Canal增量抽取的数据会写入到Kafka集群,供实时分析计算程序消费;
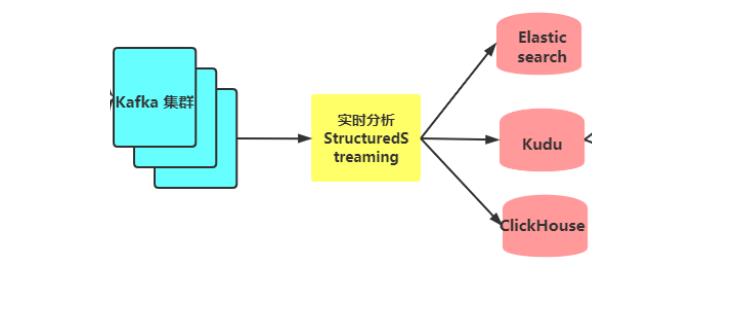
实时分析 - 实时分析计算程序消费kafka的数据,将消费出来的数据进行ETL操作;
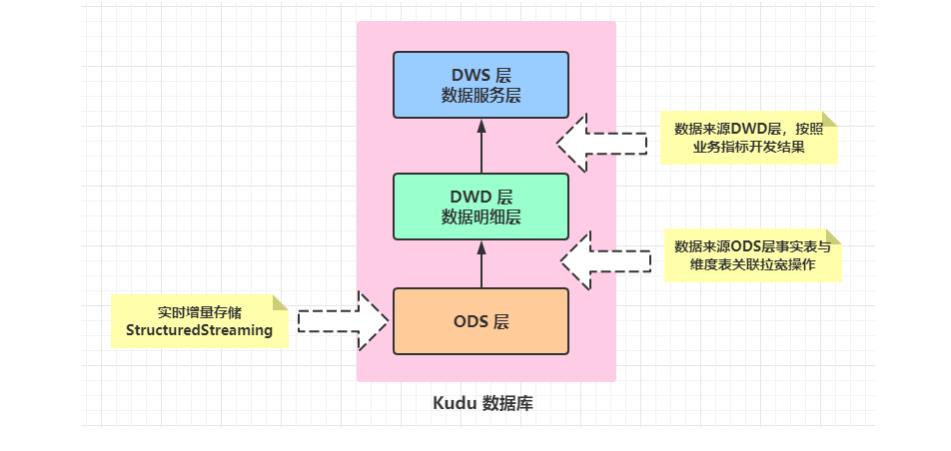
- 为了方便业务部门对各类单据的查询,StructuredStreaming流式处理系统将数据经过ETL处理后,将数据写入到Elasticsearch索引中;
- StructuredStreaming流处理会将数据写入到ClickHouse,Java Web后端直接将数据查询出来进行展示,例如:将运输车辆的GPS位置数据实时展示到GIS地图;
- StructuredStreaming将实时ETL处理后的数据同步更新到Kudu中,方便进行数据的准实时分析、查询,Impala对Kudu数据进行即席分析查询;
- 前端应用对数据进行可视化展示,比如数据服务接口或大屏实时刷新;

第四剑「破枪式」、集群规模(业务数据量及服务器配置和数量)
此处数据量,需参考实际需要酌情考虑
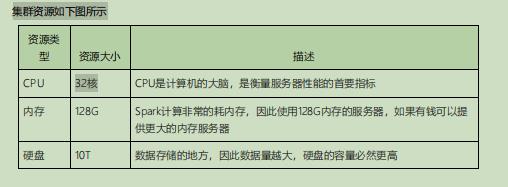
如何确认集群规模?(假设:每台服务器8T磁盘,128G内存)
每天日活跃用户100万,每人一天平均100条:100万*100条=10000万条(1亿)
每条日志1K左右,每天1亿条:100000000/1024/1024=约100G
半年内不扩容服务器来算:100G*180天=约18T
保存3副本:18T3=54T
预留20%-30%Buf=54T/0.7=77T
因此:约8T10台服务器
如果考虑数仓分层?
服务器将近在扩容1-2倍
服务器使用物理机还是云主机?
机器成本考虑:
物理机:以128G内存,20核物理CPU,40线程,8THDD和2TSSD硬盘,单台报价4W出头,需考虑托管服务器费用。一般物理机寿命5年左右
云主机,以阿里云为例,差不多相同配置,每年5W
运维成本考虑:
物理机:需要有专业的运维人员
云主机:很多运维工作都由阿里云已经完成,运维相对较轻松

第五剑「破鞭式」、数据来源及数据采集
第六剑「破索式」、数据ETL(可能离线、可能实时)
第七剑「破掌式」、业务报表分析(离线报表、实时报表)
- 第一点:传统报表分析,各个主题报表
- 数据倾斜、大表与大表关联、OOM内存溢出等等
- 第二点:Impala 即席查询,SQL语句
- 第三点:ClickHouse 实时OLAP分析
第八剑「破箭式」、数据分析引擎(Hive、Impala、Es、Spark、Flink等)
- Hive:底层MapReduce框架,“稳”
- SparkSQL:集成Hive或集成Kudu,分析数据,当然也是用StructuredStreaming
- Impala、ClickHouse:实时OLAP分析框架

第九剑「破气式」、项目问题(数据倾斜、OOM或性能优化等)
- 抛出问题,如何解决(自己解决)
- 常见性能优化,背下来:Hive性能优化、Spark性能优化(原理性东西)
例:如何避免Spark数据倾斜?
避免Spark数据倾斜,一般是要选用合适的 key,或者自己定义相关的 partitioner,通 过加盐或者哈希值来拆分这些 key,从而将这些数据分散到不同的 partition 去执 行。如下算子会导致 shuffle 操作,是导致数据倾斜可能发生的关键点所在: groupByKey;reduceByKey;aggregaByKey;join;cogroup;
总结
以上便是十年项目经验面试官亲传大数据面试独孤九剑~
愿你读过之后有自己的收获,如果有收获不妨一键三连一下~

以上是关于[新星计划]十年项目经验面试官亲传大数据面试__大数据面试独孤九剑的主要内容,如果未能解决你的问题,请参考以下文章
大数据必知必会系列__面试官问能不能徒手画一下你们的项目架构[新星计划]
大数据必知必会系列__面试官问能不能徒手画一下你们的项目架构[新星计划]
大数据必知必会系列——面试官一问就懵:你们做过的项目技术是如何选型的?[新星计划]