JVM day05 类加载阶段类加载器运行期优化
Posted halulu.me
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JVM day05 类加载阶段类加载器运行期优化相关的知识,希望对你有一定的参考价值。
类加载阶段
类的完整生命周期包括7个部分:加载——验证——准备——解析——初始化——使用——卸载
1、加载
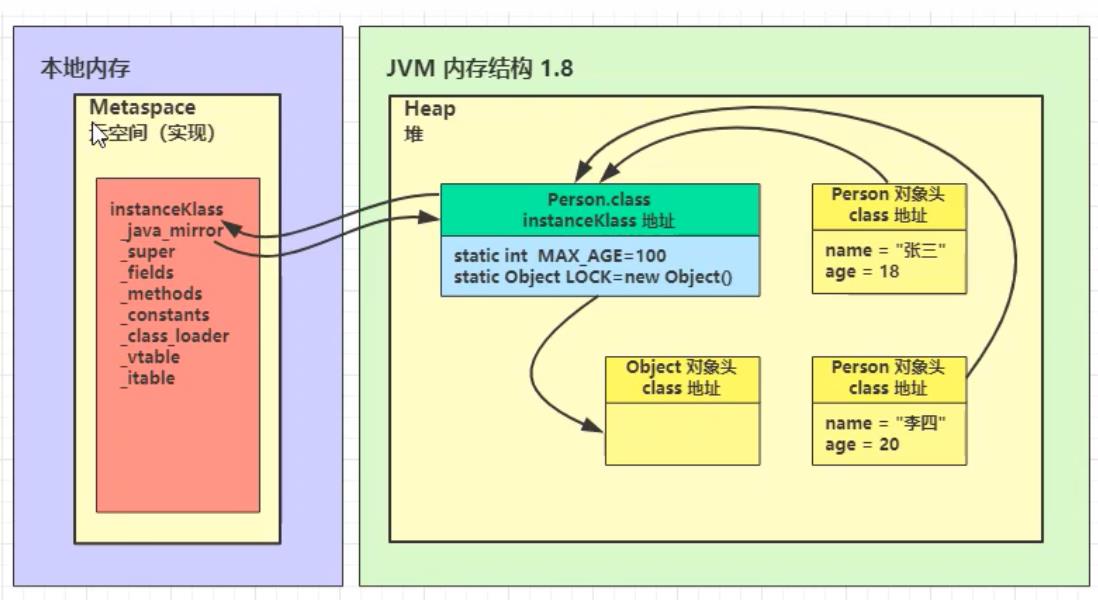
将类的字节码载入方法区中,内部采用 C++ 的
instanceKlass描述 java 类,它的重要 field 有:
1、_java_mirror 即 java 的类镜像,例如对 String 来说,就是 String.class,作用是把klass暴露给 java 使用 (String.class实际上是mirror镜像,通过String.class可以访问到instanceKlass)
2、_super 即父类
3、_fields 即成员变量
4、_methods 即方法
5、_constants 即常量池
6、_class_loader 即类加载器
7、_vtable 虚方法表
8、_itable 接口方法表
如果这个类还有父类没有加载,先加载父类
加载和链接可能是交替运行的
注意:
instanceKlass 这样的【元数据】是存储在方法区(1.8 后的元空间内),但 _java_mirror(Person.class)是存储在堆中
反射getMethods和getFileds实际上通过方法区获取的
2、链接
加载和链接可能是交替运行的
分为3个步骤:验证、准备、解析
验证: 验证类的字节码是否符合JVM的规范,安全性检查。
准备: 为static变量分配空间,设置默认值。
static跟着类对象 _java_mirror(Person.class)存储在堆中
static 变量分配空间和赋值是两个步骤
分配空间在准备阶段完成,
赋值在初始化阶段完成,在<cinit>方法中。
特例:
如果 static 变量是 final 的
基本类型,以及字符串常量,那么编译阶段值就确定了,赋值在准备阶段完成
如果 static 变量是 final 的,但属于引用类型,那么赋值也会在初始化阶段完成解析 将常量池中的符号引用解析为直接引用(类初始化完成才能执行代码)
解析: 将常量池中的符号引用解析为直接引用
(在解析之前类仅仅只是作为符号,没有引用地址)
Demo.class.getClassLoader().loadClass(“cn.halulu.test.C”)
( loadClass 方法不会导致类的解析和初始化)
此时,并没有地址信息

new C 会带值类C的加载、解析以及初始化。
此时,有引用地址信息。

3、初始化
初始化即调用 ()V ,虚拟机会保证这个类的『构造方法』的线程安全
在这个阶段,会为类的静态变量赋予正确的初始值。
类的初始化执行一次,与实例化不同的时实例化可以执行多次
发生的时机:
类初始化是【懒惰的】
1、main 方法所在的类,总会被首先初始化
2、首次访问这个类的静态变量或静态方法时
3、子类初始化,如果父类还没初始化,会引发
4、子类访问父类的静态变量,只会触发父类的初始化
5、Class.forName
6、new会导致初始化
不会导致类初始化的情况
1、访问类的 static final 静态常量(基本类型和字符串)不会触发初始化
2、类对象.class不会触发初始化(类加载时的mirror镜像)
3、创建该类的数组不会触发初始化 (new Object[0])
4、类加载器的loadClass方法
5、Class.forName的参数2为false时
案例:懒惰单例模式
本质: 运用到类初始化惰性的特点,只有在使用的时候才会被初始化。
虚拟机会保证初始化的线程安全。
public final class Singleton {
private Singleton() {
} // 内部类中保存单例
private static class LazyHolder {
static final Singleton INSTANCE = new Singleton();
}// 第一次调用 getInstance 方法,才会导致内部类加载和初始化其静态成员
public static Singleton getInstance() {
return LazyHolder.INSTANCE;
}
}
4、使用
比如类的实例化(用类创建对象),调用类的一些方法
5、卸载
class文件从内存中被销毁掉,就称为卸载,一旦类被卸载,我们就不能使用类创建对象了。
类加载器
1、类加载器是有层级关系的。Bootstrap ClassLoader 启动类加载器、Extension ClassLoader扩展类加载器、Application ClassLoader 应用程序类加载器、自定义类加载器。
2、不同层级的类加载器各司其职,每个类加载器有各自负责的区域。
3、getClassLoader()可以获取类加载器
4、null 代表启动类加载器
5、AppClassLoader 代表应用类加载器
6、ExtClassLoader 代表扩展类加载器

双亲委派模式
双亲委派就是指调用类加载器的loadClass方法时,查找类的规则。就是委托上级优先做类的加载,上级没有,再由本级的类加载器进行加载。
比如:当应用程序类加载器要加载这个类的时候,会向上级Extension ClassLoader扩展类加载器询问是否同意,扩展类加载器如果已经在类路径下找到同名的类,应用程序加载器就无法加载该类。
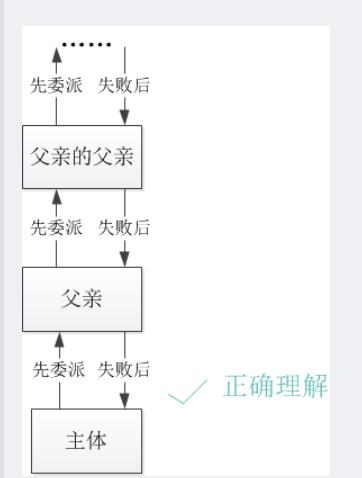
双亲委派的优势
1、避免类被重复加载
2、避免核心类被篡改,比如,我们并不能写一个类叫做java.lang.System以及其他核心类。(由于双亲委派模式,System类是有启动类加载器加载的,自己写的类并没有机会得到加载)
3、但是,我们可以自己定义一个类加载器来达到这个目的,为了避免双亲委托机制,这个类加载器也必须是特殊的。由于系统自带的三个类加载器都加载特定目录下的类,如果我们自己的类加载器放在一个特殊的目录,那么系统的加载器就无法加载,也就是最终还是由我们自己的加载器加载。
线程上下文类加载器
java.sql.DriverManager的在加载mysql驱动的时候打破了双亲委派模式。
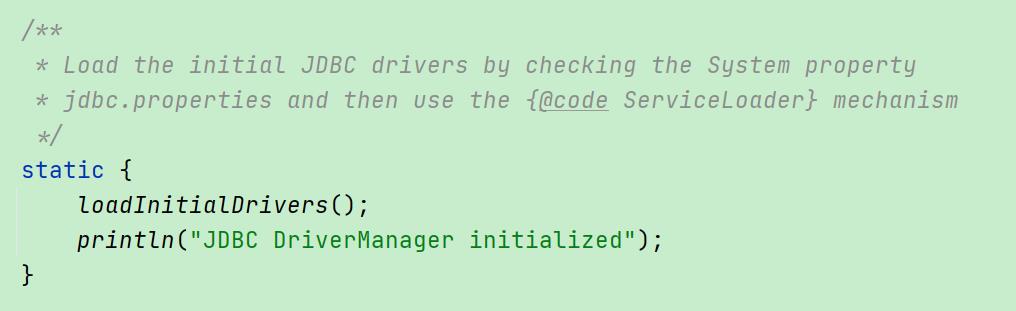
java.sql.DriverManager初始化使用的是启动类加载器,但是启动类加载器目录下并没有mysql_connector的jar包,也就是启动类加载器并不能加载到com.mysql.jdbc.Driver这个类。那么,如何才能够让DriverManager的静态代码块正确加载com.mysql.jdbc.Driver这个类?
方法1、使用Class.forName(aDriver, true, ClassLoader.getSystemClassLoader())来关联应用程序类加载器。ClassLoader.getSystemClassLoader() 使用的就是应用程序类加载器,DriverManager就是通过这样的方法来打破双亲委派模式。
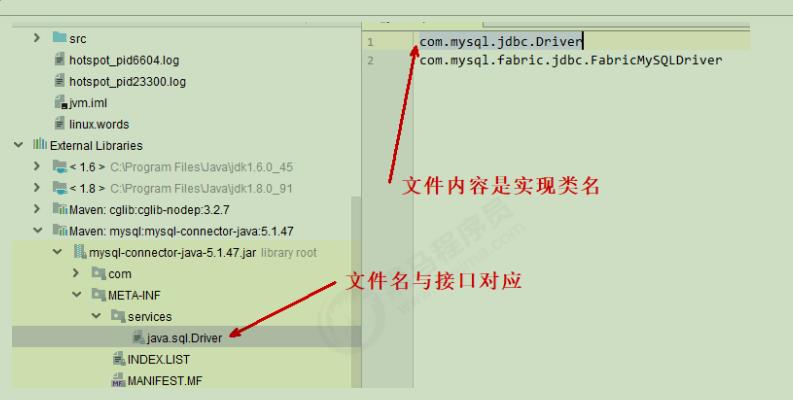
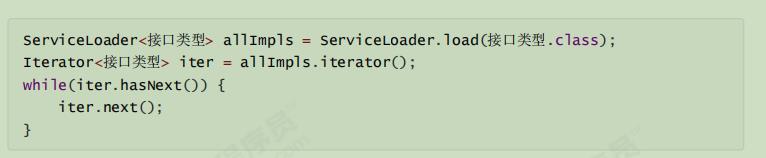
方法2、 Service Provider Interface (SPI)
1、在 jar 包的 META-INF/services 包下,以接口全限定名名为文件,文件内容是实现类名称
2、根据ServiceLoader的load()方法找到文件中的实现类
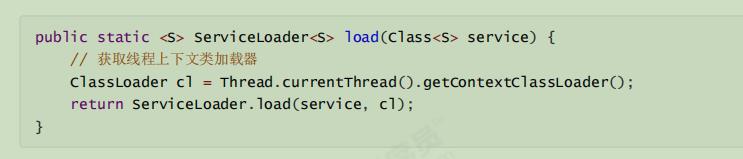
3、ServiceLoader的load()方法就是调用Thread.currentThread().getContextLoader(()获取线程上下文类加载器,即应用程序类加载器。
4、线程上下类加载器就在每个线程启动的时候,JVM默认把应用程序类加载器赋给当前线程。它内部又是通过class.forName()指定类加载器的方法来获取启动类加载器。
自定义类加载器

准备好两个class文件放入 E:\\myclasspath
public class Load7 {
public static void main(String[] args) throws Exception {
MyClassLoader classLoader = new MyClassLoader();
Class<?> c1 = classLoader.loadClass("MapImpl1");
Class<?> c2 = classLoader.loadClass("MapImpl1");
System.out.println(c1 == c2);
MyClassLoader classLoader2 = new MyClassLoader();
Class<?> c3 = classLoader2.loadClass("MapImpl1");
System.out.println(c1 == c3);
c1.newInstance();
}
}
class MyClassLoader extends ClassLoader {
@Override // name 就是类名称
protected Class<?> findClass(String name) throws ClassNotFoundException {
String path = "e:\\\\myclasspath\\\\" + name + ".class";
try {
ByteArrayOutputStream os = new ByteArrayOutputStream();
Files.copy(Paths.get(path), os);
// 得到字节数组
byte[] bytes = os.toByteArray();
// byte[] -> *.class
return defineClass(name, bytes, 0, bytes.length);
} catch (IOException e) {
e.printStackTrace();
throw new ClassNotFoundException("类文件未找到", e);
}
}
}
运行期优化
即时编译
1、分层编译
JVM 将执行状态分成了 5 个层次:
0 层,解释执行(Interpreter) (字节码解释成机器吗)
1 层,使用 C1 即时编译器编译执行(不带 profiling)(当字节码方法使用的时候会升级)
2 层,使用 C1即时编译器编译执行(带基本的 profiling)
3 层,使用 C1 即时编译器编译执行(带完全的 profiling)
4 层,使用 C2 即时编译器编译执行
profiling 是指在运行过程中收集一些程序执行状态的数据,例如【方法的调用次数】,【循环的回边次数】等
即时编译器(JIT)(Just In Time)与解释器的区别
1、解释器是将字节码解释为机器码,下次即使遇到相同的字节码,仍会执行重复的解释
2、JIT 是将一些字节码编译为机器码,并存入 CodeCache,下次遇到相同的代码,直接执行,无需再编译
3、解释器是将字节码解释为针对所有平台都通用的机器码
4、JIT会根据平台类型,生成平台特定的机器码
对于占据大部分的不常用的代码,我们无需耗费时间将其编译成机器码,而是采取解释执行(解释器)的方式运行;另一方面,对于仅占据小部分的热点代码,我们则可以将其编译成(即时编译器)机器码,以达到理想的运行速度。
Interpreter < C1 < C2,总的目标是发现热点代码(hotspot名称的由来)。
逃逸分析:
【逃逸分析】:Java的逃逸分析只发在JIT的即时编译器中,目的就是分析对象是否会被其他方法引用,如果一直不被引用,那么就把该对象当成不会逃逸处理。
基于逃逸分析的优化:(节省堆内存空间)
当判断出对象不发生逃逸时所进行的优化:
1、 栈上分配 :将变量类的实例化内存直接在栈里分配(无需进入堆),分配完成后,继续在调用栈内执行,最后线程结束,栈空间被回收,局部变量对象也被回收。对比可以看出,主要区别在栈空间直接作为临时对象的存储介质。从而减少了临时对象在堆内的分配数量。
2、同步消除:在即使编译器时,如果发现不可能被共享的对象,则可以消除这些对象的锁操作
3、标量替换:Java虚拟机中的原始数据类型(int,long等数值类型以及reference类型等)都不能再进一步分解,它们就可以称为标量。相对的,如果一个数据可以继续分解,那它称为聚合量,Java中最典型的聚合量是对象。如果逃逸分析证明一个对象不会被外部访问,并且这个对象是可分解的,那程序真正执行的时候将可能不创建这个对象,而改为直接创建它的若干个被这个方法使用到的成员变量来代替。拆散后的变量便可以被单独分析与优化,可以各自分别在栈帧或寄存器上分配空间,原本的对象就无需整体分配空间了。
4、可以使用 -XX:-DoEscapeAnalysis 关闭逃逸分析。
2、方法内联(Inlining):(节省方法栈的内存)
当调用函数的时候,如果函数的长度不太长并且是热点方法的时候,就会进行方法内联。所谓的内联即使把方法内代码拷贝、粘贴到调用者的位置。如果方法内的代码是常量的话,还能够进行常量折叠(constant folding)的优化。
减少了调用方法栈的内耗
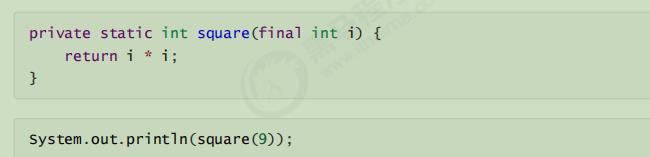
方法内联会变为:

3、字段优化
字段优化主要是针对成员变量和静态成员变量的读写操作。(放在缓存中,减少fields的读写操作)
1、即时编译器将 沿着控制流 ,缓存各个字段 存储节点 将要存储的值,或者字段 读取节点 所得到的值
2、当即时编译器 遇到对同一字段的读取节点时,如果缓存值还没有失效,那么将读取节点 替换 为该缓存值
3、当即时编译器 遇到对同一字段的存储节点 时,会 更新 所缓存的值
反射优化
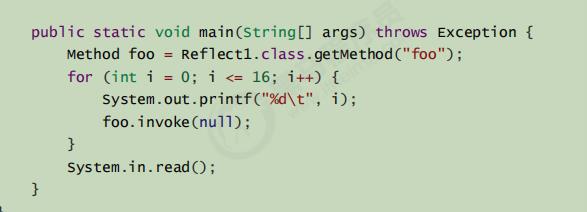
反射的invoke()方法初次调用的是MethodAccessor的NativeMethodAccessorImpl本地方法访问器,本地方法的性能一般是比较低的,但当调用次数超过膨胀阈(yu)值(默认值是15)的时候,会采用运行时生成的类GeneratedMethodAccessor1代替掉原本的本地方法访问器,性能也会因此提升。(实际上就是将反射方法调用转换成正成的方法调用)
可以通过sun.reflecti.inflationThreshold修改膨胀阈值
超过阈值会变成

以上是关于JVM day05 类加载阶段类加载器运行期优化的主要内容,如果未能解决你的问题,请参考以下文章