揭秘视频千倍压缩背后的技术原理之预测技术
Posted LiveVideoStack_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了揭秘视频千倍压缩背后的技术原理之预测技术相关的知识,希望对你有一定的参考价值。

正文字数:3312 阅读时长:4分钟
随着5G的成熟和广泛商用,带宽已经越来越高,传输视频变得更加容易。设备特别是移动设备算力的提升、存储容量的提升,使得视频技术的应用越来越广泛,无论是流媒体、泛娱乐、实时通信,视频都带给了用户更加丰富的体验。
文 / 拍乐云Pano
视频相关的技术,特别是视频压缩,因其专业性,深入开发的门槛较高。具体到视频实时通信场景,视频压缩技术面临更严峻的挑战,因为实时通信场景下,对时延要求非常高,对设备适配的要求也非常高,对带宽适应的要求也非常高,开发一款满足实时通信要求的编解码器,难度也很高。之前的文章中,我们已经在《深入浅出理解视频编解码技术》一文中简要介绍了视频编解码基本框架,今天我们将深入剖析其中的预测模块,便于大家更好地理解视频编解码技术。
01
颜色空间
开始进入主题之前,先简单看一下视频是如何在计算机中进行表达的。视频是由一系列图片按照时间顺序排列而成,每一张图片为一帧。每一帧可以理解为一个二维矩阵,矩阵的每个元素为一个像素。一个像素通常由三个颜色进行表达,例如用RGB颜色空间表示时,每一个像素由三个颜色分量组成。每一个颜色分量用1个字节来表达,其取值范围就是0~255。编码中常用的YUV格式与之类似,这里不作展开。
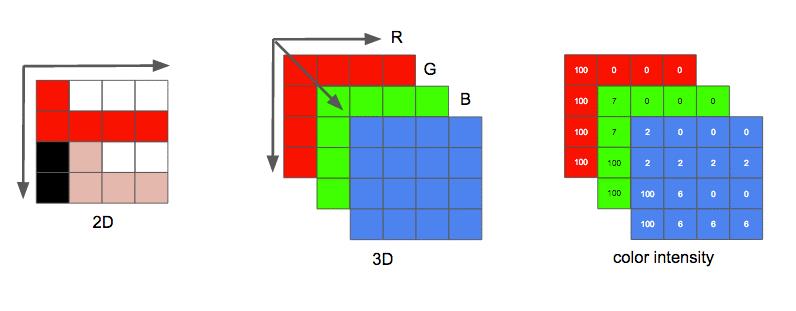
图片 From Leandro Moreira
以1280x720@60fps的视频序列为例,十秒钟的视频有1280*720*3*60*10 = 1.6GB,如此大量的数据,无论是存储还是传输,都面临巨大的挑战。视频压缩或者编码的目的,也是为了保证视频质量的前提下,将视频减小,以利于传输和存储。同时,为了能正确还原视频,需要将其解码。
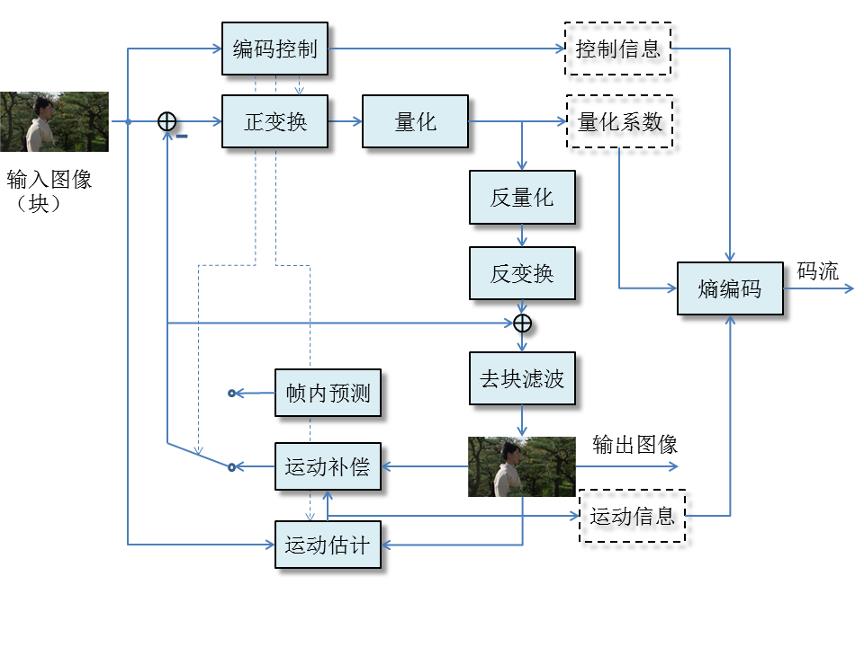
从最早的H.261开始,视频编解码的框架都采用了这一结构,如图所示。主要的模块分为帧内/帧间预测、(反)变换、(反)量化、熵编码、环内滤波。一帧视频数据,首先被分割成一系列的方块,按照从左到右从上到下的方式,逐个进行处理,最后得到码流。
02
帧内预测
视频数据被划分成方块之后,相邻的方块的像素,以及方块内的像素,颜色往往是逐渐变化的,他们之间有比较强的有相似性。这种相似性,就是空间冗余。既然存在冗余,就可以用更少的数据量来表达这样的特征。比如,先传输第一个像素的值,再传输第二个像素相对于第一个像素的变化值,这个变化值往往取值范围变小了许多,原来要8个bit来表达的像素值,可能只需要少于8个bit就足够了。同样的道理,以像素块为基本单位,也可以进行类似的“差分”操作。我们从示例图中,来更加直观地感受一下这样的相似性。

如图中所标出的两个8x8的块,其亮度分量(Y)沿着“左上到右下”的方向,具有连续性,变化不大。假如我们设计某种特定的“模式”,使其利用左边的块来“预测”右边的块,那么“原始像素”减去“预测像素”就可以减少传输所需要的数据量,同时将该“模式”写入最终的码流,解码器便可以利用左侧的块来“重建”右侧的块。极端一点讲,假如左侧的块的像素值经过一定的运算可以完全和右侧的块相同,那么编码器只要用一个“模式”的代价,传输右侧的块。
当然,视频中的纹理多种多样,单一的模式很难对所有的纹理都适用,因此标准中也设计了多种多样的帧内预测模式,以充分利用像素间的相关性,达到压缩的目的。例如下图所示的H.264中9种帧内预测方向。以模式0(竖直预测)为例,上方块的每个像素值(重建)各复制一列,得到帧内预测值。其它各种模式也采用类似的方法,不过,生成预测值的方式稍有不同。
有这么多的模式,就产生了一个问题,对于一个块而言,我们应该采用哪种模式来进行编码呢?最佳的选择方式,就是遍历所有的模式进行尝试,计算其编码的所需的比特数和产生的质量损失,即率失真优化,这样明显非常复杂,因而也有很多种其它的方式来推断哪种模式更好,例如基于SATD或者边缘检测等。
从H.264的9种预测模式,到AV1的56种帧内方向预测模式,越来越多的模式也是为了更加精准地预测未编码的块,但是模式的增加,一方面增加了传输模式的码率开销,另一方面,从如此重多的模式中选一个最优的模式来编码,使其能达到更高的压缩比,这对编码器的设计和实现也提出了更高的要求。
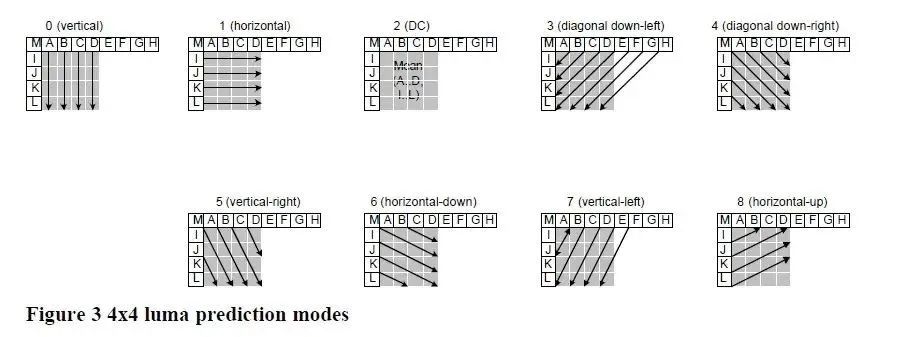
图片 From Vcodex
03
帧间预测
以下5张图片是一段视频的前5帧,可以看出,图片中只有Mario和砖块在运动,其余的场景大多是相似的,这种相似性就称之为时间冗余。编码的时候,我们先将第一帧图片通过前文所述的帧内预测方式进行编码传输,再将后续帧的Mario、砖块的运动方向进行传输,解码的时候,就可以将运动信息和第一帧一起来合成后续的帧,这样就大大减少了传输所需的bit数。这种利用时间冗余来进行压缩的技术,就是运动补偿技术。该技术早在H.261标准中,就已经被采用。





细心地读者可能已经发现,Mario和砖块这样的物体怎么描述,才能让它仅凭运动信息就能完整地呈现出来?其实视频编码中并不需要知道运动的物体的形状,而是将整帧图像划分成像素块,每个像素块使用一个运动信息。即基于块的运动补偿。下图中红色圈出的白色箭头即编码砖块和Mario时的运动信息,它们都指向了前一帧中所在的位置。Mario和砖块都有两个箭头,说明它们都被划分在了两个块中,每一个块都有单独的运动信息。这些运动信息就是运动矢量。运动矢量有水平和竖直两个分量,代表是的一个块相对于其参考帧的位置变化。参考帧就是已经编码过的某一(多)个帧。

当然,传输运动矢量本身就要占用很多 bit,为了提高运动矢量的传输效率,一方面,可以尽可能得将块划分变大,共用一个运动矢量,因为平坦区域或者较大的物体,他们的运动可能是比较一致的,从 H.264 开始,可变块大小的运动补偿技术被广泛采用;另一方面,相邻的块之间的运动往往也有比较高的相似性,其运动矢量也有较高的相似性,运动矢量本身也可以根据相邻的块运动矢量来进行预测,即运动矢量预测技术;最后,运动矢量在表达物体运动的时候,有精度的取舍。
像素是离散化的表达,现实中物体的运动显然不是以像素为单位进行运动的,为了精确地表达物体的运动,需要选择合适的精度来定义运动矢量。各视频编解码标准都定义了运动矢量的精度,运动矢量精度越高,越能精确地表达运动,但是代价就是传输运动矢量需要花费更多的bit。H.261中运动矢量是以整像素为精度的,H.264中运动矢量是以四分之一像素为精度的,AV1中还增加了八分之一精度。一般情况,时间上越近的帧,它们之间的相似性越高,也有例外,例如往复运动的场景等,可能相隔几帧,甚至更远的帧,会有更高的相似度。为了充分利用已经编码过的帧来提高运动补偿的准确度,从H.264开始引入了多参考帧技术,即,一个块可以从已经编码过的很多个参考帧中进行运动匹配,将匹配的帧索引和运动矢量信息都进行传输。
那么如何得到一个块的运动信息呢?最朴素的想法就是,将一个块,在其参考帧中,逐个位置进行匹配检查,匹配度最高的,就是最终的运动矢量。匹配度,常用的有SAD(Sum of Absolute Difference)、SSD(Sum of Squared Difference)等。逐个位置进行匹配度检查,即常说的全搜索运动估计,其计算复杂度可想而知是非常高的。为了加快运动估计,我们可以减少搜索的位置数,类似的有很多算法,常用的如钻石搜索、六边形搜索、非对称十字型多层次六边形格点搜索算法等。
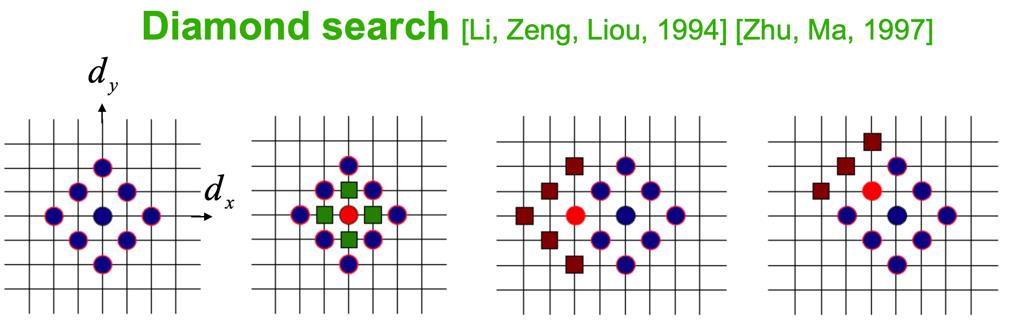
以钻石搜索为例,如图所示,以起始的蓝色点为中心的9个匹配位置,分别计算这9个位置的SAD,如果SAD最小的是中心位置,下一步搜索中心点更近的周围4个绿色点的SAD,选择其中SAD最小的位置,继续缩小范围进行搜索;如果第一步中SAD最小的点不在中心,那么以该位置为中心,增加褐色的5或者3个点,继续计算SAD,如此迭代,直到找到最佳匹配位置。
编码器在实现时,可根据实际的应用场景,对搜索算法进行选择。例如,在实时通信场景下,计算复杂度是相对有限的,运动估计模块要选择计算量较小的算法,以平衡复杂度和编码效率。当然,运动估计与运动补偿的复杂度还与块的大小,参考帧的个数,亚像素的计算等有关,在此不再深入展开。
04
总结
本文介绍的预测技术,充分利用了视频信号空间上和时间上的相关性,通过多种设计精巧的预测模式,达到了去除冗余的目的,这是视频压缩高达千倍比例的关键之一。纵观视频编解码技术的发展历史,预测模式越来越多,预测的精确度越来越高,带来的压缩比也越来越高。如何快速高效地使用这些预测模式,也必然成为设计实现的重中之重,成为H.265/H.266/AV1这些新标准发挥其高效压缩性能的关键。
讲师招募 LiveVideoStackCon 2021 北京站
LiveVideoStackCon 2021 北京站(9月3-4日)正在面向社会公开招募讲师,欢迎通过 speaker@livevideostack.com 提交个人及议题资料,无论你的公司大小,title高低,老鸟还是菜鸟,只要你的内容对技术人有帮助,其他都是次要的,我们将会在24小时内给予反馈。点击[阅读原文]了解大会更多内容。
以上是关于揭秘视频千倍压缩背后的技术原理之预测技术的主要内容,如果未能解决你的问题,请参考以下文章
H.264/AVC视频编解码技术详解二十三帧间预测编码:帧间预测编码的基本原理