知识图谱构建射雕三部曲人物关系
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了知识图谱构建射雕三部曲人物关系相关的知识,希望对你有一定的参考价值。
前言引入
知识图谱(Knowledge Graph)是一门前沿的交叉学科,用于将人类社会的海量知识结构化,并提供一个可理解,可解释的一个模型。这里我们将以射雕三部曲为例,从 0 构建起一个可以实际应用的知识图谱。
知识图谱技术是人工智能技术的组成部分,其强大的语义处理和互联组织能力,为智能化信息应用提供了基础。
知识图谱旨在描述现实世界中存在的实体以及实体之间的关系。
随着人工智能的技术发展和应用,知识图谱作为关键技术之一,已被广泛应用于智能搜索、智能问答、个性化推荐、内容分发等领域。
然而,相比于传统技术,知识图谱的普及远远不够。大部分垂直行业中的技术和业务人员对知识图谱的概念、用途和相关技术的认识仍然比较模糊。
这里我们会对知识图谱的来龙去脉有个整体的了解,随后将详细介绍知识图谱生命周期中各个环节中涉及的理论,技术和工具。
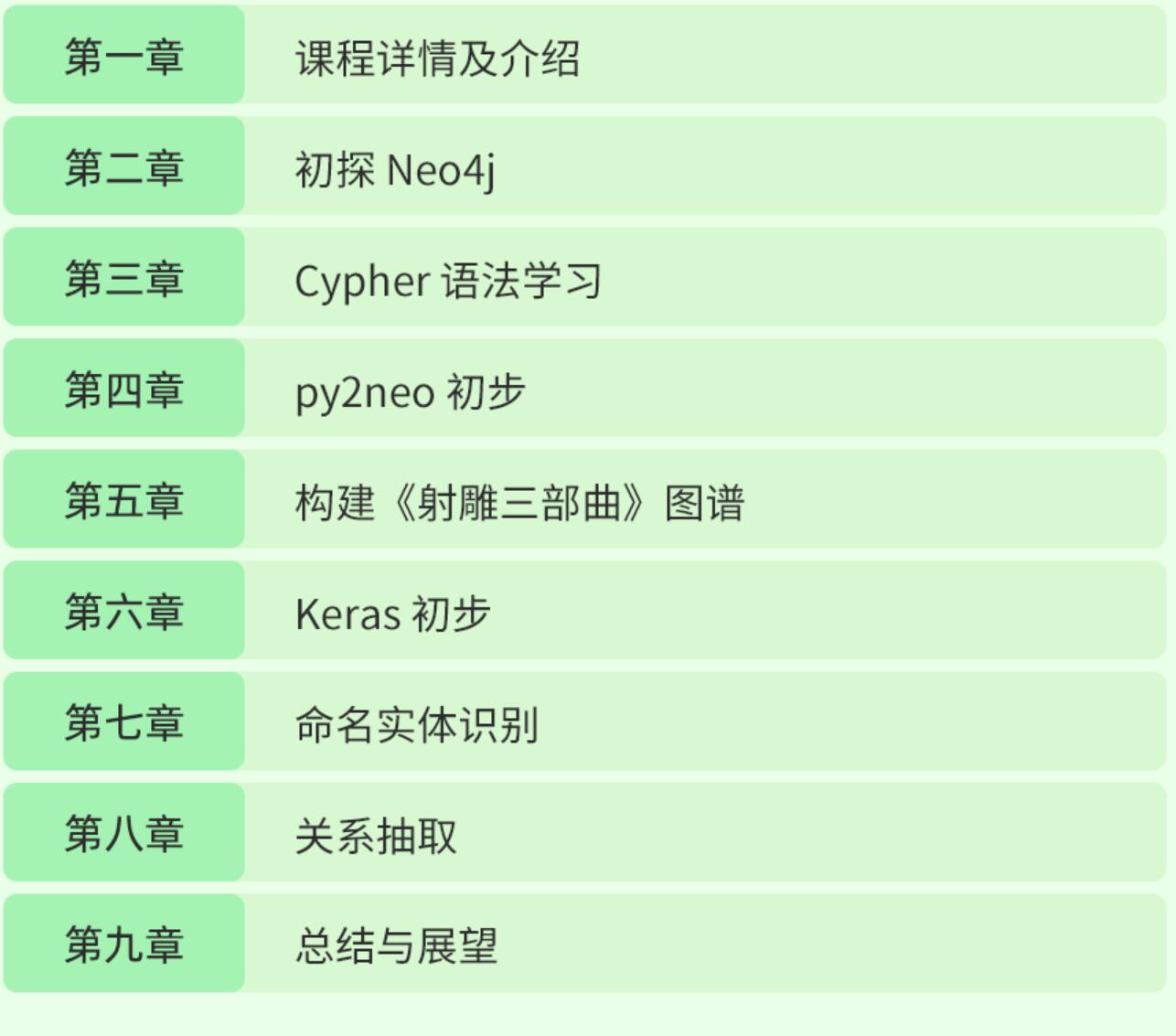
射雕三部曲构建后的图模型展示:
项目简介

如何快速梳理《射雕三部曲》中的人物关系,或者查看哪些人会什么武功?
通常的思路是通过原著和网络上的解读分析,将人物,武功,门派等信息提取出来,并构建一个模型存储,提问时通过查询这个模型来获得解答。知识图谱(knowledge graph) 就非常适合这一个任务。
知识图谱最早起源于 Google Knowledge Graph。它利用实体,关系,属性这些基本单位,以符号的形式描述了现实世界中不同概念之间的相互关系。目前,知识图谱已被广泛认为是实现认知智能的必备基础。
基础知识
知识图谱是一个前沿交叉性的学科,涉及到图论、机器学习、数据库等等领域。
图论与知识图谱
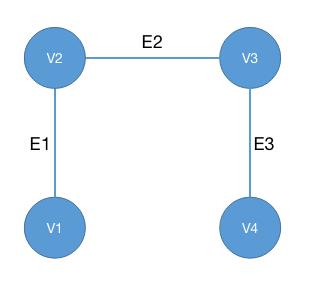
图论是数学的一个分支,以图(Graph) 为研究对象。在图论中,图由节点(Vertex)和边(Edge) 来构成。
如下图为一个由四个顶点和三条边组成的无向图。
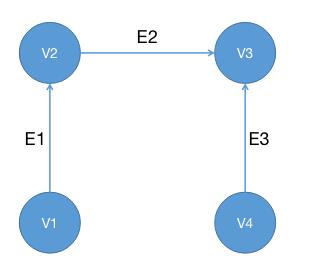
有向图是边具有方向的图,如下图所示
知识图谱从实际应用的角度出发可以理解成多关系图。 多关系图一般包含多种类型的节点和多种类型的边,如下图,不同颜色代表不同的种类。
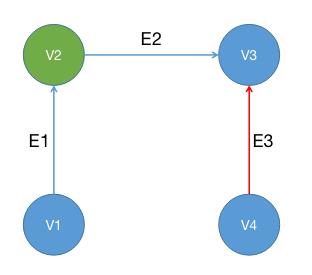
在知识图谱中,通常用实体(Entity)来表达图中的节点,用关系(Relation) 来表达图中的边。实体 指的是现实世界的事物比如人、地名、书名等,关系 则是不同实体之间到的某种联系。 在现实世界中,实体和关系也会拥有各自的属性,比如人有姓名和年龄。
知识图谱是一种基于图的数据结构,由节点(Point)和边(Edge) 组成,每个节点表示一个“实体”,每条边为实体与实体之间的“关系”,知识图谱本质上是语义网络。
实体指的可以是现实世界中的事物,比如人、地名、公司、电话、动物等;
关系则用来表达不同实体之间的某种联系。
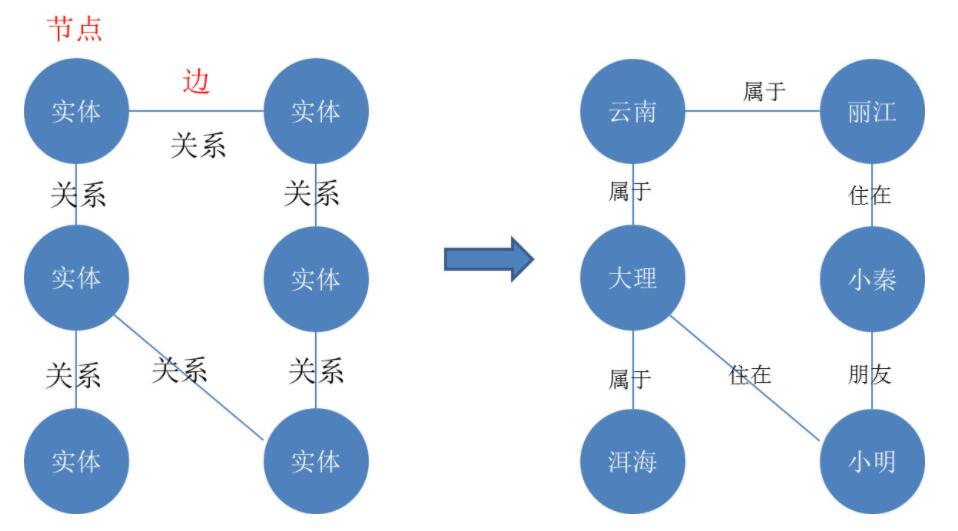
由上图,可以看到实体有地名和人;大理属于云南、小明住在大理、小明和小秦是朋友,这些都是实体与实体之间的关系。
通俗定义:知识图谱就是把所有不同种类的信息连接在一起而得到的一个关系网络,因此知识图谱提供了从“关系”的角度去分析问题的能力。
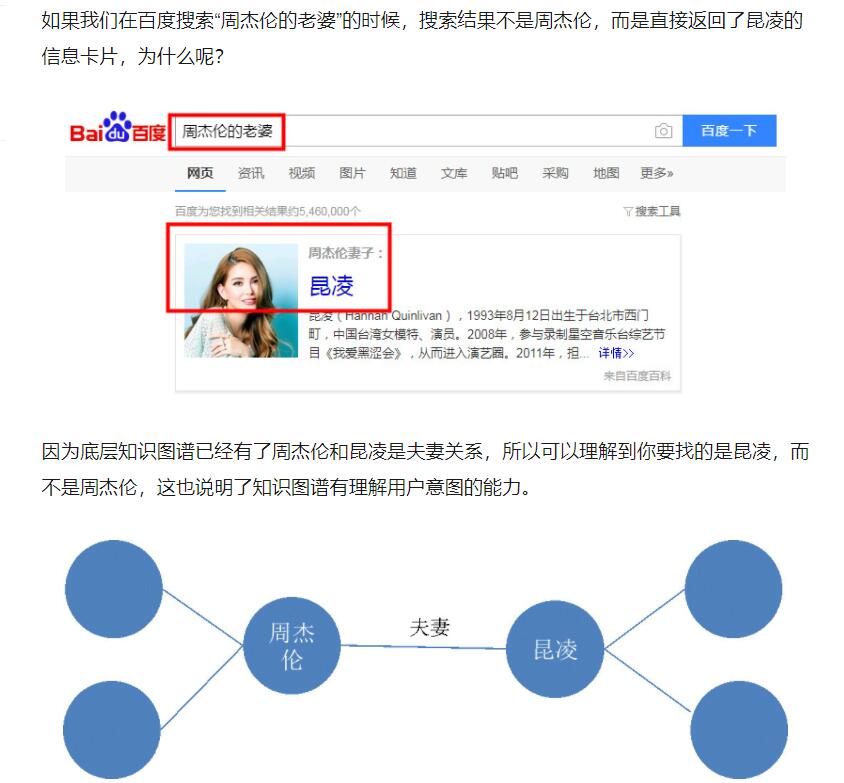
因为底层知识图谱已经有了周杰伦和昆凌是夫妻关系,所以可以理解到你要找的是昆凌,而不是周杰伦,这也说明了知识图谱有理解用户意图的能力。
又比如下图为带属性的图,郭靖和黄蓉都是《射雕英雄传》的角色,郭靖性别男,生性单纯刚直,在第三次华山论剑中获得称号“北侠”。
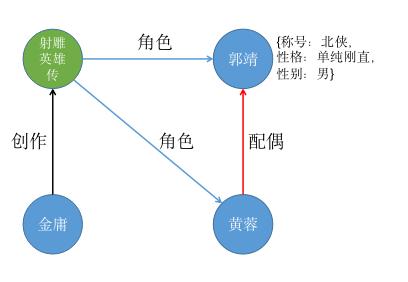
到这里相信你我已经初步认识了知识图谱。
让我们一起崇敬前辈们的伟大,一起憧憬未来吧!
感谢他们,让我们能够站在巨人的肩膀上前进!
知识图谱构建流程
知识图谱的构建是知识图谱应用的基础。
在现实世界中,存在着大量非结构化的数据,如整套金庸小说,或者是百度百科等对金庸小说人物的介绍,如何将这些非结构化的数据提取成结构化的数据,就需要借助自然语言处理等技术了,需要的技术包括但不限于如下:
命名实体识别
命名实体识别是自然语言处理的一个基础任务,其目的是识别语料中人、地名、书名等命名实体。
命名实体识别的方法基本分为两种:
- 基于规则与词典的方法:为目标实体编写模板,然后在原始语料中进行匹配
- 基于统计机器学习的方法:通过机器学习的方法对原始语料进行训练,然后再利用训练好的模型去识别实体
关系抽取
文本预料经过实体抽取,得到的是一系列离散的命名实体,为了得到语义信息,还得从语料中提取出实体之间的关联关系,通过关系将实体联系起来,才能够形成网状的知识结构。
知识图谱存储
知识图谱的本质是一种图形数据库,图数据库的基本含义是以“图”这种数据结构存储和查询数据。
图形数据库是 NoSQL 数据库的一种类型,它应用图形理论存储实体之间的关系信息。
NoSQL,泛指非关系型的数据库。
随着互联网web2.0网站的兴起,传统的关系数据库在处理web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,出现了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。
NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,特别是大数据应用难题。
------百度百科
常见的图形数据库有 Neo4j,FlockDB,AllegroGrap 等。
在本项目中主要学习 Neo4j ,Neo4j 是一个流行的开源图形数据库。
Neo4j 基于 Java 实现,兼容 ACID 特性,也支持其他编程语言,如 Ruby 和 Python。
完成本项目的最低要求:
1)掌握 Linux 基本操作
2)掌握 Python 基础操作
3)了解机器学习中监督学习的基本概念
若掌握以上技能,则可以获得更好的课程体验。
1)基础的英语阅读水平
2)对自然语言处理有一定的了解
拓展知识:监督学习supervised learning
监督学习是指:利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的过程,也称为监督训练或有教师学习。
监督学习是从标记的训练数据来推断一个功能的机器学习任务。训练数据包括一套训练示例。在监督学习中,每个实例都是由一个输入对象(通常为矢量)和一个期望的输出值(也称为监督信号)组成。
监督学习算法是分析该训练数据,并产生一个推断的功能,其可以用于映射出新的实例。一个最佳的方案将允许该算法来正确地决定那些看不见的实例的类标签。
这就要求学习算法是在一种“合理”的方式从一种从训练数据到看不见的情况下形成。
关键技术
知识图谱构建的过程中,最主要的一个步骤就是把数据从不同的数据源中抽取出来,然后按一定的规则加入到知识图谱中,这个过程我们称为知识抽取。
数据源的分为两种:结构化的数据和非结构化的数据。
结构化的数据是比较好处理的,难点在于处理非结构化的数据。
处理非结构化数据通常需要使用自然语言处理技术:实体命名识别、关系抽取、实体统一、指代消解等。
学习内容
本课程分六个方向七个实验,具体组织如下:
-
Neo4j 学习
主要掌握 Neo4j 图形数据库的部署,并通过导入已构建好的《射雕三部曲》的知识图谱,来掌握客户端界面的操作使用方法。 -
Cypher 学习
本方向分为两个实验,第一个实验使用 Neo4j 的查询语言 Cypher 进行增删查改操作。第二个实验使用 Neo4j 提供的 Python api 进行增删查改操作。 -
知识图谱建立
使用 Neo4j 中的两种批量导入方法,建立《射雕三部曲》中的人物,武功,门派等关系。 -
Keras 入门
主要学习 Keras 的使用方法,以及构建 NLP 模型常用的网络层。 -
命名实体识别
本方向主要介绍命名实体识别任务,并通过 Keras 构建一个常用于命名实体识别任务的模型 Bi-LSTM,最后进行训练与预测。 -
关系抽取
本方向主要介绍关系抽取任务,并通过 Keras 构建一个用于关系抽取的简单网络,最后进行训练与预测。
实验环境
本实验分两个环境
- 容器环境:用于 Neo4j 相关实验的学习
- jupyter:用于机器学习相关实验的学习
Jupyter Notebook(此前被称为 IPython notebook)是一个交互式笔记本,支持运行 40 多种编程语言。
Jupyter Notebook 的本质是一个 Web 应用程序,便于创建和共享文学化程序文档,支持实时代码,数学方程,可视化和 markdown。
用途包括:数据清理和转换,数值模拟,统计建模,机器学习等等。
-------百度百科
后序引出
link
…
待完善
努力 进步 感谢
加油!
以上是关于知识图谱构建射雕三部曲人物关系的主要内容,如果未能解决你的问题,请参考以下文章