Java基础面试题(建议收藏)
Posted 程序dunk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java基础面试题(建议收藏)相关的知识,希望对你有一定的参考价值。
个人博客欢迎访问
总结不易,如果对你有帮助,请点赞关注支持一下
微信搜索程序dunk,关注公众号,获取博客源码、数据结构与算法笔记、面试笔试题
| 序号 | 内容 |
|---|---|
| 1 | Java基础面试题 |
| 2 | JVM面试题 |
| 3 | Java并发编程面试 |
| 4 | 计算机网络知识点汇总 |
| 5 | MySQL面试题 |
| 6 | Mybatis源码分析 + 面试 |
| 7 | Spring面试题 |
| 8 | SpringMVC面试题 |
| 9 | SpringBoot面试题 |
| 10 | SpringCloud面试题 |
| 11 | Redis面试题 |
| 12 | Elasticsearch面试题 |
| 13 | Docker学习 |
| 14 | 消息队列 |
| 15 | 持续更新… |
面向对象
面向对象和面向过程的区别
- 面向过程:具体化的,流程化的,解决一个问题,你需要一步一步分析,一步一步实现
- 优点:性能比面向对象高,因为类调用时需要实例化,开销比较大,比较消耗资源;比如单片机、嵌入式开发、Linux/Unix等一般采用面向过程开发,性能是最重要的因素
- 缺点:没有面向对象易维护、易复用、易扩展
- 面向对象:模型化的,你只需要抽出一个类,这是一个封闭的盒子,在这里你拥有数据也拥有解决问题的方法。需要什么功能直接使用就可以了,不必去一步一步的实现,至于这个功能是如何实现的
- 优点::易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,可以设计出低耦合的系统,使系统更加灵活、更加易于维护
- 缺点:性能比面向过程低
三大特性
抽象:抽象是将一类对象的共同特征总结出来构造类的过程,包括数据抽象和行为抽象两方面,抽象只关注对象有哪些属性和行为,并不关注这些行为的细节
封装
是对象功能内聚的表现形式,在抽象基础上决定信息是否公开及公开等级,核心问题是以什么方式暴漏哪些信息。主要任务是对属性、数据、敏感行为实现隐藏,对属性的访问和修改必须通过公共接口实现。封装使对象关系变得简单,降低了代码耦合度,方便维护
迪米特原则就是对封装的要求,即 A 模块使用 B 模块的某接口行为,对 B 模块中除此行为外的其他信息知道得应尽可能少。不直接对 public 属性进行读取和修改而使用 getter/setter 方法是因为假设想在修改属性时进行权限控制、日志记录等操作,在直接访问属性的情况下无法实现。如果将 public 的属性和行为修改为 private 一般依赖模块都会报错,因此不知道使用哪种权限时应优先使用 private
继承
用来扩展一个类,子类可继承父类的部分属性和行为使模块具有服用性,继承是“is-a”的关系,可使用里氏替换原则判断是够满足“is-a”的关系,即任何父类出现的地方子类都可以出现。。如果父类引用直接使用子类引用来代替且可以正确编译并执行,输出结果符合子类场景预期,那么说明两个类符合里氏替换原则
多态
以封装和继承为基础,根据运行时对象实际类型使同以行为具有不同表现形式,多态指在编译层面无法确定最终调用的方法体,在运行期由JVM动态绑定,适合合适的重写方法,由于重载属于静态绑定,本质上重载结果是完全不同的方法,因此多态一般专指重写
重载与重写
重载
重载指方法名称相同,但参数类型个数不同,是行为水平方向不同实现。对编译器来说,方法名称和参数列表组成了一个唯一键,称为方法签名,JVM 通过方法签名决定调用哪种重载方法。不管继承关系如何复杂,重载在编译时可以根据规则知道调用哪种目标方法,因此属于静态绑定
JVM 在重载方法中选择合适方法的顺序:① 精确匹配。② 基本数据类型自动转换成更大表示范围。③ 自动拆箱与装箱。④ 子类向上转型。⑤ 可变参数
重写
重写指子类实现接口或继承父类时,保持方法签名完全相同,实现不同方法体,是行为垂直方向不同实现
元空间有一个方法表保存方法信息,如果子类重写了父类的方法,则方法表中的方法引用会指向子类实现。父类引用执行子类方法时无法调用子类存在而父类不存在的方法。
重写方法访问权限不能变小,返回类型和抛出的异常类型不能变大,必须加 @Override
类之间的关系
| 类关系 | 描述 | 权力强侧 | 举例 |
|---|---|---|---|
| 继承 | 父子类之间的关系:is-a | 父类 | 小狗继承于动物 |
| 实现 | 接口和实现类之间的关系:can-do | 接口 | 小狗实现了狗叫接口 |
| 组合 | 比聚合更强的关系:contains-a | 整体 | 头是身体的一部分 |
| 聚合 | 暂时组装的关系:has-a | 组装方 | 小狗和绳子是暂时的聚合关系 |
| 依赖 | 一个类用到另一个:depends-a | 被依赖方 | 人养小狗,人依赖于小狗 |
| 关联 | 平等的使用关系:links-a | 平等 | 人使用卡消费,卡可以提取人的信息 |
访问权限控制符
| 访问权限控制符 | 本类 | 包内 | 包外子类 | 任何地方 |
|---|---|---|---|---|
| public | √ | √ | √ | √ |
| protected | √ | √ | √ | × |
| 无 | √ | √ | × | × |
| private | √ | × | × | × |
语言特性
Java语言的优点
- 平台无关性,摆脱硬件束缚,一次编写,导出运行
- 相对安全的内存管理和访问机制,避免大部分内存泄漏和指针越界
- 热点代码检测和运行时编译及优化,使程序随时间运行增长获得更高的性能
- 完善的应用程序接口,支持第三方类库
Java如何实现平台无关?
JVM:java编译器可生成与计算机体系结构无关的字节码指令,字节码指令不仅可以轻易的在任何机器上解释执行,还可以动态地转换为本地机器代码,转换是由JVM实现的,JVM是平台相关的,屏蔽了不同操作系统的差异
语言规范:基本数据类型有明确的规定,例如int永远为32位,而C/C++中可能是16位、32位,也可能是编译器开发商指定的其他大小,Java中数值类型有固定的字节数,二进制格式存储和传输,字符串采用标准的Unicode格式存储
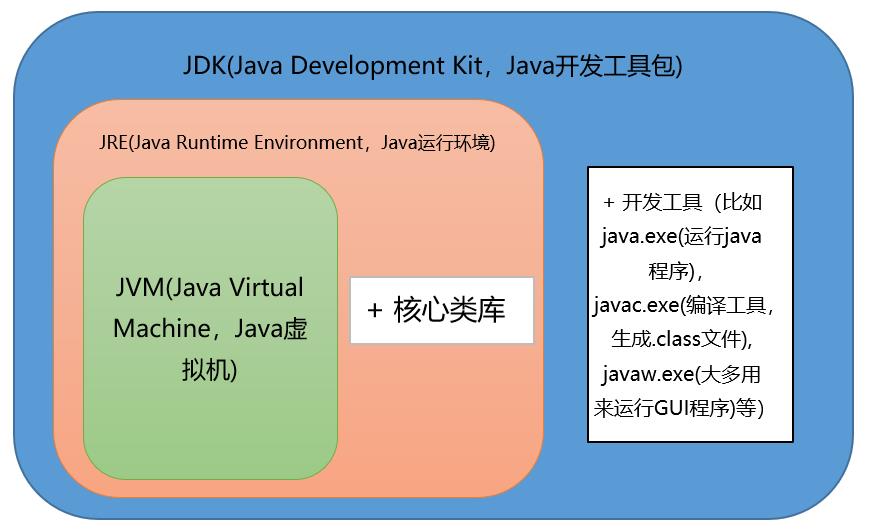
JDK和JRE的区别
JDK:Java Development Kit,开发工具包。提供了编译运行Java程序的各种工具,包括编译器(javac.exe)、JRE以及打包工具(jar.exe),是Java的核心
JRE:Java Runtime Environment,运行时环境,运行Java程序所必须的环境,包括JVM、核心类库、核心配置工具
Java是按值调用还是引用调用
- 按值传递:是指接受调用者提供的值
- 按引用调用:是指方法接受调用者提供的变量地址
Java总是按值调用,方法得到的所有参数的副本,传递对象时实际上方法接受的是对象引用的副本。方法不能修改基本数据类型的参数,如果传递了一个int值,改变值不会影响实参,因为改变的是值的一个副本
可以改变对象参数的状态,但不能让对象参数引用一个新的对象,如果传递了一个int数组,改变数组的内容会影响实参,而改变这个参数的引用并不会让实参引用新的数组对象
浅拷贝和深拷贝的区别
- 浅拷贝:只复制当前对象的基本数据类型即引用变量,没有复制引用变量指向的实际对象。修改克隆对象可能影响原对象,不安全
- 深拷贝:完全拷贝基本数据类型和应用数据类型,安全
序列化
Java 对象 JVM 退出时会全部销毁,如果需要将对象及状态持久化,就要通过序列化实现,将内存中的对象保存在二进制流中,需要时再将二进制流反序列化为对象。对象序列化保存的是对象的状态,因此属于类属性的静态变量不会被序列化
常见的序列化方式
Java 原生序列化
实现 Serializabale 标记接口,Java 序列化保留了对象类的元数据(如类、成员变量、继承类信息)以及对象数据,兼容性最好,但不支持跨语言,性能一般。序列化和反序列化必须保持序列化 ID 的一致,一般使用 private static final long serialVersionUID 定义序列化 ID,如果不设置编译器会根据类的内部实现自动生成该值。如果是兼容升级不应该修改序列化 ID,防止出错,如果是不兼容升级则需要修改
Hessian 序列化
Hessian 序列化是一种支持动态类型、跨语言、基于对象传输的网络协议。Java 对象序列化的二进制流可以被其它语言反序列化。Hessian 协议的特性:① 自描述序列化类型,不依赖外部描述文件,用一个字节表示常用基础类型,极大缩短二进制流。② 语言无关,支持脚本语言。③ 协议简单,比 Java 原生序列化高效。Hessian 会把复杂对象所有属性存储在一个 Map 中序列化,当父类和子类存在同名成员变量时会先序列化子类再序列化父类,因此子类值会被父类覆盖
JSON 序列化
JSON 序列化就是将数据对象转换为 JSON 字符串,在序列化过程中抛弃了类型信息,所以反序列化时只有提供类型信息才能准确进行。相比前两种方式可读性更好,方便调试
序列化通常会使用网络传输对象,而对象中往往有敏感数据,容易遭受攻击,Jackson 和 fastjson 等都出现过反序列化漏洞,因此不需要进行序列化的敏感属性传输时应加上 transient 关键字。transient 的作用就是把变量生命周期仅限于内存而不会写到磁盘里持久化,变量会被设为对应数据类型的零值
常问方法和类
Object 类有哪些方法?
**equals:**检测对象是否相等,默认使用 == 比较对象引用,可以重写 equals 方法自定义比较规则。equals 方法规范:自反性、对称性、传递性、一致性、对于任何非空引用 x,x.equals(null) 返回 false
**hashCode:**散列码是由对象导出的一个整型值,没有规律,每个对象都有默认散列码,值由对象存储地址得出。字符串散列码由内容导出,值可能相同。为了在集合中正确使用,一般需要同时重写 equals 和 hashCode,要求 equals 相同 hashCode 必须相同,hashCode 相同 equals 未必相同,因此 hashCode 是对象相等的必要不充分条件
toString:打印对象时默认的方法,如果没有重写打印的是表示对象值的一个字符串
*clone:clone 方法声明为 protected,类只能通过该方法克隆它自己的对象,如果希望其他类也能调用该方法必须定义该方法为 public。如果一个对象的类没有实现 Cloneable 接口,该对象调用 clone 方抛出一个 CloneNotSupport 异常。默认的 clone 方法是浅拷贝,一般重写 clone 方法需要实现 Cloneable 接口并指定访问修饰符为 public
**finalize:**确定一个对象死亡至少要经过两次标记,如果对象在可达性分析后发现没有与 GC Roots 连接的引用链会被第一次标记,随后进行一次筛选,条件是对象是否有必要执行 finalize 方法。假如对象没有重写该方法或方法已被虚拟机调用,都视为没有必要执行。如果有必要执行,对象会被放置在 F-Queue 队列,由一条低调度优先级的 Finalizer 线程去执行。虚拟机会触发该方法但不保证会结束,这是为了防止某个对象的 finalize 方法执行缓慢或发生死循环。只要对象在 finalize 方法中重新与引用链上的对象建立关联就会在第二次标记时被移出回收集合。由于运行代价高昂且无法保证调用顺序,在 JDK 9 被标记为过时方法,并不适合释放资源
**getClass:**返回包含对象信息的类对象。
**wait / notify / notifyAll:**阻塞或唤醒持有该对象锁的线程
hashCode与equals的
HashSet如何检查重复,两个对象的hashCode()相同,则equals()也一定为true
hashCode()介绍
hashCode()的作用是获取哈希吗,也称为散列码;它实际上是返回一个int整数,这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode()定义在JDK的Object类中,这就意味着Java中任何类都包含hashCode()函数
散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
为什么要有hashCode()
我们以“HashSet 如何检查重复”为例子来说明为什么要有 hashCode:
当你把对象加入HashSet时,HashSet会先计算对象的hashCode值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashCode值作比较,如果没有相符的hashCode,HashSet会假设对象没有重复出现。但是如果发现有相同 hashCode值的对象,这时会调用 equals()方法来检查 hashCode相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置
hashCode()与equals()的相关规定
如果两个对象相等,则hashcode一定相等
两个对象相等,对两个对象分别调用equals返回都是true
两个对象有相同的hashcode值,但是他们不一定相等
因此,equals()方法被覆盖,则hashCode()值也必须被覆盖
hashCode()默认行为是对堆上的对象产生独特的值,如果没有重写hashCode(),则该class两个对象,无论如何都不会相等(即使这两个对象指向相同的数据)
对象的相等与指向他们的引用相等,两者有什么不同?
对象的相等 比的是内存中存放的内容是否相等而 引用相等 比较的是他们指向的内存地址是否相等
==和equals?
- ==:它的作用是判断两个对象的地址是不是相等的,即,判断两个对象是不是同一个对象(基本的数据类型**比较的是值,引用数据类型**比较的是内存地址)
- equals():它的作用也是判断两个对象是否相等。但它一般有两种使用情况
- 类没有覆盖equals()方法,则通过equals()比较该类的两个对象时,等价通过**==**比较这两个对象
- 类覆盖了**equals()方法,一般,我们都覆盖equals()**放方法来判断两个对象内容是否相等,若他们的内容相等,则返回true
注意:String中的equals方法是被重写过的,因为Object的equals方法比较的对象的内存地址,而String的equals方法比较的是对象的值
当创建String类型的对象时,虚拟机会在常量池中查找有么有已经存在的值和要创建的值相同的对象,如果有就把它赋值给当前引用,如果没有就在常量池中创建一个String对象
数据类型
java的基本数据类型
| 数据类型 | 内存大小 | 默认值 | 取值范围 |
|---|---|---|---|
| byte | 1B | (byte)0 | -128 ~ 127 |
| short | 2B | (short)0 | -215 ~ 215-1 |
| int | 4B | 0 | -231 ~ 231-1 |
| long | 8B | 0L | -263 ~ 263-1 |
| float | 4B | 0.0F | ±3.4E+38(有效位数 6~7 位) |
| double | 8B | 0.0D | ±1.7E+308(有效位数 15 位) |
| char | 英文1B,中文UTF-8占3B,GBK占2B | ‘\\u0000’ | ‘\\u0000’ ~ ‘\\uFFFF’ |
| boolean | 单个变量4B/数组1B | false | true、false |
JVM没有boolean赋值的专用字节码指令,
boolean f = false就是使用 ICONST_0 即常数 0 赋值。单个 boolean 变量用 int 代替,boolean 数组会编码成 byte 数组
包装类
每个基本数据类型都对应一个包装类,除了int和char对应Integer和Character外,其余基本数据类型的包装类都是首字母大写
-
自动装箱:将基本类型用它们对应的引用类型包装起来
-
自动拆箱:将包装类型转换为基本数据类型
int和Integer区别
Java是一个近乎纯洁的面向对象的编程语言,但是为了编程方便还是引入了基本数据类型,但是为了能够将这些基本数据类型当做对象操作,Java为每一个基本数据类型都引入了对应的包装类型(wrapper class)),int 的包装类就是 Integer,从 Java 5 开始引入了自动装箱/拆箱机制,使得二者可以相互转换
Java 为每个原始类型提供了包装类型:
原始类型: boolean,char,byte,short,int,long,float,double
包装类型:Boolean,Character,Byte,Short,Integer,Long,Float,Double
Integer a = 127和Integer b = 127相等吗
对于对象引用类型:==比较的是对象的内存地址。
对于基本数据类型:==比较的是值
如果整型字面量的值在**-128到127之间**,那么自动装箱时不会new新的Integer对象,而是直接引用常量池中的Integer对象,超过范围 a1==b1的结果是false
public static void main(String[] args) {
Integer a = new Integer(3);
Integer b = 3; // 将3自动装箱成Integer类型
int c = 3;
System.out.println(a == b); // false 两个引用没有引用同一对象
System.out.println(a == c); // true a自动拆箱成int类型再和c比较
System.out.println(b == c); // true
Integer a1 = 128;
Integer b1 = 128;
System.out.println(a1 == b1); // false
Integer a2 = 127;
Integer b2 = 127;
System.out.println(a2 == b2); // true
}
String
字符串拼接的方式有哪些
- 直接用
+,底层用 StringBuilder 实现。只适用小数量,如果在循环中使用+拼接,相当于不断创建新的 StringBuilder 对象再转换成 String 对象,效率极差 - 使用 String 的 concat 方法,该方法中使用
Arrays.copyOf创建一个新的字符数组 buf 并将当前字符串 value 数组的值拷贝到 buf 中,buf 长度 = 当前字符串长度 + 拼接字符串长度。之后调用getChars方法使用System.arraycopy将拼接字符串的值也拷贝到 buf 数组,最后用 buf 作为构造参数 new 一个新的 String 对象返回。效率稍高于直接使用+ - 使用 StringBuilder 或 StringBuffer,两者的
append方法都继承自 AbstractStringBuilder,该方法首先使用Arrays.copyOf确定新的字符数组容量,再调用getChars方法使用System.arraycopy将新的值追加到数组中。StringBuilder 是 JDK5 引入的,效率高但线程不安全。StringBuffer 使用 synchronized 保证线程安全
String a = “a” + new String(“b”)创建了几个对象?
常量和常量拼接仍是常量,结果在常量池,只要有变量参与拼接结果就是变量,存在堆
使用字面量时只创建一个常量池中的常量,使用 new 时如果常量池中没有该值就会在常量池中新创建,再在堆中创建一个对象引用常量池中常量。因此 String a = "a" + new String("b") 会创建四个对象,常量池中的 a 和 b,堆中的 b 和堆中的 ab
StringBuffer和StringBuilder的区别?
可变性
-
String类中使用字符数组保存字符,
private final char value[],所以String对象是不可变的。 -
StringBuilder与StringBuffer都继承自
AbstractStringBuilder类,在AbstractStringBuilder中也是使用字符数组保存字符串
线程安全性
- String中的对象是不可变的,也就可以理解常量,线程安全。
AbstractStringBuilder是StringBuilder与StringBuffer的公共父类,StringBuffer对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。StringBuilder并没有对方法进行加同步锁,所以是非线程安全的
性能
- 每次对String类型进行改变的时候,都会生成一个新的String对象,然后将指向新的String对象。
- StringBuffer每次都会对StringBuffer进行操作,而不是生成新的对象并改变对象的引用,相同情况下使用StringBuilder相比使用StringBuffer仅能获得10%~15% 左右的性能提升,但却要冒多线程不安全的风险
总结
- 如果操作少量的数据使用String
- 单线程操作大量数据使用StringBuilder
- 多线程操作大量数据使用StringBuffer
switch 是否能作用在 byte 上,是否能作用在 long 上,是否能作用在 String 上?
在Java5以前,switch(expr)中,expr只能是byte、short、char、int,从java5开始,java中引入了枚举类型,expr也可以是enum类型,从Java7开始,expr还可以是字符串(String),但是long不支持
final关键字
- 修饰变量
凡是对成员变量或者局部变量(在方法中的或者代码块中的变量称为本地变量)声明为final的都叫做final变量,final变量经常和static关键字一起使用,作为常量
final修饰的基本数据的变量时,必须赋予初始值且不能变修饰引用变量时,该引用变量不能在指向其他对象
当final修饰基本数据类型变量时不赋予初始值以及引用变量指向其他对象时就会报错
当final修饰基本数据类型变量被改变时,就会报错
- 修饰方法
final也可以声明方法,方法上面加上final关键字,代表这个方法不可以被子类方法重写,如果你认为一个方法的功能足够完整了,子类不需要改变的话,你也可以声明此方法为final,final方法比非final方法要快,因为在编译的时候已经静态绑定了,不需要在运行时在进行绑定
- 修饰类
使用final修饰的类叫做final类,final类通常功能是完整的,他们不能被继承,Java中有许多类是final的,如String,Integer以及其他包装类
final、finally、finalize 有什么区别?
final可以修饰类、变量、方法,修饰类表示该类不能被继承、修饰方法表示该方法不能被重写、修饰变量表示该变量是一个常量不能被重新赋值。
finally一般作用在try-catch代码块中,在处理异常的时候,通常我们将一定要执行的代码方法finally代码块中,表示不管是否出现异常,该代码块都会执行,一般用来存放一些关闭资源的代码。
finalize是一个方法,属于Object类的一个方法,而Object类是所有类的父类,Java 中允许使用 finalize()方法在垃圾收集器将对象从内存中清除出去之前做必要的清理工作。
注解
注解的概念
注解(Annotation)是Java提供的设置程序中元素的关联信息和元数据(MetaData)的方法,他是一个接口,程序可以通过反射获取指定程序中元素的注解对象,然后通过该注解对象获取注解中的元数据信息
什么是注解?什么是元注解?
- 注解:是一种标识,使类或借口附加额外的信息,帮助编译器和JVM完成一些特定的功能,例如
@Override标识一个方法是重写方法。 - 元注解:元注解是自定义注解的注解:
@Target:约束作用位置,值是ElementType枚举常量,包括 METHOD 方法、VARIABLE 变量、TYPE 类/接口、PARAMETER 方法参数、CONSTRUCTORS 构造方法和 LOACL_VARIABLE 局部变量等@Retention:约束生命周期- SOURCE:在源文件中有效,即源文件中被保留
- CLASS:在Class文件中有效,即在Class文件中保留
- RUNTIME:在运行时有效,即在运行时保留
@Documented:表明这个注解应该被javadoc工具记录,因此可以为javadoc类的工具文档化@Inherited:是一个标记注解,表明某个被标注的类型是被继承的,如果有一个使用了@Inherited修饰的Annotation被用于一个Class,则这个注解将被用于该Class类
注解处理器
注解用于描述元数据的信息,使用的重点在于对注解处理器的定义,JavaSE5扩展了反射机制的API,以帮助程序员快速构造自定义注解处理器,对注解的使用一般包含定义及使用注解接口,我们一般通过封装统一的注解工具来使用注解
定义注解
/**
* @author :zsy
* @date :Created 2021/6/12 14:48
* @description:
*/
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface FruitProvider {
//供应商编号
public int id() default -1;
//供应商名称
public String name() default "";
//供应商地址
public String address() default "";
}
使用注解接口
定义一个Apple类,并通过注解方式定义了一个属性
/**
* @author :zsy
* @date :Created 2021/6/12 14:51
* @description:苹果
*/
@Setter
@Getter
public class Apple {
@FruitProvider(id = 1, name = "陕西商洛", address = "陕西省西安市")
private String appleProvider;
}
定义注解处理器
通过反射信息获取注解数据
/**
* @author :zsy
* @date :Created 2021/6/12 14:53
* @description:注解处理器
*/
public class FruitInfoUtil {
public static void getFruitInfo(Class<?> clazz) {
System.out.println("供应商信息");
Field[] declaredFields = clazz.getDeclaredFields();
for (Field declaredField : declaredFields) {
FruitProvider annotation = declaredField.getAnnotation(FruitProvider.class);
System.out.println("供应商编号:" + annotation.id());
System.out.println("供应商姓名:" + annotation.name());
System.out.println("供应商地址:" + annotation.address());
System.out.println(annotation);
}
}
}
测试
/**
* @author :zsy
* @date :Created 2021/6/12 14:54
* @description:
*/
public class Test {
public static void main(String[] args) {
FruitInfoUtil.getFruitInfo(Apple.class);
}
}
供应商信息
供应商编号:1
供应商姓名:陕西商洛
供应商地址:陕西省西安市
@注解.FruitProvider(name=陕西商洛, address=陕西省西安市, id=1)
类
内部类
定义在类内部的类被称为内部类,内部类根据不同的定义方式,可以分为静态内部类、成员内部类、局部内部类和匿名内部类
静态内部类
定义在类内部的静态类,就是静态内部类
静态内部类可以访问外部类的静态变量和方法;在静态内部类中可以定义静态变量、静态方法、构造反函数等;静态内部类通过外部类.静态内部类的方式调用
静态内部类可以访问外部类所有的静态变量,而不可访问外部类的非静态变量;静态内部类的创建方式,new 外部类.静态内部类(),如下
/**
* @author :zsy
* @date :Created 2021/6/12 15:07
* @description: 静态内部类
*/
public class OuterClass {
private static String className = "StaticInnerClass";
public static class StaticInnerClass {
public void getClassName() {
System.out.println("className:" + className);
}
}
//调用静态内部类
public static void main(String[] args) {
StaticInnerClass staticInnerClass = new StaticInnerClass();
staticInnerClass.getClassName();
}
}
Java集合类中HashMap在内部维护了一个静态内部类Node数组用于存放元素,Node元素对使用者是透明的,像这种和外部类关系密切且不依赖外部类实例得嘞,可以使用静态内部类
成员内部类
定义在类内部,成员位置上的非静态类,就是成员内部类。
成员内部内部类不能定义静态方法和变量(final修饰除外),因为成员内部类是非静态的,而在Java的非静态代码块中不能定义静态方法和静态变量
成员内部类可以访问外部类所有的变量和方法,包括静态和非静态,私有和公有。成员内部类依赖于外部类的实例,它的创建方式外部类实例.new 内部类()
/**
* @author :zsy
* @date :Created 2021/6/12 15:16
* @description:成员内部类
*/
public class OutClass {
private static int a = 12;
private int b = 2;
public class MemberInnerClass {
public void print() {
System.out.println(a);
System.out.println(b);
}
}
public static void main(String[] args) {
OutClass outClass = new OutClass();
MemberInnerClass memberInnerClass = outClass.new MemberInnerClass();
memberInnerClass.print();
}
}
局部内部类
定义在方法中的内部类,就是局部内部类
当一个类只需要在某个方法中使用特定的类时,可以通过局部内部类来优雅的实现
局部内部类的创建方式,在对应方法内,new 内部类()
/**
* @author :zsy
* @date :Created 2021/6/12 15:26
* @description:局部内部类
*/
public class OutClass {
private static int a;
private int b;
public void printClassTest(final int c) {
final int d = 1;
class PastClass {
public void print() {
System.out.println(c);