知识图谱构建《射雕三部曲》图谱(CSV文件导入)
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了知识图谱构建《射雕三部曲》图谱(CSV文件导入)相关的知识,希望对你有一定的参考价值。
构建《射雕三部曲》图谱
下载 CSV 文件
打开 Xfce 终端,进入 /var/lib/neo4j/import 目录,下载本节实验所需要的 CSV 文件
cd /var/lib/neo4j/import
wget https://labfile.oss.aliyuncs.com/courses/1354/data.zip
unzip data.zip
将 csv文件下载解压到 import中。
一共有三个 CSV 文件,在本节实验中,我们用 LOAD CSV 方法导入 射雕三部曲.csv 文件,用 Neo4j-admin import 方法导入 nodes.csv 和 relationships.csv 文件。
LOAD CSV 构建
load csv 文件
LOAD CSV 是 Cypher 提供的 ETL(Extract-Transform-Load) 工具, 允许从本地或者互联网上导入 CSV 文件。 导入本地文件时,Neo4j 默认的设置是把文件导入的根目录限制在当前库的 import 文件夹下。
射雕三部曲.csv 文件结构如下
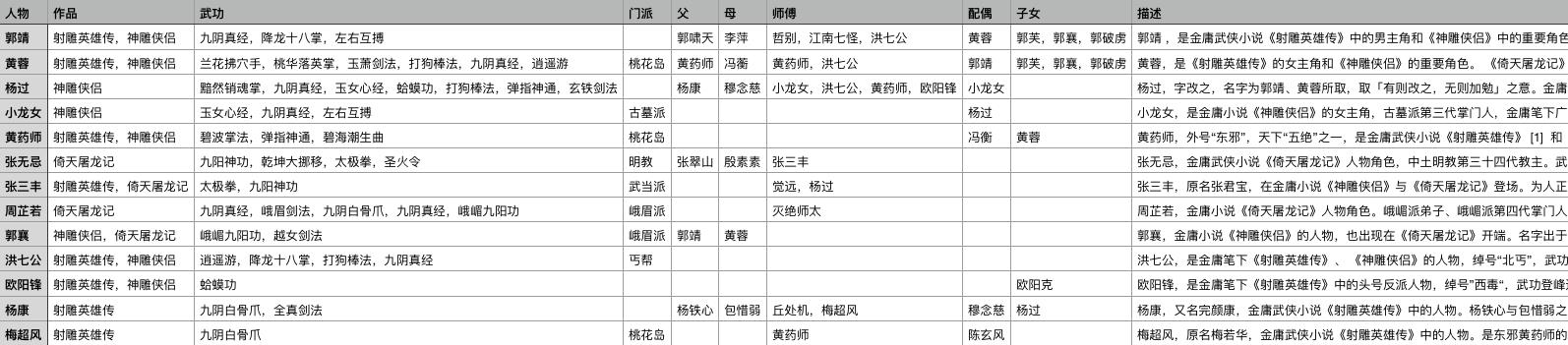
一个单元格中可能为空,或者一个实体,或者多个实体。多个实体之间用中文逗号隔开。
同时,sudo neo4j stop 停止 Neo4j 服务,在 /etc/neo4j/neo4j.conf 文件里,最下面增加一行
cypher.lenient_create_relationship=true
这一句命令的目的是在构建关系时遇到 null-[]-() 一类的情况时可以自动跳过而不报错,在下面的实验中会用到。

启动 Neo4j 服务,登录 Neo4j 客户端,在命令行中导入 CSV文件
load csv from 'file:///射雕三部曲.csv' as line return line

可以看到 load csv 命令返回了一个按行组成的列表,取列表中的元素通过如 line[0] 这样的取下标操作。
同时 load csv 接收可变参数 WITH HEADERS, 从文件中读取第一行作为参数名,在使用了该参数后返回一个 key-value 的数据结构。
load csv with headers from 'file:///射雕三部曲.csv' as line return line
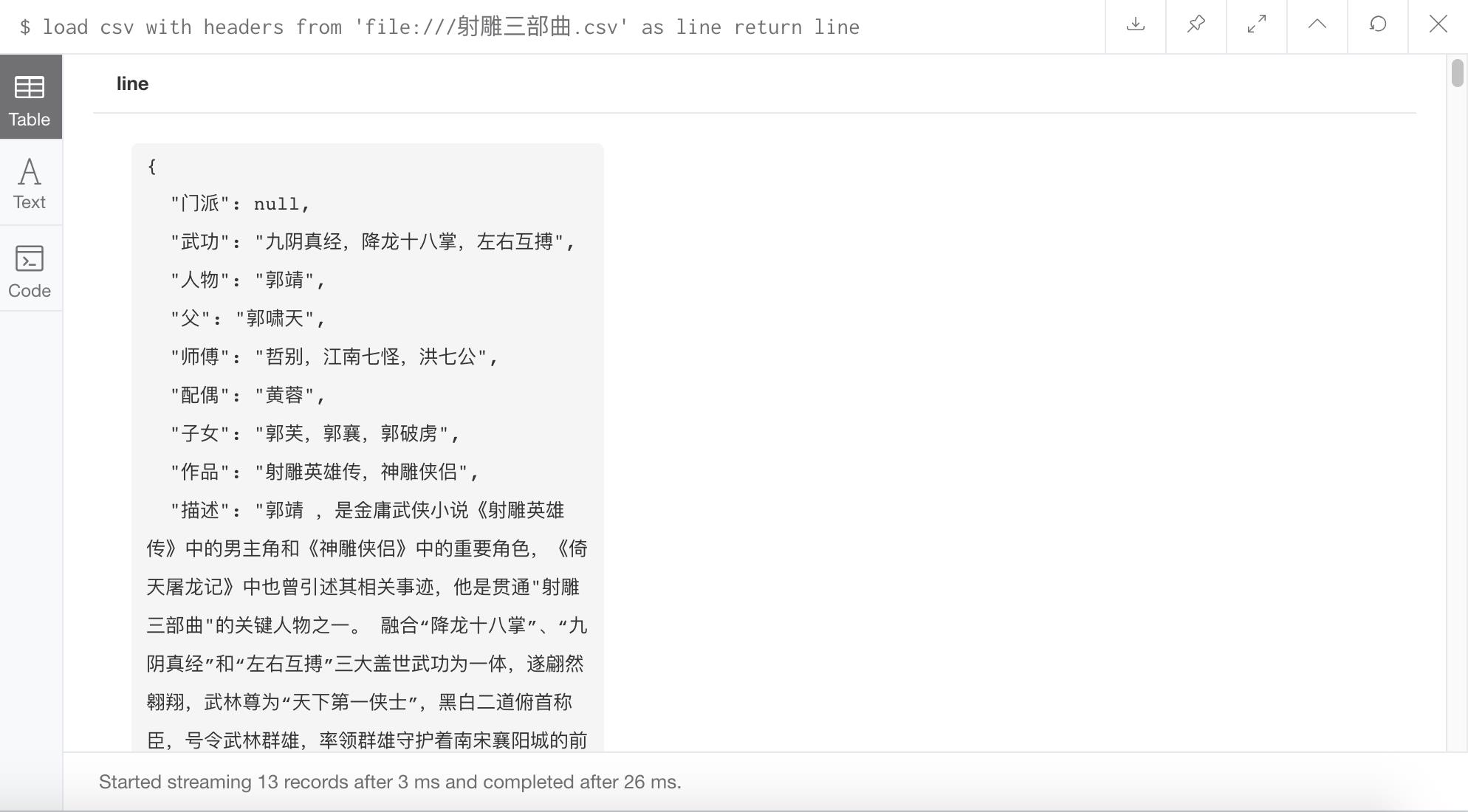
这样就可以用如 line.人物 这样的方法来取列表的元素了
构建节点
首先构建第一列的角色节点,同时第一列的人物拥有 描述 的属性,为了避免重复录入,在这里使用 merge 来创建节点。
load csv with headers from 'file:///射雕三部曲.csv' as line
merge(n:角色{name:line.人物,desc:line.描述}) return n

接下来创建作品节点
因为一个人可能会在多个作品中出现,因此先使用 split 将一个单元格中的多个作品拆分开来,然后用 foreach 分别创建
load csv with headers from 'file:///射雕三部曲.csv' as line
merge(n:角色{name:line.人物,desc:line.描述})
foreach (a in split(line.作品,',') | merge(n:作品{name:a}))
剩下的节点同理,除了配偶,父和母只包含单个实体,其他都先用 split 拆分再用 merge 创建
完整语句如下:
load csv with headers from 'file:///射雕三部曲.csv' as line
merge(n:角色{name:line.人物,desc:line.描述})
foreach (a in split(line.作品,',') | merge(n:作品{name:a}))
foreach (a in split(line.武功,',') | merge(n:武功{name:a}))
foreach (a in split(line.门派,',') | merge(n:门派{name:a}))
foreach (a in split(line.师傅,',') | merge(n:角色{name:a}))
foreach (a in split(line.子女,',') | merge(n:角色{name:a}))
foreach (a in line.父 | merge(n:角色{name:a}))
foreach (a in line.母 | merge(n:角色{name:a}))
foreach (a in line.配偶 | merge(n:角色{name:a}))

构建关系
构建关系的目标是给 CSV 中第一列的人物与后面几列的人物、作品、武功和门派之间构建关系。
load csv with headers from 'file:///射雕三部曲.csv' as line
match (book:作品),(person:角色),(skill:武功)
where
book.name in split(line.作品, ',') and
person.name = line.人物 and
skill.name in split(line.武功, ',')
merge (person)-[:所在作品]-(book)
merge (person)-[:武功]-(skill)
在创建关系的时候,要注意到 CSV 中有些单元格为空,此时使用 match 语句时用where and并排查询条件是匹配不到单元格为空的节点的,此时就需要用到 optional match ,如果有匹配到的,返回匹配到的节点,如果没有匹配到,返回 null,同时跳过 null 与角色之间的关系的建立,这部分在实验开始时已经设置好了。
如构建 角色-父 之间的关系:
load csv with headers from 'file:///射雕三部曲.csv' as line
match (book:作品),(person:角色),(skill:武功)
where
book.name in split(line.作品, ',') and
person.name = line.人物 and
skill.name in split(line.武功, ',')
optional match (father:角色)
where
father.name = line.父
merge (person)-[:所在作品]-(book)
merge (person)-[:武功]-(skill)
merge (person)-[r:父]-(father)
return (person)-[r:父]-(father)
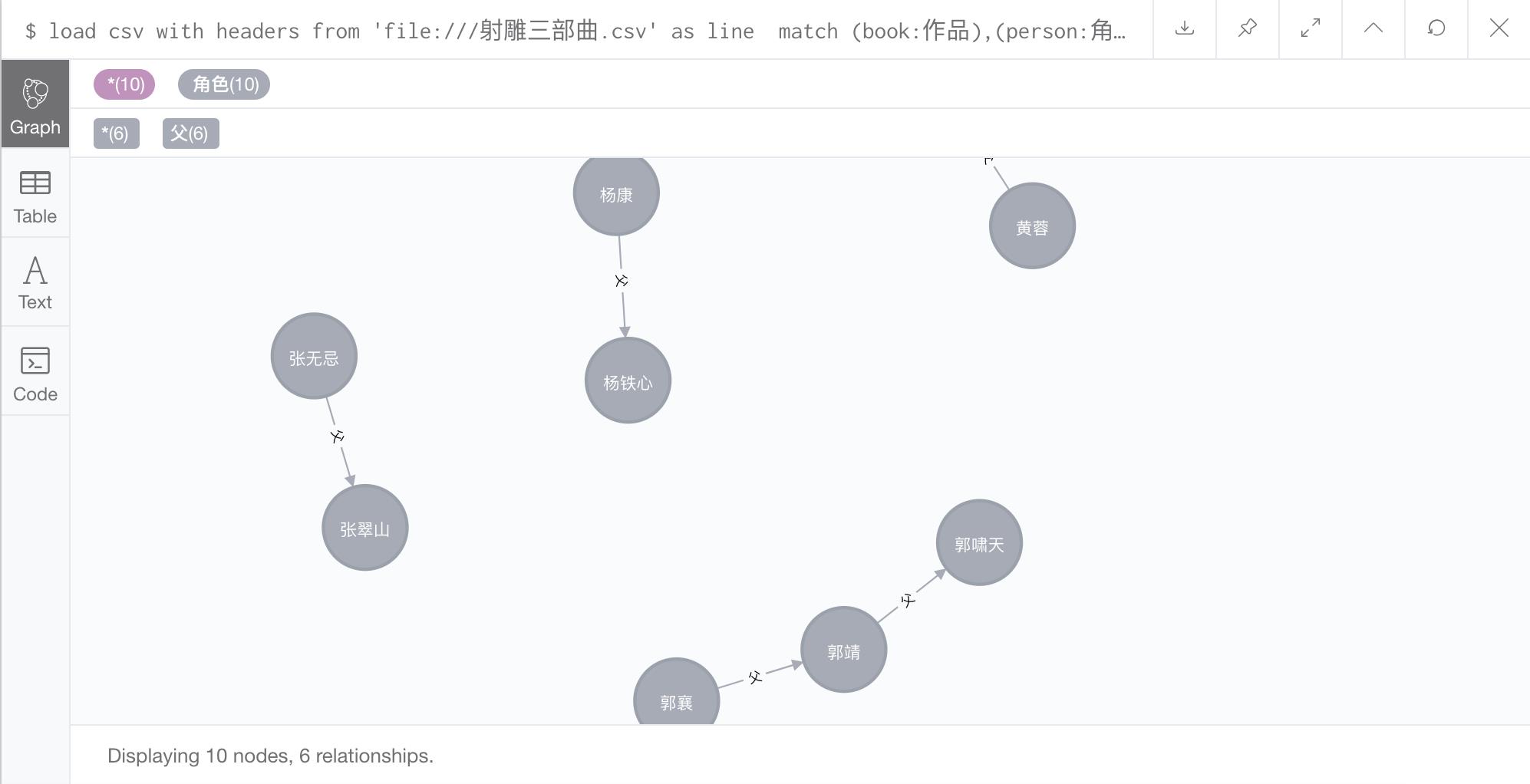
同理构建其他角色,同时要注意到,配偶关系是互相的,即如 小龙女 是 杨过 的配偶,同时 杨过 也是 小龙女 的配偶,因此构建关系时这两个节点之间需要有两条异向的边,即通过箭头 ()-[]->() 来实现。
构建关系的语句如下:
load csv with headers from 'file:///射雕三部曲.csv' as line
match (book:作品),(person:角色),(skill:武功)
where
book.name in split(line.作品, ',') and
person.name = line.人物 and
skill.name in split(line.武功, ',')
optional match (father:角色)
where
father.name = line.父
optional match (mother:角色)
where
mother.name = line.母
optional match (spouse:角色)
where
spouse.name = line.配偶
optional match (sect:门派)
where
sect.name = line.门派
optional match (children:角色)
where
children.name in split(line.子女, ',')
optional match (master:角色)
where
master.name in split(line.师傅, ',')
merge (person)-[:所在作品]-(book)
merge (person)-[:师傅]-(master)
merge (person)-[:武功]-(skill)
merge (person)-[:父]-(father)
merge (person)-[:母]-(mother)
merge (person)-[:配偶]->(spouse)
merge (person)-[:所在门派]-(sect)
merge (person)-[:子女]-(children)
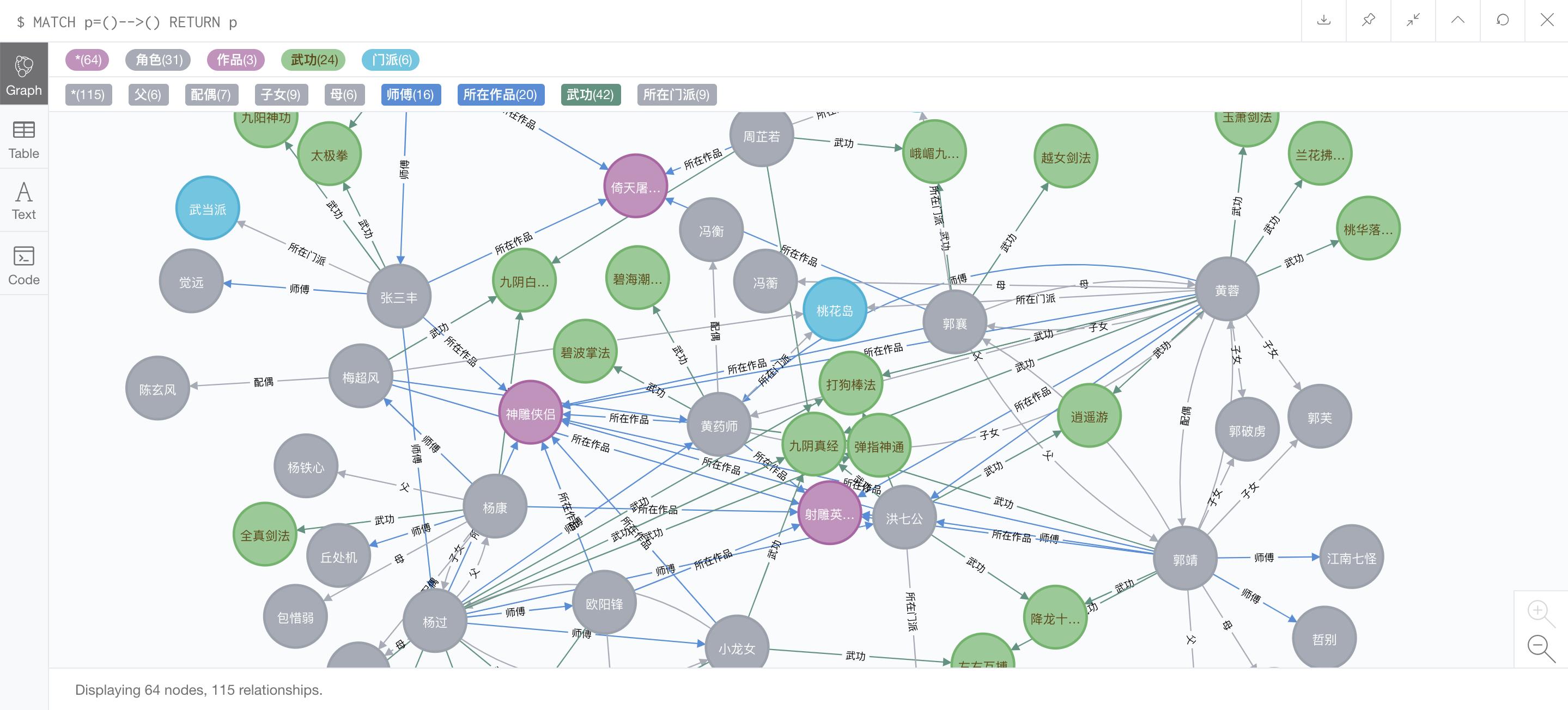
此时,所有的节点和关系都已经导入好了,通过下面的命令进行查看:
MATCH p=()-->() RETURN p
neo4j-admin import 构建
Neo4j 官方提供了 neo4j-admin import 来解决数据量非常大时导入的性能瓶颈。
参数设置如下:
--nodes节点所在 CSV 文件--relationships关系所在 CSV 文件
nodes 节点所在 CSV 文件格式形式如下:
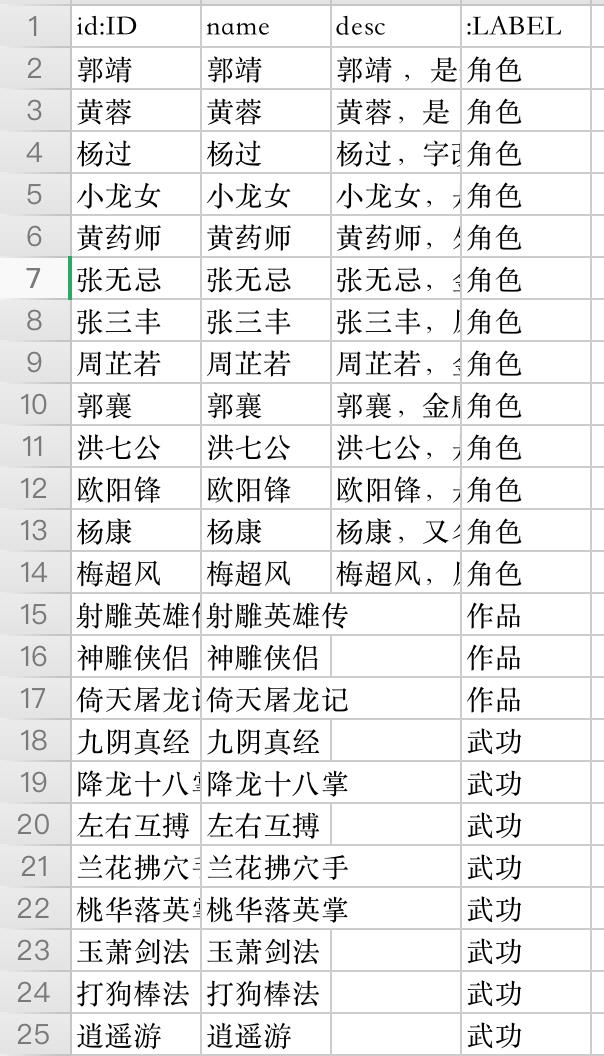
第一列为 ID 号,在构建关系时必须用过 ID 号来对应关系,第二、三列为属性值,第四列为节点类型。
relationships 关系所在 CSV 文件格式形式如下:
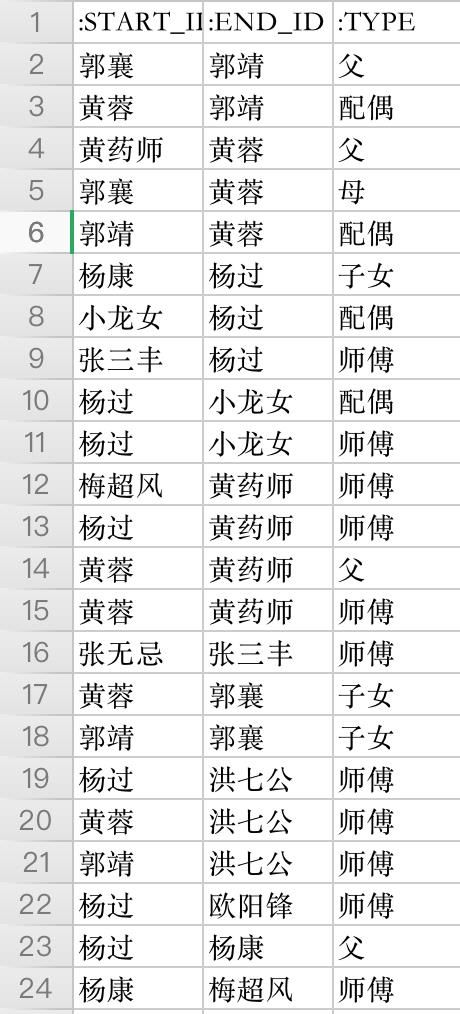
第一列表示起始节点的 ID 号,第二列表示截至节点的 ID 号,第三列为关系类型。
在使用 neo4j-admin import 时,需要先 sudo neo4j stop 停止 Neo4j 服务,同时删除旧的 graph.db 文件(通过 neo4j.conf 可以知道在 /var/lib/neo4j/data/databases 目录下)。
./neo4j-admin import --nodes=../import/nodes.csv --relationships=../import/relationships.csv
导入csv文件
可是使用命令行将相关节点和关系的csv文件导入,但是csv文件需要符合一定的格式。
指定csv文件格式
csv文件主要是对文件的表头有一定的格式要求,下文将分别记录节点文件和关系文件的表头格式。
- 节点文件表头格式如下:
:ID :LABEL - 关系文件表头格式如下:
:START_ID :END_ID :TYPE
分别代表图关系中的起始节点ID、尾节点ID和两个ID之间的关系。
使用命令行导入csv文件
- 首先将节点和关系的csv文件放在neo4j根目录下的import文件夹中
- 切换至neo4j的bin文件夹下,使用如下命令将节点和关系的csv文件导入,在导入之前必须保证所导入的数据库为空,即在导入之前将数据库删掉(数据库路径为neo4j的data/database文件夹中),导入数据时会自动创建新的数据库。
./neo4j-admin import --database=graph.db --nodes=/neo4j-community-3.5.19-unix/import/node.csv --relationships=/neo4j-community-3.5.19-unix/rel.csv --delimiter='\\t'
- –database 代表所指定的数据库
- –nodes 代表节点文件
- –relationships 代表节点间关系文件
- –delimiter 代表节点/关系文件的分隔符
参考博客 Link
总结

加油!
感谢!
以上是关于知识图谱构建《射雕三部曲》图谱(CSV文件导入)的主要内容,如果未能解决你的问题,请参考以下文章