Python 真·精选 面试题45道(建议收藏,蹲坑的时候瞅瞅)
Posted Dream丶Killer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 真·精选 面试题45道(建议收藏,蹲坑的时候瞅瞅)相关的知识,希望对你有一定的参考价值。
👉写在前面👈
本文的由来是笔者搜罗各大网站 Python 面试题时发现,大部分的文章中的面试题有的太过基础(不是笔者装🍺哈),不信看下面。
 |
|---|
还有的更厉害,不知道在哪 copy 的,经常一打开全是 110道Python面试题。。
然后笔者就在 CSDN、Github 等平台,整理了一些我认为比较有价值的题目,部分题目是我根据自身的经历进行改编的。同时用 ☆ 来表示题目的难度,如果内容有错误,请在评论区下面留言,感激不尽!!
|
|
|---|
1.如何用 Python 输出一个 100 以内的斐波那契数列(Fibonacci sequence)?★★☆☆☆ |
2.什么是 lambda 函数?它有什么好处?★★☆☆☆ |
3.请简述 Python 中 is 和 == 的区别。★★☆☆☆ |
4.请简述 function(*args, **kwargs) 中的 *args, **kwargs 分别是什么意思?★★☆☆☆ |
5.请简述面向对象中 __new__ 和 __init__ 的区别。★★★☆☆ |
6.Python 子类继承自多个父类时,如多个父类有同名方法,子类将继承自哪个方法?★☆☆☆☆ |
| 7.判断两个字符串是否同构。★★☆☆☆ |
| 8.请写出匹配中国大陆手机号且结尾不是 4 和 7 的正则表达式。 ★★☆☆☆ |
| 9.使用递推式将矩阵 [ [1, 2], [3, 4], [5, 6] ] 转换为一维向量。 ★☆☆☆☆ |
10.编写 Python 程序,打印星号金字塔。★★☆☆☆ |
| 11.生成随机整数、随机小数、0-1之间小数的方法。★★☆☆☆ |
12.列表 [1, 2, 3, 4, 5],使用 map() 函数输出 [1, 4, 9, 16, 25],再通过列表推导式获取大于 10 的数。★★☆☆☆ |
| 13.对字符串去重,并从大到小输出排序。★★☆☆☆ |
| 14.字典根据键从大到小排序;根据值从大到小排序。★★☆☆☆ |
| 15.统计字符串中每个字母出现的次数,获取出现次数最多的两个字母及它们的出现次数。★★★☆☆ |
16.filter 方法获取 1 - 10 中 3 的倍数。★★☆☆☆ |
| 17.a = (1),b = (1, ),c = (‘1’)分别是什么类型。★★☆☆☆ |
18.x = ‘abc’, y = ‘def’, z = [‘d’, ‘e’, ‘f’],写出 x.join(y) , x.join(z) 的结果。★★☆☆☆ |
| 19.s = ‘静香语文100分, 静香数学100分’,将第一个 “静香” 换成 “胖虎” 。★★☆☆☆ |
| 20.写出常见的几种异常及含义。★★★☆☆ |
| 21.解释一下直接赋值、浅拷贝与深拷贝有什么区别?★★★★☆ |
22.使用 lambda 函数对 lst = [-1, -5, 2, -3, 1, 4, -4, 3, -2, 5] 进行排序,要求排序结果正数在前(从小到大),负数在后(从大到小),如 [1, 2, 3, 4, 5, -1, -2, -3, -4, -5]。★★★☆☆ |
| 23.按照年龄从小到大,班级从小到大对 [{‘age’: 18, ‘class’: 2}, {‘age’: 21, ‘class’: 1}, {‘age’: 19, ‘class’: 2}, {‘age’: 19, ‘class’: 1}] 列表进行排序。★★★☆☆ |
24.Python 中有哪些可变类型和不可变类型,它们有什么不同?★★☆☆☆ |
| 25.写出你知道的将两个字典合并为一个新字典的方法。★★★★☆ |
| 26.将文件内容按行读取到列表中。★★☆☆☆ |
27.Python 内置函数 any() 和 all() 的用法。★★☆☆☆ |
28.谈谈 Python 中的垃圾回收机制。★★★★☆ |
29.Python 的 re 模块中 match() 和 search() 的区别?★★★☆☆ |
30.在读文件操作的时候会使用 read()、readline() 或者 readlines(),简述它们各自的作用。★★★☆☆ |
| 31.解释一下什么是闭包?★★☆☆☆ |
| 32.递归函数停止的条件。★★☆☆☆ |
33.Python 正则匹配 “good good study, day day up” 时,(g.*d) 和 (g.*?d) 有什么区别?★★★☆☆ |
| 34.简述解释型和编译型编程语言?★★★☆☆ |
35.xrange 和 range 的区别?★★☆☆☆ |
36.简述 yield 和 yield from 关键字。★★★★☆ |
37.Python 中的 help() 和 dir() 函数有什么用?★★★☆☆ |
38.在 Python 中怎么实现线程?★★★★☆ |
39.Python 中什么是猴子补丁?★★★★☆ |
| 40.如何以就地操作方式打乱一个列表的元素?★★☆☆☆ |
41.将字符串 'love' 更改为 'live'。★★☆☆☆ |
| 42.写出下列代码的结果。★★☆☆☆ |
43.Python 中函数调用参数的传递方式是值传递还是引用传递?★★★☆☆ |
44.现有一个 DataFrame 数据集中包含学生的姓名与分数,先要新增一列"评价"记录学生的及格情况,如果分数低于 60 即为 “不及格”,否则 “及格”。★★★☆☆ |
| 45.现在为获取更详细的信息,需要将 “评价” 列进行划分,60以下不及格、60至80及格、80以上优秀。★★★☆☆ |
1.如何用 Python 输出一个 100 以内的斐波那契数列(Fibonacci sequence)?
难度:★★☆☆☆
>>> a, b = 0, 1
>>> while b < 100:
print(b, end=' ')
a, b = b, a + b
1 1 2 3 5 8 13 21 34 55 89
2.什么是 lambda 函数?它有什么好处?
难度:★★☆☆☆
lambda 函数是一个可以接收任意多个参数 (包括可选参数) 并且返回单个表达式值的函数。 lambda 函数不能包含命令,它们所包含的表达式不能超过一个。
3.请简述 Python 中 is 和 == 的区别。
难度:★★☆☆☆
Python 中的对象包含三个要素:id、type 和 value。is 比较的是两个对象的 id。== 比较的是两个对象的 value。
4.请简述 function(*args, **kwargs) 中的 *args, **kwargs 分别是什么意思?
难度:★★☆☆☆
*args 和 **kwargs 主要用于函数定义的参数。Python 语言允许将不定数量的参数传给一个函数,其中 *args 表示一个非键值对的可变参数列表,**kwargs 则表示不定数量的键值对参数列表。注意:*args 和 **kwargs 可以同时在函数的定义中,但是 *args 必须在**kwargs 前面。
5.请简述面向对象中 __new__ 和 __init__ 的区别。
难度:★★★☆☆
(1) __new__ 至少要有一个参数 cls,代表当前类,此参数在实例化时由 Python 解释器自动识别。
(2) __new__ 返回生成的实例,可以返回父类(通过 super (当前类名, cls )的方式)__new__出来的实例, 或者直接是对象的 __new__ 出来的实例。这在自己编程实现 __new__ 时要特别注意。
(3) __init__ 有一个参数 self,就是这个 __new__ 返回的实例, __init__ 在 __new__ 的基础上可以完成一些其它初始化的动作, __init__ 不需要返回值。
(4) 如果 __new__ 创建的是当前类的实例,会自动调用 __init__ ,通过返回语句里面调用的 __new__ 函 数的第一个参数是 cls 来保证是当前类实例,如果是其他类的类名,那么实际创建并返回的就是其他类的实例,也就不会调用当前类或其他类的 __init__ 函数。
6.Python 子类继承自多个父类时,如多个父类有同名方法,子类将继承自哪个方法?
难度:★☆☆☆☆
Python 语言中子类继承父类的方法是按照继承的父类的先后顺序确定的,例如,子类 A 继承自父类 B、 C,且B、C中具有同名方法 Test() ,那么 A 中的 Test() 方法实际上是继承自B中的 Test() 方法。
7.判断两个字符串是否同构。
难度:★★☆☆☆
字符串同构是指字符串 s 中的所有字符都可以替换为 t 中的所有字符。在保留字符顺序的同时,必须用另 一个字符替换所有出现的字符。不能将 s 中的两个字符映射到 t 中同一个字符,但字符可以映射到自身。 试判定给定的字符串 s 和 t 是否同构。
例如:
s = “paper”
t = “title”
输出 True
s = “add”
t = “apple”
输出 False
>>> s = 'app'
>>> t = 'add'
>>> len(set(s)) == len(set(t)) == len(set(zip(s, t)))
True
8.请写出匹配中国大陆手机号且结尾不是 4 和 7 的正则表达式。
难度:★★☆☆☆
>>> import re
>>> tel = '15674899231'
>>> "有效" if (re.match(r"1\\d{9}[0-3,5-6,8-9]", tel) != None) else "无效"
'有效'
9.使用递推式将矩阵 [ [1, 2], [3, 4], [5, 6] ] 转换为一维向量。
难度:★☆☆☆☆
>>> a = [[1, 2], [3, 4], [5, 6]]
>>> [j for i in a for j in i]
[1, 2, 3, 4, 5, 6]
10.编写 Python 程序,打印星号金字塔。
难度:★★☆☆☆
编写尽量短的 Python 程序,实现打印星号金字塔。例如 n=5 时输出以下金字塔图形:
*
***
*****
*******
*********
>>> n = 5
>>> for i in range(1, n + 1):
print(' '*(n-(i-1))+'*'*(2*i-1))
*
***
*****
*******
*********
11.生成随机整数、随机小数、0-1之间小数的方法。
难度:★★☆☆☆
>>> import random
>>> import numpy as np
>>> print('正整数:', random.randint(1, 10))
正整数: 2
>>> print('5个随机小数:', np.random.randn(5))
5个随机小数: [ 0.76768263 -0.3587897 0.04880354 -0.02443411 0.73785606]
>>> print('0-1随机小数:', random.random())
0-1随机小数: 0.24387235868905555
12.列表 [1, 2, 3, 4, 5],使用 map() 函数输出 [1, 4, 9, 16, 25],再通过列表推导式获取大于 10 的数。
难度:★★☆☆☆
>>> lst = [1, 2, 3, 4, 5]
>>> map(lambda x: x**2, lst)
<map object at 0x000002B37C9D88B0>
>>> [n for n in res if n > 10]
[16, 25]
13.对字符串去重,并从大到小输出排序。
难度:★★☆☆☆
>>> s = 'aabcddeff'
>>> set_s = set(list(s))
>>> list_s = sorted(list(set_s), reverse=True)
>>> ''.join(list_s)
'fedcba'
14.字典根据键从大到小排序;根据值从大到小排序。
难度:★★☆☆☆
dic = {'a': 2, 'b': 1, 'c': 3, 'd': 0}
lst1 = sorted(dic.items(), key=lambda x: x[0], reverse=False)
# [('a', 2), ('b', 1), ('c', 3), ('d', 0)]
lst2 = sorted(dic.items(), key=lambda x: x[1], reverse=False)
# [('d', 0), ('b', 1), ('a', 2), ('c', 3)]
res_dic1 = {key: value for key, value in lst1}
res_dic2 = {key: value for key, value in lst2}
print('按照键降序:', res_dic1)
print('按照值降序:', res_dic2)
# 按照键降序: {'a': 2, 'b': 1, 'c': 3, 'd': 0}
# 按照值降序: {'d': 0, 'b': 1, 'a': 2, 'c': 3}
15.统计字符串中每个字母出现的次数,获取出现次数最多的两个字母及它们的出现次数。
难度:★★★☆☆
>>> from collections import Counter
>>> s = 'aaaabbbccd'
>>> Counter(s).most_common(2)
[('a', 4), ('b', 3)]
16.filter 方法获取 1 - 10 中 3 的倍数。
难度:★★☆☆☆
>>> list(filter(lambda x: x % 3 == 0, list(range(1, 10))))
[3, 6, 9]
17.a = (1),b = (1, ),c = (‘1’)分别是什么类型。
难度:★★☆☆☆
>>> type((1))
<class 'int'>
>>> type((1,))
<class 'tuple'>
>>> type(('1'))
<class 'str'>
18.x = ‘abc’, y = ‘def’, z = [‘d’, ‘e’, ‘f’],写出 x.join(y) , x.join(z) 的结果。
难度:★★☆☆☆
>>> x = 'abc'
>>> y = 'def'
>>> z = list(y)
>>> x.join(y)
'dabceabcf'
>>> x.join(z)
'dabceabcf'
19.s = ‘静香语文100分, 静香数学100分’,将第一个 “静香” 换成 “胖虎” 。
难度:★★☆☆☆
>>> s = '静香语文100分, 静香数学100分'
>>> s.replace('静香', '胖虎', 1)
'胖虎语文100分, 静香数学100分'
20.写出常见的几种异常及含义。
难度:★★★☆☆
IOError:输入输出异常AttributeError:试图访问一个对象没有的属性ImportError:无法引入模块或包 / 对象IndentationError:代码缩进错误IndexError:下标索引超出边界KeyError:试图访问映射中不存在的键SyntaxError:Python语法错误NameErrir:未声明/初始化对象 (没有属性)TabError:Tab和空格混用ValueError:传入无效的参数OverflowError:数值运算超出最大限制
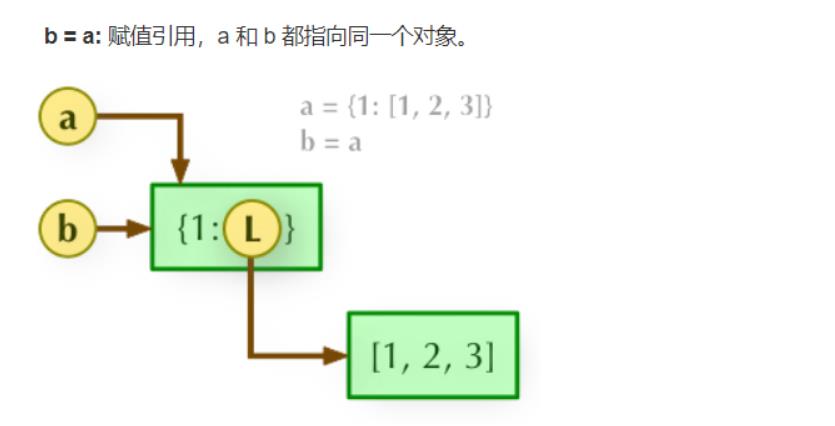
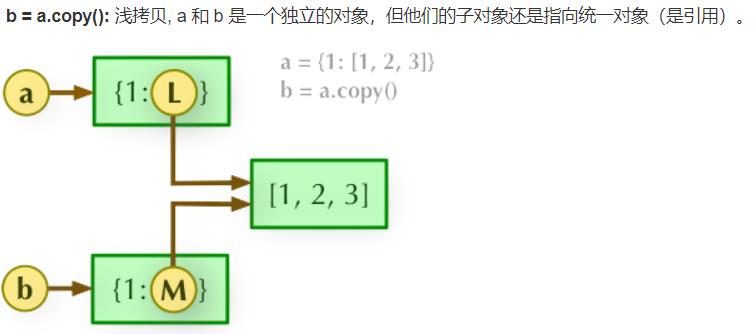
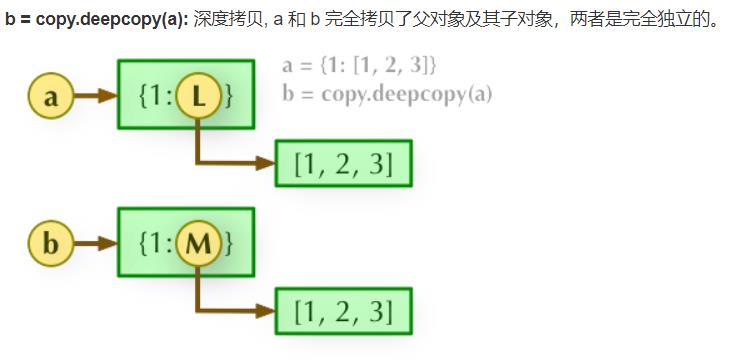
21.解释一下直接赋值、浅拷贝与深拷贝有什么区别?
难度:★★★★☆
(1)直接赋值,传递对象的引用而已。原始列表改变,被赋值的对象也会做相同改变。
(2)浅拷贝,没有拷贝子对象,所以原始数据子对象改变,拷贝的子对象也会发生变化。
(3)深拷贝,包含对象里面的子对象的拷贝,所以原始对象的改变不会造成深拷贝里任何子元素的改变,二者完全独立。
下面看一个例子:
import copy
primary_list = [1,2,3,[1,2]]
list1 = primary_list
list2 = primary_list.copy()
list3 = copy.deepcopy(primary_list)
# --直接赋值--
list1.append('a')
list1[3].append('b')
print(primary_list,'地址:',id(primary_list))
print(list1,'地址:',id(list1))
# [1, 2, 3, [1, 2, 'b'], 'a'] 地址: 2381167401856
# [1, 2, 3, [1, 2, 'b'], 'a'] 地址: 2381167401856
# --浅拷贝--
list2.append('a')
list2[3].append('b')
print(primary_list,'地址:',id(primary_list))
print(list2,'地址:',id(list2))
# [1, 2, 3, [1, 2, 'b']] 地址: 2693332999552
# [1, 2, 3, [1, 2, 'b'], 'a'] 地址: 2693332999680
# --深拷贝--
list3.append('a')
list3[3].append('b')
print(primary_list,'地址:',id(primary_list))
print(list3,'地址:',id(list3))
# [1, 2, 3, [1, 2]] 地址: 2627768688384
# [1, 2, 3, [1, 2, 'b'], 'a'] 地址: 2627768688448
 |
|---|
 |
 |
22.使用 lambda 函数对 lst = [-1, -5, 2, -3, 1, 4, -4, 3, -2, 5] 进行排序,要求排序结果正数在前(从小到大),负数在后(从大到小),如 [1, 2, 3, 4, 5, -1, -2, -3, -4, -5]。
难度:★★★☆☆
>>> lst = [-1, -5, 2, -3, 1, 4, -4, 3, -2, 5]
>>> lst.sort(key=lambda x: (x < 0, abs(x)))
# lst = sorted(lst, key=lambda x: (x < 0, abs(x)))
>>> lst
[1, 2, 3, 4, 5, -1, -2, -3, -4, -5]
23.按照年龄从小到大,班级从小到大对 [{‘age’: 18, ‘class’: 2}, {‘age’: 21, ‘class’: 1}, {‘age’: 19, ‘class’: 2}, {‘age’: 19, ‘class’: 1}] 列表进行排序。
难度:★★★☆☆
>>> lst = [{'age': 18, 'class': 2}, {'age': 21, 'class': 1}, {'age': 19, 'class': 2}, {'age': 19, 'class': 1}]
>>> lst.sort(key=lambda x: (x['age'], x['class']))
>>> lst
[{'age': 18, 'class': 2}, {'age': 19, 'class': 1}, {'age': 19, 'class': 2}, {'age': 21, 'class': 1}]
24.Python 中有哪些可变类型和不可变类型,它们有什么不同?
难度:★★☆☆☆
(1) 可变类型有 list ,dict ;不可变类型有 str ,int ,tuple。
(2) 当进行修改操作时,可变类型传递的是内存中的地址,也就是说,直接修改内存中的值,并没有开辟新的内存。
(3) 不可变类型被改变时,并没有改变原内存地址中的值,而是开辟一块新的内存,将原地址中的值复制过去,对这块新开辟的内存中的值进行操作。
25.写出你知道的将两个字典合并为一个新字典的方法。
难度:★★★★☆
# 示例:
dict1 = {'name': '静香', 'age': 18}
dict2 = {'name': '静香', 'sex': 'female'}
# 合并后
res = {'name': '静香', 'age': 18, 'sex': 'female'}
1.update()更新
dict1.update(dict2)
2.字典推导式
res = {k: v for dic in [dict1, dict2] for k, v in dic.items()}
3.元素拼接
res = dict(list(dict1.items()) + list(dict2.items()))
4.itertools.chain
chain() 可以将一个列表如 lists / tuples / iterables,链接在一起;返回 iterables 对象。
from itertools import chain
res = dict(chain(dict1.items(), dict2.items()))
5.collections.ChainMap
collections.ChainMap 可以将多个字典或映射,在逻辑上将它们合并为一个单独的映射结构
from collections import ChainMap
res = dict(ChainMap(dict2, dict1))
6.字典拆分
在Python3.5+中,可以下面这种字典拆分的方式:
res = {**dict1, **dict2}
26.将文件内容按行读取到列表中。
难度:★★☆☆☆
with open('somefile.txt') as f:
content = [line.strip() for line in f] # 去掉首尾的空白字符
27.Python内置函数 any() 和 all() 的用法。
难度:★★☆☆☆
(1)any(iterable) 函数接受一个可迭代对象 iterable 作为参数,如果 iterable 中有元素为真值则返回 True ,否则返回 False 。如果 iterable 为空则返回 False 。
(2)all(iterable) 函数接受一个可迭代对象 iterable 作为参数,如果 iterable 中所有元素为真值则返回 True ,否则返回 False 。如果 iterable 为空则返回 True 。
28.谈谈 Python 中的垃圾回收机制。
难度:★★★★☆
Python GC主要使用引用计数(reference counting)来跟踪和回收垃圾。在引用计数的基础上,通过“标记-清除”(mark and sweep)解决容器对象可能产生的循环引用问题,通过“分代回收”(generation collection)以空间换时间的方法提高垃圾回收效率。
1.引用计数
PyObject 是每个对象必有的内容,其中 ob_refcnt 就是做为引用计数。当一个对象有新的引用时,它的 ob_refcnt 就会增加,当引用它的对象被删除,它的 ob_refcnt 就会减少引用计数为 0 时,该对象生命就结束了。 优点:
- 简单
- 实时性 缺点:
- 维护引用计数消耗资源
- 循环引用
2.标记-清除机制
基本思路是先按需分配,等到没有空闲内存的时候从寄存器和程序栈上的引用出发,遍历以对象为节点、以引用为边构成的图,把所有可以访问到的对象打上标记,然后清扫一遍内存空间,把所有没标记的对象释放。
3.分代技术
分代回收的整体思想是:将系统中的所有内存块根据其存活时间划分为不同的集合,每个集合就成为一个“代”,垃圾收集频率随着“代”的存活时间的增大而减小,存活时间通常利用经过几次垃圾回收来度量。 Python 默认定义了三代对象集合,索引数越大,对象存活时间越长。
举例: 当某些内存块 M 经过了 3 次垃圾收集的清洗之后还存活时,我们就将内存块 M 划到一个集合 A 中去,而新分配的内存都划分到集合 B 中去。当垃圾收集开始工作时,大多数情况都只对集合 B 进行垃圾回收,而对集合 A 进行垃圾回收要隔相当长一段
以上是关于Python 真·精选 面试题45道(建议收藏,蹲坑的时候瞅瞅)的主要内容,如果未能解决你的问题,请参考以下文章
精选300道JavaWEB程序设计,测测你Javaweb的掌握程度(建议收藏)
101道经典JavaScript面试题总结(附答案,建议收藏)