Spark SQL 浅学笔记2
Posted 卖山楂啦prss
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark SQL 浅学笔记2相关的知识,希望对你有一定的参考价值。
工作笔记
前面提到:Hive是将SQL转为MapReduce,而SparkSQL可以理解成是将SQL解析成RDD + 优化再执行
对于开发人员来讲,SparkSQL 可以简化 RDD 的开发,提高开发效率,且执行效率非常快,所以实际工作中,基本上采用的就是> SparkSQL。Spark SQL 为了简化 RDD 的开发,提高开发效率,提供了 2 个编程抽象,类似 Spark Core 中的RDD
➢ DataFrame
➢ DataSet
Spark 中的模块
引用图片:https://zhuanlan.zhihu.com/p/61631248
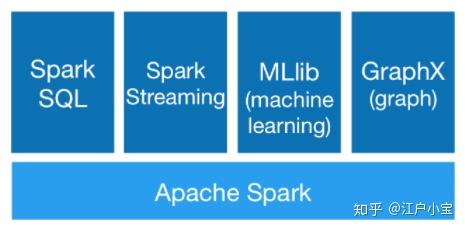
底层是Spark-core核心模块,Spark-core的核心抽象是RDD,Spark SQL等都基于RDD封装了自己的抽象,例如在Spark SQL中是DataFrame/DataSet。
相对来说RDD是更偏底层的抽象,DataFrame/DataSet是在其上做了一层封装,做了优化,使用起来更加方便。从功能上来说,DataFrame/DataSet能做的事情RDD都能做,RDD能做的事情DataFrame/DataSet不一定能做。
SparkSQL 特点
-
易整合:无缝的整合了 SQL 查询和 Spark 编程
-
统一的数据访问:使用相同的方式连接不同的数据源
-
兼容 Hive:在已有的仓库上直接运行 SQL 或者 HiveQL
-
标准数据连接:通过 JDBC 或者 ODBC 来连接
DataFrame
在 Spark 中,DataFrame 是一种以 RDD 为基础的分布式数据集,类似于传统数据库中的二维表格。(除了数据以外,还记录数据的结构信息,即schema)
DataFrame 与 RDD 的主要区别在于,
DataFrame 带有 schema 元信息,即 DataFrame所表示的二维表数据集的每一列都带有名称和类型。这使得 Spark SQL 得以洞察更多的结构信息,从而对藏于 DataFrame 背后的数据源以及作用于 DataFrame 之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标。
反观 RDD,由于无从得知所存数据元素的具体内部结构,Spark Core 只能在 stage 层面进行简单、通用的流水线优化。
简言之:
RDD中没有schema信息,而DataFrame中数据每一行都包含schema
DataFrame = RDD[Row] + shcema
同时,与 Hive 类似,DataFrame 也支持嵌套数据类型(struct、array 和 map)。从 API易用性的角度上看,DataFrame API 提供的是一套高层的关系操作,比函数式的 RDD API 要更加友好,门槛更低。
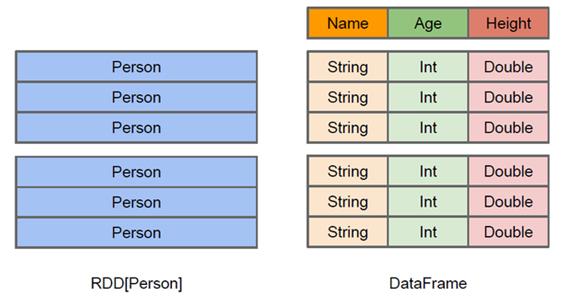
左侧的 RDD[Person]虽然以 Person 为类型参数,但 Spark 框架本身不了解 Person 类的内部结构。
而右侧的 DataFrame 却提供了详细的结构信息,使得 Spark SQL 可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。
DataFrame 是为数据提供了 Schema 的视图。可以把它当做数据库中的一张表来对待
DataFrame 也是懒执行的,但性能上比 RDD 要高,主要原因:优化的执行计划,即查询计划通过 Spark catalyst optimiser 进行优化。
DataSet
DataSet 是分布式数据集合。DataSet 是 Spark 1.6 中添加的一个新抽象,是 DataFrame的一个扩展。
它提供了 RDD 的优势(强类型,使用强大的 lambda 函数的能力)以及 SparkSQL 优化执行引擎的优点。DataSet 也可以使用功能性的转换(操作 map,flatMap,filter等等)。
➢ DataSet 是 DataFrame API 的一个扩展,是 SparkSQL 最新的数据抽象
➢与RDD相比,保存了更多的描述信息,概念上等同于关系型数据库中的二维表。
➢ 用户友好的 API 风格,既具有类型安全检查也具有 DataFrame 的查询优化特性;
➢ 用样例类来对 DataSet 中定义数据的结构信息,样例类中每个属性的名称直接映射到DataSet 中的字段名称;
➢与DataFrame相比,DataSet 保存了类型信息, 是强类型的。比如可以有 DataSet[Car],DataSet[Person],提供了编译时类型检查。
➢ DataFrame 是 DataSet 的特列,DataFrame=DataSet[Row] ,所以可以通过 as 方法将DataFrame 转换为 DataSet。Row 是一个类型,跟 Car、Person 这些的类型一样,所有的表结构信息都用 Row 来表示。获取数据时需要指定顺序
引用:Spark中DataSet的基本使用
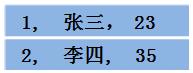
1.假设RDD中的两行数据长这样:
2.那么DataFrame中的数据长这样
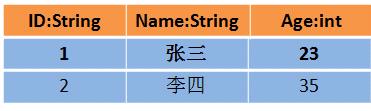
RDD中没有schema信息,而DataFrame中数据每一行都包含schema
DataFrame = RDD[Row] + shcema
RDD 转 DataFrame 实际就是加上结构信息
DataFrame 转换为普通RDD 就比较简单了,直接去掉结构信息就行了,但是转换不回原来结构,直接转为RDD[row]类型了
3.那么Dataset中的数据长这样(每行数据是个Object):
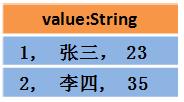
或者长这样(每行数据是个Object):

DataSet包含了DataFrame的功能,Spark2.0中两者统一,DataFrame表示为DataSet[Row],即DataSet的子集。
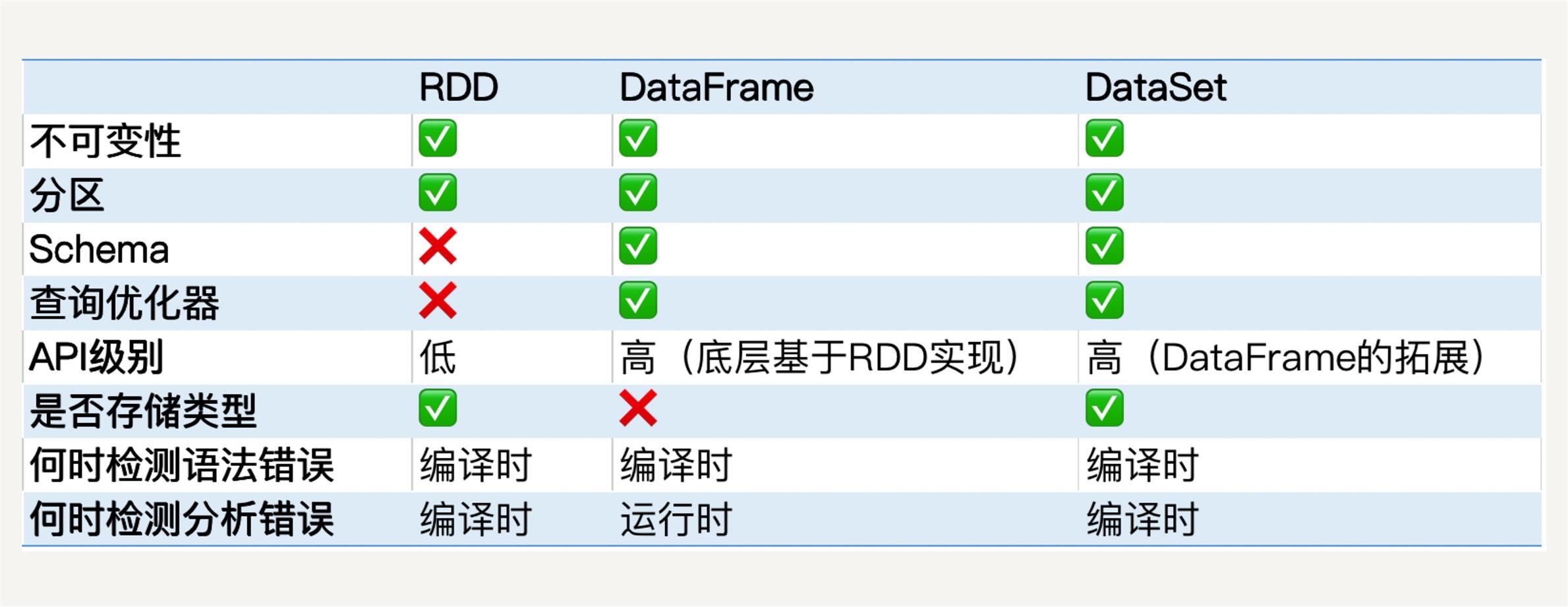
RDD、DataFrame、DataSet的区别
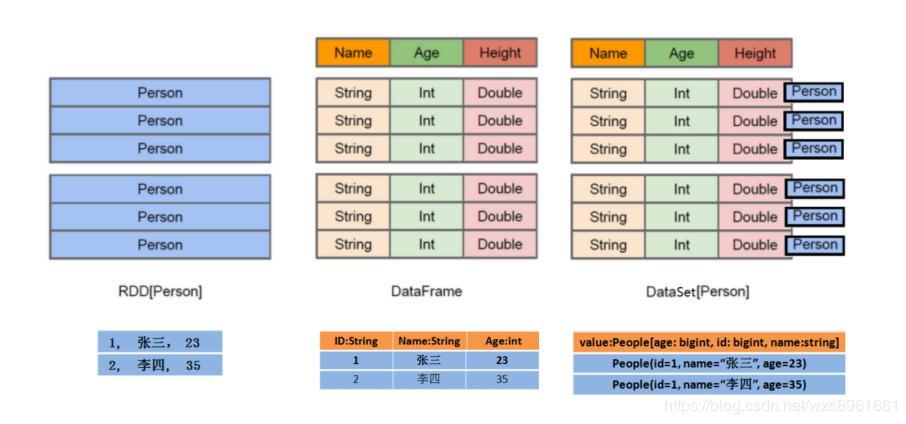
(1)RDD[Person]以Person为类型参数,但不了解其内部结构。
(2)DataFrame提供了详细的结构信息schema列的名称和类型。这样看起来就像一张表了
(3)DataSet[Person]中不光有schema信息,还有类型信息
以上是关于Spark SQL 浅学笔记2的主要内容,如果未能解决你的问题,请参考以下文章