Phoenix实践 —— Phoenix SQL常用基本语法总结小记
Posted 扫地增
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Phoenix实践 —— Phoenix SQL常用基本语法总结小记相关的知识,希望对你有一定的参考价值。
详细语法参见官网语法这里只给出常用的一些语法
Phoenix Shell常用的命令操作
!table --查看表信息
!describe tablename --可以查看表字段信息
!history --可以查看执行的历史SQL
!dbinfo
!index tb; --查看tb的索引
!quit; --退出phoenix shell
help --查看其他操作
HDFS数据直接导入到表中的操作
hadoop jar /home/phoenix-4.12/phoenix-4.6.0-HBase-1.0-client.jar org.apache.phoenix.mapreduce.CsvBulkLoadTool -t POPULATION -i /datas/us_population.csv
-t :tableName
-i: input file 文件必须在hdfs文件上。
Phoenix SQL常用的Schema操作
配置schema保存namespace映射
在
Phoenix中是没有Database的概念的,所有的表都在同一个命名空间。但支持多个命名空间,在hbase-site.xml中进行下面参数设置为true,创建的带有schema的表将映射到一个namespace。
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
</property>
创建schema:(CREATE SCHEMA)

在
HBase中创建Schema和相应的名称空间。执行此命令的用户应具有管理员权限才能在中创建HBase名称空间。
--如果存在就不创建
CREATE SCHEMA IF NOT EXISTS my_schema;
--创建SCHEMA
CREATE SCHEMA my_schema;

此操作仅在
shell中支持在可视化工具客户端中不支持。
切换schema:(USE SCHEMA_NAME)

use default;
use schema_name;
删除Schema:(DROP SCHEMA)
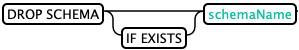
从
HBase删除模式和相应的名称空间。要启用名称空间映射,仅当架构不包含任何表时,此语句才会成功。
--存在删除SCHEMA
DROP SCHEMA IF EXISTS my_schema
--删除SCHEMA
DROP SCHEMA my_schema
Phoenix SQL的权限管理操作
赋予权限:(GRANT)

权限级别:
R-读取,W-写入,X-执行,C-创建,A-管理员,要启用/禁用访问控制,请参阅hbase配置。
应在基表上授予权限。它将传播到其所有索引和视图。组权限适用于组中的所有用户,架构权限适用于具有该架构的所有表。未指定表/架构的授予语句在GLOBAL级别上分配。
Phoenix不会向最终用户公开Execute('X')功能。但是,具有辅助索引的可变表是必需的。
GRANT 'RXC' TO 'User1'--为User1添加读、执行、创建权限
GRANT 'RWXC' TO GROUP 'Group1'--为Group1添加读、写、执行、创建权限
GRANT 'A' ON Table1 TO 'User2' --给用户User2添加Table1管理权限
GRANT 'RWX' ON my_schema.my_table TO 'User2'--为User2添加my_schema.my_table的读、写、执行权限
GRANT 'A' ON SCHEMA my_schema TO 'User3'--为User3添加my_schema添加管理权限
取消权限:(REVOKE)

- 撤消表、
schema或用户级别的权限。权限由HBase hbase:acl表中的管理,因此需要启用访问控制。Phoenix 4.14版及更高版本将提供此功能。要启用/禁用访问控制,请参阅hbase配置。- 组权限适用于组中的所有用户,
schema权限适用于具有该schema的所有表。应该撤消对基表的许可。它将传播到其所有索引和视图。未指定表/schema的吊销语句在GLOBAL级别分配。- 撤消将删除该级别的所有权限。
- 撤消权限必须与通过“授予权限”语句分配的权限完全相同。级别是指表,
schema或用户。撤销任何RXPhoenix SYSTEM表上的任何' '权限都将导致异常。撤消任何' RWX'权限,SYSTEM.SEQUENCE将导致在访问序列时发生异常。
以下示例用于撤消使用上述GRANT语句中的示例授予的权限。
REVOKE FROM 'User1'--撤销User1读、执行、创建权限
REVOKE FROM GROUP 'Group1'--撤销Group1权限
REVOKE ON Table1 FROM 'User2'--撤销User2的Table1权限
REVOKE ON my_schema.my_table FROM 'User2'--撤销User2对my_schema.my_table的权限
REVOKE ON SCHEMA my_schema FROM 'User3'--撤销User3对my_schema的权限
Phoenix SQL常用的表操作:
展示表:(list对应语法)
!table或者!tables
创建表:(CREATE TABLE)
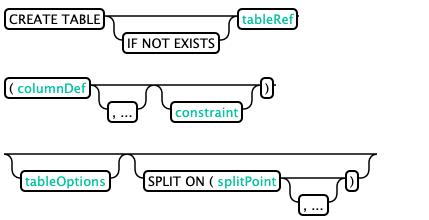
Hbase是区分大小写的,Phoenix默认会把sql语句中的小写转换成大写,再建表,如果不希望转换,需要将表名,字段名等使用引号。
Hbase默认phoenix表的主键对应到ROW,column family名为0,也可以在建表的时候指定column family。
--表名,列族名默认大写在,指定列族主键
CREATE TABLE IF NOT EXISTS my_schema.population (
State CHAR(2) NOT NULL,
City VARCHAR NOT NULL,
Population BIGINT
CONSTRAINT my_pk PRIMARY KEY (state, city));
在
phoenix中,默认情况下,表名等会自动转换为大写,若要小写,使用双引号,如"population"。
创建加盐表(SALT_BUCKETS(加盐))
加盐
Salting能够通过预分区(pre-splitting)数据到多个region中来显著提升读写性能。本质是在hbase中,rowkey的byte数组的第一个字节位置设定一个系统生成的byte值,这个byte值是由主键生成rowkey的byte数组做一个哈希算法,计算得来的。Salting之后可以把数据分布到不同的region上,这样有利于phoenix并发的读写操作。SALT_BUCKETS的值范围在(1 ~ 256)。
--创建加盐表
create table test
(
host varchar not null primary key,
description varchar
)
salt_buckets=16;
--更新加盐表
upsert into test (host,description) values ('192.168.0.1','s1');
upsert into test (host,description) values ('192.168.0.2','s2');
upsert into test (host,description) values ('192.168.0.3','s3');
salted table可以自动在每一个rowkey前面加上一个字节,这样对于一段连续的rowkeys,它们在表中实际存储时,就被自动地分布到不同的region中去了。当指定要读写该段区间内的数据时,也就避免了读写操作都集中在同一个region上。简而言之,如果我们用Phoenix创建了一个saltedtable,那么向该表中写入数据时,原始的rowkey的前面会被自动地加上一个byte(不同的rowkey会被分配不同的byte),使得连续的rowkeys也能被均匀地分布到多个regions。
设置预分区:(Pre-split(预分区))
Salting能够自动的设置表预分区,但是你得去控制表是如何分区的,所以在建phoenix表时,可以精确的指定要根据什么值来做预分区,比如:
create table test
(
host varchar not null primary key,
description varchar
)
split on ('cs','eu','na');
使用多列族
列族包含相关的数据都在独立的文件中,在
Phoenix设置多个列族可以提高查询性能。创建两个列族:
--建立多列族表
create table test_colunms
(
mykey varchar not null primary key,
a.col1 varchar,
a.col2 varchar,
b.col3 varchar
);
--更新记录
upsert into test_colunms values ('key1','a1','b1','c1');
upsert into test_colunms values ('key2','a2','b2','c2');
使用压缩
create table test
(
host varchar not null primary key,
description varchar
)
compression='snappy';
其他
建表语句中,还可以附加一些
HBase表、列族配置选项,如DATA_BLOCK_ENCODING、VERSIONS、MAX_FILESIZE 、TTLetc。具体的设置值还需要大家去进一步了解。
--DATA_BLOCK_ENCODING、VERSIONS、MAX_FILESIZE的使用
CREATE TABLE IF NOT EXISTS "my_case_sensitive_table"(
"id" char(10) not null primary key,
"value" integer)
DATA_BLOCK_ENCODING='NONE',
VERSIONS=5,
MAX_FILESIZE=2000000 split on (?, ?, ?)
--TTL的使用
CREATE TABLE IF NOT EXISTS my_schema.my_table (
org_id CHAR(15),
entity_id CHAR(15),
payload binary(1000),
CONSTRAINT pk PRIMARY KEY (org_id, entity_id) )
TTL=86400
删除表:(DROP TABLE)

删除表,可选使用
CASCADE关键字,他会导致删除表上建立的所有视图。删除表时,默认情况下HBase会删除基础数据表和索引表。配置phoenix.schema.dropMetaData可以用于改变默认配置在删除时不会删除数据并保留HBase表以进行时间点查询。
--直接删除
drop table my_schema.population;
--如果表存在就删除
drop table if exists my_schema.population;
--删除表的同时删除表上建立的所有视图
drop table my_schema.population cascade;
查询记录:(SELECT)
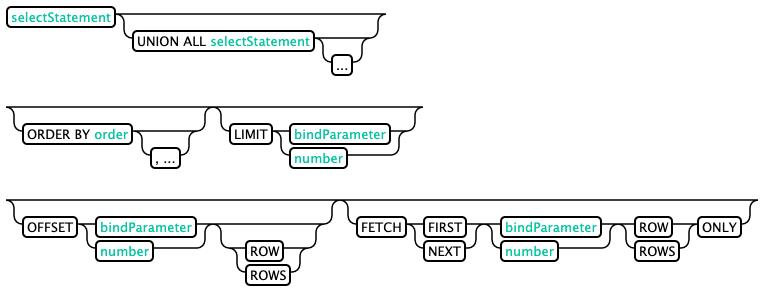
Phoenix的SELECT语法union all,group by,order by,limit (offset first与limit相同),offset都支持。
--查询结果保留1000条
select * from test limit 1000;
--返回结果100-1000,Offset跳过返回结果之前的前n行
select * from test limit 3 offset 2;
select * from test limit 3 offset 1;
--union all
select full_name from sales_person where ranking >= 5.0
union all
select reviewer_name from customer_review where score >= 8.0
插入记录:(UPSERT)
在
Phoenix中是没有Insert语句的,取而代之的是Upsert语句。Upsert有两种用法,分别是:upsert into和upsert select。
UPSERT VALUES

类似于
insert into的语句,旨在单条插入外部数据
--不加字段信息
upsert into my_schema.population values('BJ','BeiJing',8143197);
--加字段信息
upsert into my_schema.population(State,City,population) values('SZ','ShenZhen',6732422);
UPSERT SELECT

类似于
Hive中的insert select语句,旨在批量插入其他表的数据。
--带字段插入
upsert into population (state,city,population) select state,city,population from tb2 where population < 7000000;
--不带字段插入
upsert into population select state,city,population from tb2 where population > 7000000;
--支持select *
upsert into population select * from tb2 where population > 7000000;
在
phoenix中插入语句并不会像传统数据库一样存在重复数据。因为Phoenix是构建在HBase之上的,也就是必须存在一个主键。后面插入的会覆盖前面的,但是时间戳不一样。
修改记录:
由于
HBase的主键设计,相同rowkey的内容可以直接覆盖,这就变相的更新了数据。所以Phoenix的更新操作仍旧是upsert into和upsert select。实例同上插入记录。
删除记录:(DELETE)
delete from population; #清空表中所有记录,Phoenix中不能使用truncate table tb;
delete from my_schema.population where city = 'LinYin';#删除表中城市为kenai的记录
delete from system.catalog where table_name = 'int_s6a';#删除system.catalog中table_name为int_s6a的记录
以上是关于Phoenix实践 —— Phoenix SQL常用基本语法总结小记的主要内容,如果未能解决你的问题,请参考以下文章
Phoenix&HBase实践——Phoenix+HBase结合实践操作总结
Phoenix 实践——Phoenix 表的视图构建(表映射)总结小记
Phoenix实践——Phoenix配置支持二级索引和使用小记