SIGIR 2021 | 广告系统位置偏差的CTR模型优化方案
Posted 美团技术团队
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SIGIR 2021 | 广告系统位置偏差的CTR模型优化方案相关的知识,希望对你有一定的参考价值。

总第457篇
2021年 第027篇

美团到店广告平台算法团队基于多年来在广告领域上积累的经验,一直在数据偏差等业界挑战性问题不断进行深入优化与算法创新。在之前分享的《KDD Cup 2020 Debiasing比赛冠军技术方案与广告业务应用》一文[4]中,团队分享了在KDD Cup比赛中取得冠军的选择性偏差以及流行度偏差的解决方案,同时也分享了在广告业务上偏差优化的技术框架。
本文基于这一技术框架进行继续介绍,聚焦于位置偏差问题的最新进展,并详细地介绍团队在美团广告取得显著业务效果的位置偏差CTR模型优化方案,以该方案为基础形成的论文《Deep Position-wise Interaction Network for CTR Prediction》也被国际顶级会议SIGIR 2021录用。
1. 背景
2. 深度位置交叉网络(Deep Position-wise Interaction Network)
2.1 基础模块(Base Module)
2.2 深度位置交叉模块(Deep Position-wise Interaction Module)
2.3 位置组合模块(Position-wise Combination Module)
3. 实验
3.1 实验设置
3.2 离线评估
3.3 服务性能
3.4 在线评估
4. 总结与展望
近些年来,由于人工智能技术的高速发展,所带来的公平性问题也愈发受到关注。同样的,广告技术也存在着许多公平性问题,由于公平性问题造成的偏差对广告系统的生态会产生较大的负面影响。图1所示的是广告系统中的反馈环路[1],广告系统通过累积的用户交互反馈数据基于一定的假设去训练模型,模型对广告进行预估排序展示给用户,用户基于可看到的广告进行交互进而累积到数据中。在该环路中,位置偏差、流行度偏差等各种不同类型的偏差会在各环节中不断累积,最终导致广告系统的生态不断恶化,形成“强者愈强、弱者愈弱”的马太效应。

由于偏差对广告系统和推荐系统的生态有着极大的影响,针对消除偏差的研究工作也在不断增加。比如国际信息检索会议SIGIR在2018年和2020年组织了一些关注于消除偏差主题的专门会议,同时也给一些基于偏差和公平性的论文颁发了最佳论文奖(Best Paper)[2,3]。KDD Cup 2020的其中一个赛道也基于电子商务推荐中的流行度偏差进行开展[1]。
1. 背景
美团到店广告平台广告算法团队基于美团和点评双侧的广告业务场景,不断进行广告前沿技术的深入优化与算法创新。在大多数广告业务场景下,广告系统被分为四个模块,分别是触发策略、创意优选、质量预估以及机制设计,这些模块构成一个广告投放漏斗从海量广告中过滤以及精选出优质广告投放给目标用户。其中,触发策略从海量广告中挑选出满足用户意图的候选广告集合,创意优选负责候选广告的图片和文本生成,质量预估结合创意优选的结果对每一个候选广告进行质量预估,包括点击率(CTR)预估、转化率(CVR)预估等,机制排序结合广告质量以及广告出价进行优化排序。在本文中,我们也将广告称之为item。
CTR预估,作为质量预估的一个环节,是计算广告中最核心的算法之一。在每次点击付费(CPC)计费模式下,机制设计可以简单地按每千次展示收入(eCPM)来对广告进行排序以取得广告收入最大化。由于eCPM正比于CTR和广告出价(bid)的乘积。因此,CTR预估会直接影响到广告的最终收入和用户体验。为了有更高的CTR预估精度,CTR预估从早期的LR[5]、FM[6]、FFM[7]等支持大规模稀疏特征的模型,到XGBoost[8]、LightGBM[9]等树模型的结合,再到Wide&Deep[10]、Deep&Cross[11]、DeepFM[12]、xDeepFM[13]等支持高阶特征交叉的深度学习模型,进一步演化到DIN[14]、DIEN[15]、DSIN[16]等结合用户行为序列的深度学习模型,一直作为工业界以及学术界研究的热点领域之一,被不断探索和不断创新。
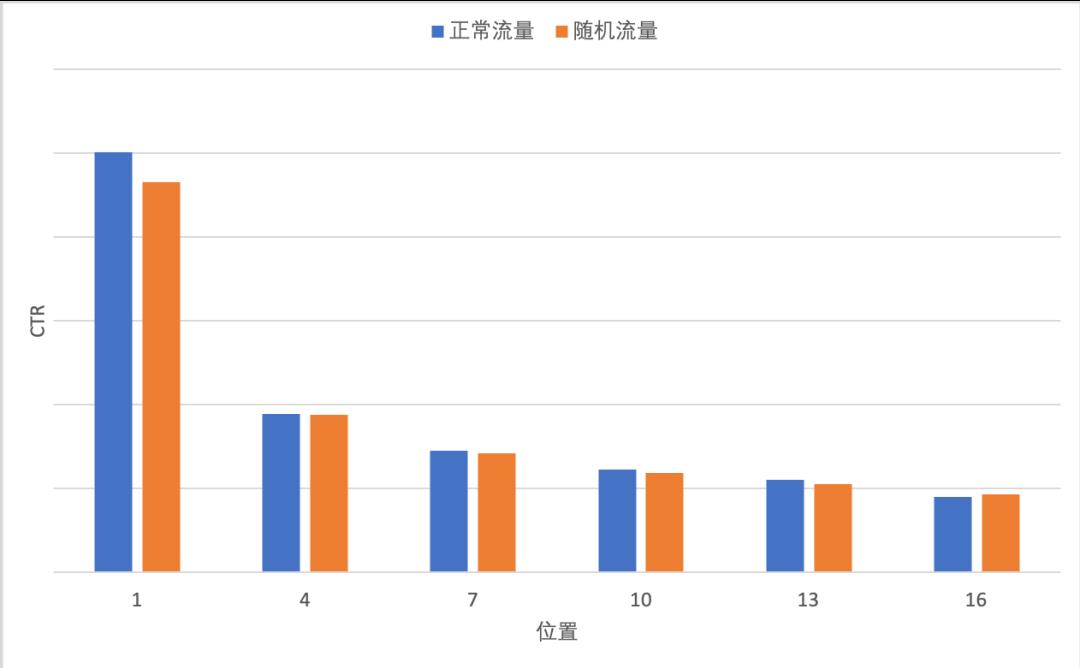
由于CTR预估模型的训练通常采用曝光点击数据,该数据是一种隐式反馈数据,所以会不可避免地产生各种偏差问题。其中,位置偏差因对CTR影响极大而备受关注。如图2所示,随机流量上不同位置的CTR分布反应了用户通常倾向于点击靠前位置的广告,并且CTR会随着曝光位置的增大而迅速下降。因此,直接在曝光点击数据上进行训练,模型不可避免地会偏向于靠前位置的广告集合,造成位置偏差问题。图2显示正常流量相比随机流量CTR分布更加集中在高位置广告上,通过反馈环路,这一问题将不断地放大,并且进一步损害模型的性能。因此,解决好位置偏差问题不仅能够提升广告系统的效果,而且还能平衡广告系统的生态,促进系统的公平性。
广告最终的真实曝光位置信息在线上预估时是未知的,这无疑进一步增大了位置偏差问题的解决难度。现有的解决位置偏差的方法可以大致分为以下两种:
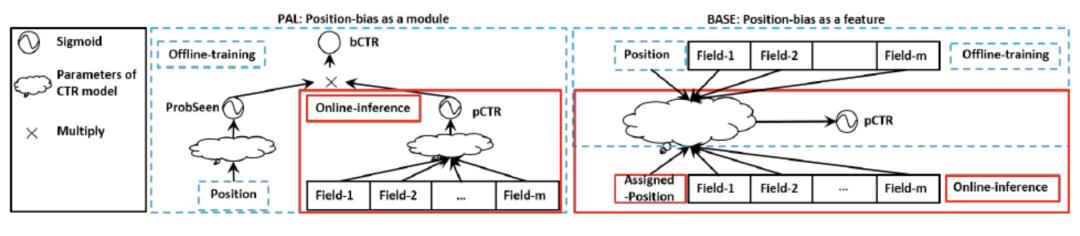
神经网络位置特征建模:该方法将位置建模为神经网络中的特征,由于在预估过程中并不知道真实位置信息,故而有些方法[17-19]把位置信息放于网络的Wide部分,在线下训练时使用真实位置,在线上预估时使用固定位置,这种方法由于其简单性和有效性,在工业界被广泛应用。为了在线上预估时无需使用位置信息,如图3所示,PAL[20]将样本的CTR建模为ProbSeen乘以pCTR,其中ProbSeen仅使用位置特征建模,而pCTR使用其他信息建模,在线上只使用pCTR作为CTR预估值。
Inverse Propensity Weighting(IPW):该方法被学术界广泛研究[21-29],其在模型训练时给不同曝光位置的样本赋予不同的样本权重,直观地看,应该将具有较低接收反馈倾向的广告样本(曝光位置靠后的广告)分配较高的权重。因此,这种方法的难点就在于不同位置的样本权重如何确定,一个简单的方法是使用广告随机展示的流量来准确地计算位置CTR偏差,但不可避免地损害用户体验。故而,许多方法致力于在有偏的流量上来准确地预估位置偏差。
上述的方法通常基于一个较强的假设,即点击伯努利变量 依赖于两个潜在的伯努利变量E和 ,如下式所示:
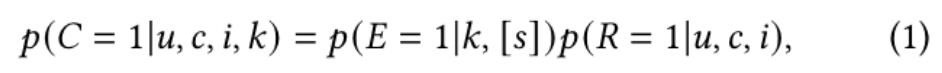
其中,等式左边指的是用户 在上下文 中点击第 个广告 的概率,我们定义上下文 为实时的请求信息。等式右边第一项指的是位置 被查看的概率,其中 通常为上下文 的一个子集,大部分方法假设 为空集,即位置 被查看的概率仅与 有关。等式右边第二项指的是相关性概率(例如用户 在上下文 中对广告 的的真实兴趣)。上述方法通常显式或隐式地估计查看概率,然后利用反事实推理(Counterfactual Inference)得出相关性概率,最终在线上将相关性概率作为CTR的预估值。训练和预估之间位置信息的不同处理将不可避免地导致线下线上间的不一致问题,进一步导致次优的模型性能。
此外,已有方法通常假设查看概率仅依赖于位置及部分上下文信息,其假设过于简单。不同的用户通常具有不同的浏览习惯,有些用户可能倾向于浏览更多item,而有些用户通常能快速做出决定,并且同一个用户在不同的上下文中搜索意图中也会有不同的位置偏好,例如商场等地点词的搜索往往意图不明确导致高低位置的CTR差异并不大。故而,位置偏差与用户,上下文有关,甚至可能与广告本身也有关,建模它们间的关系能更好地解决位置偏差问题。
不同于上述的方法,本文提出了一个基于深度位置交叉网络(Deep Position-wise Interaction Network)(DPIN)模型的多位置预估方法去有效地直接建模 来提高模型性能,其中 是第 个广告在第 个位置的CTR预估值。该模型有效地组合了所有候选广告和位置,以预估每个广告在每个位置的CTR,实现线下线上的一致性,并在在线服务性能限制的情况下支持位置、用户、上下文和广告之间的深度非线性交叉。广告的最终序可以通过最大化 来确定,其中 为广告的出价,本文在线上机制采用一个位置自顶向下的贪婪算法去得到广告的最终序。本文的贡献如下:
本文在DPIN中使用具有非线性交叉的浅层位置组合模块,该模块可以并行地预估候选广告和位置组合的CTR,达到线下线上的一致性,并大大改善了模型性能。
不同于以往只对候选广告进行用户兴趣建模,本次首次提出对候选位置也进行用户兴趣建模。DPIN应用一个深度位置交叉模块有效地学习位置,用户兴趣和上下文之间的深度非线性交叉表示。
根据对于位置的新处理方式,本文提出了一种新的评估指标PAUC(Position-wise AUC),用于测量模型在解决位置偏差问题上的模型性能。本文在美团广告的真实数据集上进行了充分的实验,验证了DPIN在模型性能和服务性能上都能取得很好的效果。同时本文还在线上部署了A/B Test,验证了DPIN与高度优化的已有基线相比有显著提升。
2. 深度位置交叉网络(Deep Position-wise Interaction Network)
本节主要介绍深度位置交叉网络(Deep Position-wise Interaction Network)(DPIN)模型。如图4所示,DPIN模型由三个模块组成,分别是处理 个候选广告的基础模块(Base Module),处理 个候选位置的深度位置交叉模块(Deep Position-wise Interaction Module)以及组合 个广告和 个位置的位置组合模块(Position-wise Combination Module),不同模块需预估的样本数量不一样,复杂模块预估的样本数量少,简单模块预估的样本数量多,由此来提高模型性能和保障服务性能。通过这三个模块的组合,DPIN模型有能力在服务性能的限制下预估每个广告在每个位置上的CTR,并学习位置信息和其他信息的深度非线性交叉表示。下文将会详细地介绍这三个模块。
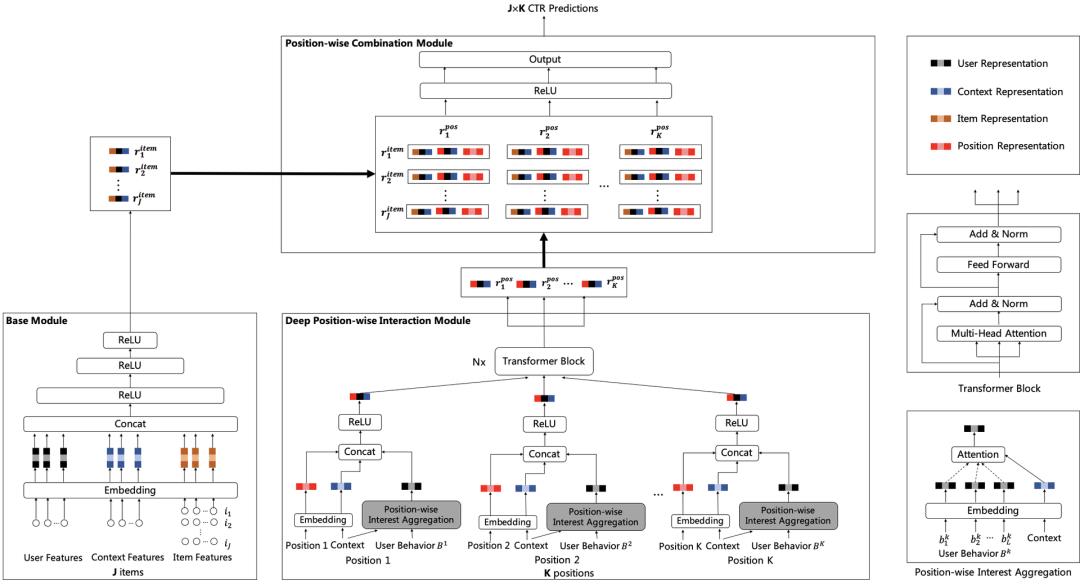
2.1 基础模块(Base Module)
与大多数深度学习CTR模型[10-16]类似,本文采用Embedding和MLP(多层感知机)的结构作为基础模块。对于一个特定请求请求,基础模块将用户、上下文和 个候选广告作为输入,将每个特征通过Embedding进行表示,拼接Embedding表示输入多层MLP,采用ReLU作为激活函数,最终可以得到每个广告在该请求下的表示。第 个广告的表示 可以通过如下公式得到:
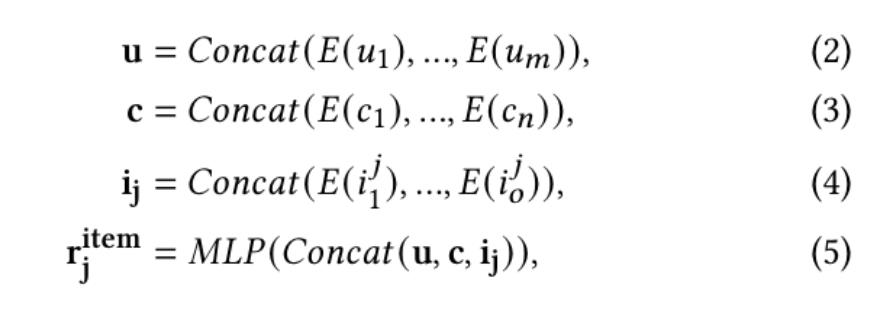
其中