太硬核了!这篇HashMap源码分析,绝对可以堪称为圣经
Posted Java德克士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了太硬核了!这篇HashMap源码分析,绝对可以堪称为圣经相关的知识,希望对你有一定的参考价值。
一、前言
本篇是继硬核ArrayList源码分析,答应我每天看一遍好么之后进行的第二篇源码分析;学完本篇你将对hashMap的结构和方法有个全面的了解;面试自己有多强,超人都不知道;比如HashMap的扩容机制,最大容量是多少,HashMap链表是如何转到红黑树,HashMap为什么线程不安全,HashMap的key,value是否能null值等等;
二、源码分析
2.1 官方说明实践
- 官方说**HashMap实现了Map接口,拥有所有的Map操作;并且允许key,value都为null;**实践一下是不是这样子;
public static void main(String[] args) {
HashMap<String, Object> map = new HashMap<>();
map.put(null,null);
System.out.println(map);//{null=null}
}
果然如此没有报错;再加一个null的key和value看看;不贴代码了,最终输出还是一个{null=null};说明HashMap的key是唯一的;?怎么保证key唯一后面继续分析;
- 继续看官方说明,HashMap与HashTable不同之处是,HashMap不同步,HashTable不允许key,value为null;实践一下
public static void main(String[] args) {
Hashtable hashtable = new Hashtable();
hashtable.put(null,null);
}
控制台红了啊!!!输出内容如下,震惊,HashTable的key,value真的不能为null;
{null=null}Exception in thread "main"
java.lang.NullPointerException
at java.util.Hashtable.put(Hashtable.java:459)
at test.HashMapTest.main(HashMapTest.java:17)
Process finished with exit code 1
点击源码看看,HashTable的put方法特大号的Make开头确保key,value不能为null,synchronized修饰;人生值得怀疑一下,因为知识追寻者以前都没用过Hashtable耍代码;
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
- 继续看官方说明,HashMap无法保证Map中内容的顺序;再次动手实践一下,如果如此,到底啥原有让map顺序不一致呢?后续分析
public static void main(String[] args) {
HashMap<String, Object> map = new HashMap<>();
map.put("清晨","娃哭了");
map.put("中午","娃饿了");
map.put("晚上","娃不想睡觉了");
System.out.println(map);//{中午=娃饿了, 晚上=娃不想睡觉了, 清晨=娃哭了}
}
后续的官方说明就不是单单能几句话可以描述得懂了,开胃菜完毕,还是看看具体的源码吧,复习的时候记得看下小技巧Tip;
Tip:
HashMap允许key和value都为null;key具有唯一性;
HashMap与HashTable不同之处是,HashMap不同步,HashTable不允许key,value为null;
HashMap无法保证Map中内容的顺序
2.2 空参构造方法分析
测试代码
public static void main(String[] args) {
HashMap<String, Object> map = new HashMap<>();
}
构造方法源码如下,发行HashMap 的加载因子loadFactor 的值是默认值0.75;
public HashMap() {//默认因子DEFAULT_LOAD_FACTOR=0.75;初始化容量为16
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
走了一遍父类如下
HashMap --> AbstractMap --> Object
看下HashMap的父类图谱,结构倒是很简单对吧;
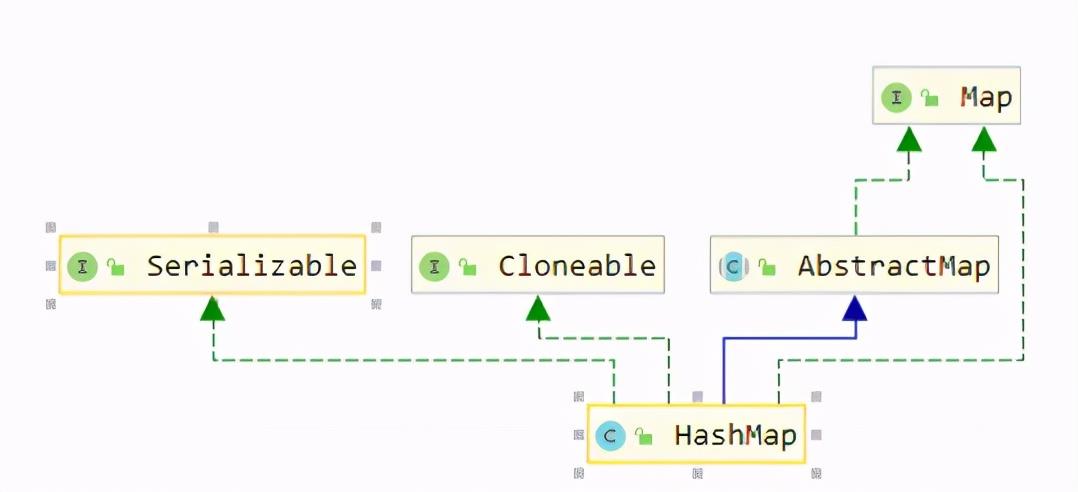
看到这边,知识追寻者有2个疑问
问题一 : 负载因子0.75是什么?
问题二:初始化容量16在哪里?
先回答一下初始化容量16问题,知识追寻者找到成员变量,默认初始化容量字段值为16;而且默认初始化值必须是2的倍数;
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16默认的初始化容量
回答负载因子0.75是指HashMap的一个扩容机制;比如 扩容因子是0.7,假设容量为10;当插入的数据达到第10*0.7 = 7 时就会发生扩容;那么知识追寻者再计算一下HashMap的扩容算法,0.75 * 16 = 12;那么也就是插入12 个数之后HashMap会发生扩容;
Tip: HashMap默认因子0.75;初始化容量16;若给定初始化容量为12,插入12个数之后再插入数据会发生扩容;
2.3 HashMap实现原理分析
官方源码的说明如下:HashMap的实现是由桶和哈希表实现,当桶的容量过于庞大时会转为树节点(与TreeMap类似,由于TreeMap底层是红黑树实现,故说桶转为红黑树也是对的);
抛出一个问题什么是桶?
回答桶之前我们先了解一下什么是哈希表(HashTable)
哈希表本质是一个链表数组;经过Hash算法计算后得出的int值找到数组上对应的位置;丢一张图给读者们看看;
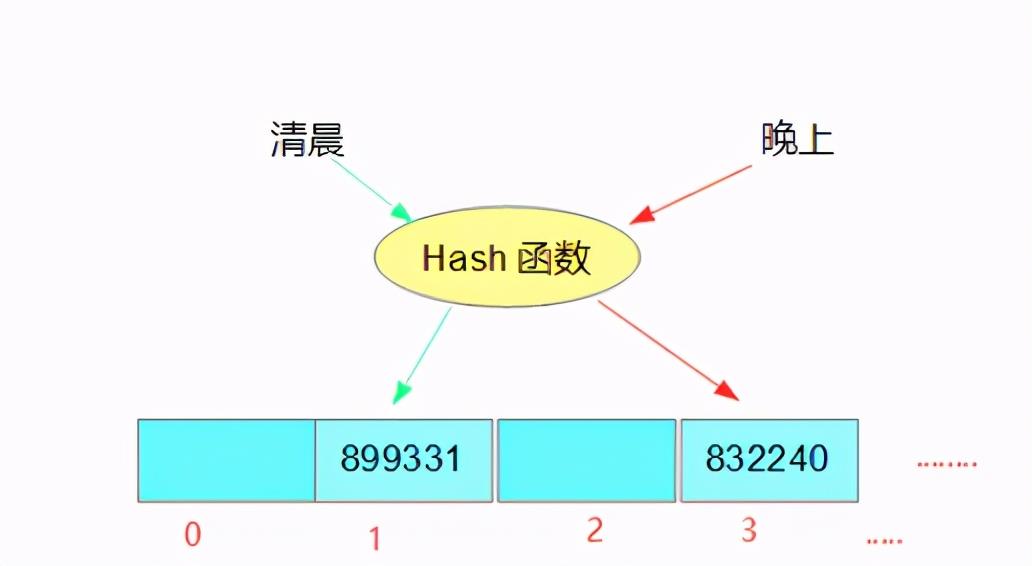
知识追寻者真是为读者操碎了心,再丢一个计算hash值的方法给你们;记得温习一下java基础String类的hashCode() 方法;若2个对象相同,hash值相同;若2个字符串内容相同(equals方法),hash值相同;
public static void main(String[] args) {
int hash_morning = Objects.hashCode("清晨");
int hash_night = Objects.hashCode("晚上");
System.out.println("清晨的hash值:"+hash_morning);//清晨的hash值:899331
System.out.println("晚上的hash值:"+hash_night);//晚上的hash值:832240
}
继续说我们的桶,一个桶就是一个链表中的每个节点,你也可以理解为一个下图中除了tab上的的entry ;看图
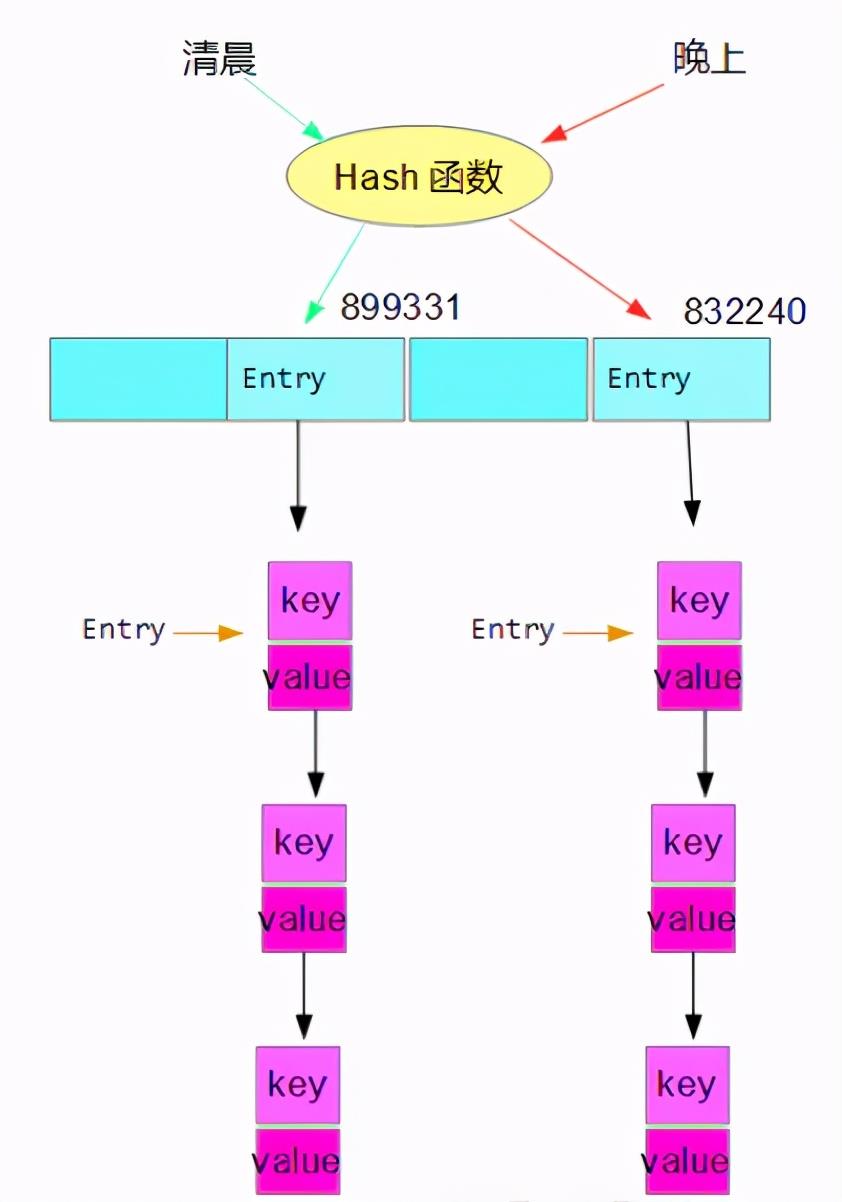
当桶的容量达到一定数量后就会转为红黑树,看图
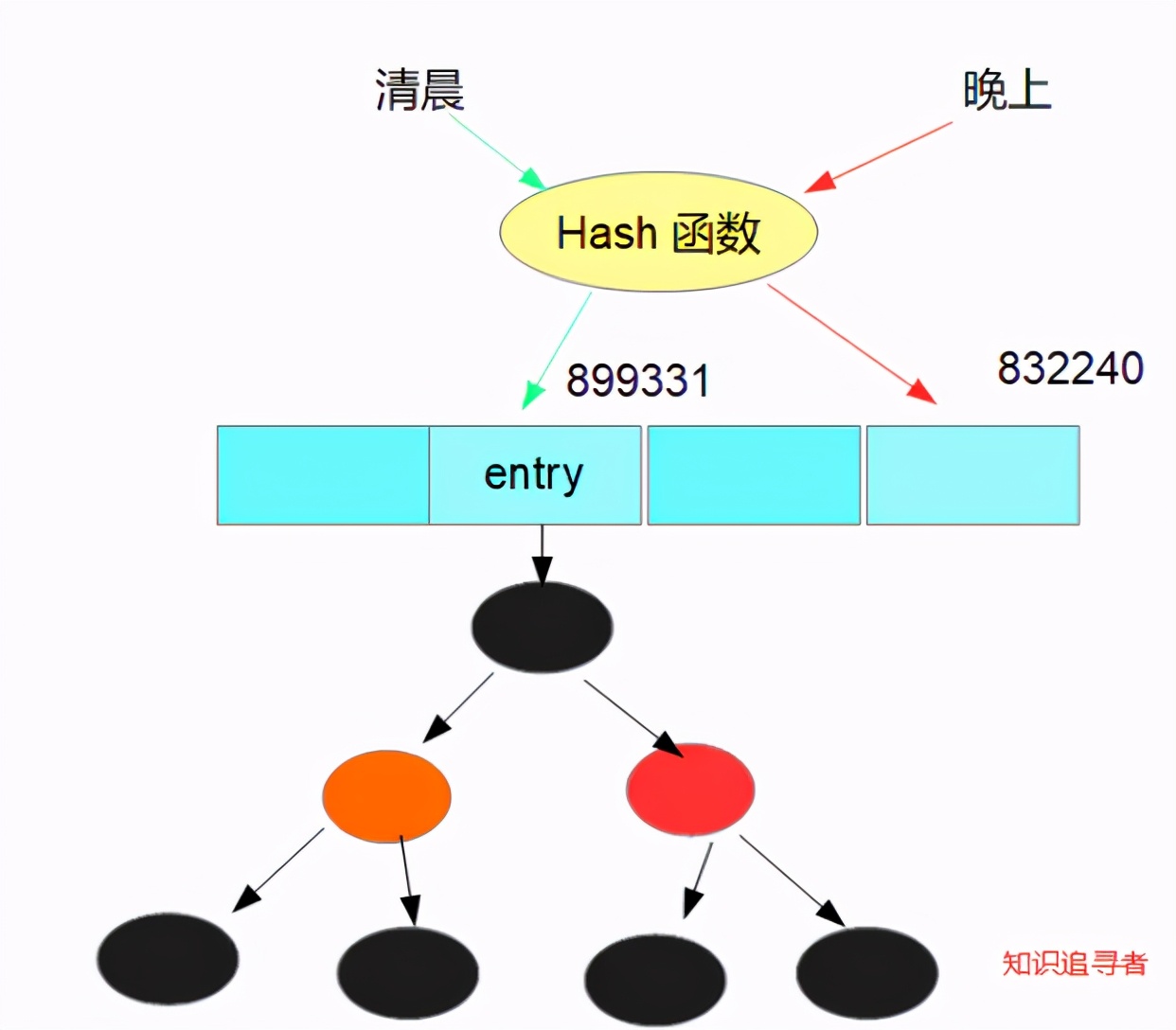
看到这边的读者肯定收获良多了,这还是开胃菜而已,进入我们今天的正题,源码分析篇;
2.4 put方法源码分析
测试代码
public static void main(String[] args) {
HashMap<String, Object> map = new HashMap<>();
map.put("清晨","娃哭了");
System.out.println(map);
}
首先进入的是put方法里面包含了putVal方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);//
}
先对key进行了一次hash再作为putVal里面的hash
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
看看putVal方法内容,因为只插入一个数据,索引为空的情况不会走else里面内容,知识追寻者这里省略了;
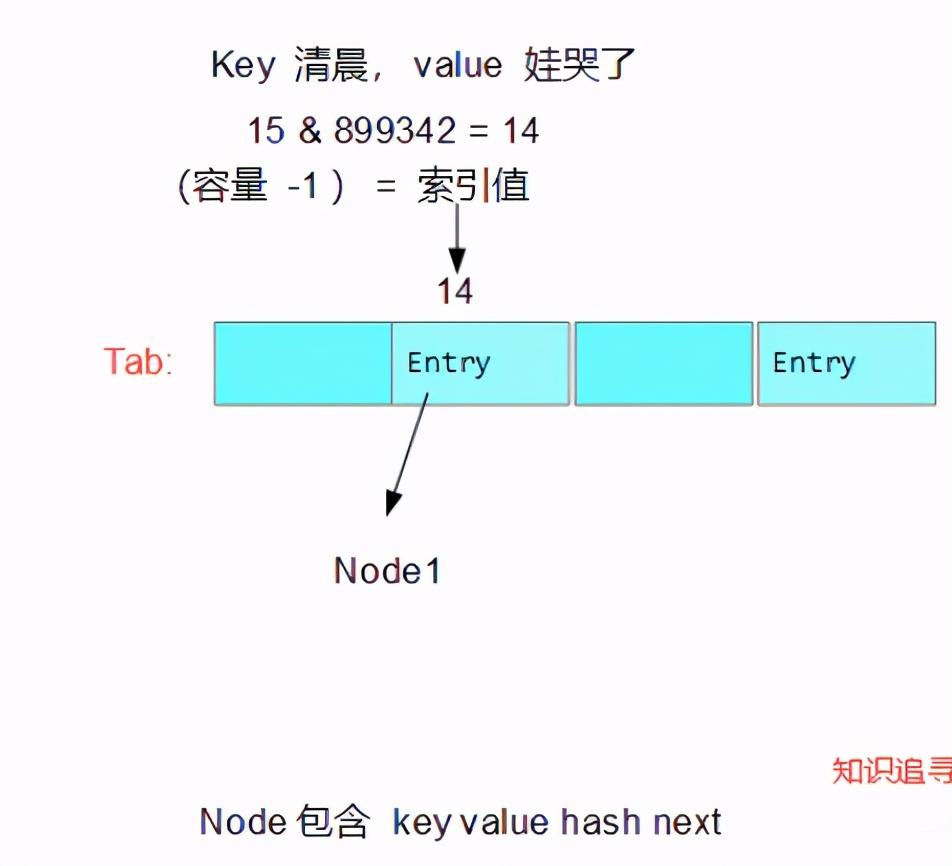
很清晰的可以看见创建了一个节点(Node<K,V>会在下面给出)放入了tab中,tab也很好理解,就是一个存放Node的列表;其索引 i = (容量 - 1) & hash值 , 本质上就是hash值拿去与的结果,所以是个哈希表;
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {//evict =true
Node<K,V>[] tab; Node<K,V> p; int n, i;// 声明 树数组, 树节点,n,i
if ((tab = table) == null || (n = tab.length) == 0)//table 为空
n = (tab = resize()).length; // resize()是 Node<K,V>[] resize() n 就是树的长度 根据初始容量就是 n=16
if ((p = tab[i = (n - 1) & hash]) == null) // i = (16-1) & hash ---> 15 & 899342 = 14 ;
tab[i] = newNode(hash, key, value, null);// 创建新节点,并插入数据
else {
.......
}
++modCount;//集合结构修改次数+1
if (++size > threshold)// size=1 ; threshold=12
resize();
afterNodeInsertion(evict);
return null;
}
这边做了个图记录一下
Node代码如下
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;//哈希值 key value异或的hash值
final K key;//键
V value;//值
Node<K,V> next;//存放下一个节点
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
...........
知识追寻者又加了一个晚上进去,跑过代码后转为图如下
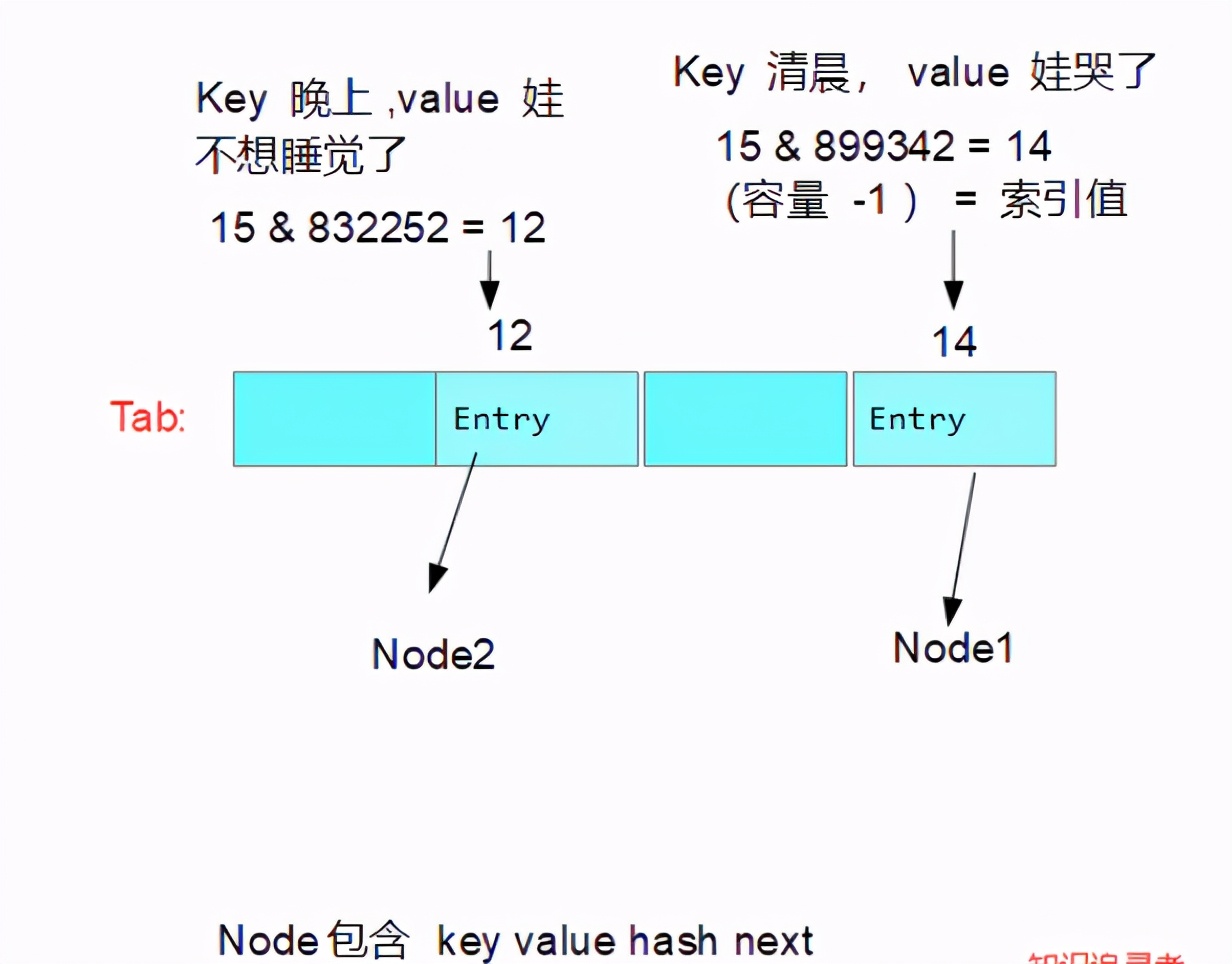
这么知识追寻者提出个想法,15的二进制是 1111 ,任何一个key ,value 的哈希值进行异或后得到Node的哈希值再与原来的1111相与 也就是取Node哈希值的二进制的后四位为准;tab的容量为16;存进去一个Node后 size 加1,最多也就是只能存储12个值就会发生扩容;这种情况下只要hash值相同就会发生碰撞,然后就会进入else方法,问题产生了,怎么构造2个一样的Node哈希值是个问题; 这边给出了示例如下:
参考链接:blog.csdn.net/hl_java/art…
public static void main(String[] args) {
System.out.println(HashMapTest.hash("Aa"));//2112
System.out.println(HashMapTest.hash("BB"));//2112
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
继续试验,发现 key的hash值相同后,会进入else方法,会在原来 AA 这个Node节点属性next添加一个节点存放Bb;哇塞这不就是实现了一个entry链表了么
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {//evict =true
Node<K,V>[] tab; Node<K,V> p; int n, i;// 声明 树数组, 树节点,n,i
if ((tab = table) == null || (n = tab.length) == 0)//table 为空
n = (tab = resize()).length; // resize()是 Node<K,V>[] resize() n 就是node的长度 根据初始容量就是 n=16
if ((p = tab[i = (n - 1) & hash]) == null) // i = (16-1) & hash ---> 15 & 哈希值
tab[i] = newNode(hash, key, value, null);// 创建新节点,并插入数据
else {
Node<K,V> e; K k; // 声明 node k
if (p.hash == hash && // p这个node 存放 Aa-->a ; hash 2112
((k = p.key) == key || (key != null && key.equals(k))))//这边key内容不相同所以没进入,故不是相同节点
e = p;
else if (p instanceof TreeNode)// 这边 p不是 TreeNode 故没转到红黑树加Node
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) { // 默认 桶的数量为0
if ((e = p.next) == null) { // 将p这个Node的下一个节点赋值给e为null;链表的开端哟
p.next = newNode(hash, key, value, null);// P创建节点存放BB--> b
// 其中 TREEIFY_THRESHOLD = 8
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);//树化
break;
}
if (e.hash == hash && //这边还是判定p和 e 是否是同一个Node
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;//key相同会新值会取代旧值
afterNodeAccess(e);
return oldValue;
}
}
++modCount;//集合结构修改次数+1
if (++size > threshold)// size=1 ; threshold=12
resize();
afterNodeInsertion(evict);
return null;
}
知识追寻者记录一下,原来key经过hash后如果hash值相同就会在形成一个链表,看代码也知道除了Tab上的第一个Entry,后面每一个Entry的Node都是一个桶;可以看见一个for循环是个无限循环,如果key的hash值相同次数达到8以后就会调用treeifyBin(tab, hash); 知识追寻者又理解了,只要桶的数量达到8后就会将链表节点树化;这就是 数组 + 链表(每个列表的节点就是一个桶) —> 数组 + 红黑树;为什么链表要转为红黑树呢,这就考虑到算法的效率问题,链表时间复杂度o(n),而红黑树的时间复杂度o(logn),树的查找效率更高;
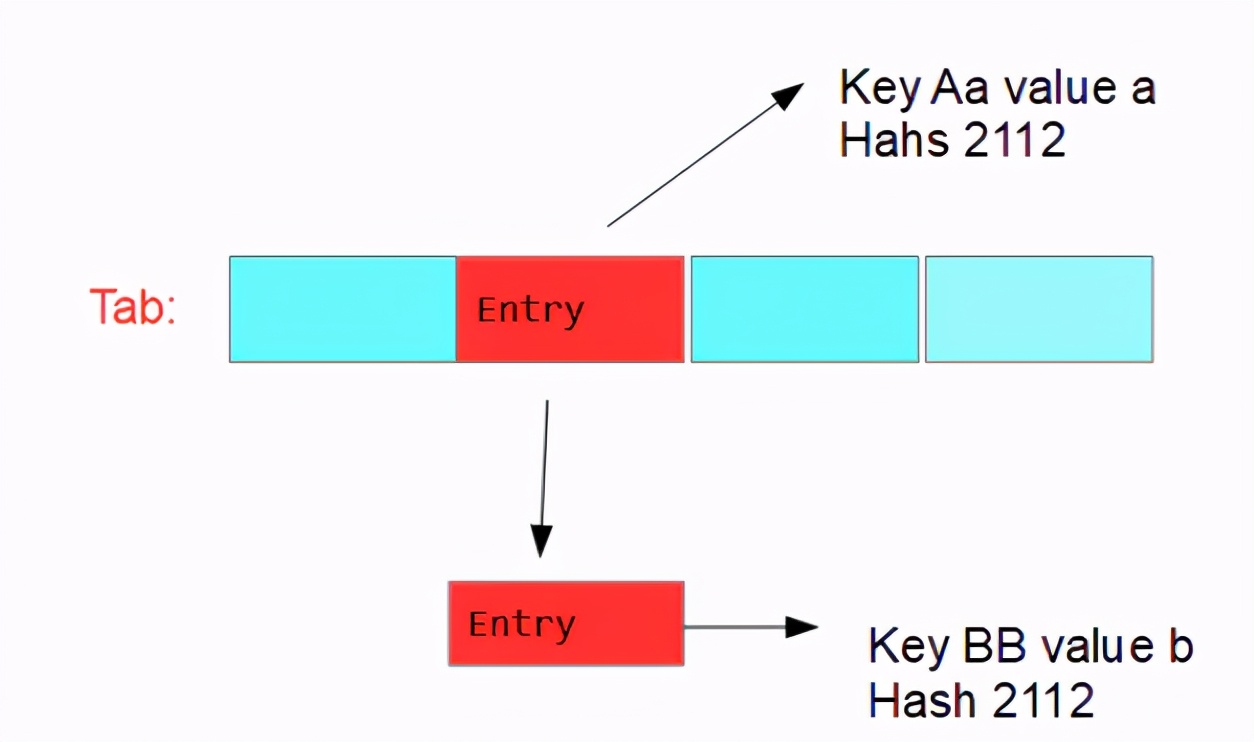
Tip : hashMap 本质是一串哈希表;哈希表首先由数组 + 链表组成;当hash碰撞后会形成链表,每个链表的节点又是一个桶;当桶的数量达到8之后就会进行树化,将链表转为红黑树,此时HashMap结构就是 数组 + 红黑树 ;如果插入相同的key,新的value会取代旧的value;
2.5 扩容源码分析
测试代码
public static void main(String[] args) {
HashMap<String, Object> map = new HashMap<>(12);
}
首先进入HashMap初始化代码
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);// 容量12 ,负载因子0.75
}
进入构造器看看;很简单 就是HashMap的最大容量值是2的30次方;其次由于输入的数字是12不是2的次幂会进行扩容,扩容的结果也很简单就是比输出的值大的2的次幂;比12大的2 的次幂就是16;
public HashMap(int initialCapacity, float loadFactor) {//initialCapacity=12,loadFactor=0.75
if (initialCapacity < 0)//容量小于0,抛出非法参数异常
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)// MAXIMUM_CAPACITY = 1<<30 也就是 2 的30次方 ;记hashMap最大
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor)) // loadFactor=0.75>0 ,否则抛出非法参数异常
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;//负载因子赋值
this.threshold = tableSizeFor(initialCapacity);// 返回一个2次方长度的容量;此时 threshold = 16
}
点进入看看tableSizeFor(initialCapacity)是什么;多个无符号右位或操作;其目的就是构造2次幂个1;很简单的计算,读者可以自行计算;
static final int tableSizeFor(int cap) {//cap=12
int n = cap - 1;// n =11
n |= n >>> 1;// 11无符号右移 1位的结果与11相或; n=15
n |= n >>> 2;//n=15
n |= n >>> 4;//n=15
n |= n >>> 8;//n=15
n |= n >>> 16;//n=15
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;//15+1=16
}
Tip : HashMap 的扩容机制就是比输入容量值大的第一个二次幂
2.6 get源码分析
测试代码
public static void main(String[] args) {
HashMap<String, Object> map = new HashMap<>(12);
map.put("a","b");
map.get("a");
}
进入get方法
public V get(Object key) {
Node<K,V> e;//声明Node 节点e
return (e = getNode(hash(key), key)) == null ? null : e.value;// 根据key的哈希值获取Node节点返回Value
}
进入 getNode(hash(key), key)方法,可以看见进行了优先选取tab上的entry节点;如果不是才会进入链表或者红黑树进行遍历比对hash值获取节点;看过put源码之后get源码都没什么奇点了;
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;// 声明 节点数组tab , 节点first, e ; n ,k
if ((tab = table) != null && (n = tab.length) > 0 &&// tab.length =16 即容量
(first = tab[(n - 1) & hash]) != null) { // 与get的计算hash 值一样; hash值= (容量-1)& hash 得到tab索引;然后获取索引值赋值给first
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))//直接检查是否是tab上的enrty,是直接就返回Node
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)//如果是红黑树就遍历获取节点
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);//否则循环遍历链表获取节点
}
}
return null;
}
2.7 hashCode源码分析
测试代码
public static void main(String[] args) {
HashMap<String, Object> map = new HashMap<>(12);
map.put("a","b");
map.put("b","c");
int hashCode = map.hashCode();
System.out.println(hashCode);//4
}
进入hashCode,就是遍历每个entrySet的哈希值进行相加作为HashMap的hash值
public int hashCode() {
int h = 0;
Iterator<Entry<K,V>> i = entrySet().iterator();//迭代器
while (i.hasNext())
h += i.next().hashCode();//迭代每个entrySet的哈希值相加
return h;
}
做个验证
public static void main(String[] args) {
HashMap<String, Object> map = new HashMap<>(12);
map.put("a","b");
map.put("b","c");
Set<Map.Entry<String, Object>> entries = map.entrySet();
entries.stream().forEach(entry->{
System.out.println(entry.hashCode());
});
}
输出内容是1,3;
Tip : HashMap 的hashCode 就是 entry 的hash值之和,其中Node的哈希值由key和value的哈希值之和;
三、总结
- HashMap允许key和value都为null;key具有唯一性;
- HashMap与HashTable不同之处是,HashMap不同步,HashTable不允许key,value为null;
- HashMap无法保证Map中内容的顺序
- HashMap默认因子0.75;初始化容量16;如果给定容量为12,插入12个数之后再插入数据会发生扩容;
- hashMap 本质是一串哈希表;哈希表首先由数组 + 链表组成;当hash碰撞后会形成链表,每个链表的节点又是一个桶;当桶的数量达到8之后就会进行树化,将链表转为红黑树,此时HashMap结构就是 数组 + 红黑树 ;如果插入相同的key,新的value会取代旧的value;
- HashMap 的扩容机制就是比输入容量值大的第一个二次幂;比如12,扩容后就是16;17扩容后就是32;
- HashMap 的hashCode 就是 entry 的hash值之和,其中Node的哈希值由key和value的哈希值之和;
最后
这次要给大家分享总结的东西就是这些了
资料全都放在——***我的学习笔记:大厂面试真题+微服务+MySQL+Java+Redis+算法+网络+Linux+Spring全家桶+JVM+学习笔记图***
最后再分享一份终极手撕架构的大礼包(学习笔记):分布式+微服务+开源框架+性能优化
是一串哈希表;哈希表首先由数组 + 链表组成;当hash碰撞后会形成链表,每个链表的节点又是一个桶;当桶的数量达到8之后就会进行树化,将链表转为红黑树,此时HashMap结构就是 数组 + 红黑树 ;如果插入相同的key,新的value会取代旧的value;
- HashMap 的扩容机制就是比输入容量值大的第一个二次幂;比如12,扩容后就是16;17扩容后就是32;
- HashMap 的hashCode 就是 entry 的hash值之和,其中Node的哈希值由key和value的哈希值之和;
最后
这次要给大家分享总结的东西就是这些了
资料全都放在——***我的学习笔记:大厂面试真题+微服务+MySQL+Java+Redis+算法+网络+Linux+Spring全家桶+JVM+学习笔记图***
最后再分享一份终极手撕架构的大礼包(学习笔记):分布式+微服务+开源框架+性能优化
以上是关于太硬核了!这篇HashMap源码分析,绝对可以堪称为圣经的主要内容,如果未能解决你的问题,请参考以下文章