面试python的内存管理机制
Posted 黑黑白白君
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面试python的内存管理机制相关的知识,希望对你有一定的参考价值。
文章目录
1)什么是内存管理?
内存管理是指软件运行时对计算机内存资源的分配和使用的技术。
- 其最主要的目的是如何高效,快速的分配,并且在适当的时候释放和回收内存资源。
现代高级编程语言管理内存的方式分为两种:自动和手动。
- 像C、C++ 等编程语言使用手动管理内存的方式,工程师编写代码过程中需要主动申请或者释放内存。
- 而 Python、PHP、Java 和 Go 等语言使用自动的内存管理系统,有内存分配器和垃圾收集器来代为分配和回收内存。
2)Python的内存管理机制
Python的内存管理机制分三个方面:对象的引用计数、垃圾回收、内存池机制。
2.1 引用计数(reference count)
在Python中,每个对象都有存有指向该对象的引用总数,即引用计数(reference count)。
- Python通过引用计数来保存内存中的变量追踪,即记录该对象被其他使用的对象引用的次数。
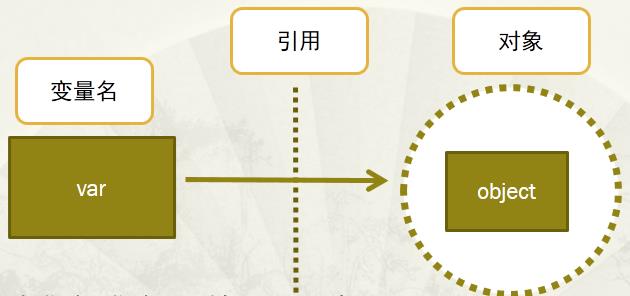
*变量VS对象
- 变量:通过变量指针引用对象。
- 变量指针指向具体对象的内存空间,取对象的值。
- 对象:类型已知,每个对象都包含一个头部信息。
- 头部信息:类型标识符和引用计数器
- 对象可以是简单的(包含数字,字符串等),也可以是容器(字典,列表或用户定义的类)
关系图如下:
注意:变量名没有类型,类型属于对象(因为变量引用对象,所以类型随对象),变量引用什么类型的对象,变量就是什么类型的。
>>> var1=123 >>> var2=var1 >>> id(var1) //id()是python的内置函数,用于返回对象的身份,即对象的内存地址。 140708032318336 >>> id(var2) 140708032318336 >>> var1='456' >>> id(var1) 1582181574320 >>> id(var2) 140708032318336 >>> type(var1) <class 'str'> >>> type(var2) <class 'int'> >>> var1=var2 >>> type(var1) <class 'int'>
-
引用所指判断
通过is进行引用所指判断,is是用来判断两个引用所指的对象是否相同。
# 整数 >>> a=1 >>> b=1 >>> a is b True # 短字符串 >>> a="good" >>> b="good" >>> a is b True # 长字符串 >>> a="very good" >>> b="very good" >>> a is b False # 列表 >>> a=[] >>> b=[] >>> a is b False由运行结果可知:
- Python缓存了整数和短字符串,因此每个对象在内存中只存有一份,引用所指对象就是相同的,即使使用赋值语句,也只是创造新的引用,而不是对象本身;
- Python没有缓存长字符串、列表及其他对象,可以由多个相同的对象,可以使用赋值语句创建出新的对象。
1、普通引用
-
查看对象的引用计数:sys.getrefcount()
>>> import sys >>> a=[1] >>> sys.getrefcount(a) 2 >>> b=a >>> sys.getrefcount(a) 3- 当使用某个引用作为参数,传递给getrefcount()时,参数实际上创建了一个临时的引用。因此,getrefcount()所得到的结果,会比期望的多1。
2、容器对象
Python的一个容器对象(比如:表、词典等),可以包含多个对象。
-
容器对象中包含的并不是元素对象本身,是指向各个元素对象的引用:
>>> a=[1,2] >>> b=a >>> a is b True >>> a[0]=2 >>> a is b True >>> a [2, 2] >>> b [2, 2]
3、引用计数增加
>>> sys.getrefcount(123)
6
>>> n=123 # 1、对象被创建
>>> sys.getrefcount(123)
7
>>> m=n # 2、被其他的变量引用
>>> sys.getrefcount(123)
8
>>> a=[1,123] # 3、作为容器对象的一个元素
>>> sys.getrefcount(123)
9
# 4、被作为参数传递给函数:foo(x)
4、引用计数减少
>>> del m # 1、对象的别名被显式的销毁
>>> sys.getrefcount(123)
8
>>> n=456 # 2、对象的一个别名被赋值给其他对象
>>> sys.getrefcount(123)
7
>>> a.remove(123) # 3、对象从一个窗口对象中移除,或,窗口对象本身被销毁
>>> sys.getrefcount(123)
6
# 4、一个本地引用离开了它的作用域,比如上面的foo(x)函数结束时,x指向的对象引用减1。
2.2 垃圾回收(garbage collection)
当Python中的对象越来越多,占据越来越大的内存,启动垃圾回收,将没用的对象清除。
-
原理:
当Python的某个对象的引用计数降为0时,说明没有任何引用指向该对象,该对象就成为要被回收的垃圾。
-
注意:
- 垃圾回收时,Python不能进行其它的任务,频繁的垃圾回收将大大降低Python的工作效率。
- Python只会在特定条件下,自动启动垃圾回收(垃圾对象少就没必要回收)。
- 当Python运行时,会记录其中分配对象(object allocation)和取消分配对象(object deallocation)的次数。当两者的差值高于某个阈值时,垃圾回收才会启动。
引用计数能够解决大多数垃圾回收的问题,但是遇到两个对象相互引用的情况,del语句可以减少引用次数,但是引用计数不会归0,对象也就不会被销毁,从而造成了内存泄漏问题。针对该情况,Python引入了标记-清除机制。
标记-清除机制:
标记-清除用来解决引用计数机制产生的循环引用,进而导致内存泄漏的问题 。
- 循环引用只有在容器对象才会产生,比如字典,元组,列表等。
该机制在进行垃圾回收时分成了两步:
- 标记阶段:遍历所有的对象,如果是可达的(reachable),也就是还有对象引用它,那么就标记该对象为可达。
- 清除阶段:再次遍历对象,如果发现某个对象没有标记为可达(即为Unreachable),则就将其回收。
上面描述的垃圾回收的阶段,会暂停整个应用程序,等待标记清除结束后才会恢复应用程序的运行。
为了减少应用程序暂停的时间,Python通过“分代回收”(Generational Collection)以空间换时间的方法提高垃圾回收效率。
分代回收:
Python将所有的对象分为0,1,2三代:
-
所有的新建对象都是0代对象,当某一代对象经历过垃圾回收,依然存活,就被归入下一代对象。
-
当某一代中被分配的对象与被释放的对象之差达到某一阈值时,就会触发当前一代的gc扫描。
- 当某一代被扫描时,比它年轻的一代也会被扫描,因此,第2代的gc扫描发生时,第0,1代的gc扫描也会发生,即为全代扫描。
- 当某一代被扫描时,比它年轻的一代也会被扫描,因此,第2代的gc扫描发生时,第0,1代的gc扫描也会发生,即为全代扫描。
-
阈值分析:
>>> import gc >>> gc.get_threshold() # gc模块中查看阈值的方法 (700, 10, 10)- 700即是垃圾回收启动的阈值,700=新分配的对象数量-释放的对象数量,第0代gc扫描被触发
- 第一个10:第0代gc扫描发生10次,则第1代的gc扫描被触发
- 第二个10:第1代的gc扫描发生10次,则第2代的gc扫描被触发
- 当然也是可以手动启动垃圾回收:gc.collect()
2.3 内存池机制
为什么要引入内存池?
当创建大量消耗小内存的对象时,频繁调用new/malloc会导致大量的内存碎片,致使效率降低。
- 内存池的作用就是预先在内存中申请一定数量的,大小相等的内存块留作备用,当有新的内存需求时,就先从内存池中分配内存给这个需求,不够之后再申请新的内存。
这样做最显著的优势就是能够减少内存碎片,提升效率。
Python提供了对内存的垃圾收集机制,但是它将不用的内存放到内存池而不是返回给操作系统。python中的内存管理机制为Pymalloc。
- Python中有分为大内存和小内存:(256K为界限分大小内存):
- 大内存使用malloc进行分配
- 小内存使用内存池进行分配
CPython(python解释器)的内存架构图:
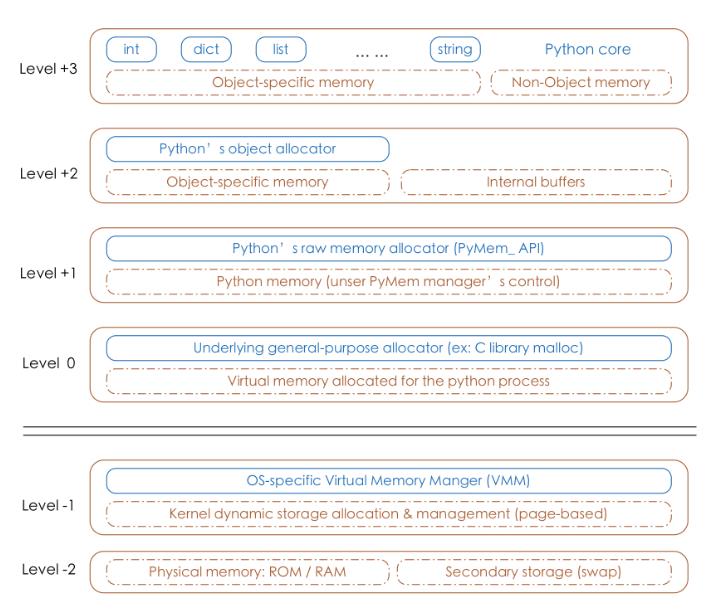
- python的对象管理主要位于Level+1~Level+3层,内存池为+1和+2层。
- Level+3层:对于python内置的对象(比如int,dict等)都有独立的私有内存池,对象之间的内存池不共享,即int释放的内存,不会被分配给float使用。
- 用户对Python对象的直接操作。
- Level+2层:当申请的内存大小小于256KB时,内存分配主要由 Python 对象分配器(Python’s object allocator)实施。
- 即使用内存池管理系统进行分配,调用malloc函数分配内存,但是每次只会分配一块大小为256K的大块内存。
- 不会调用free函数释放内存,将该内存块留在内存池中以便下次使用。
- Level+1层:当申请的内存大小大于256KB时,由Python原生的内存分配器进行分配,本质上是调用C标准库中的malloc/realloc等函数。
- malloc函数分配内存。
- free函数释放内存。
- Level+3层:对于python内置的对象(比如int,dict等)都有独立的私有内存池,对象之间的内存池不共享,即int释放的内存,不会被分配给float使用。
【部分内容参考自】
- Python内存管理机制:https://www.cnblogs.com/geaozhang/p/7111961.html#yinyongjishu
- 什么是Python的 “内存管理机制”:https://blog.csdn.net/bjweimengshu/article/details/107624945
以上是关于面试python的内存管理机制的主要内容,如果未能解决你的问题,请参考以下文章