一线大数据专家,用一文详解大数据架构,从数据获取到深度学习
Posted Javachichi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一线大数据专家,用一文详解大数据架构,从数据获取到深度学习相关的知识,希望对你有一定的参考价值。
前言
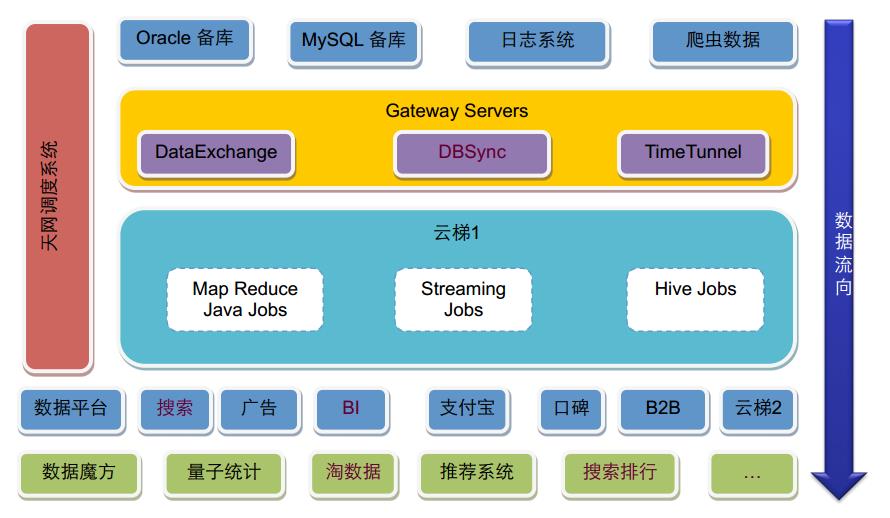
本文将从大数据的本质:大数据现状及挑战,驱动因素,未来趋势,Spark原理及应用,探针,爬虫,日志采集,Flink ,深度学习,数据分发中间件进行整体的介绍与概述,下图将全面详解大数据架构。

主要内容
大数据这几年真的很火,于是有越来越多的人开始学习大数据技术。很多人会误以为大数据是一门技术,其实不然,大数据更多的是一门市场宣传语言,也可以理解为一种思考方式。从技术角度来看,大数据是一系列技术的组合,所以真正全面掌握大数据技术也是一件很困难的事情。
编写本文的初衷就是总结这些年的工作和学习经验,希望可以分享给更多人,同时对自己而言也是一个提高、总结和升华的过程。
总的来说,本文围绕一个通用技术栈来组织章节,主要聚焦大数据平台的一些知识,主要分为三部分:
第一部分:第1~3章,主要讲述大数据的本质、运营商大数据的架构和一些基本的业务知识。
- 第1章:阐述大数据的本质和面临的挑战;首先提一个问题: “大数据”是-项专门的技术吗?有的人可能会以为大数据是一项专门的技术,其实不是,“大数据”这三个字只是一门市场语言( Marketing Language ),其背后是硬件、数据库、操作系统、Hadoop等一系列技术的综合应用,所以本书我们希望从一个端到端的架构展开讲解典型的大数据技术。
- 第2章:概述大数据架构及背后的驱动因素,以及未来发展的趋势;①架构驱动的因素:运营商和互联网面临不同的历史时期,因而大数据在各自领域承担的使命是不一样的。②运营商面临被管道化的挑战,营收下滑,大数据项目承担企业战略转型、数据变现的使命。同时由于成本的压力,以及大量基础设施和设备利旧的诉求,所以运营商在大数据项目中,对性能、成本和集成度提出了很高的要求。③互联网企业近几年盈利颇丰,大数据往往是承担业务快速创新、未来探索的一种驱动因素,所以对架构的扩展性、灵活性等方面的追求优先级在成本之上。互联网企业每建一个数据中心通常就是几千台的规模,这在运营商看来是不可想象的。背后的商业驱动因素不一样, 所带来的架构挑战也不一样。
- 第3章:介绍运营商领域的业务,让读者对大数据能做什么有一个直观的感受。运营商大数据便可以衍生出众多业务,主要有SQM (运维质量管理)、CSE(客户体验提升). MSS (市场运维支撑)、DMP (数据管理平台)。
第二部分:第4~11章,围绕大数据平台技术栈来阐述数据获取、处理、分析和应用平台涉及的技术。
- 第4章:介绍数据获取涉及的探针、爬虫、日志采集、数据分发中间件等技术。大数据技术的核心是从数据中获取价值,而第一步 就是要弄清楚有什么数据、怎样获取。在企业的生产过程中,数据无所不在,但是如果不能正确获取,或者没有能力获取,就浪费了宝贵的数据资源。本章主要介绍数据获取的技术。
- 第5章:介绍流式数据处理引擎、CEP、流式应用。我们将大数据处理按处理时间的跨度要求分为以下几类,从短到长分别是:①基于实时数据流的数据处理( Streaming Data Processing ),通常的时间跨度在数百毫秒到数秒之间。②基于历史数据的交互式查询( Interactive Query ), 通常的时间跨度在数十秒到数分钟之间。③复杂的批量数据处理( Batch Data Processing ),通常的时间跨度在几分钟到数小时之间。接下来的几章会分别讲述在这几种处理时间跨度要求下将采取的技术,首先讲述实时数据流的处理。当然,批和流及交互式查询并不一定能完全分开,Spark 的一个主要想法就是统一几个引擎,所以本章会讲到Spark Streaming,在第7章将详细讲述Spark对批的处理。
- 第6章:介绍交互式分析技术、MPP DB、热门的SQL on Hadoop技术。定义:基于历史数据的交互式查询( Interactive Query ),通常的时间跨度在数十秒到数分钟之间。
- 第7章:介绍批处理技术、Spark, 以及大规模机器学习的BSP技术等。定义:复杂的批量数据处理( Batch Data Processing ),通常的时间跨度在几分钟到数小时之间。
- 第8章:探讨机器学习、深度学习相关技术。机器学习( Machine Leamning, ML) 是一门多领域交叉学科,涉及概率论、统计学、過近论、凸分析、算法复杂度理论等多门学科。其专门研究计算机是怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构,使之不断改善自身的性能。除了机器学习外,本章还将涉及另外-一个领域一数据挖掘, 它和机器学习有很大的交集。机器学习和数据挖掘是两个非常难的领域,本章更多地从架构和应用角度去解读,理论知识则不进行重点阐述。
- 第9章:统一资源管理是趋势,本章介绍资源管理的核心技术和算法。资源管理的本质是集群、数据中心级别资源的统一管理和分配, 以提高效率。其中,多租户、弹性伸缩、动态分配是资源管理系统要解决的核心问题。本章首先介绍资源管理的基本概念,以及Hadoop领域常见的一些资源调度框架;接着介绍大数据时代面临的多租户问题、数据中心的统一资 源调度、资源调度和分配算法,以及基于应用描述的智能调度;最后介绍一个Mesos代码分析实战。
- 第10章:存储是基础,本章介绍存储的关键技术。存储是所有大数据组件的基础,存储的发展远低于CPU和MEM,导致CPU和存储的速度差越来越大,所以对于DBA来说,调优有时候基本等价于调存储。本章将从系统架构和应用角度讲述对存储的理解,希望对读者理解存储有所帮助。
- 第11章:探讨大数据技术怎么云化,以及关键技术是什么。云计算发展到今天,可以说已经成功地从概念落地到实际。企业IT系统是否上云,已经成为企业CIO构建企业IT系统优先考虑的问题。以AWS/Microsoft Azure 为代表的厂商,每年的云计算收人高达几十亿美元,而且仍能保持较快的增长速度。从广义上说,大数据技术也是云上的一种基础服务。大数据技术怎样服务化是- - -个值得研究的领域。本章将讨论以AWS为代表的EMR方案、阿里的ODPS等众多厂商探讨的服务化方案,以及Docker技术对大数据的影响等内容。
第三部分:第12章,技术和文化息息相关,技术影响文化,文化影响技术。
- 第12章:介绍大数据开发文化、开源、DevOps, 探讨理念和文化对技术的冲击。本章不具体讲哪个组件的开发技术,只想和大家一-起探讨一 - 下开源文化、理念,以及大数据开发模式的一些改变。

因为内容有点多,所以小编只做了一个简单的概述,每个小节里面都有更加细化的内容,希望大家能够理解和喜欢,多多支持小编!
需要本【大数据架构详解:从数据获取到深度学习】技术文档的小伙伴,可以在文末获取免费领取方式!
需要完整版文档的小伙伴,可以一键三连,下方获取免费领取方式!

以上是关于一线大数据专家,用一文详解大数据架构,从数据获取到深度学习的主要内容,如果未能解决你的问题,请参考以下文章
媒体观察丨国内大数据一线专家分享:大家都在用Hadoop的原因是什么?
分享《深度学习与计算机视觉算法原理框架应用》《大数据架构详解从数据获取到深度学习》PDF数据集