一年标星翻倍,它凭什么成为GitHub最活跃大数据项目之一?
Posted 大数据文摘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一年标星翻倍,它凭什么成为GitHub最活跃大数据项目之一?相关的知识,希望对你有一定的参考价值。
2015年,阿里搜索算法团队遇到了一个问题。
整个淘宝和天猫的商品都需要实时更新到在线的搜索和推荐引擎中,以及要根据用户在在线行为进行实时个性化的搜索排序和推荐。
在这样挑战的业务需求大背景下,阿里搜索团队迫切需要找到一个能承受巨大计算量并且实时化的计算引擎。
通过综合多方面因素的权衡和判断,阿里最终选择了Flink作为实时计算引擎。
之后也正如我们所见,阿里集团顶住了包括双十一、618等全年不断的大大小小促销活动。
作为一个14年才进入Apache的年轻项目,当时的Flink是如何吸引了阿里搜索团队的注意的呢?
阿里巴巴资深技术专家,实时计算负责人,也是Flink中文社区发起人王峰 (莫问)告诉我们,团队首先看中的是Flink的架构设计,尤其是作为一个纯流式思想来做大数据处理,不仅可以基于Kappa结构来做流式数据处理,还可以基于流为核心做批流融合的计算能力。
也正因如此,作为备受瞩目的新一代开源大数据计算引擎,Flink项目已成为Apache基金会和GitHub最为活跃的项目之一。在去年年底Flink Forward Asia 2019上透露,仅仅是2019年一年的时间,Flink在GitHub上的star数量就翻了一倍,贡献者数量也呈现出持续增长的态势。
为了让更多技术从业者了解Flink,Apache Flink Committer执笔,四位PMC成员审核,将Flink 9大技术版块详细拆分,突出重点内容并搭配全面的学习素材。
看完这份知识图谱,才算真的搞懂Flink!
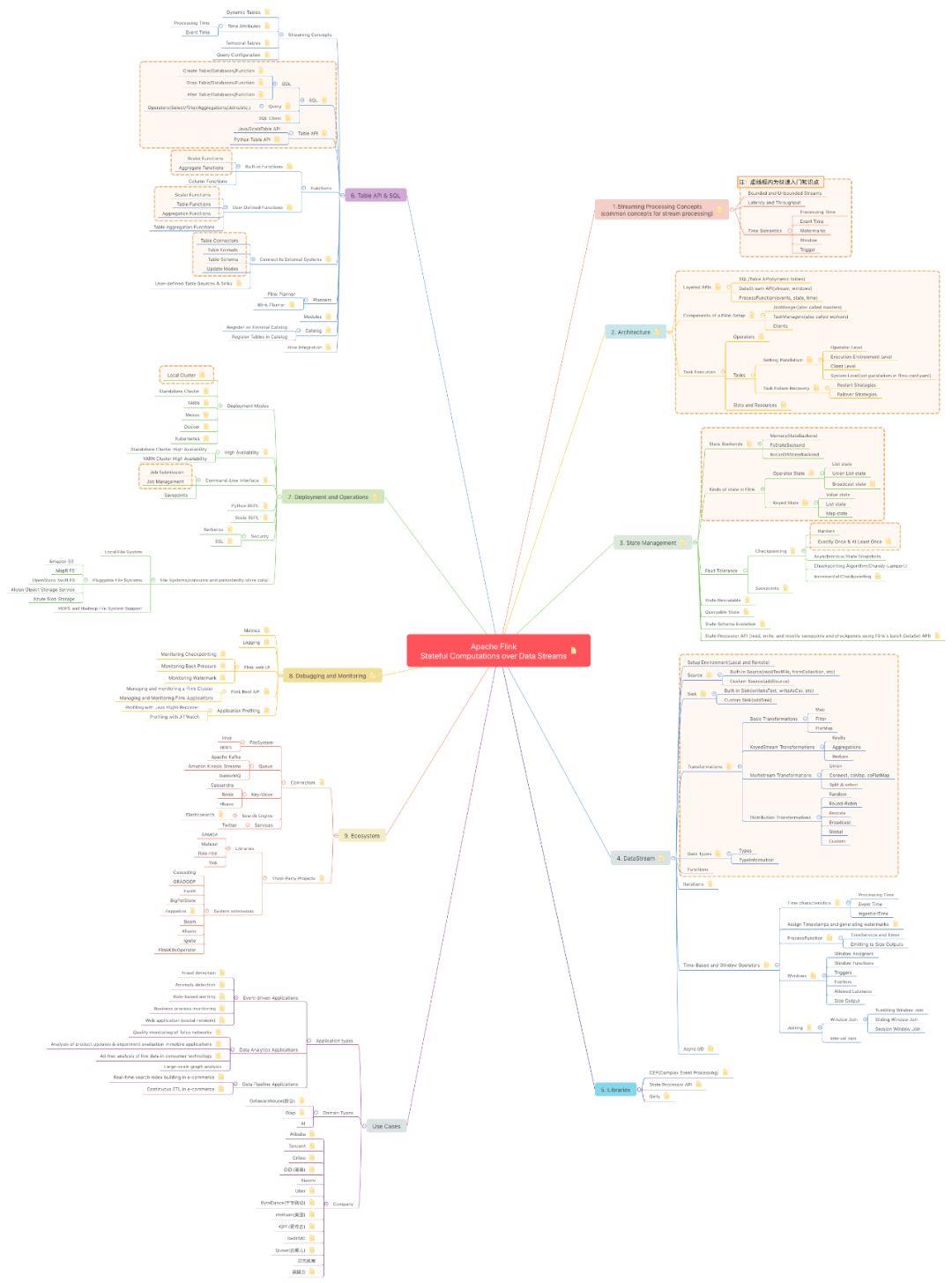
各版块知识点详解
-
Streaming Processing Concepts(common concepts for stream processing)
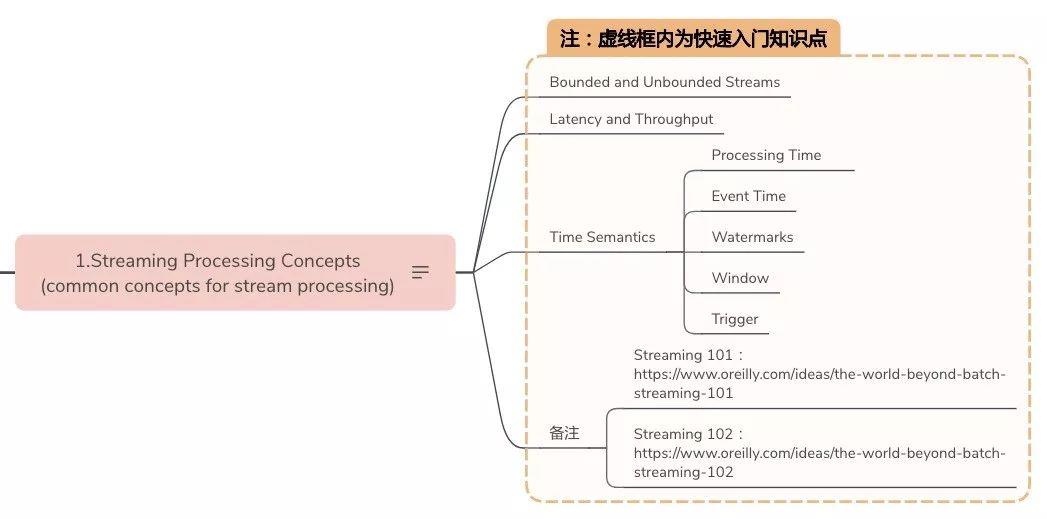
-
Architecture
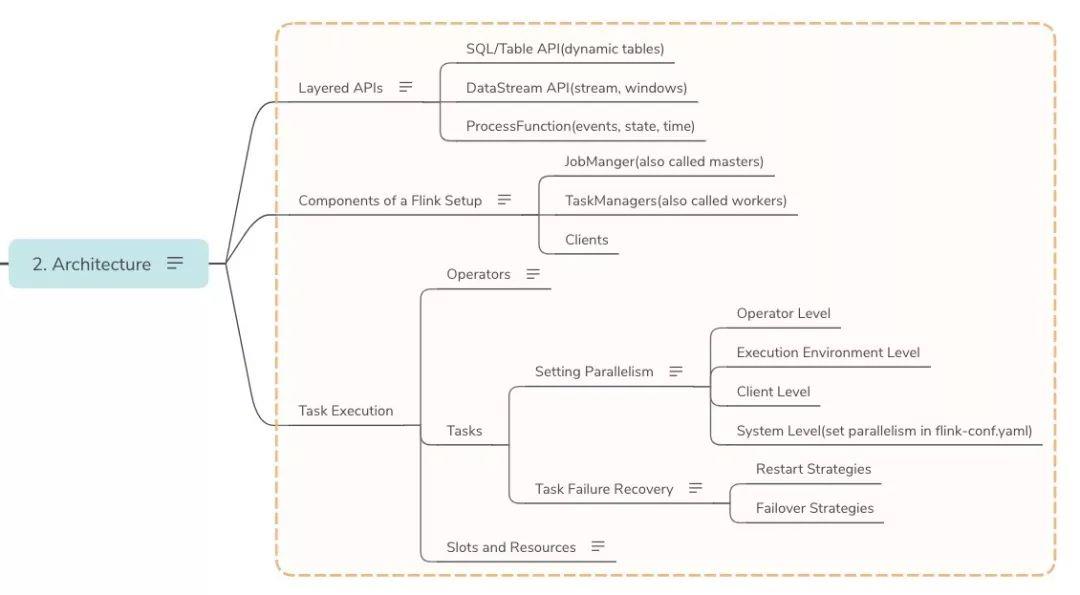
-
State Management
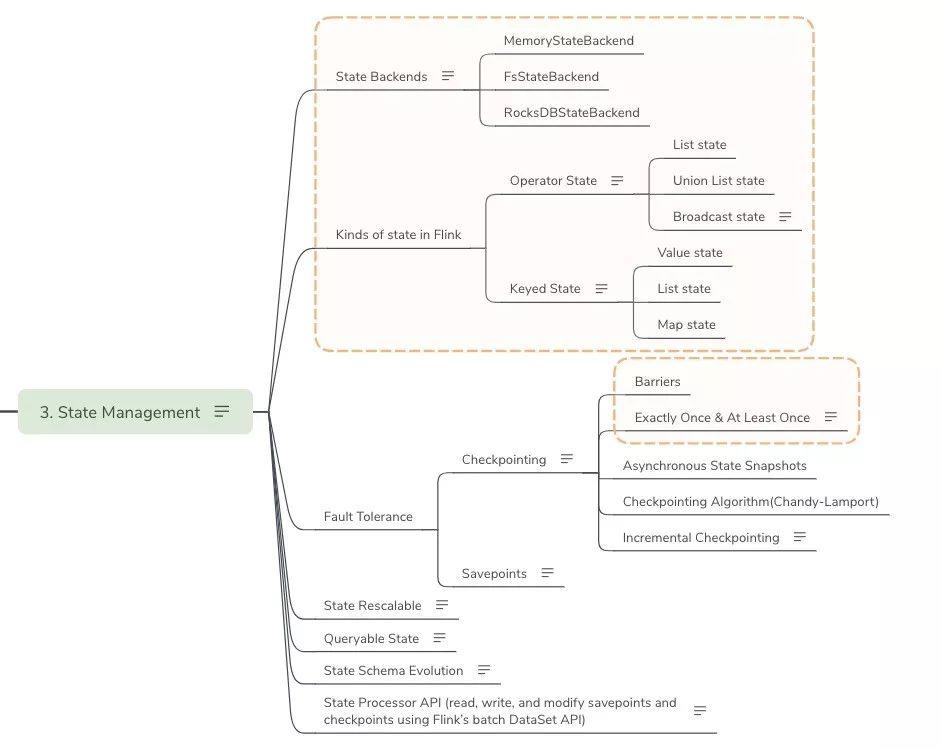
-
DataStream
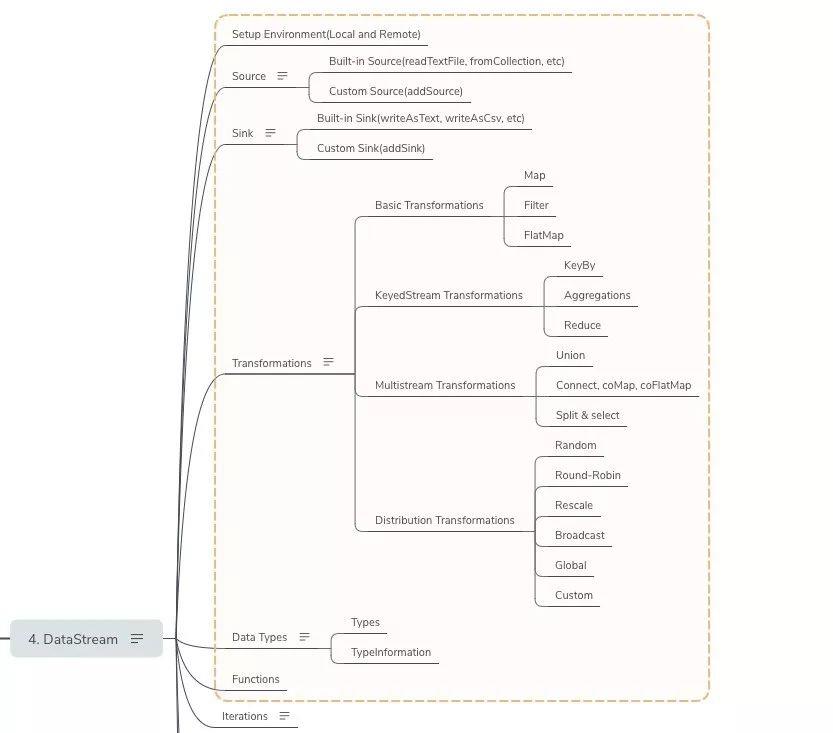
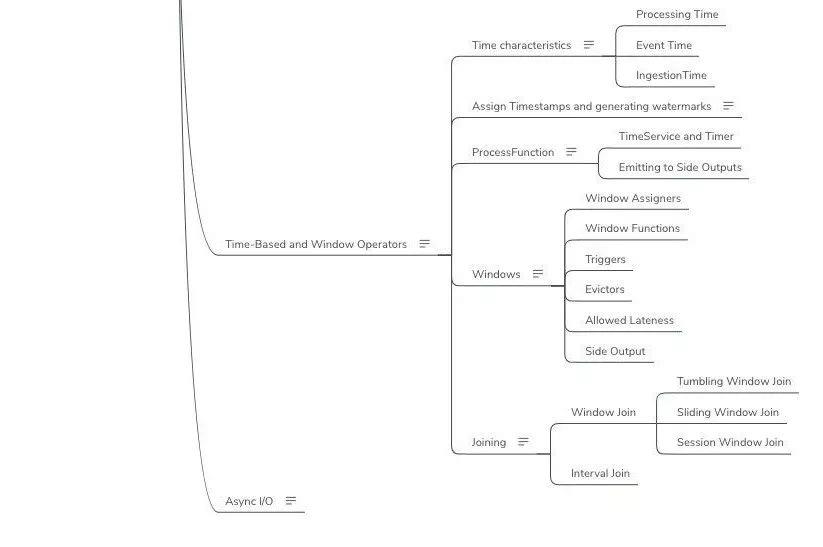
-
Libraries

-
Table API & SQL
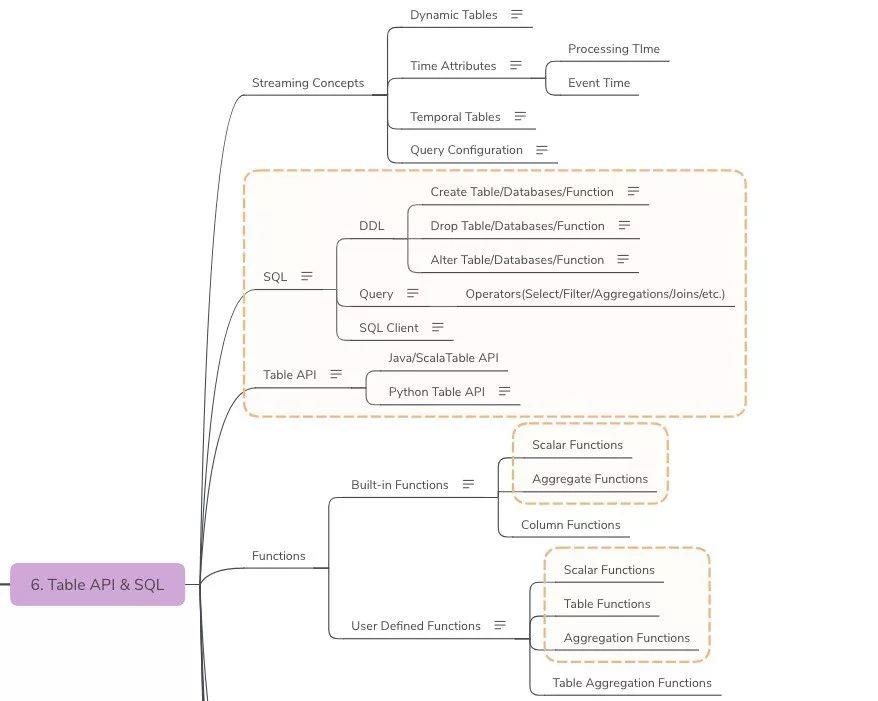
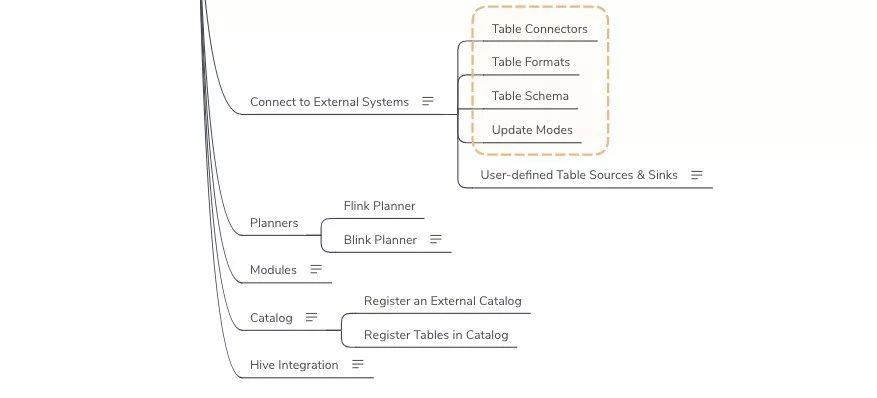
-
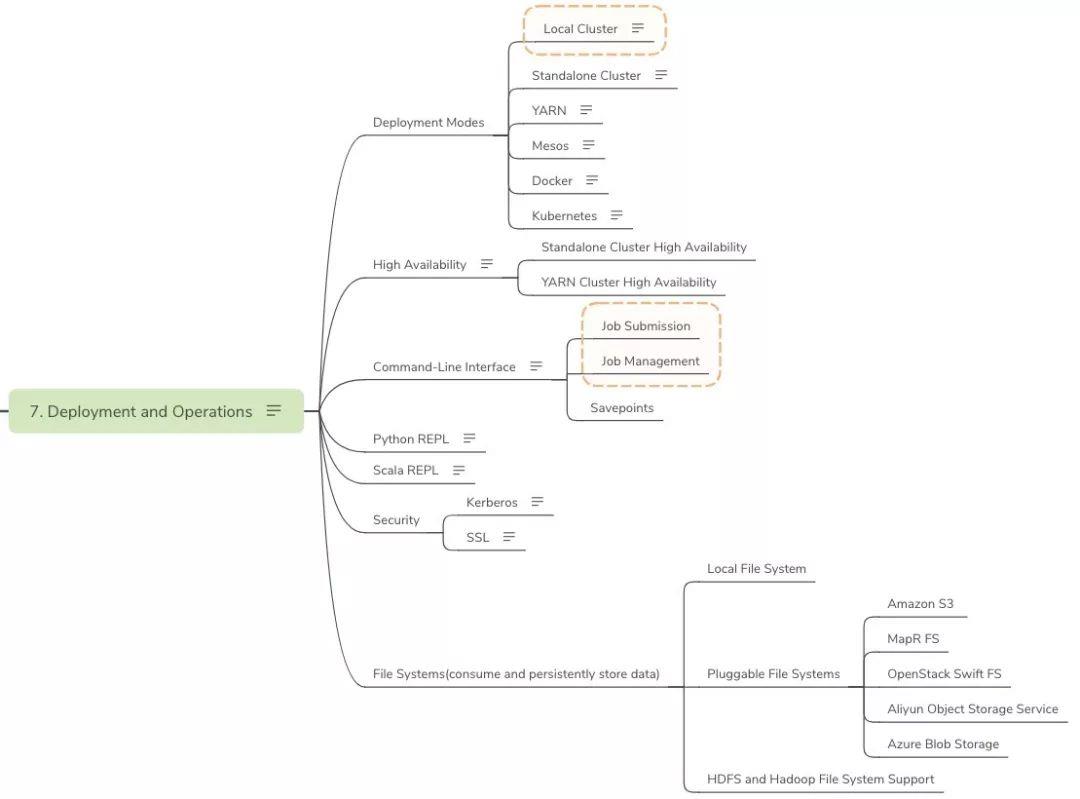
Deployment and Operations
-
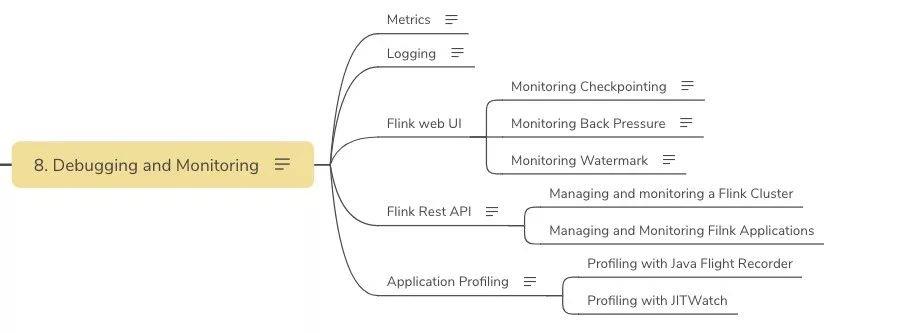
Debugging and Monitoring
-
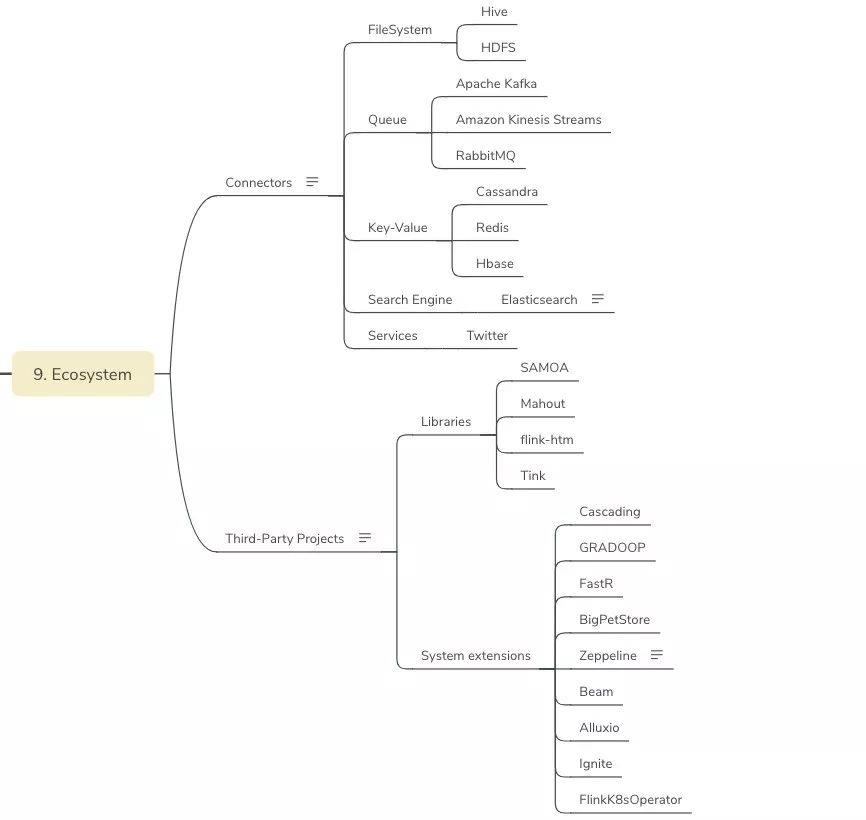
Ecosystem
-
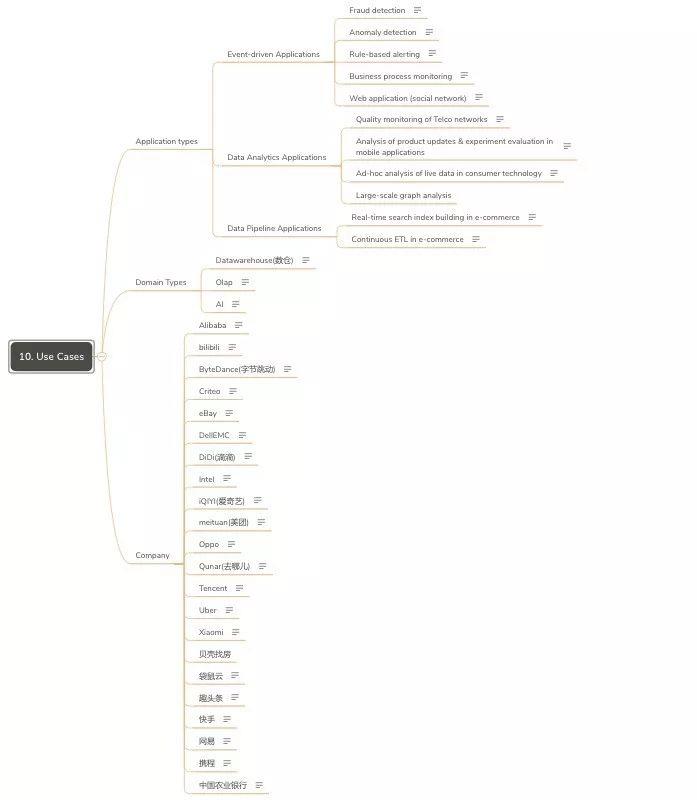
Use Cases
重磅福利:阿里大数据训练营重磅开启!
以上是关于一年标星翻倍,它凭什么成为GitHub最活跃大数据项目之一?的主要内容,如果未能解决你的问题,请参考以下文章
20天内看完这套GitHub标星18k+的Android资料,深夜思考
超赞的PyTorch资源大列表,GitHub标星9k+,中文版也上线了