Spark之核心架构
Posted 柳小葱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark之核心架构相关的知识,希望对你有一定的参考价值。
😻前面我们介绍了一些pyspark的基础指令集,但是对spark的核心架构了解还不够透彻,今天我们就来介绍一些spark的核心架构,以及一些基本概念,对以前内容感兴趣的小伙伴可以查看👇:
今天我们来介绍一下spark的一些运行原理、架构、组成部分。
1.spark运行架构
spark框架的核心是一个计算引擎,整体来说,它采用了标准的master——slave的结构。如图所示,它展示了一个 Spark 执行时的基本结构。图形中的 Driver 表示 master,负责管理整个集群中的作业任务调度。图形中的 Executor 则是 slave,负责实际执行任务。
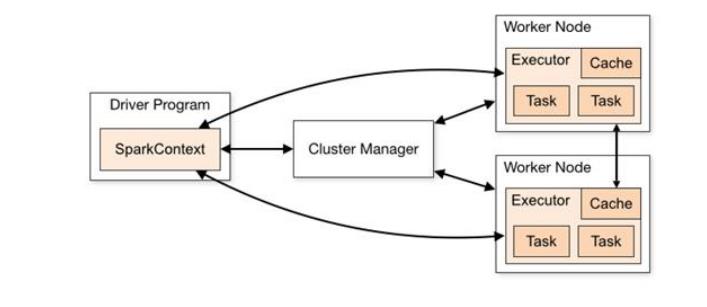
1.1 Driver
Driver是spark的驱动节点,用于执行spark任务中的main方法,负责实际代码的执行工作。主要负责以下任务:
- 将用户程序转化为作业(job)
- 在Executor之间调度任务
- 跟踪Executor的执行情况
- 通过 UI 展示查询运行情况
通俗理解Driver就是驱使整个应用运行起来的程序,也称之为
Driver 类
1.2 Executor
Spark Executor 是集群中工作节点(Worker)中的一个 JVM 进程,负责在 Spark 作业中运行具体任务(Task),任务彼此之间相互独立。Spark 应用启动时,Executor 节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有 Executor 节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他 Executor 节点上继续运行。
- 负责运行组成 Spark 应用的任务,并将结果返回给驱动器进程
- 它们通过自身的块管理器(Block Manager)为用户程序中要求缓存的RDD 提供内存式存储。RDD 是直接缓存在 Executor 进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
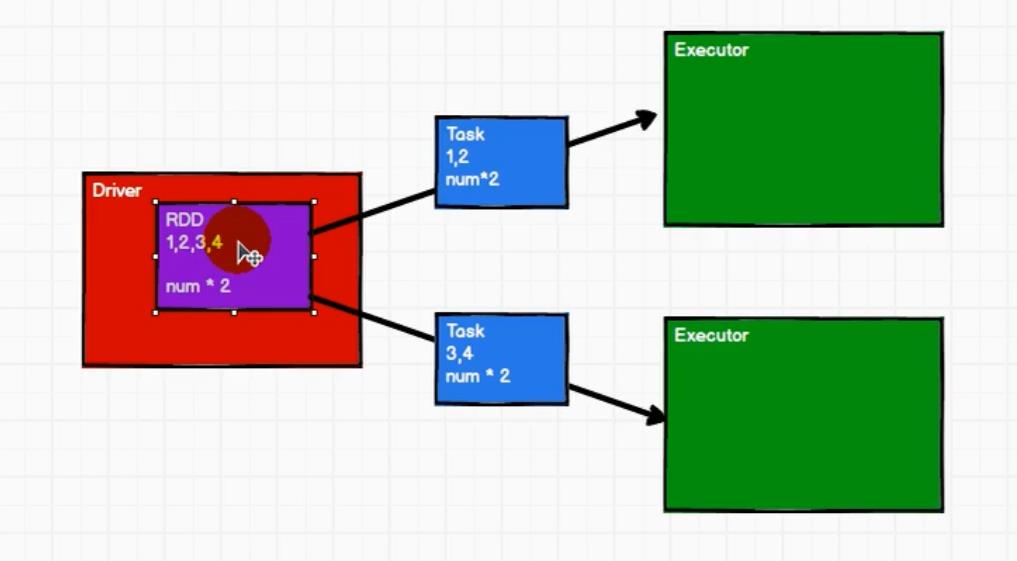
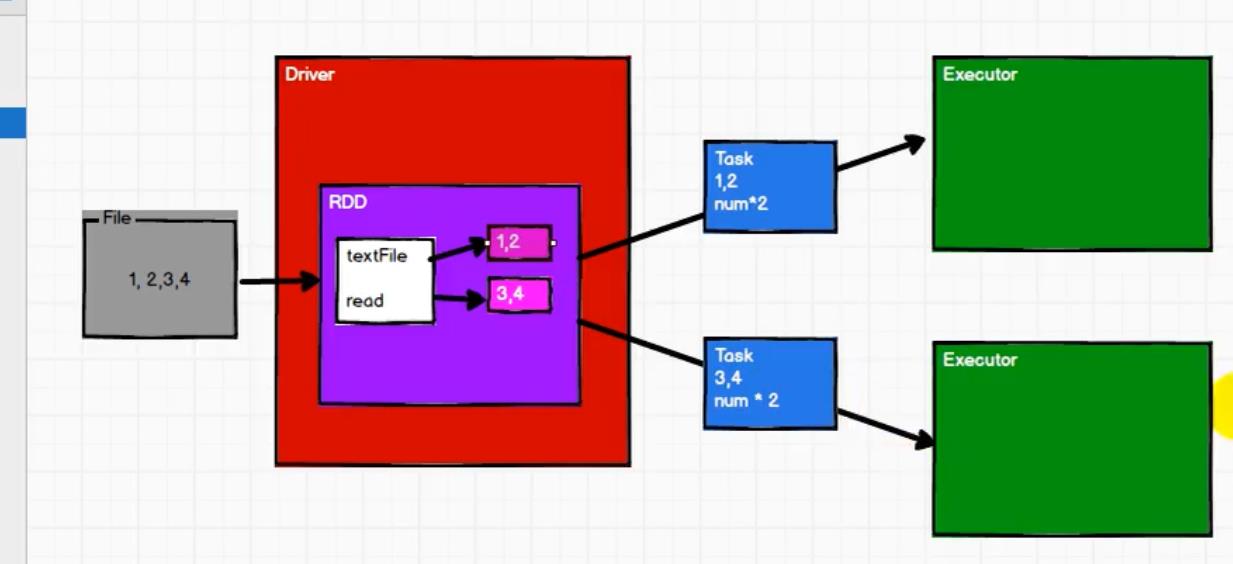
2.RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。
- 存储的弹性:内存与磁盘的自动切换;
- 容错的弹性:数据丢失可以自动恢复;
- 计算的弹性:计算出错重试机制;
- 分片的弹性:可根据需要重新分片。
- 分布式:数据存储在大数据集群不同节点上
- 数据集:RDD 封装了计算逻辑,并不保存数据
- 数据抽象:RDD 是一个抽象类,需要子类具体实现
- 不可变:RDD 封装了计算逻辑,是不可以改变的,想要改变,只能产生新的 RDD,在新的 RDD 里面封装计算逻辑
- 可分区、并行计算
我们应该如何去理解这个RDD,如何理解是是最基本的数据处理单元,解释RDD之前先说一下java的IO操作,这里之所以要说java的IO是因为RDD的处理方式和java的IO操作很像。
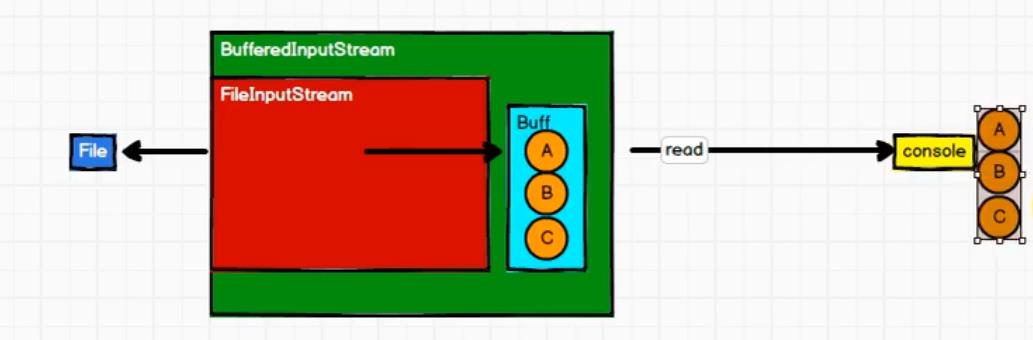
2.1 IO操作的字符流
在字符流中,我们并不是将A、B、C字符读一个然后输出一个,而是将字符读到缓冲区中,等缓冲区的数据占满了之后,一并输出。
2.2 IO操作的字节流
在字节流中,我们并没有重新定义字节流的IO模式,只是在字符流的基础上增加了一些逻辑过程,我们在字符流的基础上增加了utf-8方式转关换流,将字符转化为字节,然后再存入缓冲区,等到缓冲区占满后,再输出结果。这种利用字符流的基础来构建字节流的方式叫做装饰者设计模式。
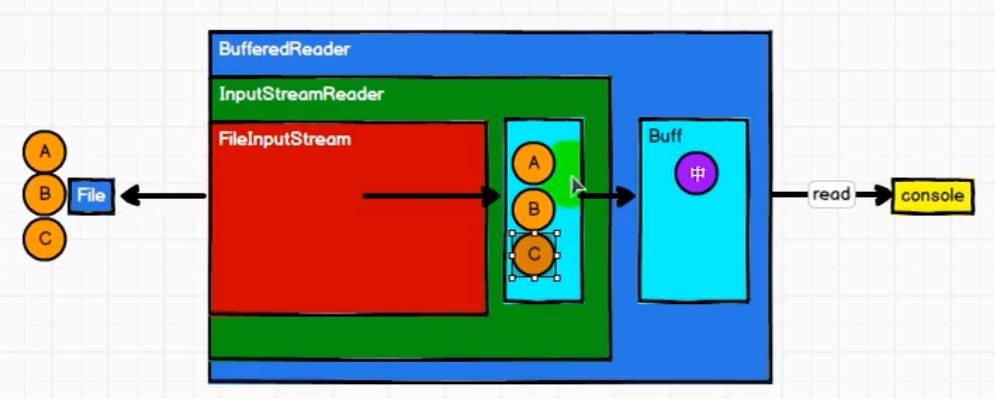
2.3 RDD
我们需要处理个文件,将文件按行读入hadoopRDD,然后mappartitionRDD将数据进行分区,然后再用mappartitionRDD转化为key-value形式,然后再用shuffleRDD进行聚合,输出最后的结果。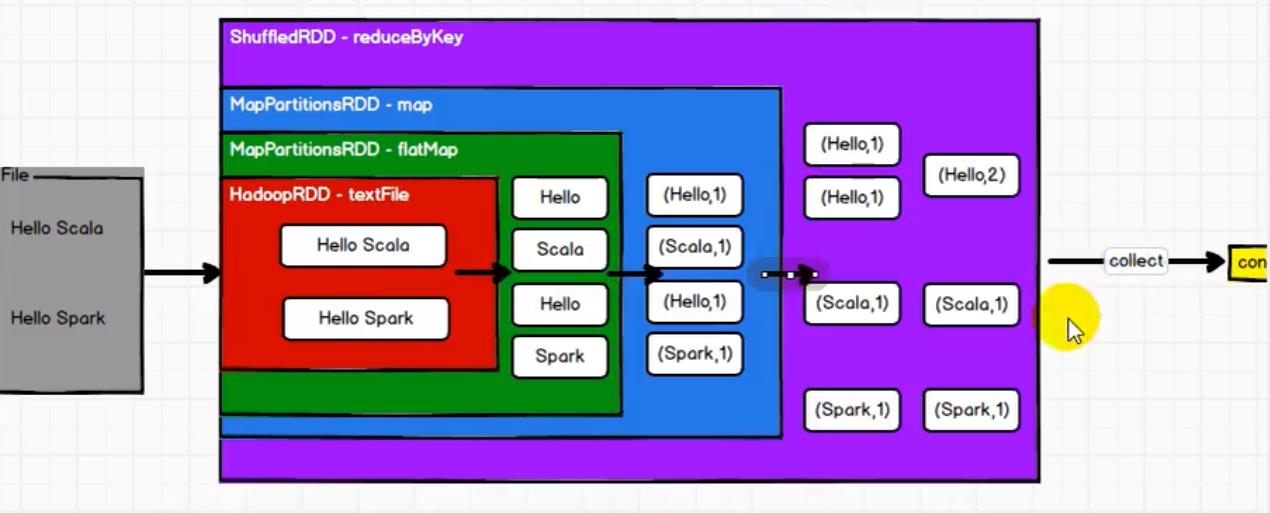
大家看到RDD的处理方式和IO很像,让我们来总结一下:
- RDD处理方式类似于IO,也是装饰者设计模式
- 这里一层一层的RDD只是定义了数据的处理逻辑,并不会真正执行,只有当触发collect方法时才会触发真正的执行过程。
- IO中有缓冲区;RDD是没有缓冲区的,不保存数据。
参考资料
《尚硅谷spark3.0》
《Spark权威指南》
以上是关于Spark之核心架构的主要内容,如果未能解决你的问题,请参考以下文章