大数据-Hadoop2.7实现PageRank算法-MapReduce&HDFS
Posted oliveQ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据-Hadoop2.7实现PageRank算法-MapReduce&HDFS相关的知识,希望对你有一定的参考价值。
记录一下实验大作业,信息较为详尽,自己跳转即可
PageRank是Google专有的算法,用于衡量特定网页相对于搜索引擎索引中的其他网页而言的重要程度,实现了将链接价值概念作为排名因素。
本实验基于Hadoop2.7的MapReduce和HDFS实现了简单版的PageRank算法【本质是矩阵的迭代运算】
运行环境
1)Oracle Linux 7.4
2)Hadoop2.7.4
3)JDK-1.8
算法原理
一个页面的“得票数”由所有链向它的页面的重要性来决定,到一个页面的超链接相当于对该页投一票。一个页面的PageRank是由所有链向它的页面(“链入页面”)的重要性经过递归算法得到的,也就是从许多优质的网页链接过来的网页,必定还是优质网页。
-
两个假设
数量假设:如果一个页面节点接收到的其他网页指向的入链数量越多,那么这个页面越重要。
质量假设:指向页面A的入链质量不同,质量高的页面会通过链接向其他页面传递更多的权重。所以越是质量高的页面指向页面A,则页面A越重要。 -
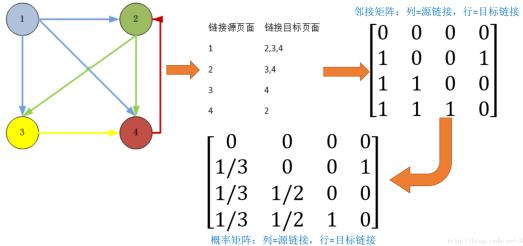
计算公式
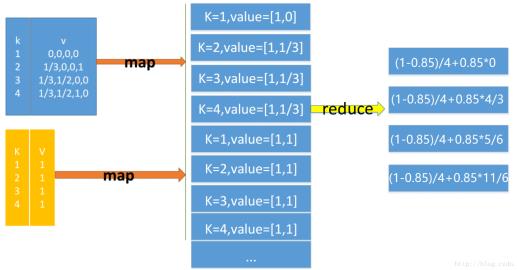
P R ( p i ) = 1 − d n + d ∑ p j ∈ M ( i ) P R ( p j ) l ( j ) PR(p_i)=\\frac{1-d}n+d\\sum\\limits_{p_j\\isin M(i)}\\frac{PR(p_j)}{l(j)} PR(pi)=n1−d+dpj∈M(i)∑l(j)PR(pj)
其中,n是所有页面数, P R ( p i ) PR(p_i) PR(pi)是指页面 p i p_i pi的PageRank值, L ( j ) L(j) L(j)是指页面 p j p_j pj的链出页面数, M ( i ) M(i) M(i)是指页面 p i p_i pi的链入页面数,d是阻尼系数,指用户继续向后浏览的概率(j->i),Google设为0.85。
-
两大特征
PR值的传递性:网页A指向网页B时,A的PR值也部分传递给B
重要性的传递性:一个重要网页比一个不重要网页传递的权重要多 -
基本原理
- 初始阶段,网页通过链接关系构建起有向图,每个页面设置相同的PageRank值。
- 每轮更新计算中,每个页面将其当前的PageRank值平均分配到本页面包含的出链上(上式中的 P R L \\frac{PR}{L} LPR,代码中标为pr),将所有指向本页面的入链权值求和,即可得到新的PageRank得分。
- 当每个页面都获得了更新后的PageRank值,就完成了一轮PageRank计算。
主要步骤
Hadoop平台的配置和启动
hdfs-site.xml和core-site.xml,配置了备份系数dfs.replication为3,
HDFS的默认路径:hdfs://master:9000
namenode的默认路径:file:/opt/data/hadoop/dfs/name
datanode的默认路径:file:/opt/data/hadoop/dfs/data
启动Hadoop集群:start-all.sh
实验数据准备
page.csv和pagerank.csv,分别表示网页链入的信息,网页初始pr值
Hadoop dfs -put 数据源地址 HDFS目的地址(/root/pagerank/datas/)
Maven项目创建

项目依赖包配置pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>hadoopmr</groupId>
<artifactId>pagerank</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient
</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.6</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>
</project>
代码定义及流程图
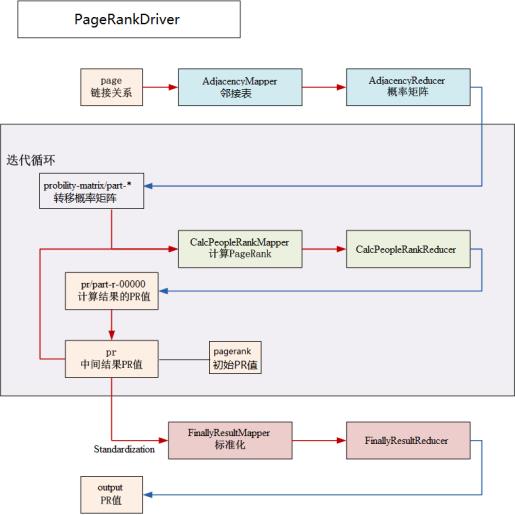
- HadoopUtils.java和HDFSUtils.java,重写函数,并快速调用
- PageRankDriver.java,调用主函数,设定迭代计算的次数(10)
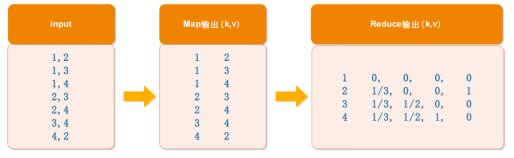
- AdjacencyMatrix.java,将用户数据转换成邻接表和邻接概率矩阵
- CalcPageRank.java,将邻接概率矩阵和pr矩阵进行计算并将得到的pr结果输出
- Standardization.java,对pr值进行重计算,每个pr都除以pr总值
数据文件
page.csv
1,2
1,3
1,4
2,3
2,4
3,4
4,2
pagerank.csv
1,1
2,1
3,1
4,1
功能代码
- HadoopUtils
import java.util.HashMap;
import java.util.Iterator;
import java.util.TreeMap;
import java.util.regex.Pattern;
public class HadoopUtils {
/**
* 分隔符类型,使用正则表达式,表示分隔符为\\t或者,
* 使用方法为SPARATOR.split(字符串)
*/
public static final Pattern SPARATOR = Pattern.compile("[\\t,]");
/**
* 计算unixtime两两之间的时间差
* @param timeSortMap key为unixtime,value为pos
* @return key为pos, value为该pos的停留时间
*/
public static HashMap<String, Float> calcStayTime(TreeMap<Long, String> timeSortMap) {
HashMap<String, Float> resMap = new HashMap<String, Float>();
Iterator<Long> iter = timeSortMap.keySet().iterator();
Long currentTimeflag = iter.next();
//遍历treemap
while (iter.hasNext()) {
Long nextTimeflag = iter.next();
float diff = (nextTimeflag - currentTimeflag) / 60.0f;
//超过60分钟过滤不计
if (diff <= 60.0) {
String currentPos = timeSortMap.get(currentTimeflag);
if (resMap.containsKey(currentPos)) {
resMap.put(currentPos, resMap.get(currentPos) + diff);
} else {
resMap.put(currentPos, diff);
}
}
currentTimeflag = nextTimeflag;
}
return resMap;
}
}
- HDFSUtils
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
public class HDFSUtils {
private FileSystem fs = null;
public HDFSUtils(Configuration conf){
try {
fs = FileSystem.newInstance(conf);
} catch (IOException e) {
e.printStackTrace();
}
}
public void deleteDir(String path) throws IOException {
Path p = new Path(path);
if(fs.exists(p)) {
fs.delete(p, true);
}
}
public void rename(String src, String dest) throws IOException {
Path p = new Path(src);
Path destPath = new Path(dest);
if(fs.exists(p)) {
this.deleteDir(dest);
fs.rename(p, destPath);
}
}
}
- PageRankDriver
import java.io.IOException;
public class PageRankDriver {
public static void main(String[] args) throws InterruptedException, IOException, ClassNotFoundException {
// 生成概率矩阵
AdjacencyMatrix.run(args);
for (int i = 0; i < 10; i++) {
// 2.迭代10次
CalcPageRank.run(args);
}
// 标准化
Standardization.run();
}
}
- AdjacencyMatrix
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
//将用户原始数据集转换成邻接表->邻接矩阵->邻接概率矩阵的过程
public class AdjacencyMatrix {
//输出邻接表
public static class AdjacencyMapper extends Mapper<LongWritable, Text, Text, Text> {
Text k = new Text();
Text v = new Text();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
super.setup(context);
System.out.println("AdjacencyMapper input:");
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//打印当前读入的数据
System.out.println(value.toString());
String[] strArr = HadoopUtils.SPARATOR.split(value.toString());
//原始用户id为key,目标用户id为value
k.set(strArr[0]);
v.set(strArr[1]);
context.write(k, v);
}
}
//输入邻接表,输出邻接概率矩阵
public static class AdjacencyReducer extends Reducer<Text, Text, Text, Text> {
Text v = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//初始化概率矩阵,概率矩阵只有一列,函数和总用户数相同,totalsum=1
int nums = 4;//用户数
float[] U = new float[nums];//构建用户邻接矩阵
int out = 0;//该用户的链出数
StringBuilder printSb = new StringBuilder();
for (Text value : values) {
//从value中拿到目标用户的id
int targetUserIndex = Integer.parseInt(value.toString以上是关于大数据-Hadoop2.7实现PageRank算法-MapReduce&HDFS的主要内容,如果未能解决你的问题,请参考以下文章