关于linux系统调优这一篇文章就够了
Posted 宝山的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于linux系统调优这一篇文章就够了相关的知识,希望对你有一定的参考价值。
文章目录
Linux 系统调性能调优详解

作为运维工程师来讲,最主要的工作保障:企业门户网站、业务系统、应用程序、软件高效稳定的运行,密切关注业务系统、操作系统性能,对业务系统、操作系统实施性能优化,使其发挥最大的性能;
影响Linux服务器、业务网站等性能因素有哪些层面呢?下面我们就一起看看如何调优吧
1.影响服务器性能因素

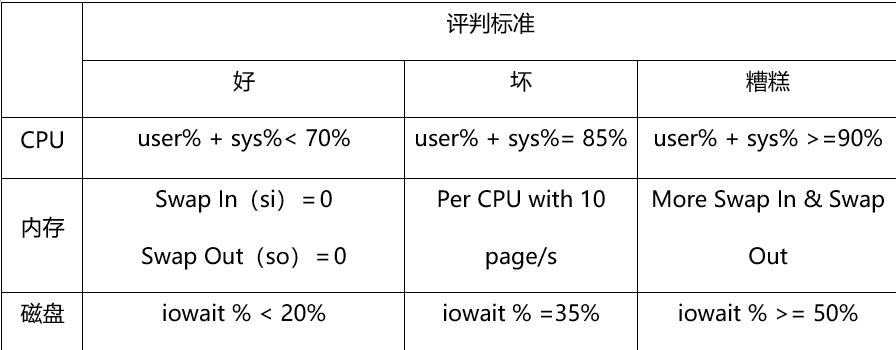
2.系统性能评估标准
- %user:表示CPU处在用户模式下的时间百分比。
- %sys:表示CPU处在系统模式下的时间百分比。
- %iowait:表示CPU等待输入输出完成时间的百分比。
- swap in:即si,表示虚拟内存的页导入,即从SWAP DISK交换到RAM
- swap out:即so,表示虚拟内存的页导出,即从RAM交换到SWAP DISK。
- 如图:

3.系统性能分析工具
-
3.1常用命令
vmstat、sar、iostat、netstat、free、ps、top、iftop -
3.2常用系统性能组合分析命令
top、uptime 检查系统整体的负载、承受能力; vmstat、sar、iostat 、top 检测是否是CPU瓶颈; free、vmstat 检测是否是内存瓶颈; iostat、iotop 检测是否是磁盘I/O瓶颈; netstat、iftop 检测是否是网络带宽瓶颈。
4.linux 性能评估与优化
4.1 系统整体性能评估
-
uptime 命令(查看系统负载)
[root@localhost ~]# uptime 04:15:24 up 2 days, 13:05, 1 user, load average: 0.01, 0.02, 0.05 [root@localhost ~]# 现在时间、系统已经运行了多长时间、目前有多少登录用户、load average:系统在过去的1分钟、5分钟和15分钟内的平均负载。 load average:这三个值的大小一般不能大于系统CPU的个数,例如,本输出中系统有8个CPU,如果load average的三个值长期大于8时,说明CPU很繁忙,负载很高,可能会影响系统性能,但是偶尔大于8时,倒不用担心,一般不会影响系统性能。 [root@localhost ~]# uptime -p #以漂亮的格式显示机器正常运行的时间 up 2 days, 13 hours, 9 minutes [root@localhost ~]# uptime -s #系统自开始运行时间 年-月-日 小时-分钟-秒 2021-06-08 15:09:34 [root@localhost ~]# uptime -h #显示帮助信息 服务器1: load average: 0.15, 0.08, 0.01 1核 服务器2: load average: 4**.15,** 6**.08,** 6**.01** 1核 服务器3: load average: 10**.15,** 10**.08,** 10**.01** 4核 答案:服务器2 如果服务器的CPU为1核心,则load average中的数字 >=3 负载过高,如果服务器的CPU为4核心,则load average中的数字 >=12 负载过高。 经验:单核心,1分钟的系统平均负载不要超过3,就可以,这是个经验值
4.2 CPU性能评估
-
1.vmstat 命令(监控系统CPU)
[root@localhost ~]# vmstat procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 3059368 2104 230268 0 0 0 0 28 26 0 0 100 0 0 r列表示运行和等待cpu时间片的进程数,这个值如果长期大于系统CPU的个数,说明CPU不足,需要增加CPU。 b列表示在等待资源的进程数,比如正在等待I/O、或者内存交换等。 us列显示了用户进程消耗的CPU 时间百分比。us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,就需要考虑优化程序或算法。 sy列显示了内核进程消耗的CPU时间百分比。Sy的值较高时,说明内核消耗的CPU资源很多。 根据经验,us+sy的参考值为80%,如果us+sy大于 80%说明可能存在CPU资源不足。 -
2.top命令(实时监控系统CPU)
[root@localhost ~]# top top - 04:50:43 up 2 days, 13:41, 1 user, load average: 0.10, 0.06, 0.06 Tasks: 102 total, 1 running, 101 sleeping, 0 stopped, 0 zombie %Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 3865308 total, 2912528 free, 573852 used, 378928 buff/cache KiB Swap: 524284 total, 524284 free, 0 used. 3028580 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 38151 root 20 0 0 0 0 S 0.3 0.0 0:01.93 kworker/0:0 1 root 20 0 125332 3828 2496 S 0.0 0.1 0:04.48 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.33 kthreadd top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,常用于服务端性能分析。 第一行数据相当于uptime命令输出。11:00:54是当前时间,up 54 days,23:55 是系统已经运行的时间,6 users表示当前有6个用户在登录,load average:16.32,18.75,21.04分别表示系统一分钟平均负载,5分钟平均负载,15分钟平均负载。 平均负载 平均负载表示的平均活跃进程数,包括正在running的进程数,准备running(就绪态)的进程数,和处于不可中断睡眠状态的进程数。如果平均负载数刚好等于CPU核数,那证明每个核都能得到很好的利用,如果平均负载数大于核数证明系统处于过载的状态,通常认为是超过核数的70%认为是严重过载,需要关注。还需结合1分钟平均负载,5分钟平均负载,15分钟平均负载看负载的趋势,如果1分钟负载比较高,5分钟和15分钟的平均负载都比较低,则说明是瞬间升高,需要观察。如果三个值都很高则需要关注下是否某个进程在疯狂消耗CPU或者有频繁的IO操作,也有可能是系统运行的进程太多,频繁的进程切换导致。比如说上面的演示环境是一台8核的centos机器,证明系统是长期处于过载状态在运行。 第二行的Tasks信息展示的系统运行的整体进程数量和状态信息。102 total 表示系统现在一共有102个用户进程,1 running 1个进程正在处于running状态,101 sleeping 表示101 个进程正处于sleeping状态,0 stopped 表示 0 个进程正处于stopped状态,0 zombie表示 有0个僵尸进程。 第3行的%Cpu(s)表示的是总体CPU使用情况。 us user 表示用户态的CPU时间比例 sy system 表示内核态的CPU时间比例 ni nice 表示运行低优先级进程的CPU时间比例 id idle 表示空闲CPU时间比例 wa iowait 表示处于IO等待的CPU时间比例 hi hard interrupt 表示处理硬中断的CPU时间比例 si soft interrupt 表示处理软中断的CPU时间比例 st steal 表示当前系统运行在虚拟机中的时候,被其他虚拟机占用的CPU时间比例。 第4,5行显示的是系统内存使用情况。单位是KiB。totol 表示总内存,free 表示没使用过的内容,used是已经使用的内存。buff表示用于读写磁盘缓存的内存,cache表示用于读写文件缓存的内存。avail表示可用的应用内存。 第6行开始往后表示的是具体的每个进程状态: PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND PID 进程ID USER 进程所有者的用户名,例如root PR 进程调度优先级 NI 进程nice值(优先级),越小的值代表越高的优先级 VIRT 进程使用的虚拟内存 RES 进程使用的物理内存(不包括共享内存) SHR 进程使用的共享内存 CPU 进程使用的CPU占比 MEM 进程使用的内存占比 TIME 进程启动后到现在所用的全部CPU时间 COMMAND 进程的启动命令(默认只显示二进制,top -c能够显示命令行和启动参数)
4.3 内存性能评估
-
free指令监控内存
[root@localhost ~]# free -m total used free shared buff/cache available Mem: 3774 560 2844 8 370 2957 Swap: 511 0 511 [root@localhost ~]# 一般有这样一个经验公式:应用程序可用内存/系统物理内存>70%时,表示系统内存资源非常充足,不影响系统性能,应用程序可用内存/系统物理内存<20%时,表示系统内存资源紧缺,需要增加系统内存 20%<应用程序可用内存/系统物理内存<70%时,表示系统内存资源基本能满足应用需求,暂时不影响系统性能。
4.4 磁盘I/O性能评估
-
iostat命令
iostat被用于监视系统输入输出设备和CPU的使用情况。它的特点是汇报磁盘活动统计情况,同时也会汇报出CPU使用情况。 [root@localhost ~]# iostat -bash: iostat: command not found [root@localhost ~]# yum -y install sysstat [root@localhost ~]# iostat -d 1 10 #没隔1秒,持续10次 Linux 3.10.0-693.el7.x86_64 (localhost.localdomain) 06/11/2021 _x86_64_ (2 CPU) Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn sda 0.08 1.36 0.66 304530 146757 scd0 0.00 0.00 0.00 1028 0 dm-0 0.00 0.01 0.00 2228 0 对上面每项的输出解释如下: kB_read/s表示每秒读取的数据块数。 kB_wrtn/s表示每秒写入的数据块数。 kB_read表示读取的所有块数。 kB_wrtn表示写入的所有块数。 可以通过kB_read/s和kB_wrtn/s的值对磁盘的读写性能有一个基本的了解,如果kB_wrtn/s值很大,表示磁盘的写操作很频繁,可以考虑优化磁盘或者优化程序,如果kB_read/s值很大,表示磁盘直接读取操作很多,可以将读取的数据放入内存中进行操作。 -
sar 命令系统运行状态统计
通过sar -d组合,可以对系统的磁盘IO做一个基本的统计,请看下面的一个输出 [root@localhost ~]# sar -d 2 6 Linux 3.10.0-693.el7.x86_64 (localhost.localdomain) 06/11/2021 _x86_64_ (2 CPU) 05:46:58 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util 05:47:00 AM dev8-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 05:47:00 AM dev11-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 05:47:00 AM dev253-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 需要关注的几个参数含义: await表示平均每次设备I/O操作的等待时间(以毫秒为单位)。 svctm表示平均每次设备I/O操作的服务时间(以毫秒为单位)。 %util表示一秒中有百分之几的时间用于I/O操作。 对以磁盘IO性能,一般有如下评判标准: 正常情况下svctm应该是小于await值的,而svctm的大小和磁盘性能有关,CPU、内存的负荷也会对svctm值造成影响,过多的请求也会间接的导致svctm值的增加。 await值的大小一般取决与svctm的值和I/O队列长度以及I/O请求模式,如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,则表示I/O队列等待太长,系统上运行的应用程序将变慢,此时可以通过更换更快的硬盘来解决问题。 %util项的值也是衡量磁盘I/O的一个重要指标,如果%util接近100%,表示磁盘产生的I/O请求太多,I/O系统已经满负荷的在工作,该磁盘可能存在瓶颈。长期下去,势必影响系统的性能,可以通过优化程序或者通过更换更高、更快的磁盘来解决此问题。
4.5 网络性能评估
-
常用命令
通过ping命令 检测网络的连通性;
通过netstat –i 组合检测网络接口状况;
通过netstat –r组合 检测系统的路由表信息;
通过sar -n组合 显示系统的网络运行状态;
通过iftop -i eth0 查看网卡流量;fping 检测主机是否存在
-
iftop 命令
iftop是一款实时流量监控工具,监控TCP/IP连接等,缺点就是无报表功能。必须以root身份才能运行 [root@localhost ~]# yum -y install iftop [root@localhost ~]# iftop #默认监控第一块网卡的流量 [root@localhost ~]# iftop -i ens33 #指定监控ens33网卡流量 [root@localhost ~]# iftop -n #直接显示IP, 不进行DNS反解析 -
fping 命令
检测192.168.1.1到192.168.1.10之间的主机是否存在: [root@localhost ~]# fping -a -g 192.168.1.1 192.168.1.10 检测192.168.1.1/24的主机是否存在: [root@localhost ~]# fping -a -g 192.168.1.1/24 将IP列表放在一个文件里面,通过读取文件来检测列表里的主机是否存在: [root@localhost ~]# fping -a -f ip.txt 检测www.baidu.com是否存在: [root@localhost ~]# fping www.baidu.com

5.系统优化实战
5.1找出系统中使用CPU最多的进程
-
方法1
运行top , 找出使用CPU最多的进程 ,按大写的P,可以按CPU使用率来排序显示 -
方法2
按照实际使用CPU,从大到小排序显示所有进程列表 [root@localhost ~]# ps -aux --sort -pcpu | more USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 647 0.1 0.1 305032 6196 ? Ssl Jun08 4:11 /usr/bin/vmtoolsd root 1 0.0 0.0 125332 3844 ? Ss Jun08 0:04 /usr/lib/systemd/system d --switched-root --system --deserialize 21 root 2 0.0 0.0 0 0 ? S Jun08 0:00 [kthreadd] root 3 0.0 0.0 0 0 ? S Jun08 0:00 [ksoftirqd/0] root 5 0.0 0.0 0 0 ? S< Jun08 0:00 [kworker/0:0H] root 6 0.0 0.0 0 0 ? S Jun08 0:02 [kworker/u256:0] root 7 0.0 0.0 0 0 ? S Jun08 0:01 [migration/0] root 8 0.0 0.0 0 0 ? S Jun08 0:00 [rcu_bh] root 9 0.0 0.0 0 0 ? S Jun08 0:20 [rcu_sched] root 10 0.0 0.0 0 0 ? S Jun08 0:02 [watchdog/0] root 11 0.0 0.0 0 0 ? S Jun08 0:02 [watchdog/1] root 12 0.0 0.0 0 0 ? S Jun08 0:01 [migration/1] root 13 0.0 0.0 0 0 ? S Jun08 0:00 [ksoftirqd/1] root 15 0.0 0.0 0 0 ? S< Jun08 0:00 [kworker/1:0H] 注: -pcpu 可以显示出进程绝对路径,方便找出木马程序运行的路径

5.2 找出系统中使用内存最多的进程
-
方法1
使用top命令 运行top , 然后按下大写的M 可以按内存使用率来排序显示 -
方法2
按照实际使用内存,从大到小排序显示所有进程列表 [root@localhost ~]# ps -aux --sort -rss | more 降序 [root@localhost ~]# ps -aux --sort rss | more 升序 [root@localhost ~]# ps -aux --sort -rss | more USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND mysql 31977 0.0 11.8 1183068 456476 ? Sl Jun10 0:16 /usr/local/mysql55/bin/ mysqld --basedir=/usr/local/mysql55 --datadir=/data/mysql --plugin-dir=/usr/local/mysql55 /lib/plugin --user=mysql --log-error=/data/mysql/localhost.localdomain.err --pid-file=/da ta/mysql/localhost.localdomain.pid root 901 0.0 0.4 562428 16576 ? Ssl Jun08 0:32 /usr/bin/python -Es /us r/sbin/tuned -l -P root 911 0.0 0.3 610356 13988 ? Ssl Jun08 0:00 /usr/sbin/libvirtd polkitd 661 0.0 0.2 534264 10184 ? Ssl Jun08 0:00 /usr/lib/polkit-1/polki td --no-debug root 663 0.0 0.2 695264 9332 ? Ssl Jun08 0:21 /usr/sbin/NetworkManage r --no-daemon root 645 0.0 0.2 212120 8588 ? Ssl Jun08 0:17 /usr/sbin/rsyslogd -n root 464 0.0 0.1 36828 6548 ? Ss Jun08 0:09 /usr/lib/systemd/system d-journald
5.3 找出系统中对磁盘读写最多的进程
-
查看系统中哪个磁盘或分区最繁忙?
对于这个服务器,8块磁盘中,哪个硬盘最繁忙?哪个分区最繁忙? 通过iostat命令查看IO是否存在瓶颈 [root@localhost ~]# iostat -d -k -p /dev/sda Linux 3.10.0-693.el7.x86_64 (localhost.localdomain) 06/11/2021 _x86_64_ (2 CPU) Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn sda 0.08 1.35 0.67 305166 151035 sda1 0.02 0.13 0.01 29849 2088 sda2 0.00 0.01 0.00 2500 0 sda3 0.06 1.20 0.66 270744 148946 测试: 给磁盘写入一些内容, 写入时尽可能不读磁盘 读入的数据用/dev/zero ,/dev/zero不会读磁盘的。 sync #把内存中的数据快速写到磁盘上。 只做dd不执行sync,不容易看不出写入效果 [root@localhost ~]# dd if=/dev/zero of=h.txt bs=10M count=1000;sync ^C79+0 records in 79+0 records out 828375040 bytes (828 MB) copied, 32.059 s, 25.8 MB/s 再次查看 [root@localhost ~]# iostat -p sda -dk Linux 3.10.0-693.el7.x86_64 (localhost.localdomain) 06/11/2021 _x86_64_ (2 CPU) Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn sda 0.09 1.35 2.87 305242 650691 sda1 0.02 0.13 0.01 29849 2088 sda2 0.00 0.01 0.00 2500 0 sda3 0.07 1.20 2.86 270820 648602 [root@localhost ~]# -
iotop命令,查看哪个进程使用磁盘读写最多
[root@localhost ~]# yum -y install iotop [root@localhost ~]# iotop -o -d 1 o 只显示有io操作的进程 -b 批量显示,无交互,主要用作记录到文件 -n NUM 显示NUM次,主要用于非交互式模式 -d SEC 间隔SEC秒显示一次 -p PID 监控的进程pid -u USER 监控的进程用户

5.4 找出系统中使用网络最多的进程
-
nload 监控总体带宽使用情况
[root@localhost ~]# yum install nload -y #安装nload工具 [root@localhost ~]# nload #开启监控 另外重新打开一个终端,然后产生一些测试数据 [root@localhost ~]# ab -n 1000 -c 2 http://www.baidu.com/index.html 测试结果 [root@localhost ~]# nload Device ens33 [192.168.10.10] (1/2): ========================================================================================= Incoming: # # # # Curr: 28.07 MBit/s # Avg: 28.07 MBit/s # Min: 28.07 MBit/s # Max: 28.07 MBit/s # Ttl: 145.24 MByte Outgoing: Curr: 350.62 kBit/s Avg: 350.62 kBit/s Min: 350.62 kBit/s Max: 350.62 kBit/s . Ttl: 4.76 MByte Device ens33 [192.168.10.10] (1/2): ========================================================================================= Incoming: ## ## ## ## Curr: 28.48 MBit/s ## Avg: 28.48 MBit/s ## Min: 28.07 MBit/s ## Max: 28.48 MBit/s ## Ttl: 147.06 MByte Outgoing: Curr: 353.68 kBit/s Avg: 353.68 kBit/s Min: 350.62 kBit/s Max: 353.68 kBit/s .. Ttl: 4.79 MByte -
nethogs 使用带宽最多的进程
[root@localhost ~]# yum -y install nethogs #安装nethogs工具 [root@localhost ~]# nethogs #开启监控 在另外开一个终端下载 wget东西 [root@localhost ~]# wget https://downloads.mysql.com/archives/get/p/23/file/mysql-5.6.20.tar.gz 监控测试显示结果 [root@localhost ~]# nethogs Ethernet link detected Waiting for first packet to arrive (see sourceforge.net bug 1019381) NetHogs version 0.8.5 PID USER PROGRAM DEV SENT RECEIVED 39738 root wget ens33 21.877 4158.442 KB/sec 38492 root sshd: root@pts/0 ens33 0.870 0.211 KB/sec ? root unknown TCP 0.000 0.000 KB/sec TOTAL 22.747 4158.653 KB/sec
5.5 优化linux文件打开最大数
在生产环境中,由于某些软件、应用程序发挥最大的性能,使用Linux内核默认资源显然不够的,要对Linux内核资源进行重新修改和调整,对Linux内核资源进行优化
默认Linux内核对每个用户设置了打开文件最大数为1024,对于高并发网站,是远远不够的,需要将默认值调整到更大
inux每个用户打开文件最大数永久设置方法,将如下代码加入内核限制文件/etc/security/limits.conf的末尾:
* soft noproc 65535
* hard noproc 65535
* soft nofile 65535
* hard nofile 65535
如上设置为对每个用户分别设置nofile、noproc最大数,如果需要对Linux整个系统设置文件最大数限制,需要修改/proc/sys/fs/file-max中的值,该值为Linux总文件打开数,
例如设置为:echo 3865161233 >/proc/sys/fs/file-max。

6.内核参数优化
vi /etc/sysctl.conf
net.ipv4.tcp_max_tw_buckets = 6000
timewait的数量,默认是180000。
net.ipv4.ip_local_port_range = 1024 65000
允许系统打开的端口范围。
net.ipv4.tcp_tw_recycle = 1
启用timewait快速回收。
net.ipv4.tcp_tw_reuse = 1
开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接。
net.ipv4.tcp_syncookies = 1
开启SYN Cookies,当出现SYN等待队列溢出时,启用cookies来处理。
net.core.somaxconn = 262144
web应用中listen函数的backlog默认会给我们内核参数的net.core.somaxconn限制到128,而nginx定义的NGX_LISTEN_BACKLOG默认为511,所以有必要调整这个值。
net.core.netdev_max_backlog = 262144
每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。
net.ipv4.tcp_max_orphans = 262144
系统中最多有多少个TCP套接字不被关联到任何一个用户文件句柄上。如果超过这个数字,孤儿连接将即刻被复位并打印出警告信息。这个限制仅仅是为了防止简单的DoS攻击,不能过分依靠它或者人为地减小这个值,更应该增加这个值(如果增加了内存之后)。
net.ipv4.tcp_max_syn_backlog = 262144
记录的那些尚未收到客户端确认信息的连接请求的最大值。对于有128M内存的系统而言,缺省值是1024,小内存的系统则是128。
net.ipv4.tcp_timestamps = 0
时间戳可以避免序列号的卷绕。一个1Gbps的链路肯定会遇到以前用过的序列号。时间戳能够让内核接受这种“异常”的数据包。这里需要将其关掉。
net.ipv4.tcp_synack_retries = 1
为了打开对端的连接,内核需要发送一个SYN并附带一个回应前面一个SYN的ACK。也就是所谓三次握手中的第二次握手。这个设置决定了内核放弃连接之前发送SYN+ACK包的数量。
net.ipv4.tcp_syn_retries = 1
在内核放弃建立连接之前发送SYN包的数量。
net.ipv4.tcp_fin_timeout = 1
如果套接字由本端要求关闭,这个参数决定了它保持在FIN-WAIT-2状态的时间。对端可以出错并永远不关闭连接,甚至意外当机。缺省值是60秒。2.2 内核的通常值是180秒,你可以按这个设置,但要记住的是,即使你的机器是一个轻载的WEB服务器,也有因为大量的死套接字而内存溢出的风险,FIN- WAIT-2的危险性比FIN-WAIT-1要小,因为它最多只能吃掉1.5K内存,但是它们的生存期长些。
net.ipv4.tcp_keepalive_time = 30
当keepalive起用的时候,TCP发送keepalive消息的频度。缺省是2小时。
总结
如果你阅读到这里,我相信你一定和我一样,正在努力的变成一个优秀的运维工程师,朝着心中的那一方净土出发。
关于linux系统内核优化。总体从系统和应用程序出发,但如果在具体点,我们还是从以下方面去考虑:
硬件层面
CPU、内存、硬盘容量、硬盘I/O读写、网卡自身带宽容量等,通常对硬件层面因素的优化主要是考虑增加其配置;软件层面
Linux系统下各个应用程序:Nginx、Tomcat、MYSQL、Redis、程序代码、网站代码等,对其网站代码、软件的配置文件参数优化、优化软件架构、是否增加集群、分布式结构以扩展软件的本身的性能;系统层面
选择比较稳定的Linux操作系统发行版、减少不必要的服务、端口、修改Linux内核自身的限制、对Linux内核实施优化(打开端口数、进程数、文件数等);网络层面
引入性能比较强硬件网络设备、交换机、路由器、防火墙,增加网络设备的背板带宽、带宽容量、吞吐率、运营商购买带宽容量等;
写作不易,点个赞,收藏下哦,方便以后查找。
以上是关于关于linux系统调优这一篇文章就够了的主要内容,如果未能解决你的问题,请参考以下文章