深度学习之openvino预训练模型测试
Posted ZONG_XP
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习之openvino预训练模型测试相关的知识,希望对你有一定的参考价值。
0 背景
在《深度学习之win10安装配置openvino》中我们介绍了 openvino 的安装方法,本文对下一步的使用进行一个介绍。
1 模型介绍
openvino 提供了一系列的预训练模型,包含 intel 预训练模型以及 public 预训练模型,覆盖了目标检测、语义分割、实例分割等常见任务。
随着不同版本的更新,提供的预训练模型也越来越丰富。
对于 intel 提供的预训练模型,我们可以直接在 openvino 中进行调用,而对于 public 预训练模型,则需要有一个转化过程,本文对这两类模型的应用方法做详细的介绍。
1.1 intel 预训练模型
- Action Recognition Models / 行为识别模型
- Classification Models / 图像分类模型
- Head Pose Estimation Models / 头部姿态估计模型
- Human Pose Estimation Models / 人体姿态估计模型
- Image Processing Models / 图像处理模型(超分辨率)
- Instance Segmentation Models / 实例分割模型
- Machine Translation Models / 机器翻译模型
- Object Attribute Estimation Models / 目标属性估计模型(年龄、性别、关键点、汽车属性等)
- Object Detection Models / 目标检测模型(人脸、人员、汽车、自行车等)
- Optical Character Recognition Models / OCR 字符识别
- Question Answering Models / 问答模型
- Semantic Segmentation Models / 语义分割模型
- Text-to-speech Models / 文本转语音模型
- Token Recognition Models / token 识别模型
1.2 public 预训练模型
- Action Recognition Models / 动作识别模型
- Classification Models / 分类模型(densenet、googlenet、mobilenet、resnet、vgg等)
- Colorization Models / 着色模型
- Face Recognition Models / 人脸识别模型
- Human Pose Estimation Models / 人体姿态估计模型
- Image Inpainting Models / 图像修复模型
- Image Processing Models / 图像处理模型(去模糊 deblurgan)
- Image Translation Models / 图像翻译模型
- Instance Segmentation Models / 实例分割模型
- Monocular Depth Estimation Models / 单目深度估计模型
- Object Attribute Estimation Models / 目标属性估计模型
- Object Detection Models / 目标检测模型
- Optical Character Recognition Models / OCR 字符识别模型(车牌识别)
- Place Recognition Models / 位置识别模型
- Semantic Segmentation Models / 语义分割模型
- Sound Classification Models / 声音分类模型
- Speech Recognition Models / 语音识别模型
- Style Transfer Models / 风格转换模型
- Text-to-speech Models / 文本转语音模型
2 intel 预训练模型测试
2.1 模型介绍
我们以语义分割模型为例,测试 Semantic Segmentation Models 中的 unet-camvid-onnx-0001 模型,从名字可以看出来,这是一个在 camvid 数据集上训练过的 unet 模型。数据集包含 12 个类别,分别是 Sky、Building、Pole、Road、Pavement、Tree、SignSymbol、Fence、Vehicle、Pedestrian、Bike、Unlabeled。
模型性能如下,可通过比较不同模型的参数量和精度来选择满足自己需求的模型,比如追求速度,选择参数量少的模型,追求精度,选择 mIou 高的模型。
| 指标 | 值 |
| GFlops | 260.1 |
| MParams | 31.03 |
| Source Framework | PyTorch |
| mIou | 71.95% |
输入信息:
Image, shape - 1,3,368,480, format is B,C,H,W where:
B- batch sizeC- channelH- heightW- width
Channel order is BGR
Semantic segmentation class probabilities map, shape -1,12,368,480, output data format is B,C,H,W where:
B- batch sizeC- predicted probabilities of input pixel belonging to classCin the [0, 1] rangeH- horizontal coordinate of the input pixelW- vertical coordinate of the input pixel
2.2 模型下载
了解了模型的基本情况后,我们下载模型进行测试。在 SDK 的 C:\\Program Files (x86)\\IntelSWTools\\openvino_2020.3.355\\deployment_tools\\tools\\model_downloader 路径中,包含有模型下载的脚本 downloader.py
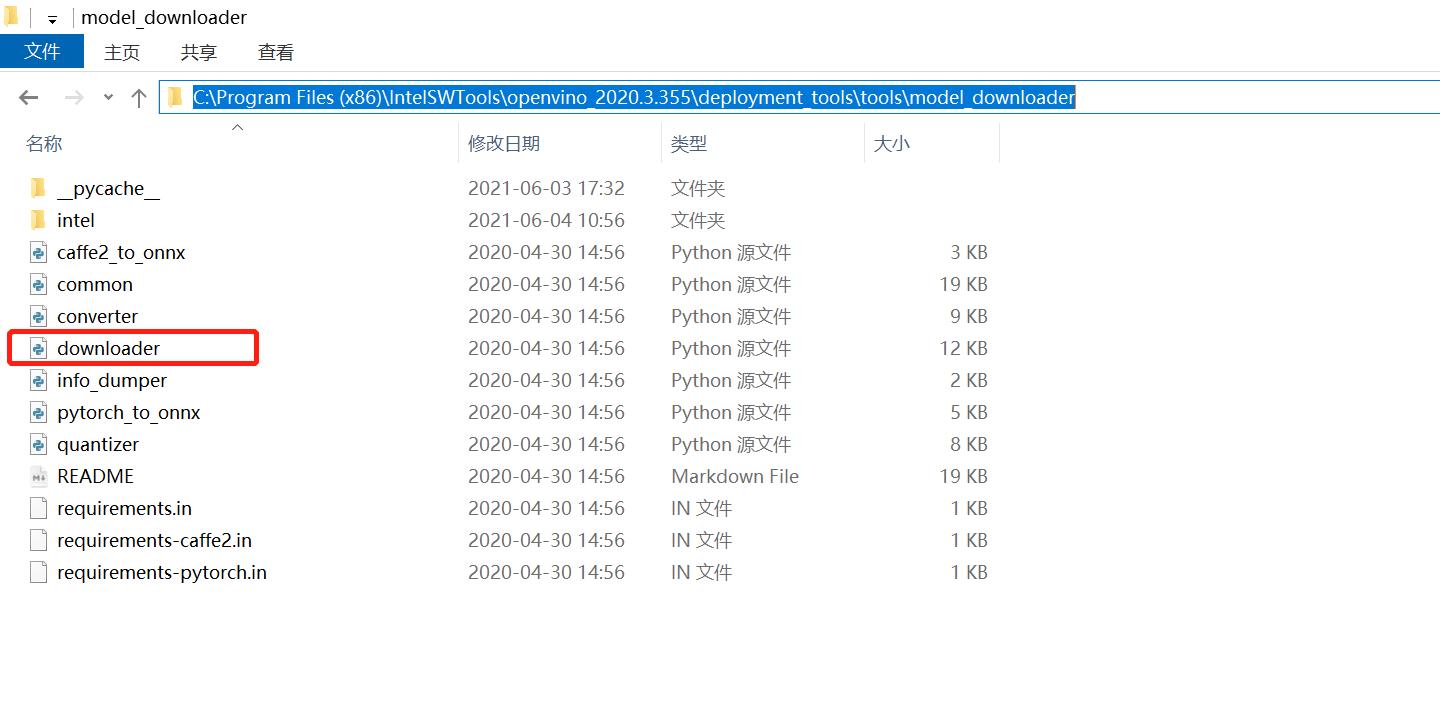
我们在 cmd 或 powershell 终端中查看一下该脚本的使用方法
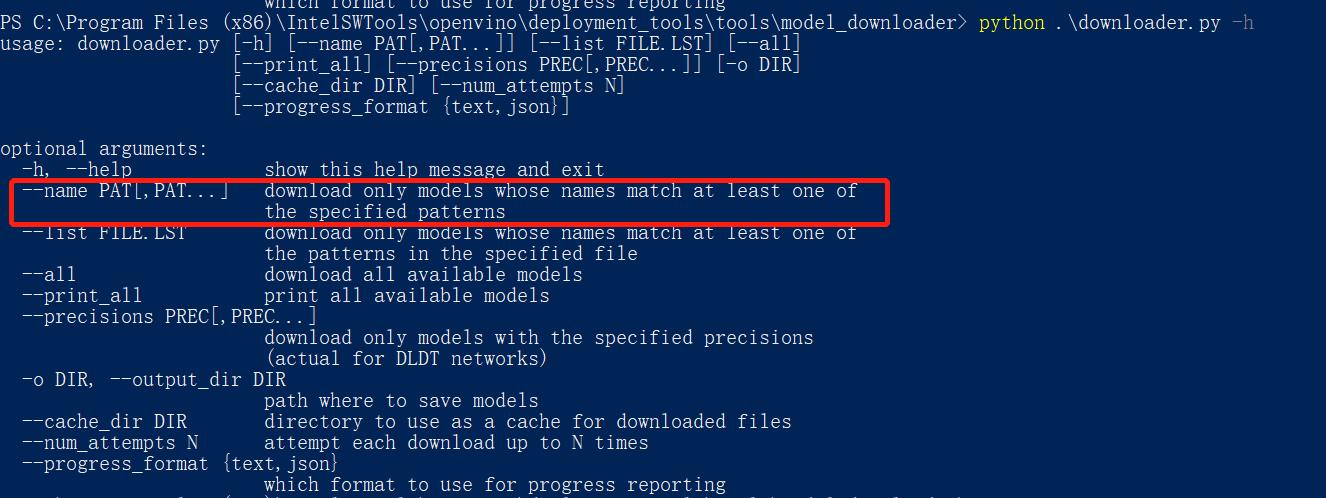
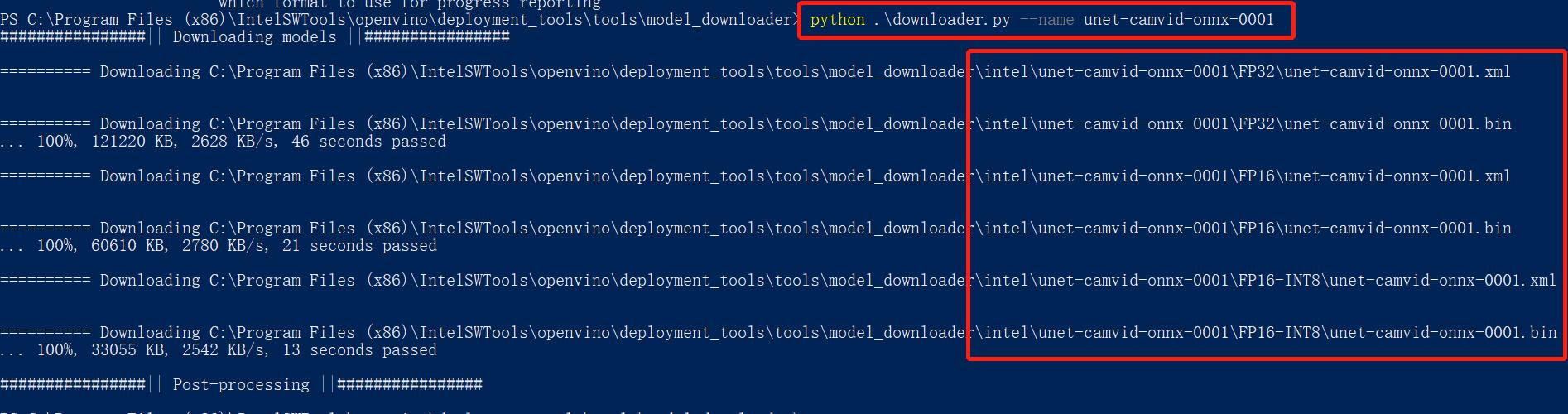
可以看到,只需要指定一下模型名称就行,下载后的模型路径在 C:\\Program Files (x86)\\IntelSWTools\\openvino_2020.3.355\\deployment_tools\\tools\\model_downloader\\intel\\unet-camvid-onnx-0001
2.3 工程编译
在 sdk 中,提供了一系列的 Demos,实现不同功能的检测,以 C++ 为主,也有一部分 python 代码,路径位于 C:\\Program Files (x86)\\IntelSWTools\\openvino_2020.3.355\\deployment_tools\\open_model_zoo\\demos
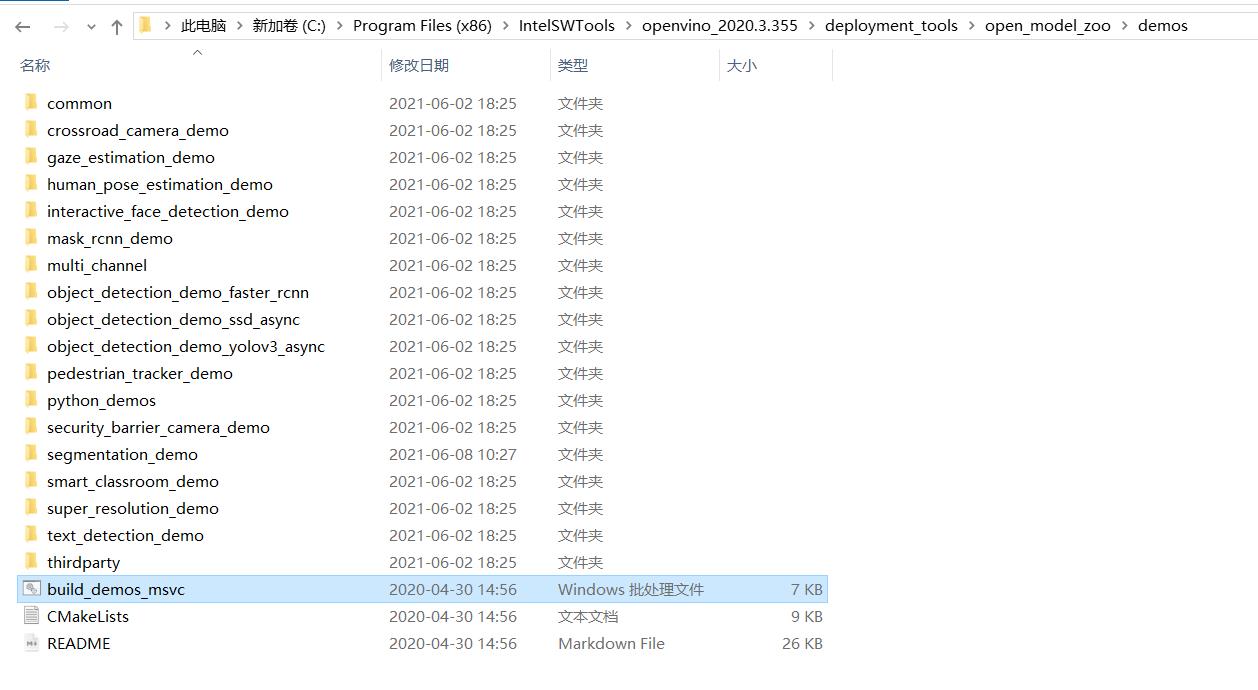
在终端中运行 build_demos_msvc.bat, 可以对这些 demos 进行批量处理,在 C:\\Users\\ZONGXP\\Documents\\Intel\\OpenVINO\\omz_demos_build 路径下(根据自己的用户名查找)生成工程文件
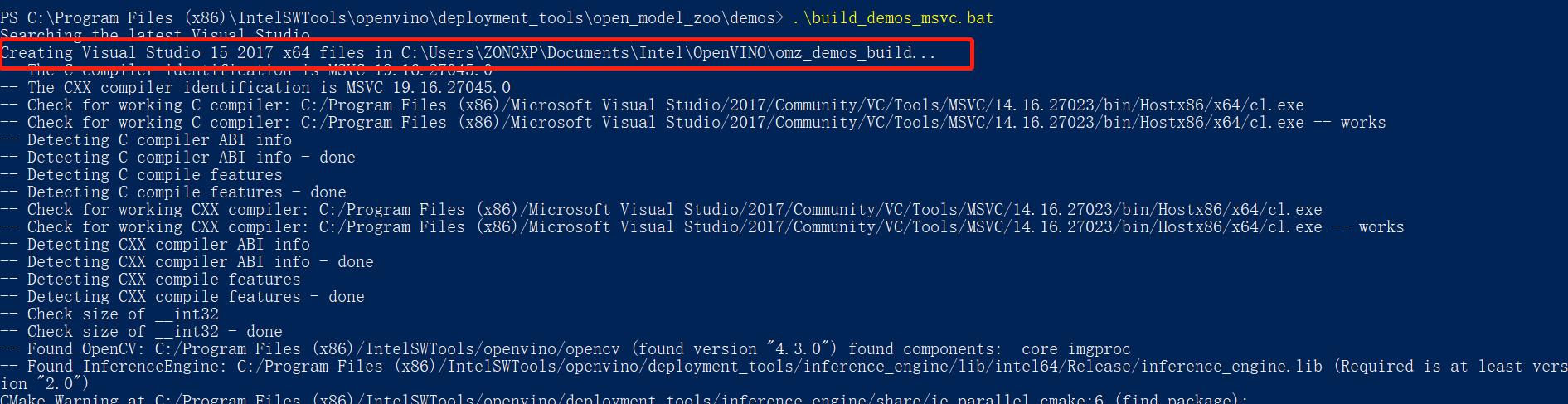
在 intel64/Release 生成了我们要用的可执行文件,其中就有 segmentation_demo.exe
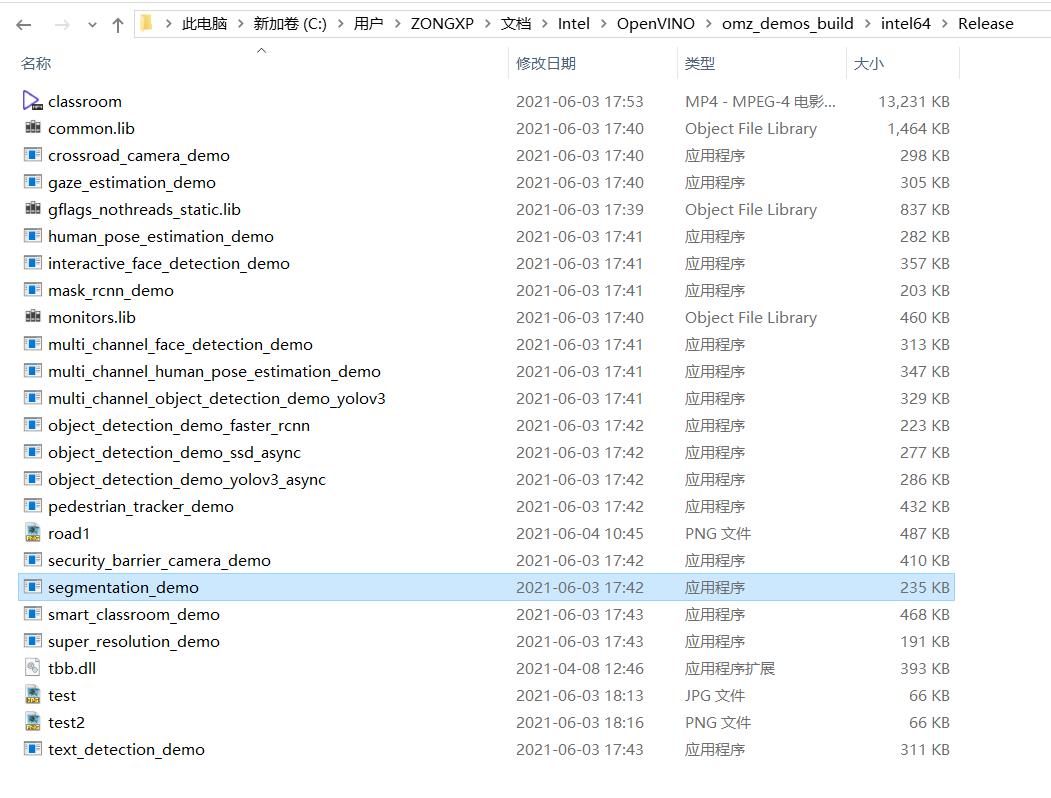
2.3 工程测试
在终端中查看使用方法,可以看到需要指定输入要处理的图片,以及模型路径

我们使用一张 camVID 数据集中的照片进行测试,并指定刚才下载的 unet 预训练模型

运行结果
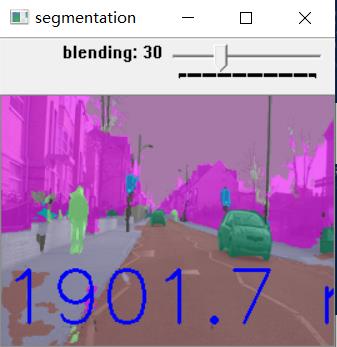
注意代码默认运行在 CPU 上,如果要使用算力棒或 GPU 设备,则使用 -d 指令指定

可以看到,在我的测试环境中,算力棒的算力比不过笔记本的 CPU,说明了这种设备适合应用于 CPU 比较弱的设备上,才会有加速效果。
3 public 预训练模型
emm...突然发现,我使用的 openvino 版本有点低,Version 2020.3,没有按照我说的这种方法进行分类,即区分 intel 和 public,因此本文先到这里,有时间了升级一下版本,再做进一步测试
4 参考
以上是关于深度学习之openvino预训练模型测试的主要内容,如果未能解决你的问题,请参考以下文章