使用Python爬虫技术获取动态网页数据简洁方法与实践案例
Posted 肖永威
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Python爬虫技术获取动态网页数据简洁方法与实践案例相关的知识,希望对你有一定的参考价值。
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。Python语言,就可以作为爬虫算法的编写语言。
1. 网络爬虫技术概述
对于非软件专业开发人员来说,网络爬虫技术还是比较复杂的。对于专业B/S结构软件开发人员,网络爬虫软件开发技术是围绕Http协议展开的,主要涉及到知识点有URL、Http请求与Webservice、数据格式。
对于非软件专业开发人员来说,一般合法获取动态数据,可以简单的理解为机器人自动通过浏览器查询网页,自动记录获取的数据,也就是如下图所示发请求(Request)及返回(Respone)过程,和分析网页记录数据过程。
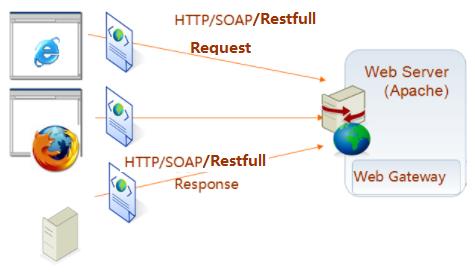
1.1. Http网络处理过程
Http网络处理过程简化描述是以下步骤:
客户端(例如浏览器Chrome、自己开发的Python的程序)通过URL发http请求,服务端响应请求,返回html+CSS+JavaScipt代码(含数据),而JavaScipt代码中可能含有URL请求,动态的再请求,直到加载完成整个网页。
我们常说爬虫其实就是在这一堆的动态HTTP请求中,找到能给我们返回需要数据的URL链接,无论是网页链接还是App抓包得到的API链接,我们获取后,模拟客户端发送一个请求包,得到一个返回包,我们再针对返回包解析数据。主要内容有:
- URL
- 请求方法(POST, GET)
- 请求包headers
- 请求包内容
- 返回包headers
http请求由请求行,消息报头,请求正文三部分构成。

| 请求方法 | 说明 |
|---|---|
| GET | 请求获取Request-URI所标识的资源 |
| POST | 在Request-URI所标识的资源后附加新的数据 |
| HEAD | 请求获取由Request-URI所标识的资源的响应消息报头 |
| PUT | 请求服务器存储一个资源,并用Request-URI作为其标识 |
| DELETE | 请求服务器删除Request-URI所标识的资源 |
| TRACE | 请求服务器回送收到的请求信息,主要用于测试或诊断 |
| CONNECT | 保留将来使用 |
| OPTIONS | 请求查询服务器的性能,或者查询与资源相关的选项和需求 |
HTTP响应也由三部分组成,包括状态行,消息报头,响应正文。

我们关心的是响应正文,直接截取我们需要的数据。当然,常用的方法是解析响应的页面,很多时候更完整。
1.2. 数据解析
http请求返回格式就是http响应,有固定格式,但是数据体可能多种多样。常用有四种方式:
- 正则表达式
- requests-html
- BeautifulSoup
- lxml的XPath
2. 爬取成品油零售价格数据实践案例
我们偶尔需要获取互联网上某些数据,例如需要最近今年成品油零售价格数据。
2.1. 找到数据源
全国油价数据中心(http://data.eastmoney.com/cjsj/oil_default.html)。
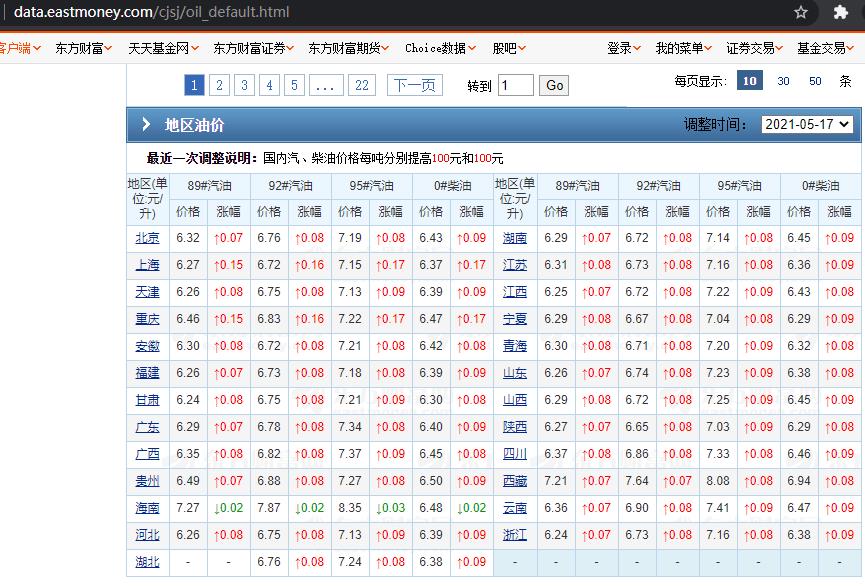
2.2. 找到网页数据查询接口
Fiddler是一种常见的抓包分析软件,我们可以利用Fiddler详细的对HTTP请求进行分析,并模拟对应的HTTP请求。
使用Fiddler时,本地终端浏览器和服务器之间所有的Request,Response都将经过Fiddler,由Fiddler进行转发。由于所有的数据都会经过Fiddler,所以Fiddler能够截获这些数据没实现网络数据抓包。如下图为Fiddler抓取网络链接请求情况。
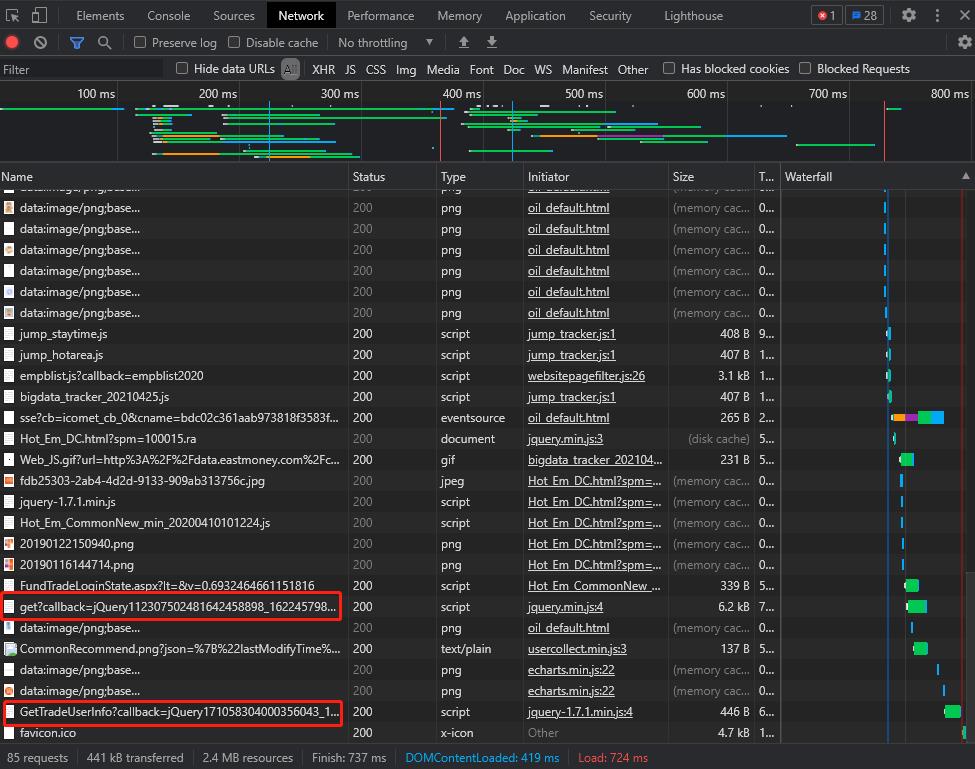
跟踪、分析网络请求,发现如下链接是获取数据的接口:

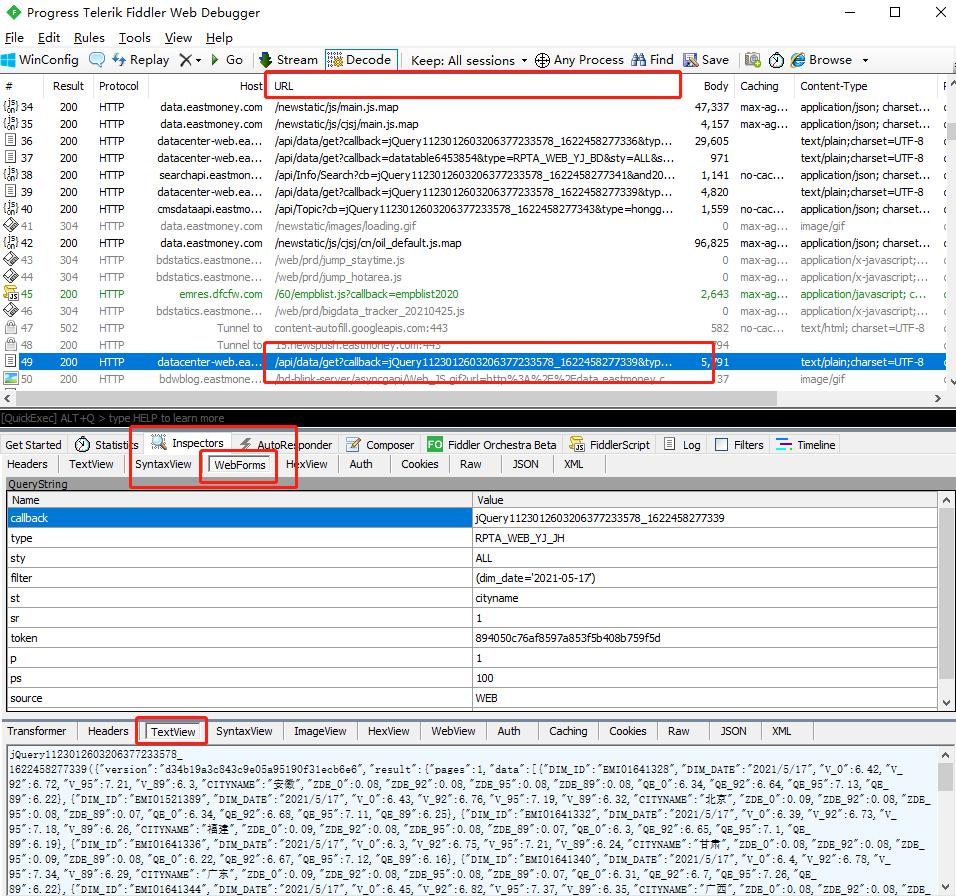
通过跟踪监控请求,在WebForms请求表单中,找到日期数据,也就是接口API的变量。
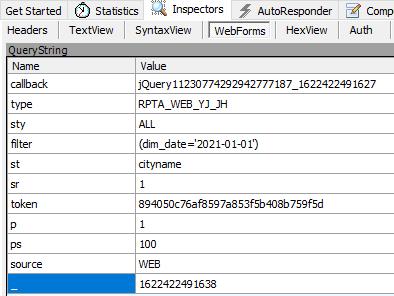
感兴趣,可以自己再找下日期变量列表的API。
2.3. 分析返回数据格式
分析网页太麻烦了,直接截取数据方式分析爬取结果。
数据格式:
jQuery11230774292942777187_1622422491627(
{"version":"cafaf0743a45b7965a243c937f23dea5",
"result":{"pages":1,"data":[
{"DIM_ID":"EMI01641328","DIM_DATE":"2021/2/1","V_0":5.8,"V_92":6.13,"V_95":6.59,"V_89":5.74,"CITYNAME":"安徽","ZDE_0":0.06,"ZDE_92":0.06,"ZDE_95":0.06,"ZDE_89":0.06,"QE_0":5.74,"QE_92":6.07,"QE_95":6.53,"QE_89":5.68},
{"DIM_ID":"EMI01521389","DIM_DATE":"2021/2/1","V_0":5.81,"V_92":6.16,"V_95":6.56,"V_89":5.76,"CITYNAME":"北京","ZDE_0":0.06,"ZDE_92":0.06,"ZDE_95":0.07,"ZDE_89":0.05,"QE_0":5.75,"QE_92":6.1,"QE_95":6.49,"QE_89":5.71},
{"DIM_ID":"EMI01641332","DIM_DATE":"2021/2/1","V_0":5.77,"V_92":6.14,"V_95":6.55,"V_89":5.71,"CITYNAME":"福建","ZDE_0":0.06,"ZDE_92":0.06,"ZDE_95":0.06,"ZDE_89":0.05,"QE_0":5.71,"QE_92":6.08,"QE_95":6.49,"QE_89":5.66}
],"count":25},"success":true,"message":"ok","code":0}
);
2.4. Python实现抓取数据
本案例使用了requests模块,需要单独安装,如下所示:
pip install requests
# -*- coding: utf-8 -*-
'''
Created on 2021年5月31日
@author: 肖永威
'''
import requests
import re
import json
from datetime import datetime
import pandas as pd
from time import sleep
import random
class Crawler(object):
def __init__(self):
# 东方财富接口
self.url = 'http://datacenter-web.eastmoney.com/api/data/get'
# 调价日期接口API
self.params_date = 'callback=jQuery112300671446287155848_1622441721838&type=RPTA_WEB_YJ_RQ&sty=ALL&st=dim_date&sr=-1&token=894050c76af8597a853f5b408b759f5d&p=1&ps=5000&source=WEB&_=1622441721839'
# 油价接口API
self.params_price = 'callback=jQuery11230774292942777187_1622422491627&type=RPTA_WEB_YJ_JH&sty=ALL&filter=(dim_date%3D%27$date$%27)&st=cityname&sr=1&token=8&p=1&ps=100&source=WEB&_=1622422491638'
# 取调价时间
def getDates(self,start_date):
dates_json = self._getResponse(self.params_date)
self.dates = []
start_date = datetime.strptime(start_date, "%Y-%m-%d").date()
for dates in dates_json:
dim_date = dates['dim_date']
dim_date = dim_date.replace('/','-')
if datetime.strptime(dim_date, "%Y-%m-%d").date() >= start_date:
self.dates.append(dim_date)
print (self.dates)
# 取价格
def getOilprice(self):
self.pricedatas = []
k = len(self.dates)
i = 0
for dates in self.dates:
params_price = self.params_price.replace('$date$', dates)
prices_json = self._getResponse(params_price)
self.pricedatas.extend(prices_json)
sleep(random.randint(0,3))
i = i + 1
print('完成:{:.2%}'.format(i/k))
self.df = pd.DataFrame(self.pricedatas)
#self.df.to_csv('price20210531.csv',encoding='utf_8_sig')
print(self.pricedatas)
# 取API返回值
def _getResponse(self,params):
r = requests.get(self.url,params)
# 正则表达式,获取括号里的JSON数据
p = re.compile(r'[(](.*?)[)]', re.S)
jsondata = re.findall(p,r.text)
# 返回数据为Json格式
result = json.loads(jsondata[0])
return result['result']['data']
def main():
Oil_prices = Crawler()
tmp = Oil_prices.getDates('2008-03-01')
Oil_prices.getOilprice()
if __name__ == '__main__':
main()
2.5. 数据解析
由于是直接截取API返回数据,处理起来相对简单些,直接使用正则方式,匹配出内嵌JSON数据。
其中,代码片段:
r = requests.get(self.url,params)
# 正则表达式,获取括号里的JSON数据
p = re.compile(r'[(](.*?)[)]', re.S)
jsondata = re.findall(p,r.text)
# 返回数据为Json格式
result = json.loads(jsondata[0])
return result['result']['data']
3. 总结
关于爬虫技术,如果仅仅是提高获取数据速度和方便性,实际上也是比较简单的,从IT软件视角来看,都是很成熟的技术和协议,如果你会JSP、前后端分离开发、SOA技术,合法的爬虫将会很简单。重点是找到请求的URL,识别接口API和参数变量。
推荐多了解Webservice接口技术,提高解析数据效率。
参考:
《python爬虫之requests的使用》 博客园 , lweiser ,2019年6月
《深入理解HTTP协议》 知乎 ,零壹技术栈,2018年9月
《通过fiddler抓取HTTP协议的数据包 | 详细介绍fiddler使用过程。西边人西说测试》 CSDN博客 ,西边人细说测试 ,2018年3月
《Fiddler抓HTTP和HTTPS(手机/电脑)数据包步骤》 CSDN博客 ,梦想成为大佬的菜鸟 ,2019年11月
以上是关于使用Python爬虫技术获取动态网页数据简洁方法与实践案例的主要内容,如果未能解决你的问题,请参考以下文章