预算分配Budget Allocation:Morphl-AI的营销科学解决方案
Posted 悟乙己
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了预算分配Budget Allocation:Morphl-AI的营销科学解决方案相关的知识,希望对你有一定的参考价值。
文章目录
1 公司介绍
Morphl是一家国外提供AI解决方案的公司(PS:这家公司,web UI挺好看的~):
网址:https://morphl.io/products/morphl-cloud.html
MorphL社区版
MorphL Community Edition使用大数据和机器学习来预测数字产品和服务中的用户行为,其目标是通过个性化来提高KPI(点击率,转换率等),主要涵盖的模型包括:
- 模型1 : 人群购物阶段模型shopping stage - 高潜力购买人群圈选;
精确定位那些更有可能加入购物车、去结账或完成交易的用户。 - 模型2 : 购物丢失模型 cart abandonment - 加购易丢失人群圈选 ;
精确定位那些更有可能在当前或下一回合放弃购物车的用户。 - 模型3 : Customers LTV - 生命周期模型
通过关注具有较低或中等客户终身价值的用户,减少客户流失,将他们转变为忠实客户。 - 个性化推荐模型
- 关联产品模型
- 高频购买模型
- 搜索意图
- 人群分类
- 流失预警
2 预算分配
在morphl理论体系里面,预算分配包含两个步骤:
- 计算,budge -> revence 预算到收入之间的函数关系
- 计算,每个活动的预算分配优化模型
第一步 预算/收入预测函数
f(Cost) = f(Cost(t) | Cost(t-1), Revenue(t-1), ... Cost(t0), Revenue(t0)) = Revenue function
根据历史的预算/收入数据,进行预测
第二步 预算最优化问题
在有了每个活动预算/收入预测函数之后,就可以开始解决预算最优化,以下有三种情况:
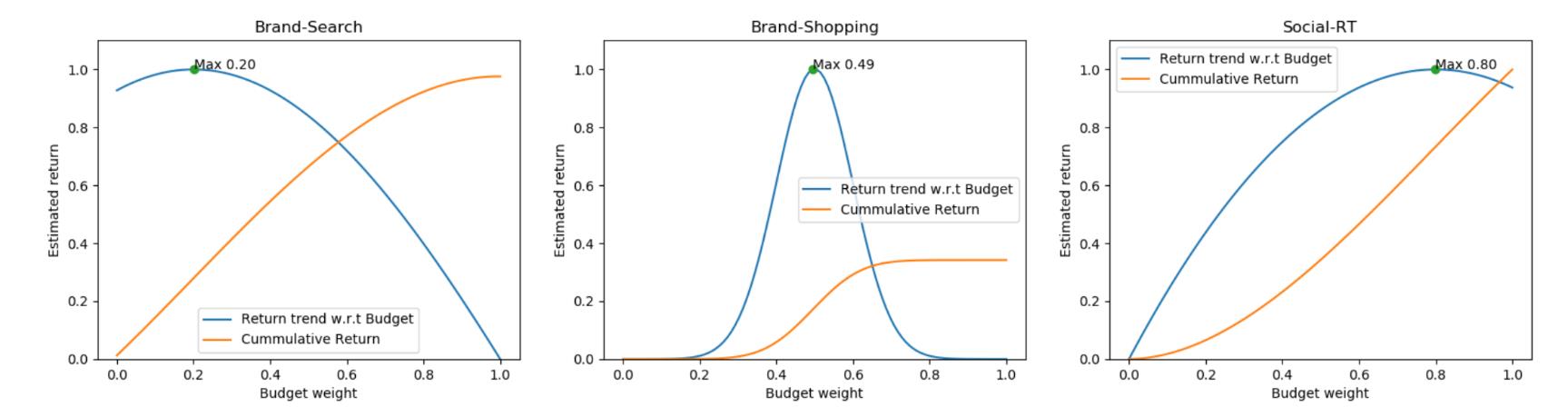
黄线是预算/投入金额累计线;
蓝线是预算/投入效率曲线(原文表示:The blue line is the relation between the budget and the returning sum.)
曲线的顶点就是最佳的budge范围,可以帮助进行预算分配
3 相关案例解读
3.1 相关数据样式
github地址:Morphl-AI/Ecommerce-Marketing-Spend-Optimization
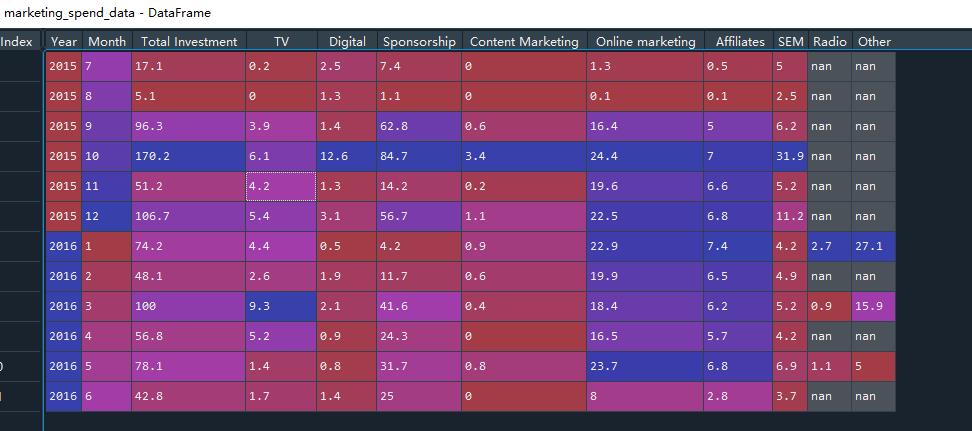
来看github放开的两个数据源格式:
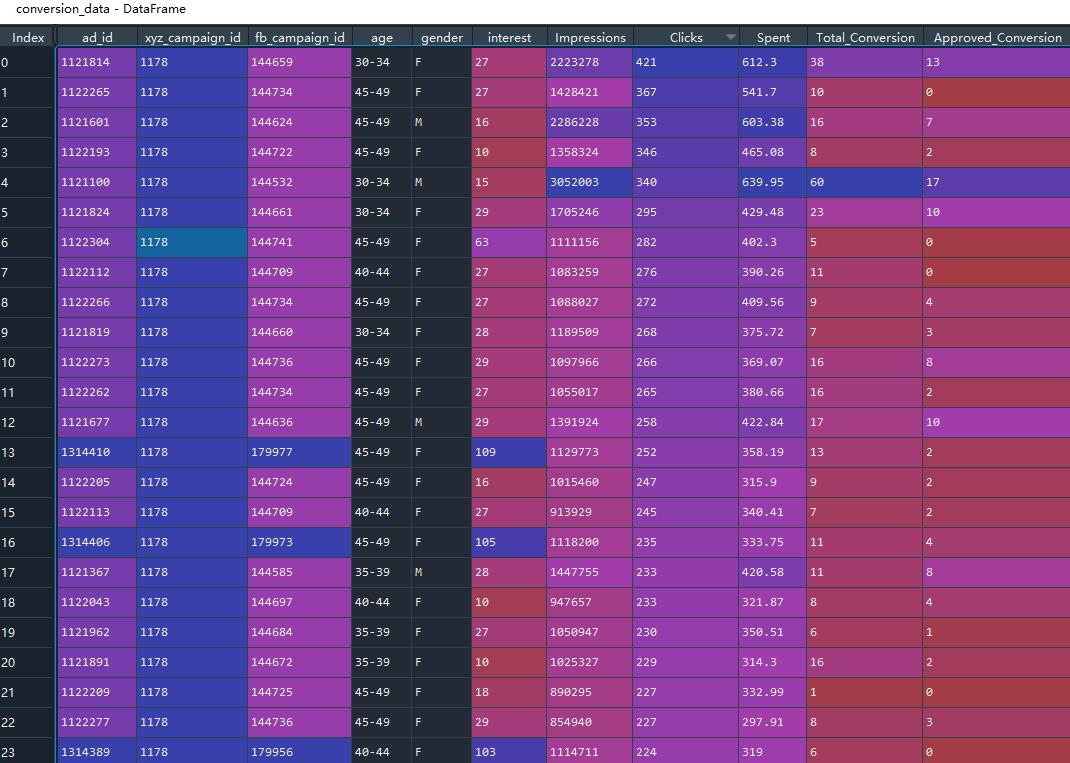
- 市场花费数据,包括年份,总投入,TV/Digital 等渠道的收入
- 渠道转化数据,广告ID,FB活动ID,年龄,性别,曝光,点击,花费,转化等
其中的几个案例,介绍了几种他们常用的方法:
3.2 2. Budget optimization - basic statistical model
这里其实是非常简单的几种方法
- 收入 ~ 投入,直接除法算ROI
- 收入 ~ 曝光,曝光 ~ 投入,也是直接除法换算
3.3 4. Budget allocation - pseudo-revenue - first-revenue assumption - regressions
- 用上了回归模型来计算,Revenue~cost
- 举例了两种做法,Revenue ~ cost 两变量回归;rev ~ cost + click等协变量
这里有一个bucket index概念,还没特别看懂,猜测是一个合理的活动间隔期,类似session
Let a bucket be: C o s t B = [ 0 , 0 , 50 , 20 , 0 , 15 ] Cost_B=[0, 0, 50, 20, 0, 15] CostB=[0,0,50,20,0,15], R e v e n u e B = [ 30 , 100 ] Revenue_B=[30, 100] RevenueB=[30,100].
This means that the first revenue (30) was generated by the first two costs alone,
so we merged the next bucket as well.
We’ll sum them, getting C Σ B = 85 C_{\\Sigma B}=85 CΣB=85 and R Σ B = 130 R_{\\Sigma B}=130 RΣB=130. Then, the bucket constant is: α B = 130 / 85 = 1.529 \\alpha_B=130/85=1.529 αB=130/85=1.529.
Then, our pseudo-revenues will be: P s e u d o − R e v e n u e B = [ 0 ∗ α B , 0 ∗ α B , 50 ∗ α B , 20 ∗ α B , 0 ∗ α B , 15 ∗ α B ] = [ 0 , 0 , 76.45 , 30.58 , 0 , 22.935 ] Pseudo-Revenue_{B} = [0*\\alpha_B, 0*\\alpha_B, 50*\\alpha_B, 20*\\alpha_B, 0*\\alpha_B, 15*\\alpha_B] = [0, 0, 76.45, 30.58, 0, 22.935] Pseudo−RevenueB=[0∗αB,0∗αB,50∗αB,20∗αB,0∗αB,15∗αB]=[0,0,76.45,30.58,0,22.935].
借助上述例子,猜测,
- 为什么不是一一对应:
[
0
,
0
,
50
,
20
,
0
,
15
]
−
>
[
r
1
,
r
2
,
r
3
,
r
4
,
r
5
]
[0,0,50,20,0,15] -> [r1,r2,r3,r4,r5]
[0,0,50,20,0,15]−>[r1,r2,r3,r4,r5]
因为投入 和 统计收入 不是同步的,投入之后会需要一段时间来统计。 - 如何一一对应?
可以采用一些数据插补策略,比如算一个总的bucket constant
3.4 5. Budget allocation - pseudo-revenue - one-week assumption - regressions
第四案例,可能是间断式的活动,那么第五个案例,可能是一个长期的案例,
所以这里的bucket时间间隔是固定的1周,以此进行计算。
4 代码测试
github地址:Morphl-AI/Ecommerce-Marketing-Spend-Optimization
来看github放开的两个数据源格式:
- 市场花费数据,包括年份,总投入,TV/Digital 等渠道的收入
- 渠道转化数据,广告ID,FB活动ID,年龄,性别,曝光,点击,花费,转化等
4.1 简单系数一阶收入预测
对应jupyter - 2. Budget optimization - basic statistical model
就是直接 => R e v / C o s t Rev / Cost Rev/Cost
import pandas as pd
'''
模型一:直接算个总的ROI
Directly modeling f(Cost) = Revenue
'''
class StatisticalModel:
def __init__(self):
# This model has just a single parameter, computed as the count between targets and inputs
self.param = np.nan
def fit(self, x, t):
assert self.param != self.param
self.param = t.sum() / x.sum() # 核心,非常简单的算一个ROI,作为系数进行计算
def predict(self, x):
assert self.param == self.param
return x * self.param
def errorL1(y, t):
return np.abs(y - t).mean()
def plot(model, valData, xKey, tKey):
validCampaigns = list(valData.keys())
ax = plt.subplots(len(validCampaigns), figsize=(5, 30))[1]
for i, k in enumerate(validCampaigns):
x = valData[k][xKey]
t = valData[k][tKey]
y = model[k].predict(x)
ax[i].scatter(x, y, label="%s Predicted" % (tKey))
ax[i].scatter(x, t)
ax[i].set_title(k)
ax[i].legend()
# 数据读入
conversion_data = pd.read_csv('Datasets/conversion_data.csv')
# marketing_spend_data = pd.read_csv('Datasets/marketing_spend_data.csv')
model_cost_revenue = {}
predictions_cost_revenue = {}
errors_cost_revenue = {}
displayDf = pd.DataFrame()
res_cost_revenue = []
campaigns = set(conversion_data['xyz_campaign_id'])
# from sklearn.model_selection import train_test_split
# X_train,X_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size=0.3,random_state=0)
trainData = {}
valData = {}
for k in campaigns:
data = conversion_data[conversion_data['xyz_campaign_id'] == k]
num = int(len(data)*0.8)
trainData[k] = data[:num]
valData[k] = data[num:]
# Cost_col = 'Cost'
# Revenue_col = 'Revenue'
Cost_col = 'Spent' # 投入
Revenue_col = 'Total_Conversion' # 产出
for k in campaigns:
model_cost_revenue[k] = StatisticalModel()
model_cost_revenue[k].fit(trainData[k][Cost_col], trainData[k][Revenue_col])
predictions_cost_revenue[k] = model_cost_revenue[k].predict(valData[k][Cost_col])
errors_cost_revenue[k] = errorL1(predictions_cost_revenue[k], valData[k][Revenue_col])
res_cost_revenue.append([k, trainData[k][Cost_col].sum(), trainData[k][Revenue_col].sum(), \\
model_cost_revenue[k].param, errors_cost_revenue[k]])
displayDf = pd.DataFrame(res_cost_revenue, columns=["Campaign", Cost_col, Revenue_col, "Fit", "Error (L1)"])
display(displayDf)
print("Mean error:", displayDf["Error (L1)"].mean())
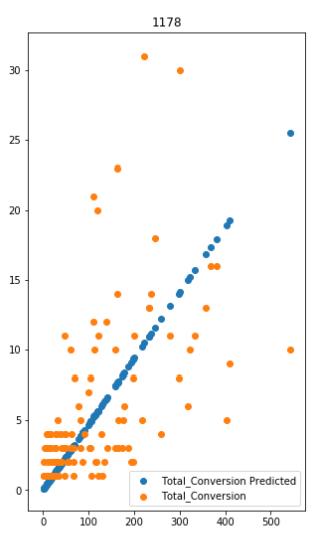
plot(model_cost_revenue, valData, Cost_col, Revenue_col)
只是一个范例,
4.2 模型二:考虑曝光
类似:cost -> 曝光 -> 收入
Cost x Revenue ~= Cost x Sessions + Sessions x Revenue
曝光 = a1 * cost
收入 = a2 * 曝光
分两步走,主要截取的也是2. Budget optimization - basic statistical model
# 随机设定一个session
session_col = 'Impressions' # 曝光
Cost_col = 'Spent' # 投入
Revenue_col = 'Total_Conversion' # 产出
# 第一步:曝光 = a1 * cost
model_cost_sessions = {}
predictions_cost_sessions = {}
errors_cost_sessions = {}
displayDf = pd.DataFrame()
res_cost_sessions = []
for k in campaigns:
model_cost_sessions[k] = StatisticalModel()
model_cost_sessions[k].fit(trainData[k][Cost_col], trainData[k][session_col])
predictions_cost_sessions[k] = model_cost_sessions[k].predict(valData[k][Cost_col])
errors_cost_sessions[k] = errorL1(predictions_cost_sessions[k], valData[k][session_col])
res_cost_sessions.append([k, trainData[k][Cost_col].sum(), trainData[k][session_col].sum(), \\
model_cost_sessions[k].param, errors_cost_sessions[k]])
displayDf = pd.DataFrame(res_cost_sessions, columns=["Campaign", Cost_col, session_col, "Fit", "Error (L1)"])
display(displayDf)
print("Mean error:", displayDf["Error (L1)"].mean())
plot(model_cost_sessions, valData, Cost_col, session_col)
# 第二步:收入 = a2 * 曝光
model_sessions_revenue = {}
predictions_sessions_revenue = {}
errors_sessions_revenue = {}
displayDf = pd.DataFrame()
res_sessions_revenue = []
for k in campaigns:
model_sessions_revenue[k] = StatisticalModel()
model_sessions_revenue[k].fit(trainData[k][session_col], trainData[k][Revenue_col])
predictions_sessions_revenue[k] = model_sessions_revenue[k].predict(valData[k][session_col])
errors_sessions_revenue[k] = errorL1(predictions_sessions_revenue[k], valData[k][Revenue_col])
res_sessions_revenue.append([k, trainData[k][session_col].sum(), trainData[k][Revenue_col].sum(), \\
model_sessions_revenue[k].param, errors_sessions_revenue[k]])
displayDf = pd.DataFrame(res_sessions_revenue, columns=["Campaign", session_col, Revenue_col, "Fit", "Error (L1)"])
display(displayDf)
print("Mean error:", displayDf["Error (L1)"].mean())
plot(model_sessions_revenue, valData, session_col, Revenue_col)
# 第三步:合并
displayDf = pd.DataFrame()
errors_cost_revenue = {}
res_cost_revenue_combined = []
class TwoModel(object):
def __init__(self, modelA, modelB):
self.modelA = modelA
self.modelB = modelB
def predict(self, x):
return self.modelA.predict(self.modelB.predict(x))
models_cost_revenue = {k : TwoModel(model_cost_sessions[k], model_sessions_revenue[k]) for k in valData}
for k in campaigns:
predictions_cost_revenue[k] = models_cost_revenue[k].predict(valData[k][Cost_col])
errors_cost_revenue[k] = errorL1(predictions_cost_revenue[k], valData[k][Revenue_col])
res_cost_revenue_combined.append([k, errors_cost_revenue[k]])
displayDf = pd.DataFrame(res_cost_revenue_combined, columns=["Campaign", "Error (L1)"])
display(displayDf)
print("Mean error:", displayDf["Error (L1)"].mean())
plot(models_cost_revenue, valData, Cost_col, Revenue_col)
以上是关于预算分配Budget Allocation:Morphl-AI的营销科学解决方案的主要内容,如果未能解决你的问题,请参考以下文章