Hive SQL底层执行过程详细剖析
Posted 过往记忆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive SQL底层执行过程详细剖析相关的知识,希望对你有一定的参考价值。
本文结构采用宏观着眼,微观入手,从整体到细节的方式剖析 Hive SQL 底层原理。第一节先介绍 Hive 底层的整体执行流程,然后第二节介绍执行流程中的 SQL 编译成 MapReduce 的过程,第三节剖析 SQL 编译成 MapReduce 的具体实现原理。
Hive
Hive是什么?Hive 是数据仓库工具,再具体点就是一个 SQL 解析引擎,因为它即不负责存储数据,也不负责计算数据,只负责解析 SQL,记录元数据。
Hive直接访问存储在 HDFS 中或者 HBase 中的文件,通过 MapReduce、Spark 或 Tez 执行查询。
我们今天来聊的就是 Hive 底层是怎样将我们写的 SQL 转化为 MapReduce 等计算引擎可识别的程序。了解 Hive SQL 的底层编译过程有利于我们优化Hive SQL,提升我们对Hive的掌控力,同时有能力去定制一些需要的功能。
Hive 底层执行架构
我们先来看下 Hive 的底层执行架构图, Hive 的主要组件与 Hadoop 交互的过程:
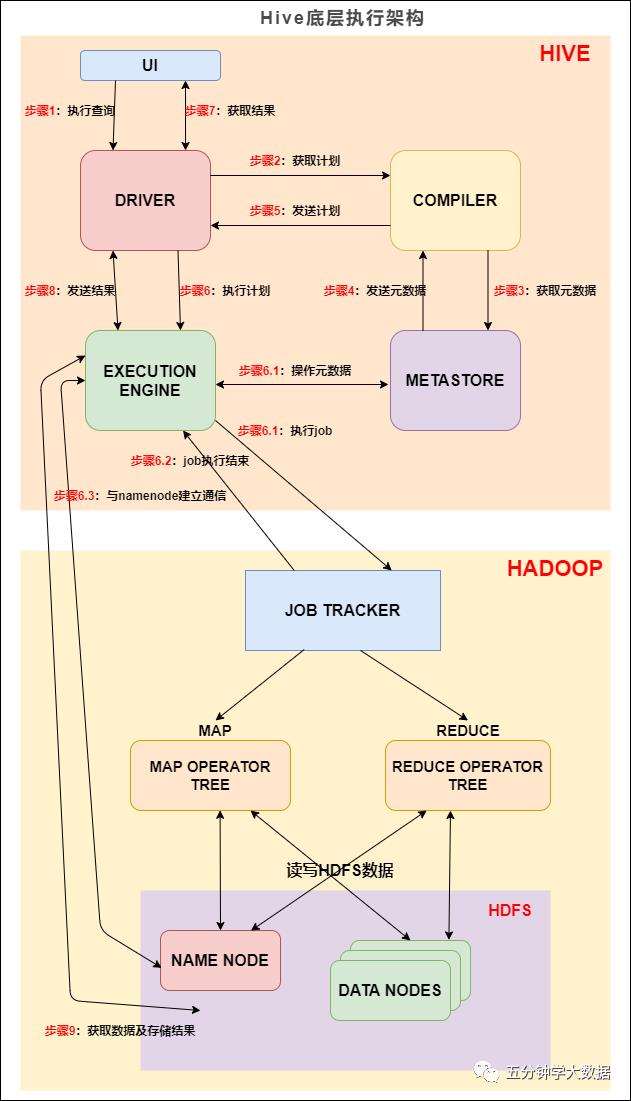
在 Hive 这一侧,总共有五个组件:
UI:用户界面。可看作我们提交SQL语句的命令行界面。
DRIVER:驱动程序。接收查询的组件。该组件实现了会话句柄的概念。
COMPILER:编译器。负责将 SQL 转化为平台可执行的执行计划。对不同的查询块和查询表达式进行语义分析,并最终借助表和从 metastore 查找的分区元数据来生成执行计划。
METASTORE:元数据库。存储 Hive 中各种表和分区的所有结构信息。
EXECUTION ENGINE:执行引擎。负责提交 COMPILER 阶段编译好的执行计划到不同的平台上。
上图的基本流程是:
步骤1:UI 调用 DRIVER 的接口;
步骤2:DRIVER 为查询创建会话句柄,并将查询发送到 COMPILER(编译器)生成执行计划;
步骤3和4:编译器从元数据存储中获取本次查询所需要的元数据,该元数据用于对查询树中的表达式进行类型检查,以及基于查询谓词修建分区;
步骤5:编译器生成的计划是分阶段的DAG,每个阶段要么是 map/reduce 作业,要么是一个元数据或者HDFS上的操作。将生成的计划发给 DRIVER。
如果是 map/reduce 作业,该计划包括 map operator trees 和一个 reduce operator tree,执行引擎将会把这些作业发送给 MapReduce :
步骤6、6.1、6.2和6.3:执行引擎将这些阶段提交给适当的组件。在每个 task(mapper/reducer) 中,从HDFS文件中读取与表或中间输出相关联的数据,并通过相关算子树传递这些数据。最终这些数据通过序列化器写入到一个临时HDFS文件中(如果不需要 reduce 阶段,则在 map 中操作)。临时文件用于向计划中后面的 map/reduce 阶段提供数据。
步骤7、8和9:最终的临时文件将移动到表的位置,确保不读取脏数据(文件重命名在HDFS中是原子操作)。对于用户的查询,临时文件的内容由执行引擎直接从HDFS读取,然后通过Driver发送到UI。
Hive SQL 编译成 MapReduce 过程
编译 SQL 的任务是在上节中介绍的 COMPILER(编译器组件)中完成的。Hive将SQL转化为MapReduce任务,整个编译过程分为六个阶段:
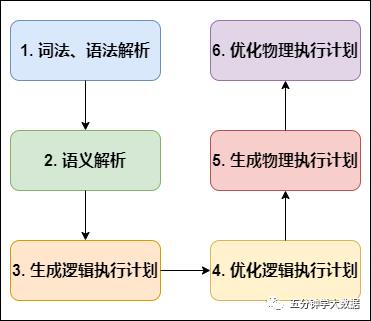
词法、语法解析: Antlr 定义 SQL 的语法规则,完成 SQL 词法,语法解析,将 SQL 转化为抽象语法树 AST Tree;
Antlr是一种语言识别的工具,可以用来构造领域语言。使用Antlr构造特定的语言只需要编写一个语法文件,定义词法和语法替换规则即可,Antlr完成了词法分析、语法分析、语义分析、中间代码生成的过程。
语义解析: 遍历 AST Tree,抽象出查询的基本组成单元 QueryBlock;
生成逻辑执行计划: 遍历 QueryBlock,翻译为执行操作树 OperatorTree;
优化逻辑执行计划: 逻辑层优化器进行 OperatorTree 变换,合并 Operator,达到减少 MapReduce Job,减少数据传输及 shuffle 数据量;
生成物理执行计划: 遍历 OperatorTree,翻译为 MapReduce 任务;
优化物理执行计划: 物理层优化器进行 MapReduce 任务的变换,生成最终的执行计划。
下面对这六个阶段详细解析:
为便于理解,我们拿一个简单的查询语句进行展示,对5月23号的地区维表进行查询:
select * from dim.dim_region where dt = '2021-05-23';
阶段一:词法、语法解析
根据Antlr定义的sql语法规则,将相关sql进行词法、语法解析,转化为抽象语法树AST Tree:
ABSTRACT SYNTAX TREE:
TOK_QUERY
TOK_FROM
TOK_TABREF
TOK_TABNAME
dim
dim_region
TOK_INSERT
TOK_DESTINATION
TOK_DIR
TOK_TMP_FILE
TOK_SELECT
TOK_SELEXPR
TOK_ALLCOLREF
TOK_WHERE
=
TOK_TABLE_OR_COL
dt
'2021-05-23'
阶段二:语义解析
遍历AST Tree,抽象出查询的基本组成单元QueryBlock:
AST Tree生成后由于其复杂度依旧较高,不便于翻译为mapreduce程序,需要进行进一步抽象和结构化,形成QueryBlock。
QueryBlock是一条SQL最基本的组成单元,包括三个部分:输入源,计算过程,输出。简单来讲一个QueryBlock就是一个子查询。
QueryBlock的生成过程为一个递归过程,先序遍历 AST Tree ,遇到不同的 Token 节点(理解为特殊标记),保存到相应的属性中。
阶段三:生成逻辑执行计划
遍历QueryBlock,翻译为执行操作树OperatorTree:
Hive最终生成的MapReduce任务,Map阶段和Reduce阶段均由OperatorTree组成。
基本的操作符包括:
TableScanOperator
SelectOperator
FilterOperator
JoinOperator
GroupByOperator
ReduceSinkOperator`
Operator在Map Reduce阶段之间的数据传递都是一个流式的过程。每一个Operator对一行数据完成操作后之后将数据传递给childOperator计算。
由于Join/GroupBy/OrderBy均需要在Reduce阶段完成,所以在生成相应操作的Operator之前都会先生成一个ReduceSinkOperator,将字段组合并序列化为Reduce Key/value, Partition Key。
阶段四:优化逻辑执行计划
Hive中的逻辑查询优化可以大致分为以下几类:
投影修剪
推导传递谓词
谓词下推
将Select-Select,Filter-Filter合并为单个操作
多路 Join
查询重写以适应某些列值的Join倾斜
阶段五:生成物理执行计划
生成物理执行计划即是将逻辑执行计划生成的OperatorTree转化为MapReduce Job的过程,主要分为下面几个阶段:
对输出表生成MoveTask
从OperatorTree的其中一个根节点向下深度优先遍历
ReduceSinkOperator标示Map/Reduce的界限,多个Job间的界限
遍历其他根节点,遇过碰到JoinOperator合并MapReduceTask
生成StatTask更新元数据
剪断Map与Reduce间的Operator的关系
阶段六:优化物理执行计划
Hive中的物理优化可以大致分为以下几类:
分区修剪(Partition Pruning)
基于分区和桶的扫描修剪(Scan pruning)
如果查询基于抽样,则扫描修剪
在某些情况下,在 map 端应用 Group By
在 mapper 上执行 Join
优化 Union,使Union只在 map 端执行
在多路 Join 中,根据用户提示决定最后流哪个表
删除不必要的 ReduceSinkOperators
对于带有Limit子句的查询,减少需要为该表扫描的文件数
对于带有Limit子句的查询,通过限制 ReduceSinkOperator 生成的内容来限制来自 mapper 的输出
减少用户提交的SQL查询所需的Tez作业数量
如果是简单的提取查询,避免使用MapReduce作业
对于带有聚合的简单获取查询,执行不带 MapReduce 任务的聚合
重写 Group By 查询使用索引表代替原来的表
当表扫描之上的谓词是相等谓词且谓词中的列具有索引时,使用索引扫描
经过以上六个阶段,SQL 就被解析映射成了集群上的 MapReduce 任务。
SQL编译成MapReduce具体原理
在阶段五-生成物理执行计划,即遍历 OperatorTree,翻译为 MapReduce 任务,这个过程具体是怎么转化的呢
我们接下来举几个常用 SQL 语句转化为 MapReduce 的具体步骤:
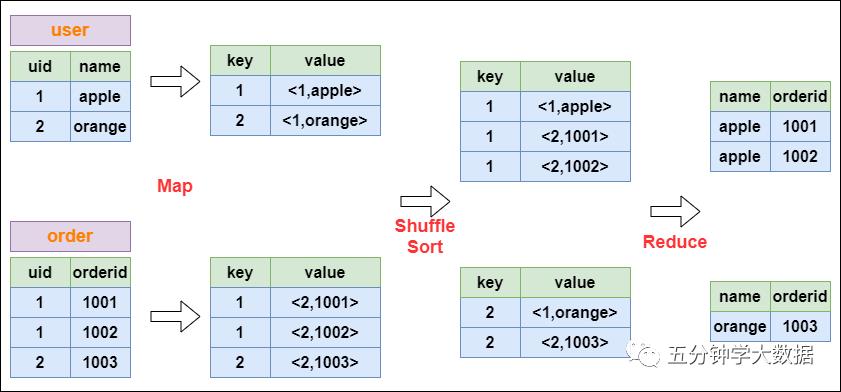
Join的实现原理
以下面这个SQL为例,讲解 join 的实现:
select u.name, o.orderid from order o join user u on o.uid = u.uid;
在map的输出value中为不同表的数据打上tag标记,在reduce阶段根据tag判断数据来源。MapReduce的过程如下:
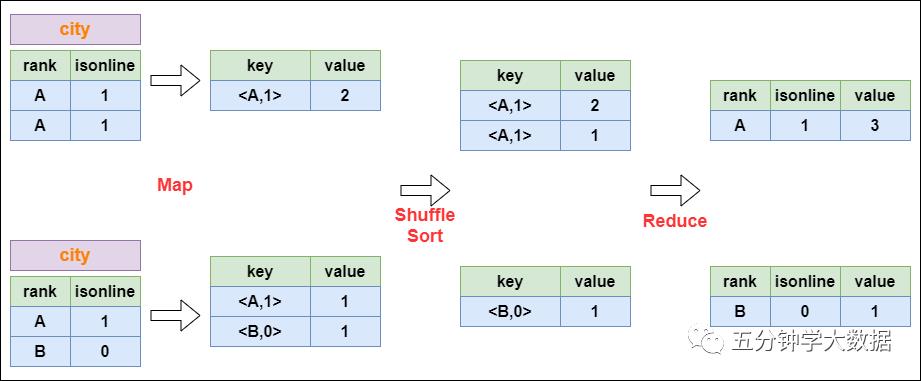
Group By的实现原理
以下面这个SQL为例,讲解 group by 的实现:
select rank, isonline, count(*) from city group by rank, isonline;
将GroupBy的字段组合为map的输出key值,利用MapReduce的排序,在reduce阶段保存LastKey区分不同的key。MapReduce的过程如下:
Distinct的实现原理
以下面这个SQL为例,讲解 distinct 的实现:
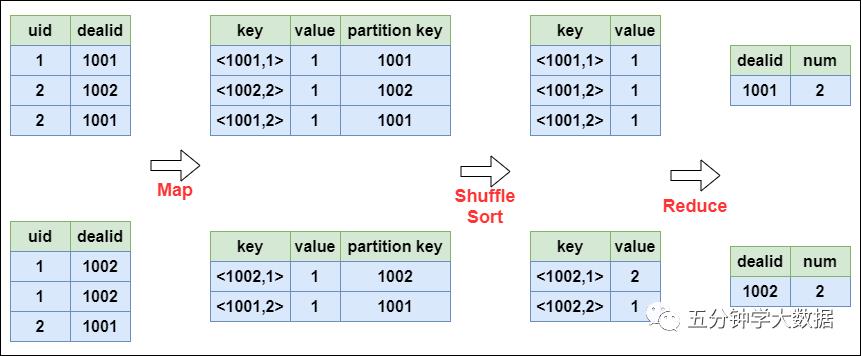
select dealid, count(distinct uid) num from order group by dealid;
当只有一个distinct字段时,如果不考虑Map阶段的Hash GroupBy,只需要将GroupBy字段和Distinct字段组合为map输出key,利用mapreduce的排序,同时将GroupBy字段作为reduce的key,在reduce阶段保存LastKey即可完成去重:
--END--
以上是关于Hive SQL底层执行过程详细剖析的主要内容,如果未能解决你的问题,请参考以下文章