10个python办公黑科技,助你办公效率提高100倍
Posted 1_bit
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了10个python办公黑科技,助你办公效率提高100倍相关的知识,希望对你有一定的参考价值。
1946年,世界上第一台通用计算机“ENIAC”在美国宾夕法尼亚大学诞生;“ENIAC”占地170平方米,重达30吨,耗电功率约150千瓦,每秒钟可进行5000次运算,这个庞然大物用于美国国防部进行弹道计算。
在当时,计算机只是被用于了特殊部门。现如今已过60余年,人类在计算机发展进程中越走越远,技术的发展使价格越加便宜,体积也更加便于携带,计算机随之出现在了各行各业之中。在第47期《中国互联网络发展状况统计报告》中提到,截至2020年12月,中国网民数量达到9.89亿,互联网普及率达到70.4%,如此多的用户必然有着巨大的商业市场,所需要的计算机应用程序也越加多样,那么创造这些计算机应用程序就需要进行程序编写。
在计算机中,编写程序需要使用计算机编程语言,由于种类及针对性不同,计算机语言存在上百种,那对于目前日益复杂的办公需求,到底什么语言才可以提高我们的办公效率呢?如今有了一个答案,这个热门的语言叫做 python,python 拥有着众多的第三方库,或者说这些库就是已经实现好的功能,正等着你去使用它,完成你需要的定制功能;我们只需要学会 python 基础语法,既可以在办公中提高自己的工作效率。
今天这篇文章将会模拟解决 10 个办公需求为主要内容,带读者感受 python 的魅力;当然,读者也可以从本篇文中直接得到这 10 个问题解决办法。本篇文将要解决的 10 个办公需求如下:
- 上班第一天,老板叫我从一堆文本信息中提取出手机号码,我改如何去做?
- 上班第二天,领导叫我将第一天提取的电话号码存储到 Excel 中,我是如何快速解决的。
- 上班第三天,今天叫我去文本中提取邮箱了,给了我一天时间,但我玩了半天才开始进行信息提取。
- 上班第四天,今天给了我一堆图片,让我加上公司水印。
- 上班第五天,前同事的电脑中太多重复文件,领导让我清理重复文件精简信息。
- 上班第六天,领导跟我说数一下这个文本到底有多少个中文字符。
- 上班第七天,帮助美工小姐姐将网址生成二维码图片。
- 上班第八天,如何将图片生成 gif?我手到擒来。
- 上班第九天,人事急匆匆的找到我让我急忙翻译一份英文文档,我立马答应下来。
- 上班第十天,提取视频的音频信息并且升职加薪!
上班第一天
上班第一天,你的上级给你一堆文本文件,叫你去提取出手机号码。如果是常规的办公人员,获取信息会一个个的去文本中查找,但在如今计算机深度普及的时代,显然提高办公效率解放自身才是更好的选择;那么这时,就让 python 祝你一臂之力,在职场腾飞吧。
首先我们可以考虑,文本文件为 txt 的后缀文件,这个文本文件第一件事情则是需要读取;读取文本信息需要使用 python 的 open 函数,此时创建一个 python 文件名为 day1.py 编写一个函数名为 get_str,传入参数为需要读取到的文件路径,该函数返回读取到的内容,函数代码如下:
#读取目标文本文件
def get_str(path):
f = open(path,encoding="utf-8")
data = f.read()
f.close()
return data
此时已经编写好了读取文本内容函数,那么接下来就应该需要在这个读取到的值之中提取电话号码,提取电话号码使用正则,在此不过多说明正则的使用用法;使用正则我们需要使用 re模块;引入 re 模块后,调用 re 模块的 findall 方法对电话号码进行读取,然后进行返回:
import re
#正则获取文本号码
def get_phone_number(str):
res = re.findall(r'(13\\d{9}|14[5|7]\\d{8}|15\\d{9}|166{\\d{8}|17[3|6|7]{\\d{8}|18\\d{9})', str)
return res
那么最后一步就还剩保存信息。保存信息创建一个函数名为 save_res,传入两个参数分别是提取号码的结果以及保存文件的路径,之后遍历结果使用 write 方法写入即可,该函数代码如下:
#保存得到号码
def save_res(res,save_path):
save_file = open(save_path, 'w')
for phone in res:
save_file.write(phone)
save_file.write('\\n')
save_file.write('\\n号码共计:'+str(len(res)))
save_file.close()
print('号码读取OK,号码共计:'+str(len(res)))
那么最后一步就还剩如何如何调用已创建的代码。此时使用 input 接收两个输入值;一个为需要读取的目标文件路径,另一个为需要保存结果的文件路径,之后依次调用函数即可,代码如下:
path=input("请输入文件路径:")
save_path=input("请输入文件保存路径:")
#read_str=get_str(path)
res=get_phone_number(get_str(path))
save_res(res,save_path)
此时我们创建 1 个 txt 文件用于测试,文件名及后缀为 phone.txt,内容为:
张三:15888888888
李四:15888888888
王五:15888888888
草帽:15888888888
李四:15888888888
柳叶:15888888888
柳叶:15888888888
李四:15888888888
柳叶:15888888888
柳叶:15888888888
李四:15888888888
柳叶:15888888888
柳叶:15888888888
李四:15888888888
柳叶:15888888888
李四:15888888888
李四:15888888888
柳叶:15888888888
接下来在 DOS 中运行 python 文件 day1,输入文件存储路径以及保存路径,当完成信息提取后将会有提示:

此时到保存的文件 res.txt 查看,发现电话号码信息已经被提取:
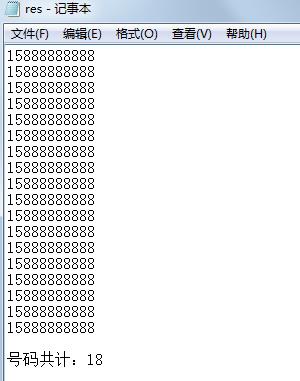
此时第一天的工作轻松搞定,并且还可以把脚本分享给同事,提高自己的形象,岂不美哉?
上班第二天
上班第二天,新分配给你的任务是将第一天的 phone.txt 文本使用 Excel 保存,此时如果该文本是上万条信息,可能你独自手动操作将会耗时非常久才能完成这个任务,并且大概率有遗漏。这时使用 python 进行自动化操作将会极大的减少你操作的时间,并且在程序正确的情况下遗漏数据概率极低。那 python 是否可以胜任第二天的功能呢?答案当然是“能!”。python 有一个第三方库叫做 xlwt,通过 xlwt 可以自动将数据保存到 Excel 文件中,接下来我们来看一下具体如何解决。
首先创建一个 python 文件名为 day2.py,在头部引入 xlwt:
import xlwt
由于我们当前所需要的数据是第一天任务用到的,在这里我们继续使用第一天所用使用到的 get_str 函数:
#读取目标文本文件
def get_str(path):
f = open(path,encoding="utf-8")
data = f.read()
f.close()
return data
接着我们创建一个函数名为 save_excel,该函数功能包括了保存文件、设置 sheet 名、设置列名以及设置列值。save_excel 函数接收 4 个参数,分别为 save_path、sheetname、column_name_list、content。首先我们在函数内创建一个 Workbook 对象:
def save_excel(save_path,sheetname,column_name_list,read_list):
workbook = xlwt.Workbook()
接着在函数体中使用 add_sheet 增加一个 sheet,add_sheet 函数接收一个参数为 sheet 名称,我们将接收的 sheetname 参数作为 sheetname 的值,add_sheet 函数将会返回创建的这个 sheet 对象,代码写为:
sheet1 = workbook.add_sheet(sheetname=sheetname)
接收完参数后,我们可以使用 for 循环将传递过来的列名 column_name_list 在该 sheet 上进行设置:
for i in range(0,len(column_name_list)):
sheet1.write(0,i,column_name_list[i])
以上代码中 write 方法第一个参数为 sheet 的第几行,这里为 0 即为最开始的一行;参数 i 为第几列,由于 i 是从 0 开始到当前列元素长度位置进行对 column_name_list 的遍历,此时则是从 0 到 column_name_list 的最后一个元素,那么将会从最开头的列到对应最尾的列,则将所有列名填写值 sheet 页头部。
接着就应该为这些列设置元素了。此时遍历传递过来的 read_list,read_list 为这些列的具体内容,例如姓名与电话号码。此时遍历 read_list 由于原始数据每一行将会是以 : 作为姓名与电话分隔,例如 “张三:15888888888”,这时遍历 read_list 列表应该将值再进行分隔,以列名设置同理进行赋值,在此不再赘述,代码如下:
i=1
for v in read_list:
kval=v.split(':')
for j in range(0,len(kval)):
sheet1.write(i+1,j,kval[j])
print(kval[j])
i=i+1
最后使用 workbook 对象调用 save 方法,传递保存地址即可。那么该 save_excel 自定义函数完整代码如下:
#保存为Excel文件
def save_excel(save_path,sheetname,column_name_list,read_list):
workbook = xlwt.Workbook()
sheet1 = workbook.add_sheet(sheetname=sheetname)
for i in range(0,len(column_name_list)):
sheet1.write(0,i,column_name_list[i])
i=1
for v in read_list:
kval=v.split(':')
for j in range(0,len(kval)):
sheet1.write(i+1,j,kval[j])
i=i+1
workbook.save(save_path)
print('信息保存 OK,记录条数共计:'+str(len(read_list)))
此时已经完成了主要功能的编写,那么接下来就应该接受用户输入 文件路径、文件保存路径、sheetname、列名 以及对原始数据用换行符 “\\n” 作为列表分隔符,调用部分完整代码如下:
path=input("请输入文件路径:")
save_path=input("请输入文件保存路径:")
sheet_name=input("请输入sheetname:")
column_name=input("请输入列名,并且使用英文逗号隔开:")
column_name_list=column_name.split(',')
read_str=get_str(path)
read_list=read_str.split('\\n')
save_excel(save_path,sheet_name,column_name_list,read_list)
此时运行 day2.py 文件,输入完所需内容将会出现成功提示:

随后在保存的文件中可以看到提取出来的信息:
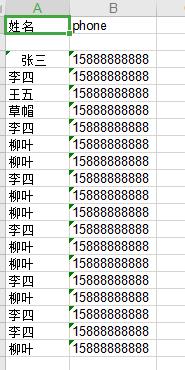
上班第三天
时间到了第三天,你领导问你如何知道python学习方向的?你告诉了他,是买了这一份知识图鉴:

你把你的送给了领导并且自己又买了一份。第三天领导给你的任务是从文本中提取邮箱,这个任务跟第一个任务差不多,我们只需要替换正则即可完成任务。创建一个 python 文件名为 day3.py,day3.py 所有完整代码如下:
import re
#正则获取目标信息
def get_re_str(str):
res = re.findall(r'^[A-Za-z0-9\\u4e00-\\u9fa5]+@[a-zA-Z0-9_-]+(\\.[a-zA-Z0-9_-]+)+$', str)
return res
#读取目标文本文件
def get_str(path):
f = open(path,encoding="utf-8")
data = f.read()
f.close()
return data
#保存得到的信息
def save_res(res,save_path):
save_file = open(save_path, 'w')
for phone in res:
save_file.write(phone)
save_file.write('\\n')
save_file.close()
print('信息读取OK,信息共计:'+str(len(res)))
path=input("请输入文件路径:")
save_path=input("请输入文件保存路径:")
#read_str=get_str(path)
res=get_re_str(get_str(path))
save_res(res,save_path)
在以上代码中,我们为了函数功能与名称对应,修改了部分函数名以及必要的正则信息,在此我们就已经知道,如果从一个文本中提取出常用信息只需要修改对应的正则即可,不会写正则我们可以搜索引擎搜索,直接替换即可完成该功能;在这里,邮箱的正则为 '^[A-Za-z0-9\\u4e00-\\u9fa5]+@[a-zA-Z0-9_-]+(\\.[a-zA-Z0-9_-]+)+$'。我们此时运行该文件,填上必要的输入信息即可取出对应文本中的邮件文本信息。
上班第四天
今天是第四天,你在前三天都做的很不错,自然而然你的上级将会更加看重你。此时你的上级给了你一个G大小的压缩包,告诉你里面的图片都需要添加水印,此时你该如何实现这个功能呢?当然可以通过其他软件付费,但是自己大概率是会垫付这几十块钱,既然已经学会了 python 完成了部分任务,那么就应该去寻找一下 python 是否有相关的支持库。如果你已经开始寻找相关的 python 支持,我可以告诉你“恭喜!你的想法非常正确”。使用 python 的 opencv 库即可完成这个操作。
安装好 opencv 库后,导入 opencv 库并且引入 os,因为我们将对某一个文件夹下的文件进行批量水印操作,会涉及到目录文件读取:
import cv2
import os
接下来根据用户输入路径确定需要操作的目录下图片:
path=input("请输入需要加水印的文件夹路径:")
接着获取目录下所有文件:
file_list = os.listdir(path)
最后循环遍历每一份图片,使用 imread 方法读取图片获得该图片对象,并且使用 putText 方法为该图片对象添加水印信息,水印信息参数已在注释中说明,最后再使用 imwrite 方法保存图片即可:
for filename in file_list:
img1 = cv2.imread(path+filename,cv2.IMREAD_COLOR)
cv2.putText(img1,'CSDN',(10,10) , 1, 1, (255,255,255),1) #图片,文字,位置,字体,字号,颜色,厚度
cv2.imwrite(path+filename, img1)
运行程序输入路径后,最终生成的图片结果如下:


上班第五天
你在公司已经小有名气,这时你的上级领导跟你说“你上一位同事的电脑中太多重复文件,导出文件过多,需要删除重复文件”;这时你得到了这个任务,那如何去删除重复文件呢?没错,是使用文件的 md5 值进行对照,相同文件的 md5 值一样,只需要遍历该目录的文件 md5 值,若出现重复 md5 则删除该文件即可。
第一步导入两个模块,其中 hashlib 作为 md5 计算所需的模块:
import hashlib,os
接着编写一个函数,需要传入一个文件路径,从而获取这个文件的 md5:
def getMD5(filepath):
f = open(filepath,'rb')
md5obj = hashlib.md5()
md5obj.update(f.read())
hash = md5obj.hexdigest()
f.close()
return str(hash).upper()
以上代码中,hashlib.md5() 为获取一个 md5 加密对象,md5obj.update() 为指定加密的信息,最后 md5obj.hexdigest() 获取加密后的 16 进制字符串,此时就可以得到 md5 加密后的 16 进制了,最后将其返回。接着我们就需要请用户输入需要过滤重复文件的目录:
path=input("请输入需要重复文件过滤文件夹路径:")
随后获取目录下的文件信息,并且创建一个列表记录 md5 值:
file_list = os.listdir(path)
file_md5=[]
接着使用 for 循环对指定目录进行遍历:
for filename in file_list:
md5val=getMD5(path+filename)
if md5val in file_md5:
os.remove(path+filename)
else:
file_md5.append(md5val)
print("处理完毕...")
以上代码中调用 getMD5 方法获取文件的 md5 值,随后判断该 md5 值是否在记录列表中,如果在则使用 os 的 remove 方法移除该文件,否则就将记录该 md5 值,这样就实现了重复文件删除的操作。
运行程序输入目录后将清理完重复文件:

上班第六天
今天你的领导跟你说,需要读取作者的中文字数,以便于给予发放稿费,但是只能算中文字符;由于之前据说是让实习生慢慢数的,所以希望你能够加快数中文字符的速度。
当然,对于用了几天 python 的你来说自然难不到,这是一个很简单的操作。需要完成这个需求很简单,我们需要用到 python 两个模块,一个是 os 另一个是 re;os 用于读取文本信息,re 用于判断中文字符,我们先创建一个函数名为 get_str 接收文本路径作为参数,然后返回文本信息;由于这段时间都是使用这个函数,具体的解释并不过多赘述,函数实现如下:
#读取目标文本文件
def get_str(path):
f = open(path)
data = f.read()
f.close()
return data
接下来依旧是输入目标路径代码:
path=input("请输入文件路径:")
接着,我们只需要使用 re 模块中的 findall 方法即可提取,我们在 findall 方法中指定中文字符的范围为 \\u4e00-\\u9fa5 即可:
path=input("请输入文件路径:")
word=re.findall('([\\u4e00-\\u9fa5])',get_str(path))
print("中文字符,除特殊字符外共:",len(word))
最后我们把需要技术的内容复制到一个文本中,运行脚本,结果如下:

上班第七天
今天美工小姐姐跟你说,制作海报需要官网的二维码,可是她不知道去哪得到,非常需要你的帮助,你跟她说让她稍等片刻马上发送给她。那,你是怎么实现的呢?
在 python 中有个库叫做 qrcode,qrcode可以直接生成指定 url 的二维码,首先引入 qrcode 库。
import qrcode
接着设置你所需要创建二维码的具体信息,例如大小、尺寸、容错等,代码及注释如下:
qr = qrcode.QRCode(
version=2,#尺寸
error_correction=qrcode.constants.ERROR_CORRECT_L,#容错信息当前为 7% 容错
box_size=10,#每个格子的像素大小
border=1#边框格子宽度
)#设置二维码的大小
接着指定 url、生成二维码图片最后进行保存即可:
qr.add_data("https://www.csdn.net/")#指定 url
img = qr.make_image()#生成二维码图片
img.save("F:\\work\\day7\\csdn.png")#保存
运行脚本这时 csdn 官网链接就生成了:


上班第八天
上班第八天来了,你的技巧赢得了领导、同事的肯定,同事小王跟你说要你制作一个 gif 图片,他不懂怎么去做,但是有多张图片,你一口答应下来;小王给了你一个文件夹,文件夹中有按序号排列的图片,你需要按照需要进行动图制作。为了介绍方便,我们以以下两张图为例:

此时所需要的 python 库为 imageio,使用 imageio 可方便的使多张图片生成 gif 图。首先我们需要一个列表存储图片路径,此处为了方便演示,直接使用列表作为存储,并且创建一个变量为图片的保存路径:
import imageio
image_list = [r'F:\\work\\day4\\1.png', r'F:\\work\\day4\\2.png']
gif_name = r'F:\\work\\day4\\gif.gif'
接下来创建一个列表存储读取后的图片信息,方便合成 gif 图片:
frames = []
接着遍历图片路径,随后使用 imageio 的 imread 方法读取图片添加到 frames 列表之中:
for image_name in image_list:
frames.append(imageio.imread(image_name))
接下来使用 imageio 的 mimsave 方法传入 gif_name 保存路径信息、frames 图片信息、‘GIF’ 生成图片类型以及 gif 图的切换秒数 duration 参数为 2:
imageio.mimsave(gif_name, frames, 'GIF', duration=2)
最后运行该脚本,得到以下 gif 图片:

上班第九天
第九天到来,今天一早人事跟你说需要你翻译一份文档成中文,不需要质量太好但是一定要快速。你依旧一口应下,那么你的自信来源于哪呢?当然是来源于 python 的强大。python 中有一个库叫做 translate 可以直接翻译英文文本,我们首先引入该库:
from translate import Translator
随后设置翻译的语言类型:
translator = Translator(to_lang="Chinese")
接着设定翻译的语言文本,在此我们创建一个函数直接获取文本信息:
def get_str(path):
f = open(path)
data = f.read()
f.close()
return data
接着要求用户输入文件路径并且获得文件文本:
path=input("请输入文件路径:")
text=get_str(path)
文本信息为:
Virtual Group Coaching: How to Improve Group Relationships in Remote Work Settings
最关键的一步,我们将文本拿去 translate 方法中进行翻译,最后输出:
translation = translator.translate(text)
print(translation)
我们最后运行脚本,得到结果:

上班第十天成功转正并升职
第十天,今天领导给了你一个视频文件,希望你能够提取出音频,他对你非常看重,并且跟你说过完今天转正后提前升职加薪,你也是非常兴奋,当场3句代码直接提取出了指定视频的音频。
python 对视频进行操作可以使用 moviepy 库,第一步引入 moviepy:
from moviepy.editor import AudioFileClip
随后使用 AudioFileClip 获取视频信息:
my_audio_clip = AudioFileClip("E:\\PyVedio\\py02.mp4")
最后直接使用 方法将视频的音频写入到文件之中:
my_audio_clip.write_audiofile("E:\\PyVedio\\py02.wav")
看完了 python 那么多的“神奇”妙用,你还不赶紧用于办公吗?当下社会对办公效率的要求日益加深,合理的学会一门编程语言进行高效的办公是突出个人能力的途径之一。python 作为当下最流行的语言之一,拥有许许多多强大的第三库支持,在办公领域方面应用得当将会祝你在职场中斩荆披棘、突破自我。
上班第十一天跟领导出差突遇紧急事件
今天你们出差来到一个偏僻的地方,酒店wifi服务员自己也不懂,只记得很简单,你直接使用python进行了破解,随后领导跟你说要马上做一个舆论分析非常紧急,你立马开始着手制作。领导怎么知道你懂那么多?那是因为他也买了CSDN 的 python 知识图鉴,知道了 python 的全部学习路线,你也想知道吗?那就购买一份吧,30块钱祝你腾飞~

以上是关于10个python办公黑科技,助你办公效率提高100倍的主要内容,如果未能解决你的问题,请参考以下文章
❤️ 6个Python办公黑科技,工作效率提升100倍!HR小姐姐都馋哭了(附代码)❤️
❤️ 6个Python办公黑科技,工作效率提升100倍!HR小姐姐都馋哭了(附代码)❤️