GaussDB(DWS)发生数据倾斜不要慌,一文教你轻松获取表倾斜率
Posted 华为云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GaussDB(DWS)发生数据倾斜不要慌,一文教你轻松获取表倾斜率相关的知识,希望对你有一定的参考价值。
摘要:GaussDB(DWS)是MPP并行架构,若表的数据存在倾斜情况,会引起一系列性能问题,影响用户体验,严重时可能会引起系统故障。因此能快速获取倾斜的表并整改是GaussDB(DWS)运维管理人员比较关注的事情。
本文分享自华为云社区《GaussDB(DWS)发生数据倾斜不要慌,一文教你轻松获取表倾斜率》,原文作者:SeqList 。
GaussDB(DWS)是MPP并行架构,若表的数据存在倾斜情况,会引起一系列性能问题,影响用户体验,严重时可能会引起系统故障。因此能快速获取倾斜的表并整改是GaussDB(DWS)运维管理人员比较关注的事情。
需求描述
GaussDB(DWS)自身提供pgxc_get_table_skewness视图来查询倾斜情况,但实际实践过程中,该视图存在性能问题,且该视图的倾斜率计算有问题。实践过程中,该视图获取的某个表的倾斜率在不高的情况下(例如0.03),但实际上该表是存在倾斜情况的。
同时在很多时候我们需要获取一个schema下所有表的倾斜率,以排查倾斜问题,pgxc_get_table_skewness在产品文档中也描述是一个性能较差的视图。
因此项目实践过程中急需一个性能好且能表达倾斜情况的函数或视图。
设计思路
GaussDB(DWS)有获取每个DN的空间大小函数table_distribution,通过该函数,我们能快速获取每个DN的大小,同时可以根据每个DN的大小,来获取表的倾斜情况:
skewness = (max(dnsize) - avg(dnsize))*100/max(dnsize)
该倾斜率公式计算表的最大DN空间大小与平均DN空间大小的占比,能准确反映倾斜率,乘100为表现百分比。
实现过程
根据倾斜公式,我们得出以下SQL,该SQL能快速获取schema所有表的倾斜情况,下面以public为例:
select schemaname,tablename,sum(dnsize)/1024^3 dnsize_gb,(max(dnsize) - avg(dnsize))*100/nullif(max(dnsize),0) skewness_factor
from (
select schemaname
,tablename
,(regexp_split_to_array(tbl_dis,'[\\,\\(\\)]+'))[4]::bigint as vprocname
,(regexp_split_to_array(tbl_dis,'[\\,\\(\\)]+'))[5]::bigint as dnsize
from (
select nspname as schemaname
,relname as tablename
,table_distribution(nspname,relname)::text as tbl_dis
from pg_class a
inner join pg_namespace b
on a.relnamespace = b.oid
and a.relkind = 'r'
and b.oid not in (100)
)
)
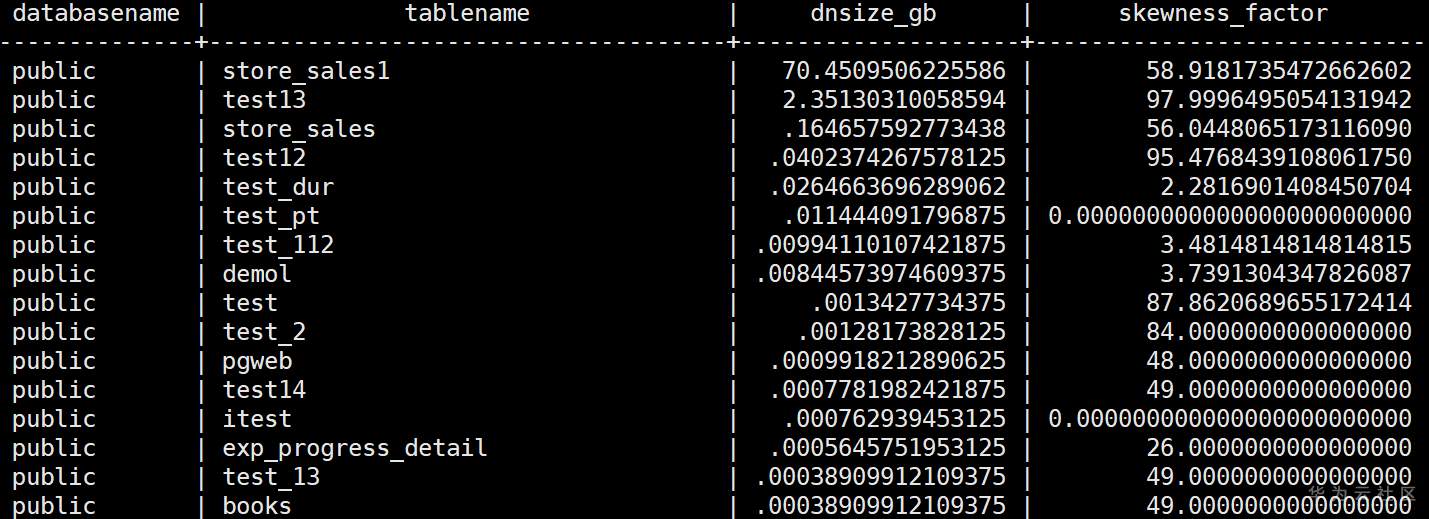
where schemaname= 'public' group by 1,2 order by 3 desc;结果样例如下,通过例子,可以看出来,test13这个表2GB,且发生严重的倾斜97%,同时store_sales1一个70GB的大表也存在倾斜情况58%
与GaussDB(DWS)的pgxc_get_table_skewness视图结果比对
使用GaussDB(DWS) 的系统视图pgxc_get_table_skewness,比较难看出来store_sales1存在倾斜情况。
此处我们使用的是系统视图pgxc_get_table_skewness获取
select * from PGXC_GET_TABLE_SKEWNESS where schemaname = 'public' and tablename in ('store_sales1','test13');从结果上看,skewratio字段,test13表能看出来存在严重倾斜情况,而store_sales1的skewratio值只有0.031,看不出来存在倾斜情况。但事实上该表是存在一定倾斜的

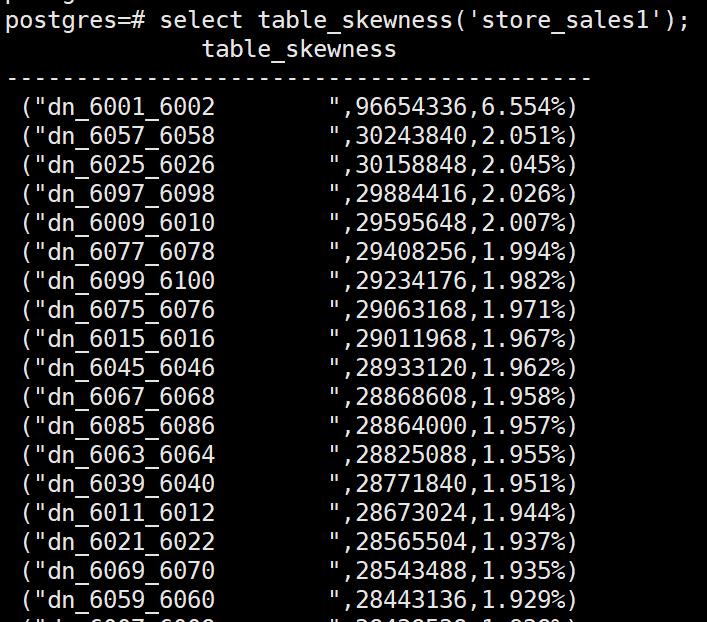
我们通过table_skewness看每个DN的数据分布验证,发现store_sales1的确存在一定倾斜。
总结:
GaussDB(DWS)的倾斜率获取视图pgxc_get_table_skewness的结果,虽能反映严重倾斜的表,但存在倾斜的大表则比较难看出来。同时该函数存在一定的性能问题,较多表的情况下基本执行不出来。
本文提供的倾斜率获取办法能比较准确反映表的倾斜情况且能叫快速获取整schema所有的表的倾斜率方法;该方法在测试过程中,数据量越大,表越多,执行的时间会越慢,测试一个schema约3800张表,共40TB左右的数据,在5分钟左右获取所有表的空间大小与倾斜率。
但本文提供的方法只能对单个schema操作,对整个数据库获取表空间大小与倾斜率,实测无法执行成功。若对时效性不要求的话,可以每天固定一个时间,已跑批的形式,获取一个库的所有表清单,使用table_distribution函数,一次一个表地获取表的空间信息,使用多并发执行,这样的方式能在一定时间内将所有表的空间情况执行完成。
例如:对整库有10万张表的情况,可以使用100个并发同时执行 insert into table_size_info select * from table_distribution('schema.table'); 这样的方式将10万张表的DN空间信息获取完成,然后使用本文的公式汇总获取每个表的倾斜率与空间总大小。
想了解GuassDB(DWS)更多信息,欢迎微信搜索“GaussDB DWS”关注微信公众号,和您分享最新最全的PB级数仓黑科技,后台还可获取众多学习资料~
以上是关于GaussDB(DWS)发生数据倾斜不要慌,一文教你轻松获取表倾斜率的主要内容,如果未能解决你的问题,请参考以下文章