机器学习入门:多变量线性回归
Posted 华为云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习入门:多变量线性回归相关的知识,希望对你有一定的参考价值。
摘要:给大家简单介绍了多变量线性回归,还附赠在处理梯度下降过程中通用的两个小技巧。
本文分享自华为云社区《【跟着小Mi一起机器学习吧!】多变量线性回归(一)》,原文作者:Skytier。
1 多维特征
既然是多变量线性回归,那么肯定是存在多个变量或者多个特征的情况啦。就拿之前研究的线性回归来说,只有一个单一的特征变量即x表示房屋面积,我们希望用这个特征量来预测Y,也就是房屋的价格。当然,实际情况肯定并非如此,大伙在买房的时候是不是还要考虑房屋的数量、楼层数、房子的年龄等等各种信息呀,那么我们就可以用![]() 来表示这四个特征,仍然可以用Y来表示我们所想要预测的输出变量。
来表示这四个特征,仍然可以用Y来表示我们所想要预测的输出变量。
现在我们有四个特征变量,如下图:
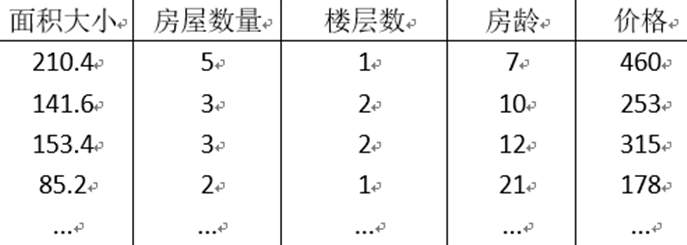
小写n可以用来表示特征量的数目,这里例子中n=4,有4个特征。这里的n和之前的符号m是不一样的概念,之前我们用m来表示样本的数量,所以如果你有47行,那么m就是这个表格里面的行数或者说是训练样本数。然后我们要用![]() 来表示第i个训练样本的输入特征值。举个具体的例子,
来表示第i个训练样本的输入特征值。举个具体的例子,![]() 就表示第二个训练样本的特征向量,所以这里的
就表示第二个训练样本的特征向量,所以这里的![]() =
= ,即预测第二套房子价格的四个特征量。小tips,这里的上标2就是训练集的一个索引,可千万不要给它看作是x的二次平方哦,而是对应着你所看到的表格中的第二行,也就是第二个训练样本,是一个四维向量。事实上更普遍地来说,这是一个n维的向量。而
,即预测第二套房子价格的四个特征量。小tips,这里的上标2就是训练集的一个索引,可千万不要给它看作是x的二次平方哦,而是对应着你所看到的表格中的第二行,也就是第二个训练样本,是一个四维向量。事实上更普遍地来说,这是一个n维的向量。而![]() 则表示第i个训练样本中第j特征量的值,对应表格中,
则表示第i个训练样本中第j特征量的值,对应表格中,![]() 代表着第二个训练样本中第三个特征量的值,也就是2。
代表着第二个训练样本中第三个特征量的值,也就是2。
好了,表达形式搞清楚了,那么假设由于变量的增多,当然也会有所改变啦。单变量的假设函数是![]() ,这么一类比,小Mi要考考大家啦!多变量又是什么情况呢,又是多变量,又是线性的。没错,支持多变量假设形式就是:
,这么一类比,小Mi要考考大家啦!多变量又是什么情况呢,又是多变量,又是线性的。没错,支持多变量假设形式就是:![]() 。
。
举个例子:![]()
详细来说,这个假设是为了预测以万为单位的房屋价格,一个房子的基本的价格可能是80w,加上每平方米1000元,然后价格会随着楼层数的增加继续增长,随着卧室数的增加而增加,但是呢,随着使用年数的增加而贬值,这么一看这个例子是不是很有道理!
不过强迫症的小Mi还想队伍形式更加统一一点,为了表示方便,我们可以假定![]() 的值为1,具体而言,这意味着对于第i个样本都有一个向量
的值为1,具体而言,这意味着对于第i个样本都有一个向量![]() ,并且
,并且![]() 。也可以说额外定义了第0个特征量。因此,现在的特征向量x是一个从0开始标记的n+1维的向量。而参数
。也可以说额外定义了第0个特征量。因此,现在的特征向量x是一个从0开始标记的n+1维的向量。而参数![]() 也是一个从0开始标记的向量,它也是n+1维的特征量向量。
也是一个从0开始标记的向量,它也是n+1维的特征量向量。
由此假设就可以摇身一变简化为:![]() ,其中上标T代表矩阵的转置,是不是很巧妙!
,其中上标T代表矩阵的转置,是不是很巧妙!
![]()
这里小Mi还真不得不夸下这个![]() ,是它是它就是它,帮助我们可以以这种非常简洁的形式写出假设。这就是多特征量情况下的假设形式,也就是所谓的多元线性回归。多元一词就是表示我们用多个特征量或者变量来预测Y值。
,是它是它就是它,帮助我们可以以这种非常简洁的形式写出假设。这就是多特征量情况下的假设形式,也就是所谓的多元线性回归。多元一词就是表示我们用多个特征量或者变量来预测Y值。
2 多变量梯度下降
好了,多变量线性回归假设的形式已经有了,也就是说料已经有了,接下来就要开始炒菜啦!
在多元回归的假设形式中,我们已经按惯例假设![]() 。此模型的参数包括
。此模型的参数包括![]() ,但在这里我们不把它看作n个独立参数,而是考虑把这些参数看作一个n+1维的
,但在这里我们不把它看作n个独立参数,而是考虑把这些参数看作一个n+1维的![]() 向量,因此代价函数
向量,因此代价函数![]() 的表达式表示为:
的表达式表示为: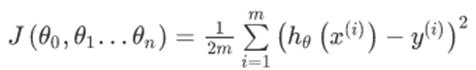
其中,![]()
我们的目标和单变量线性回归问题中一样,是要找出使得代价函数最小的一系列参数。 多变量线性回归的批量梯度下降算法为:
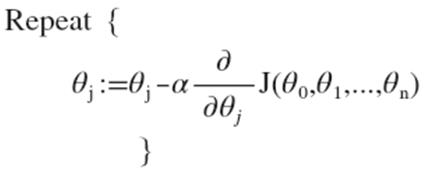
即:
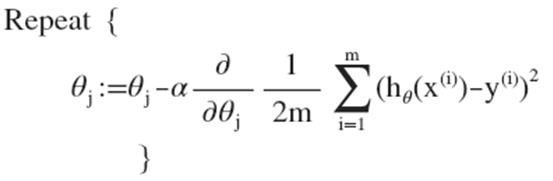
求导数后可得到:

我们要不断更新每个![]() 参数,通过
参数,通过![]() 减去
减去![]() 乘以导数项,我们再整理好写成
乘以导数项,我们再整理好写成![]() ,从而将会得到可行的用于多元线性回归的梯度下降法。
,从而将会得到可行的用于多元线性回归的梯度下降法。
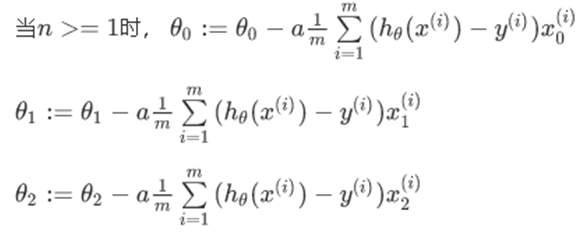
代码示例:
计算代价函数:
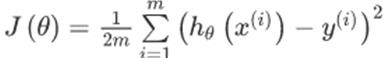 。其中,
。其中,![]()
Python 代码:
def computeCost(X, y, theta):
inner = np.power(((X * theta.T) - y), 2)
return np.sum(inner) / (2 * len(X))3 梯度下降法实践-特征缩放
接下来,我们将学习一些在梯度下降运算中的实用技巧,首先给大家介绍一个称为特征缩放的方法,这个方法如下:
如果你有一个机器学习问题,这个问题有多个特征,而你能确保这些特征都处在一个相近的范围内,也就是说确保不同特征的取值在相近的范围内,这样梯度下降法就能更快地收敛。具体来说,假如你有一个具有两个特征的问题,其中![]() 是房屋面积大小,它的取值在0~2000之间,
是房屋面积大小,它的取值在0~2000之间,![]() 是卧室的数量,可能取值在1~5之间,如果你要画出代价函数
是卧室的数量,可能取值在1~5之间,如果你要画出代价函数![]() 的等值线,那么看起来应该是像这样的,是一个关于参数
的等值线,那么看起来应该是像这样的,是一个关于参数![]() 和
和![]() 的函数,这里要忽略
的函数,这里要忽略![]() ,并假想这个函数的变量只有
,并假想这个函数的变量只有![]() 和
和![]() ,但如果
,但如果![]() 的取值范围远远大于
的取值范围远远大于![]() 的取值范围的话,那么最终画出来的代价函数
的取值范围的话,那么最终画出来的代价函数![]() 的等值线就会呈现出这样一种非常歪斜并且椭圆的形状,其实2000比5的比例会让这个椭圆更加瘦长。所以这个又瘦又高的椭圆形等值线图就是这些非常高大细长的椭圆形构成了代价函数
的等值线就会呈现出这样一种非常歪斜并且椭圆的形状,其实2000比5的比例会让这个椭圆更加瘦长。所以这个又瘦又高的椭圆形等值线图就是这些非常高大细长的椭圆形构成了代价函数![]() 的等值线。如果你在这种代价函数上运行梯度下降的话,你的梯度最终可能需要花很长一段时间,并且可能会来回波动,然后会经过很长时间,最终才会收敛到全局最小值。
的等值线。如果你在这种代价函数上运行梯度下降的话,你的梯度最终可能需要花很长一段时间,并且可能会来回波动,然后会经过很长时间,最终才会收敛到全局最小值。
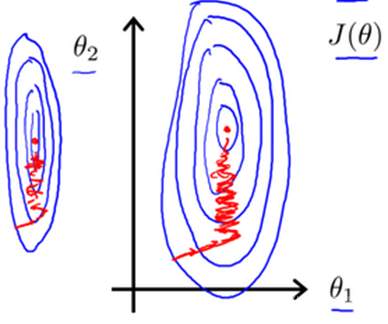
事实上,你可以想象,如果这些等值线更夸张一些,就是把它画的更细更长,可能就比这更夸张,结果就是梯度下降的过程可能更加缓慢,反复来回振荡需要更长的时间,才找到一条通往全局最小值的路。在这样的情况下,一种有效的方法就是进行特征缩放。具体来说,如果把特征![]() 定义为房子的面积大小除以2000,并且把
定义为房子的面积大小除以2000,并且把![]() 定义为卧室的数量除以5,那么代价函数
定义为卧室的数量除以5,那么代价函数![]() 的等值线就会偏移得没那么严重,看起来更圆一些了。如果你在这样的代价函数上来执行梯度下降的话,那么梯度下降算法可以从数学上来证明,就会找到一条更直接的路径,通向全局最小,而不是像刚才那样,沿着一条复杂得多的路径来找全局最小值。因此,通过这些特征缩放,它们的值的范围变得相近,在这个例子中,我们最终使两个特征
的等值线就会偏移得没那么严重,看起来更圆一些了。如果你在这样的代价函数上来执行梯度下降的话,那么梯度下降算法可以从数学上来证明,就会找到一条更直接的路径,通向全局最小,而不是像刚才那样,沿着一条复杂得多的路径来找全局最小值。因此,通过这些特征缩放,它们的值的范围变得相近,在这个例子中,我们最终使两个特征![]() 和
和![]() 都在0和1之间,这样你得到的梯度下降法就会更快地收敛。
都在0和1之间,这样你得到的梯度下降法就会更快地收敛。
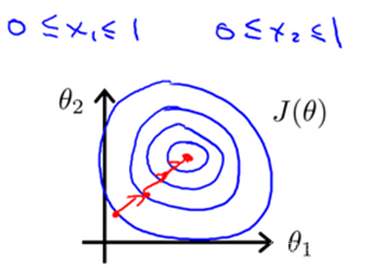
更一般地,我们执行特征缩放时,我们通常的目的是将特征的取值约束到-1到+1的范围内。具体来说,你的特征![]() 总是等于1。因此,这已经是在这个范围内,但对其他的特征,你可能需要通过除以不同的数,来让它们处于同一范围内。-1和+1这两个数字并不是太重要,所以,如果你有一个特征
总是等于1。因此,这已经是在这个范围内,但对其他的特征,你可能需要通过除以不同的数,来让它们处于同一范围内。-1和+1这两个数字并不是太重要,所以,如果你有一个特征![]() ,它的取值在0~3之间,这没问题;如果你有另外一个特征
,它的取值在0~3之间,这没问题;如果你有另外一个特征![]() ,取值在-2到+0.5之间,这也非常接近-1到+1的范围,这些都是可以的;但如果你有另一个特征比如
,取值在-2到+0.5之间,这也非常接近-1到+1的范围,这些都是可以的;但如果你有另一个特征比如![]() ,假如它的单位在-100~+100之间,那么这个范围跟-1~+1就有很大不同了。所以,这可能是一个范围不太合适的特征。类似地,如果你的特征在一个非常非常小的范围内,比如一个特征
,假如它的单位在-100~+100之间,那么这个范围跟-1~+1就有很大不同了。所以,这可能是一个范围不太合适的特征。类似地,如果你的特征在一个非常非常小的范围内,比如一个特征![]() 的范围在-0.0001~+0.0001之间,那么这同样是一个比-1~+1小得多的范围。因此,我同样会认为,这个特征的范围不合适。所以,可能你认可的范围,也许可以大于+1或者小于+1,但是也别太大,比如+100,或者也别太小,比如这里的0.001,不同的人有不同的经验。但是,正常可以这么考虑,如果一个特征是在-3~+3范围内,这个范围是可以接受的,但如果这个范围大于了-3~+3的范围,我可能就要开始注意了,如果它的取值在-1/3~+1/3的话,我也觉得还不错,可以接受,或者是0~1/3或者-1/3~0,这些典型的范围我都觉得是可以接受的,但如果特征的范围取得很小的话,比如刚刚提及的
的范围在-0.0001~+0.0001之间,那么这同样是一个比-1~+1小得多的范围。因此,我同样会认为,这个特征的范围不合适。所以,可能你认可的范围,也许可以大于+1或者小于+1,但是也别太大,比如+100,或者也别太小,比如这里的0.001,不同的人有不同的经验。但是,正常可以这么考虑,如果一个特征是在-3~+3范围内,这个范围是可以接受的,但如果这个范围大于了-3~+3的范围,我可能就要开始注意了,如果它的取值在-1/3~+1/3的话,我也觉得还不错,可以接受,或者是0~1/3或者-1/3~0,这些典型的范围我都觉得是可以接受的,但如果特征的范围取得很小的话,比如刚刚提及的![]() ,就要开始考虑。因此,总的来说,不用过于担心你的特征是否在完全相同的范围或区间内,但是只要它们足够接近的话,梯度下降法就会正常地工作。除了将特征除以最大值以外,在特征缩放中,有时候我们也会进行一个称之为均值归一化的工作,也就是说你有一个特征
,就要开始考虑。因此,总的来说,不用过于担心你的特征是否在完全相同的范围或区间内,但是只要它们足够接近的话,梯度下降法就会正常地工作。除了将特征除以最大值以外,在特征缩放中,有时候我们也会进行一个称之为均值归一化的工作,也就是说你有一个特征![]() ,就可以用
,就可以用![]() 来替换,让你的特征值具有为0的平均值。
来替换,让你的特征值具有为0的平均值。
很明显,我们不需要把这一步应用到![]() 中,因为
中,因为![]() 总是等于1,所以它不可能有为0的平均值,但是对其他的特征来说,比如房子的大小取值介于0~2000之间,并且假如房子面积的平均值是等于1000,那么你可以用如下公式,将
总是等于1,所以它不可能有为0的平均值,但是对其他的特征来说,比如房子的大小取值介于0~2000之间,并且假如房子面积的平均值是等于1000,那么你可以用如下公式,将![]() 的值变为size,减去平均值,再除以2000。类似地,如果这些房子有1~5卧室,并且平均一套房子有两间卧室,那么你可以使用这个公式来均值归一化你的第二个特征
的值变为size,减去平均值,再除以2000。类似地,如果这些房子有1~5卧室,并且平均一套房子有两间卧室,那么你可以使用这个公式来均值归一化你的第二个特征![]() ,在这两种情况下,你可以算出新的特征
,在这两种情况下,你可以算出新的特征![]() 和
和![]() ,这样它们的范围可以在-0.5~+0.5之间。当然这不一定对,
,这样它们的范围可以在-0.5~+0.5之间。当然这不一定对,![]() 的值可以略大于0.5,但很接近。更一般的规律是,你可以把
的值可以略大于0.5,但很接近。更一般的规律是,你可以把![]() 替代为
替代为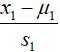 ,其中,定义
,其中,定义![]() 是训练接中特征
是训练接中特征![]() 的平均值,而这个
的平均值,而这个![]() 是该特征值的范围,范围指的是最大值减去最小值。或者对于学过标准差的同学来说,把
是该特征值的范围,范围指的是最大值减去最小值。或者对于学过标准差的同学来说,把![]() 设为变量的标准差也是可以的,但是其实用最大值减最小值就可以了。类似地,对于第二个特征
设为变量的标准差也是可以的,但是其实用最大值减最小值就可以了。类似地,对于第二个特征![]() ,也可以同样的减去平均值再除以范围,也就是最大值减最小值。这类公式将你的特征也许并不是这样,但是大概是这样范围,顺便提一下,只需要将特征转换为相近似的范围就都是可以的,特征缩放其实并不需要太精确,只是为了让梯度下降能够运行得更快一点而已,收敛所需的迭代次数更少就行了。
,也可以同样的减去平均值再除以范围,也就是最大值减最小值。这类公式将你的特征也许并不是这样,但是大概是这样范围,顺便提一下,只需要将特征转换为相近似的范围就都是可以的,特征缩放其实并不需要太精确,只是为了让梯度下降能够运行得更快一点而已,收敛所需的迭代次数更少就行了。
4 梯度下降法实践-学习率
另一种技巧可以使梯度下降在实践中工作地更好,也就是有关学习率![]() 。具体而言,这是梯度下降算法的更新规则,我们需要认识的是所谓的调试是什么,还有一些小技巧来确保梯度下降是正常工作的,另外,还需要知道如何选择学习率
。具体而言,这是梯度下降算法的更新规则,我们需要认识的是所谓的调试是什么,还有一些小技巧来确保梯度下降是正常工作的,另外,还需要知道如何选择学习率![]() 。
。
通常做的事是确保梯度下降正常工作。梯度下降所做的事情就是为你找到一个![]() 值,并且希望它能够最小化代价函数
值,并且希望它能够最小化代价函数![]() 。因此,通常可以在梯度下降算法运行时,画出代价函数
。因此,通常可以在梯度下降算法运行时,画出代价函数![]() 的值。
的值。
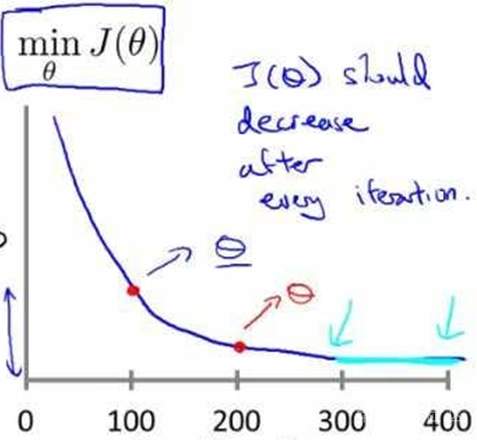
这里的x轴表示的是梯度下降算法的迭代次数。随着梯度下降算法的运行,你可能会得到这样一条曲线,注意x轴是迭代次数,之前我们给出的![]() 中,x轴表示的是参数向量
中,x轴表示的是参数向量![]() ,与当前图像不同。具体来说,第一个红点的含义是运行100次的梯度下降迭代后得到某个
,与当前图像不同。具体来说,第一个红点的含义是运行100次的梯度下降迭代后得到某个![]() 值,对于这个点,表示梯度下降算法100步迭代后,得到的
值,对于这个点,表示梯度下降算法100步迭代后,得到的![]() 值算出的
值算出的![]() 。而第二个红点对应的是梯度下降算法200步迭代后得到的
。而第二个红点对应的是梯度下降算法200步迭代后得到的![]() 值算出的
值算出的![]() 。所以这个曲线表示的是梯度下降的每步迭代后代价函数的值。如果梯度下降算法正常工作的话,每一步迭代之后
。所以这个曲线表示的是梯度下降的每步迭代后代价函数的值。如果梯度下降算法正常工作的话,每一步迭代之后![]() 都应该下降。这条曲线的一个用处在于它可以告诉你,当你达到300步迭代后,300-400步迭代之间,
都应该下降。这条曲线的一个用处在于它可以告诉你,当你达到300步迭代后,300-400步迭代之间,![]() 并没有下降多少,所以当你达到400步迭代时,这条曲线看起来已经很平坦了。在这里400步迭代的时候,梯度下降算法差不多已经收敛了。通过这条曲线可以帮助你判断梯度下降算法是否已经收敛。顺便提一下,对于每一个特定的问题,梯度下降算法所需的迭代次数可能会相差很大,所以对于某一个问题,梯度下降算法只需要30步迭代就可以达到收敛,然而换一个问题,也许梯度下降算法需要3000步迭代或者是3000000步甚至更多,实际上我们很难提前判断,梯度下降算法需要多少步才能收敛。另外,也可以进行一些自动的收敛测试,也就是说让一种算法来告诉你梯度下降算法是够已经收敛。
并没有下降多少,所以当你达到400步迭代时,这条曲线看起来已经很平坦了。在这里400步迭代的时候,梯度下降算法差不多已经收敛了。通过这条曲线可以帮助你判断梯度下降算法是否已经收敛。顺便提一下,对于每一个特定的问题,梯度下降算法所需的迭代次数可能会相差很大,所以对于某一个问题,梯度下降算法只需要30步迭代就可以达到收敛,然而换一个问题,也许梯度下降算法需要3000步迭代或者是3000000步甚至更多,实际上我们很难提前判断,梯度下降算法需要多少步才能收敛。另外,也可以进行一些自动的收敛测试,也就是说让一种算法来告诉你梯度下降算法是够已经收敛。
梯度下降算法收敛所需要的迭代次数根据模型的不同而不同,我们不能提前预知,我们可以绘制迭代次数和代价函数的图表来观测算法在何时趋于收敛。
也有一些自动测试是否收敛的方法,例如将代价函数的变化值小于某个阀值(例如0.001),那么测试就判定函数已经收敛,但是选择一个合适的阈值是相当困难的,因此,为了检测梯度下降算法是否收敛,更倾向于通过看曲线图,而不是依靠自动收敛测试。
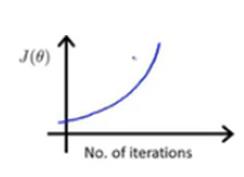
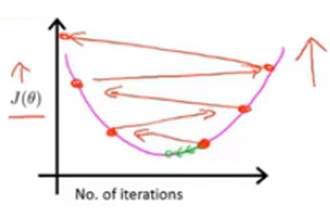
此外,这种曲线图还可以提前告知我们算法没有正常工作,具体地说,代价函数![]() 随迭代步数的变化曲线,实际上在不断上升,就表明梯度下降算法没有正常工作,而这样的曲线图意味着我应该使用较小的学习率。先前也已经推理过学习率大小的问题,梯度下降算法的每次迭代受到学习率的影响,如果学习率过小,则达到收敛所需的迭代次数会非常高,会收敛得很慢;如果学习率过大,每次迭代可能不会减小代价函数,可能会越过局部最小值导致无法收敛。所以如果画出代价函数的曲线,我们可以清楚知道到底发生了什么
随迭代步数的变化曲线,实际上在不断上升,就表明梯度下降算法没有正常工作,而这样的曲线图意味着我应该使用较小的学习率。先前也已经推理过学习率大小的问题,梯度下降算法的每次迭代受到学习率的影响,如果学习率过小,则达到收敛所需的迭代次数会非常高,会收敛得很慢;如果学习率过大,每次迭代可能不会减小代价函数,可能会越过局部最小值导致无法收敛。所以如果画出代价函数的曲线,我们可以清楚知道到底发生了什么
具体来说,我们通常可以尝试一系列![]() 值:
值:
比如:0.001,0.003,0.01,0.03,0.1,0.3,1,...,每3倍取一个值,然后对这些不同的![]() 值绘制
值绘制![]() 随迭代步数变化的曲线,从而选择的是
随迭代步数变化的曲线,从而选择的是![]() 快速下降的一个
快速下降的一个![]() 值。
值。
以上是关于机器学习入门:多变量线性回归的主要内容,如果未能解决你的问题,请参考以下文章