RocketMQ基础概念剖析&源码解析
Posted Hollis Chuang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RocketMQ基础概念剖析&源码解析相关的知识,希望对你有一定的参考价值。
Topic
Topic是一类消息的集合,是一种逻辑上的分区。为什么说是逻辑分区呢?因为最终数据是存储到Broker上的,而且为了满足高可用,采用了分布式的存储。
这和Kafka中的实现如出一辙,Kafka的Topic也是一种逻辑概念,每个Topic的数据会分成很多份,然后存储在不同的Broker上,这个「份」叫Partition。而在RocketMQ中,Topic的数据也会分布式的存储,这个「份」叫MessageQueue。
其分布可以用下图来表示。
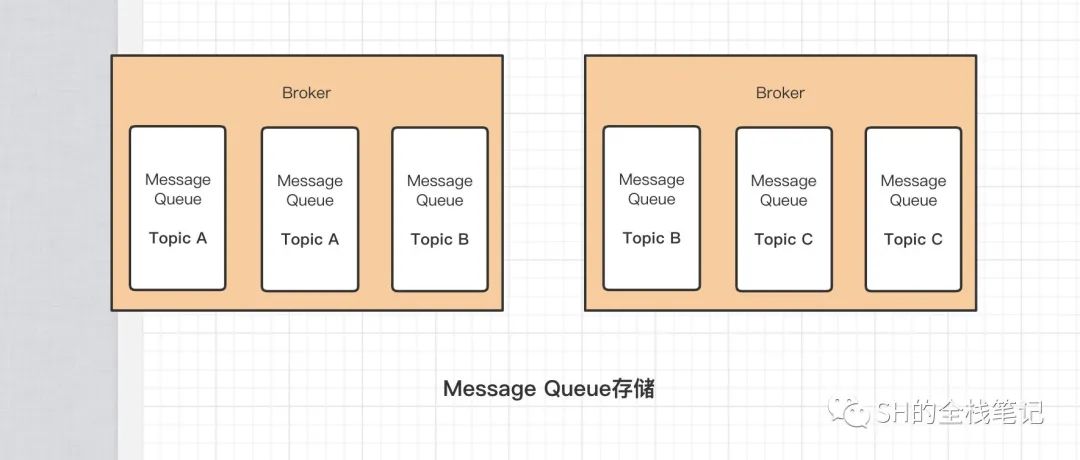
这样一来,如果某个Broker所在的机器意外宕机,而且刚好MessageQueue中的数据还没有持久化到磁盘,那么该Topic下的这部分消息就会完全丢失。此时如果有备份的话,MQ就可以继续对外提供服务。
为什么还会出现没有持久化到磁盘的情况呢?现在的OS当中,程序写入数据到文件之后,并不会立马写入到磁盘,因为磁盘I/O是非常耗时的操作,在计算机来看是非常慢的一种操作。所以写入文件的数据会先写入到OS自己的缓存中去,然后择机异步的将Buffer中的数据刷入磁盘。
通过多副本冗余的机制,使得RocketMQ具有了高可用的特性。除此之外,分布式存储能够应对后期业务大量的数据存储。如果不使用分布式进行存储,那么随着后期业务发展,消息量越来越大,单机是无论如何也满足不了RocketMQ消息的存储需求的。如果不做处理,那么一台机器的磁盘总有被塞满的时候,此时的系统就不具备可伸缩的特性,也无法满足业务的使用要求了。
但是这里的可伸缩,和微服务中的服务可伸缩还不太一样。因为在微服务中,各个服务是无状态的。而Broker是有状态的,每个Broker上存储的数据都不太一样,因为Producer在发送消息的时候会通过指定的算法,从Message Queue列表中选出一个MessageQueue发送消息。
如果不是很理解这个横向扩展,那么可以把它当成Redis的Cluster,通过一致性哈希,选择到Redis Cluster中的具体某个节点,然后将数据写入Redis Master中去。如果此时想要扩容很方便,只需要往Redis Cluster中新增Master节点就好了。
所以,数据分布式的存储本质上是一种数据分片的机制。在此基础上,通过冗余多副本,达成了高可用。
Broker
Broker可以理解为我们微服务中的一个服务的某个实例,因为微服务中我们的服务一般来说都会多实例部署,而RocketMQ也同理,多实例部署可以帮助系统扛住更多的流量,也从某种方面提高了系统的健壮性。
在RocketMQ4.5之前,它使用主从架构,每一个Master Broker都有一个自己的Slave Broker。
那RocketMQ的主从Broker是如何进行数据同步的呢?
Broker启动的时候,会启动一个定时任务,定期的从Master Broker同步全量的数据。
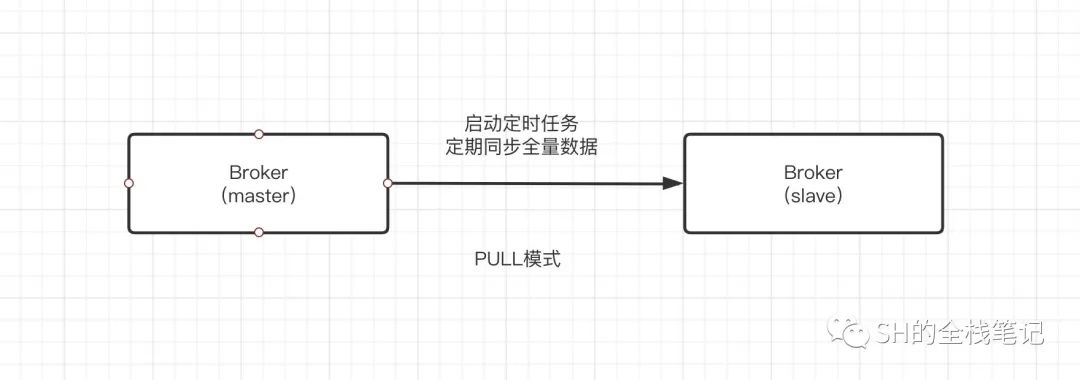
这块可以先不用纠结,后面我们会通过源码来验证这个主从同步逻辑。
上面提到了Broker会部署很多个实例,那么既然多实例部署,那必然会存在一个问题,客户端是如何得知自己是连接的哪个服务器?如何得知对应的Broker的IP地址和端口?如果某个Broker突然挂了怎么办?
NameServer
这就需要NameServer了,NameServer是什么?
这里先拿Spring Cloud举例子——Spring Cloud中服务启动的时候会将自己注册到Eureka注册中心上。当服务实例启动的时候,会从Eureka拉取全量的注册表,并且之后定期的从Eureka增量同步,并且每隔30秒发送心跳到Eureka去续约。如果Eureka检测到某个服务超过了90秒没有发送心跳,那么就会该服务宕机,就会将其从注册表中移除。
RocketMQ中,NameServer充当的也是类似的角色。两者从功能上也有一定的区别。
Broker在启动的时候会向NameServer注册自己,并且每隔30秒向NameServerv发送心跳。如果某个Broker超过了120秒没有发送心跳,那么就会认为该Broker宕机,就会将其从维护的信息中移除。这块后面也会从源码层面验证。
当然NameServer不仅仅是存储了各个Broker的IP地址和端口,还存储了对应的Topic的路由数据。什么是路由数据呢?那就是某个Topic下的哪个Message Queue在哪台Broker上。
Producer
总体流程
接下来,我们来看看Producer发送一条消息到Broker的时候会做什么事情,整体的流程如下。
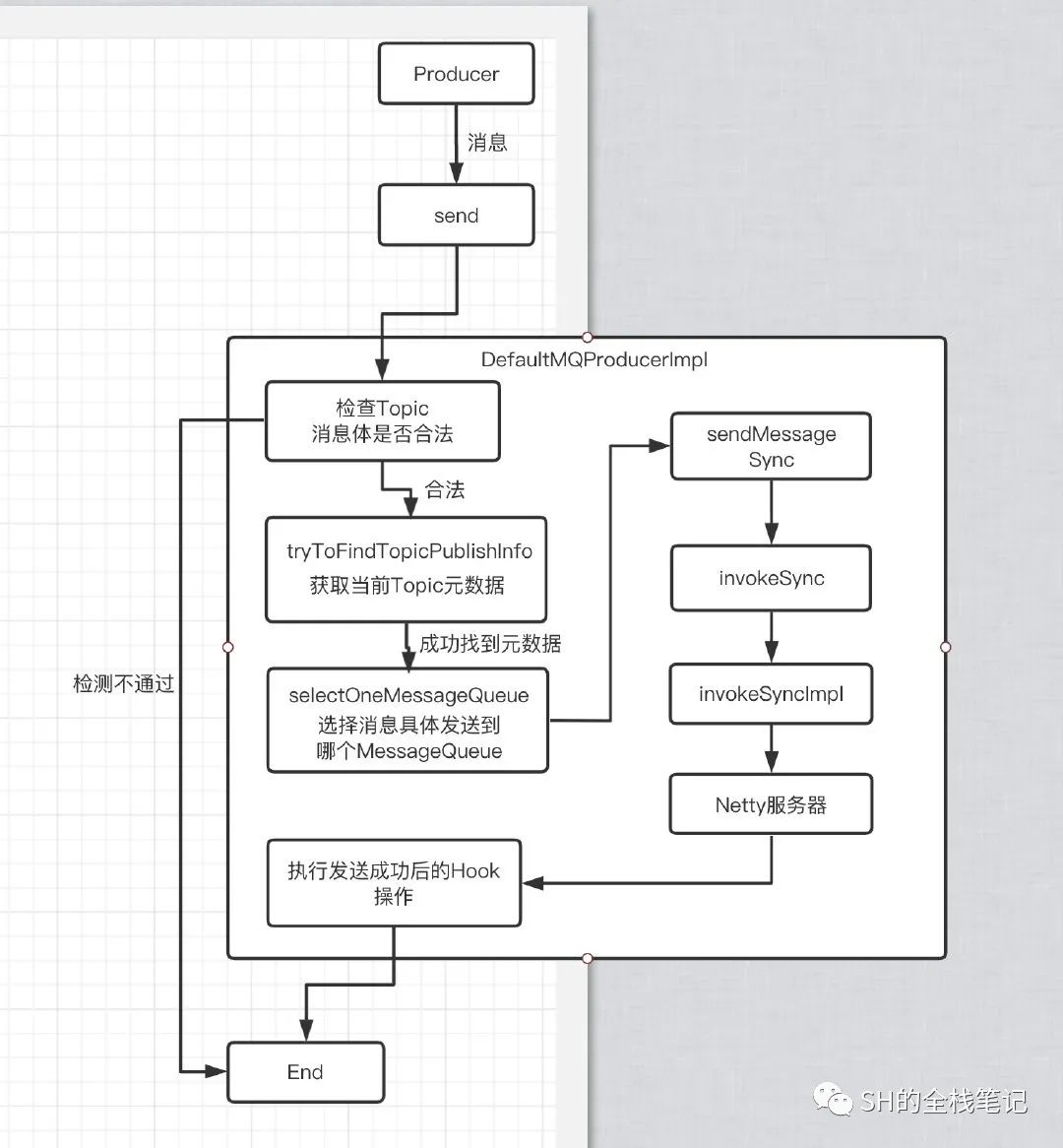
检查消息合法性
整体来看,其实是个很简单的操作,跟我们平时写代码是一样的,来请求了先校验请求是否合法。Producer启动这里会去校验当前Topic数据的合法性。
-
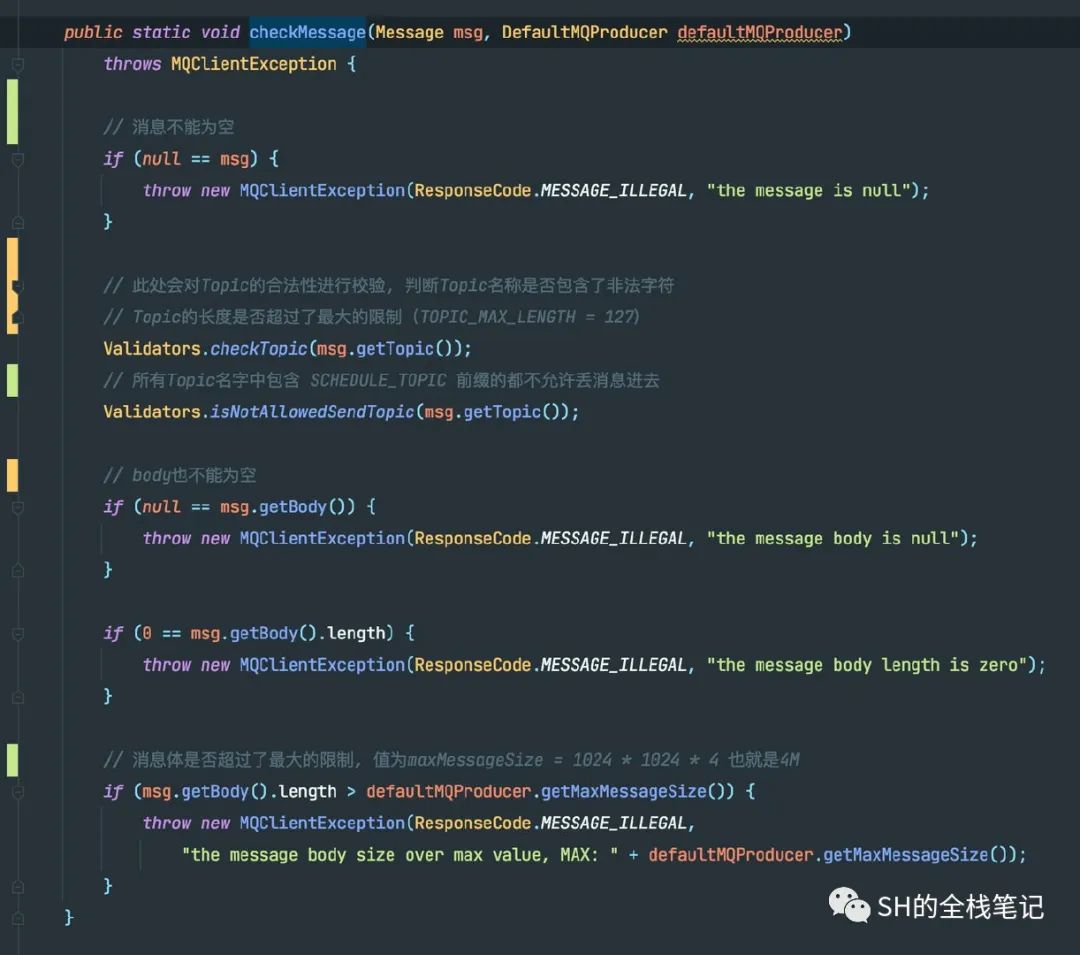
Topic名称中是否包含了非法字符
-
Topic名称长度是否超过了最大的长度限制,由常量TOPIC_MAX_LENGTH来决定,其默认值为127
-
当前消息体是否是NULL或者是空消息
-
当前消息体是否超过了最大限制,由常量maxMessageSize决定,值为1024 * 1024 * 4,也就是4M。
都是些很常规的操作,和我们平时写的checker都差不多。
获取Topic的详情
当通过了消息的合法性校验之后,就需要继续往下走。此时的关注点就应该从消息是否合法转移到我要发消息给谁。
此时就需要通过当前消息所属的Topic拿到Topic的详细数据。
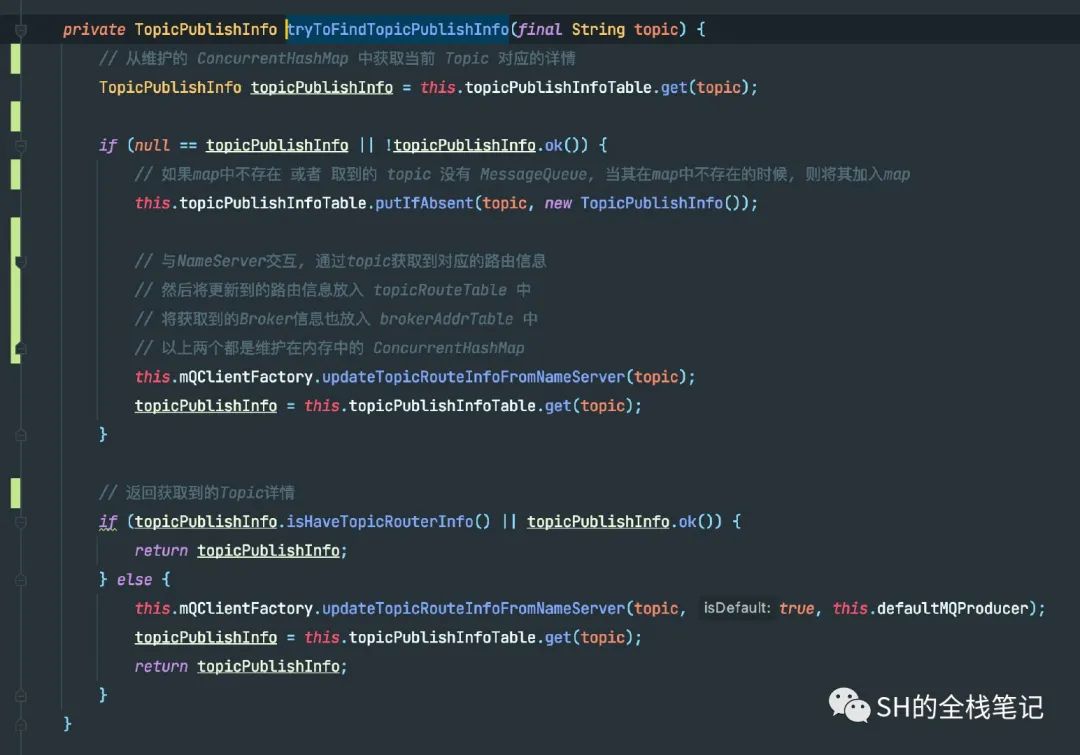
获取Topic的方法源码在上面已经给出来了,首先会从内存中维护的一份Map中获取数据。顺带一提,这里的Map是ConcurrentHashMap,是线程安全的,和Golang中的Sync.Map类似。
当然,首次发送的话,这个Map肯定是空的,此时会调用NameServer的接口,通过Topic去获取详情的Topic数据,此时会在上面的方法中将其加入到Map中去,这样一来下次再往该Topic发送消息就能够直接从内存中获取。这里就是简单的实现的缓存机制 。
从方法名称来看,是通过Topic获取路由数据。实际上该方法,通过调用NameServer提供的API,更新了两部分数据,分别是:
Topic路由信息
Topic下的Broker相关信息
而这两部分数据都来源于同一个结构体TopicRouteData。其结构如下。
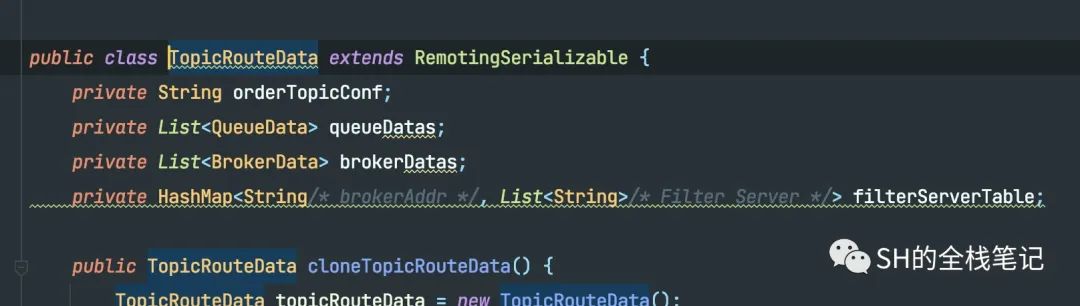
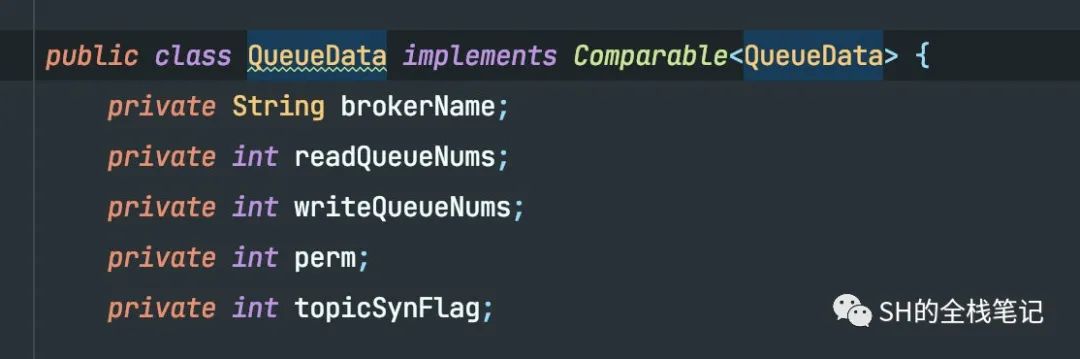
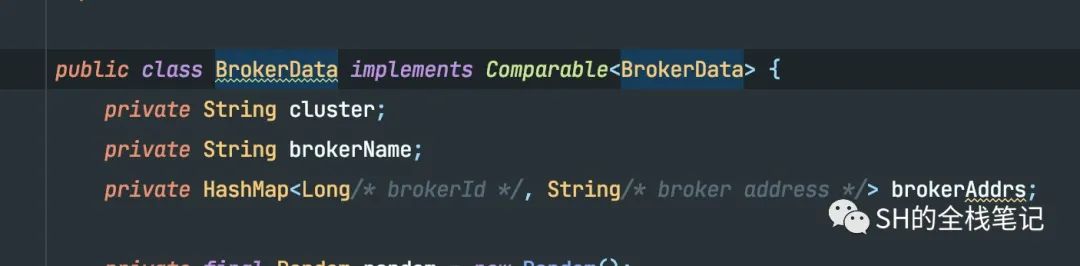
通过源码可以看到,就包含了该Topic下所有Broker下的Message Queue相关的数据、所有Broker的地址信息。
发送的具体Queue
此时我们获取到了需要发送到的Broker详情,包括地址和MessageQueue,那么此时问题的关注点又该从「消息发送给谁」转移到「消息具体发送到哪儿」。
什么叫发送到哪儿?
开篇提到过一个Topic下会被分为很多个MessageQueue,「发送到哪儿」指的就是具体发送到哪一个Message Queue中去。
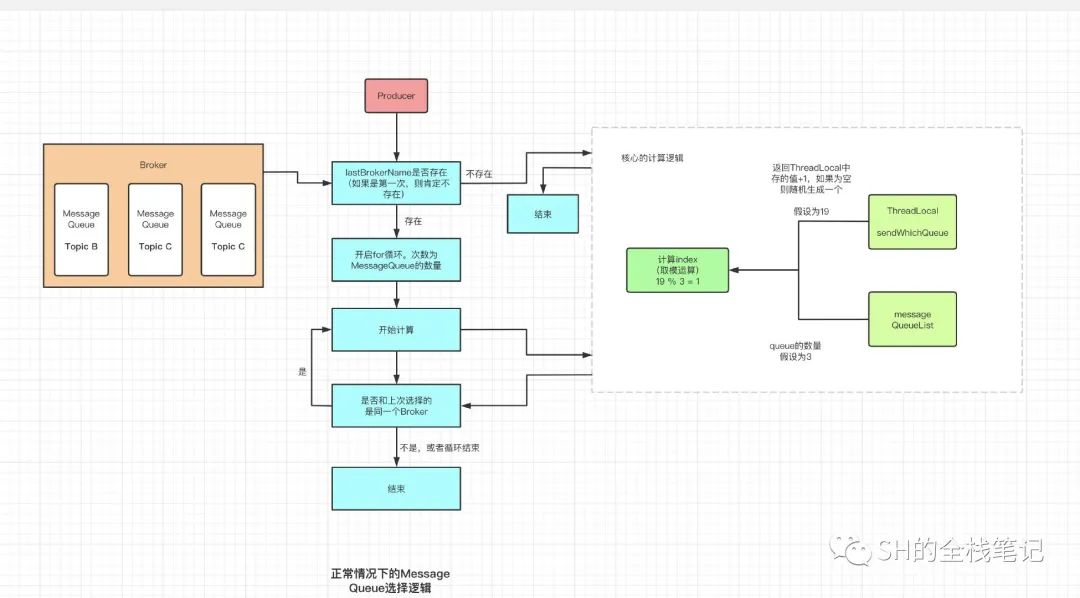
Message Queue选择机制
核心的选择逻辑
还是先给出流程图
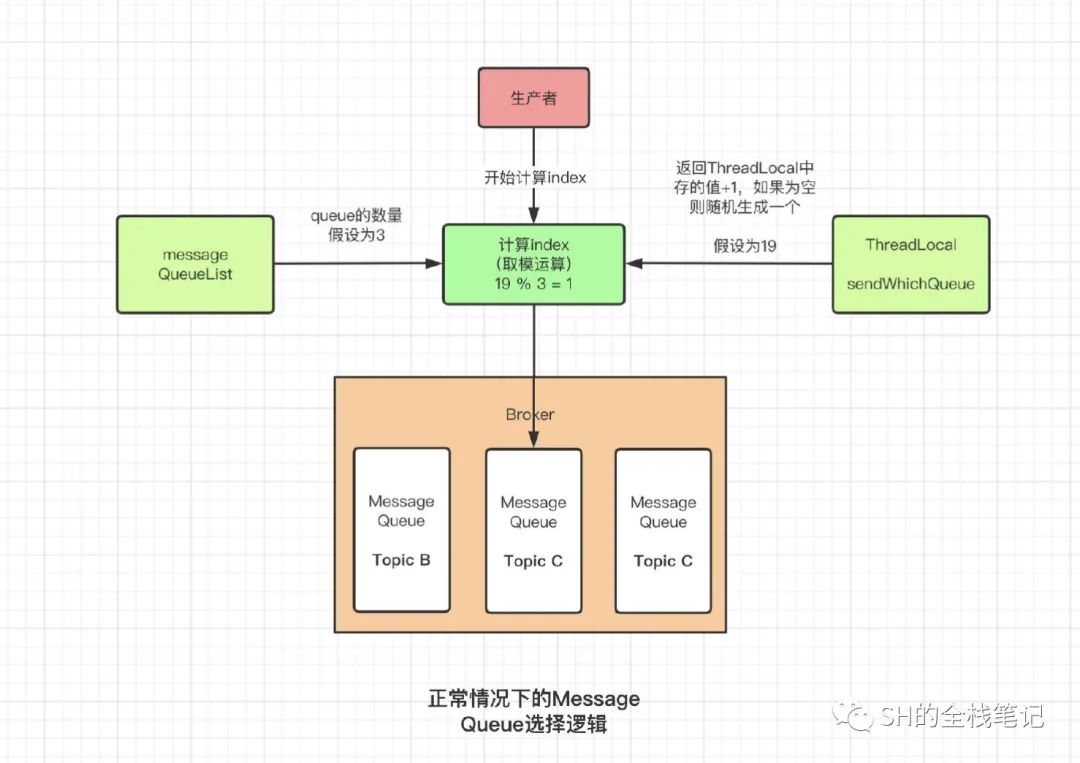
核心逻辑,用大白话讲就是将一个随机数和Message Queue的容量取模。这个随机数存储在Thread Local中,首次计算的时候,会直接随机一个数。
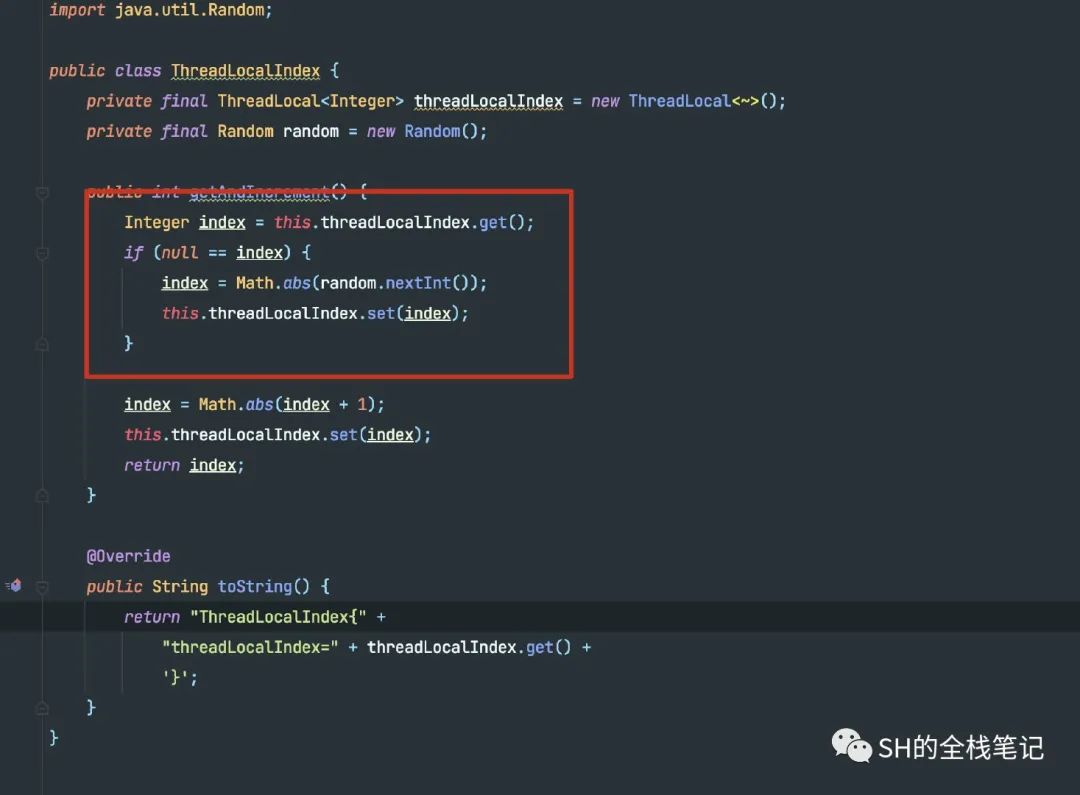
此后,都直接从ThreadLocal中取出该值,并且+1返回,拿到了MessageQueue的数量和随机数两个关键的参数之后,就会执行最终的计算逻辑。
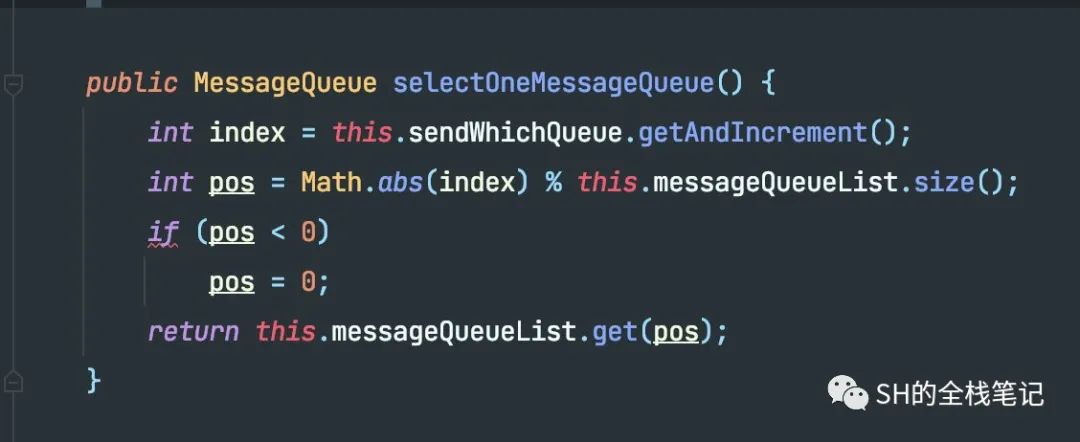
接下来,我们来看看选择Message Queue的方法SelectOneMessageQueue都做了什么操作吧。
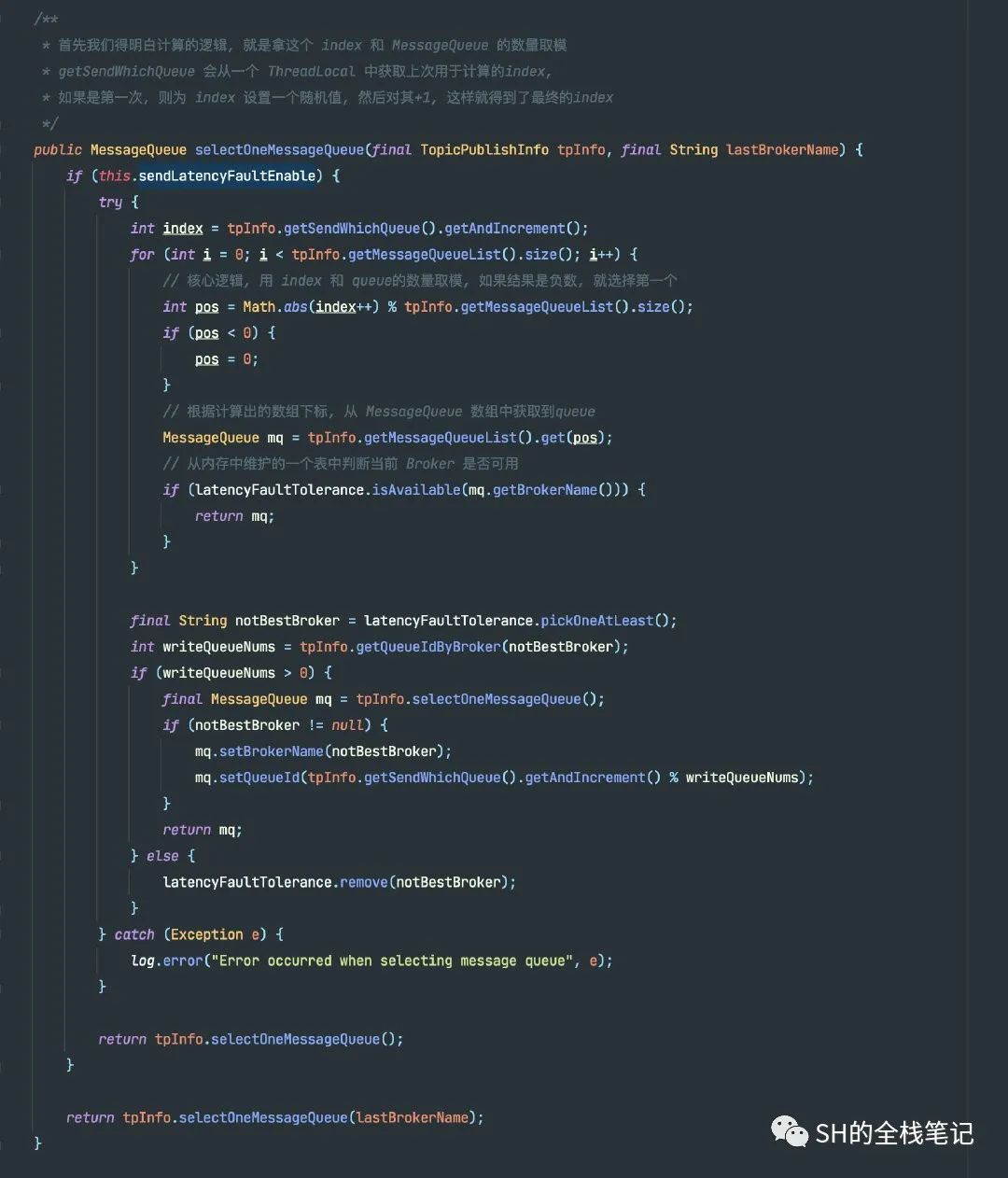
可以看到,主逻辑被变量sendLatencyFaultEnable分为了两部分。
容错机制下的选择逻辑
该变量表意为发送延迟故障。本质上是一种容错的策略,在原有的MessageQueue选择基础上,再过滤掉不可用的Broker,对之前失败的Broker,按一定的时间做退避。
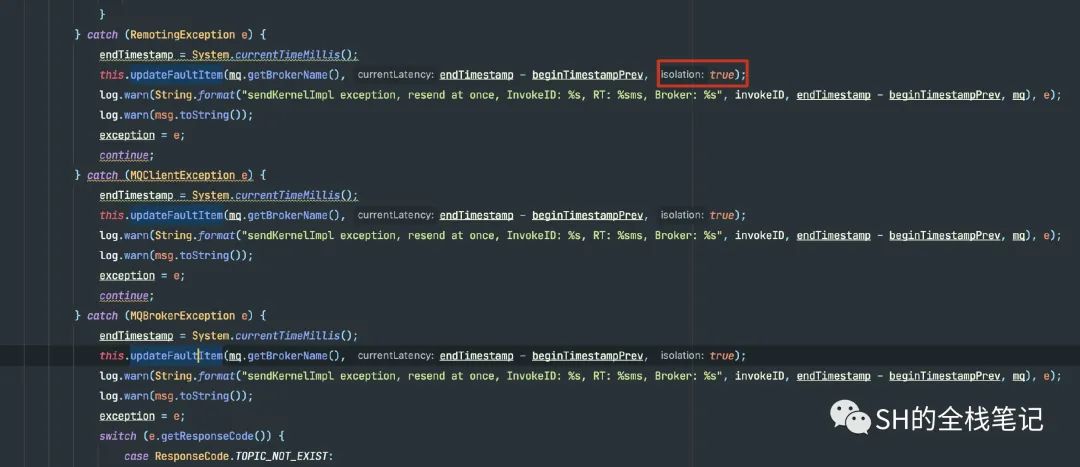
可以看到,如果调用Broker信息发生了异常,那么就会调用updateFault这个方法,来更新Broker的Aviable情况。注意这个参数isolation的值为true。接下来我们从源码级别来验证上面说的退避3000ms的事实。
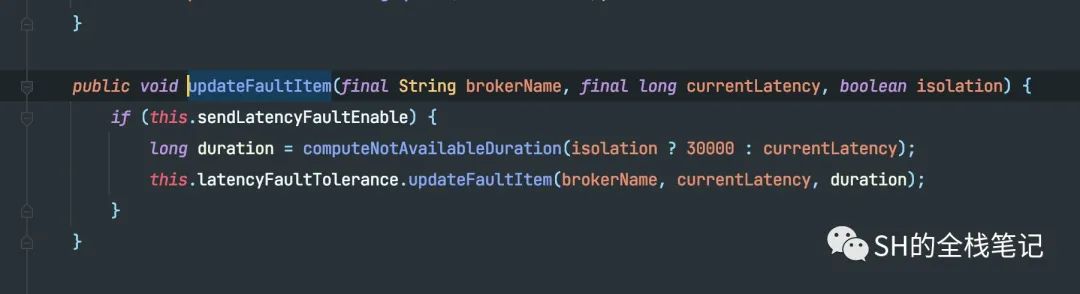
可以看到,isolation值是true,则duration通过三元运算符计算出来结果为30000,也就是30秒。所以我们可以得出结论,如果发送消息抛出了异常,那么直接会将该Broker设置为30秒内不可用。
而如果只是发送延迟较高,则会根据如下的map,根据延迟的具体时间,来判断该设置多少时间的不可用。

例如,如果上次请求的latency超过550ms,就退避3000ms;超过1000,就退避60000;
正常情况下的选择逻辑
而正常情况下,如果当前发送故障延迟没有启用,则会走常规逻辑,同样的会去for循环计算,循环中取到了MessageQueue之后会去判断是否和上次选择的MessageQueue属于同一个Broker,如果是同一个Broker,则会重新选择,直到选择到不属于同一个Broker的MessageQueue,或者直到循环结束。这也是为了将消息均匀的分发存储,防止数据倾斜。
发送消息
选到了具体的Message Queue之后就会开始执行发送消息的逻辑,就会调用底层Netty的接口给发送出去,这块暂时没啥可看的。
Broker的启动流程
主从同步
在上面提到过,RocketMQ有自己的主从同步,但是有两个不同的版本,版本的分水岭是在4.5版本。这两个版本区别是什么呢?
4.5之前:有点类似于Redis中,我们手动的将某台机器通过命令slave of 变成另一台Redis的Slave节点,这样一来就变成了一个较为原始的一主一从的架构。为什么说原始呢?因为如果此时Master节点宕机,我们需要人肉的去做故障转移。RocketMQ的主从架构也是这种情况。
4.5之后:引入了Dleger,可以实现一主多从,并且实现自动的故障转移。这就跟Redis后续推出了Sentinel是一样的。Dleger也是类似的作用。
下图是Broker启动代码中的源码。
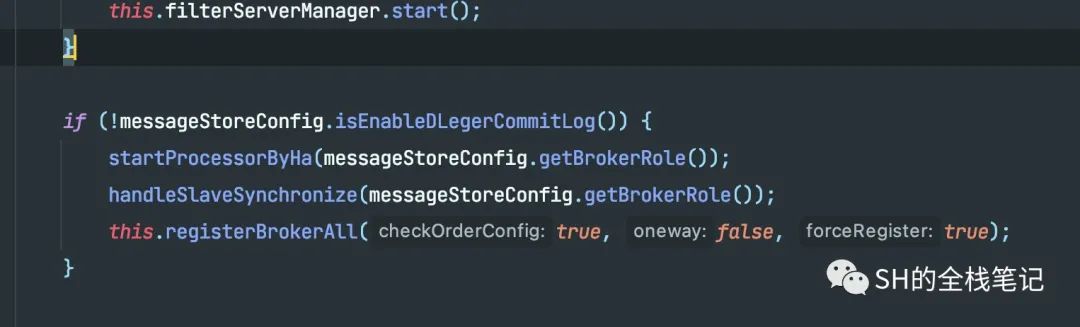
可以看到判断了是否开启了Dleger,默认是不开启的。所以就会执行其中的逻辑。
刚好我们就看到了,里面有Rocket主从同步数据的相关代码。
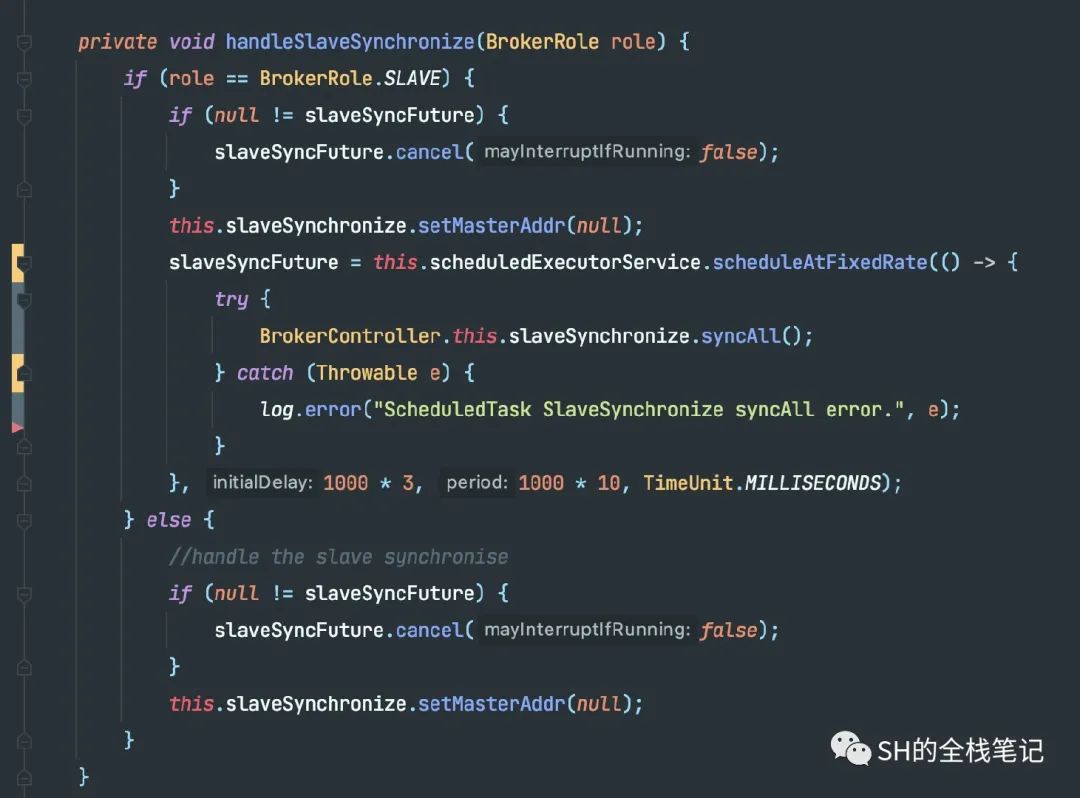
如果当前Broker节点的角色是Slave,则会启动一个周期性的定时任务,定期(也就是10秒)去Master Broker同步全量的数据。同步的数据包括:
Topic的相关配置
Cosumer的消费偏移量
延迟消息的Offset
订阅组的相关数据和配置
注册Broker
完成了主动同步定时任务的启动之后,就会去调用registerBrokerAll去注册Broker。可能这里会有点疑问,我这里是Broker启动,只有当前一个Broker实例,那这个All是什么意思呢?
All是指所有的NameServer,Broker启动的时候会将自己注册到每一个NameServer上去。为什么不只注册到一个NameServer就完事了呢?这样一来还可以提高效率。归根结底还是高可用的问题。
如果Broker只注册到了一台NameServer上,万一这台NameServer挂了呢?这个Broker对所有客户端就都不可见了。实际上Broker还在正常的运行。
进到registerBrokerAll中去。
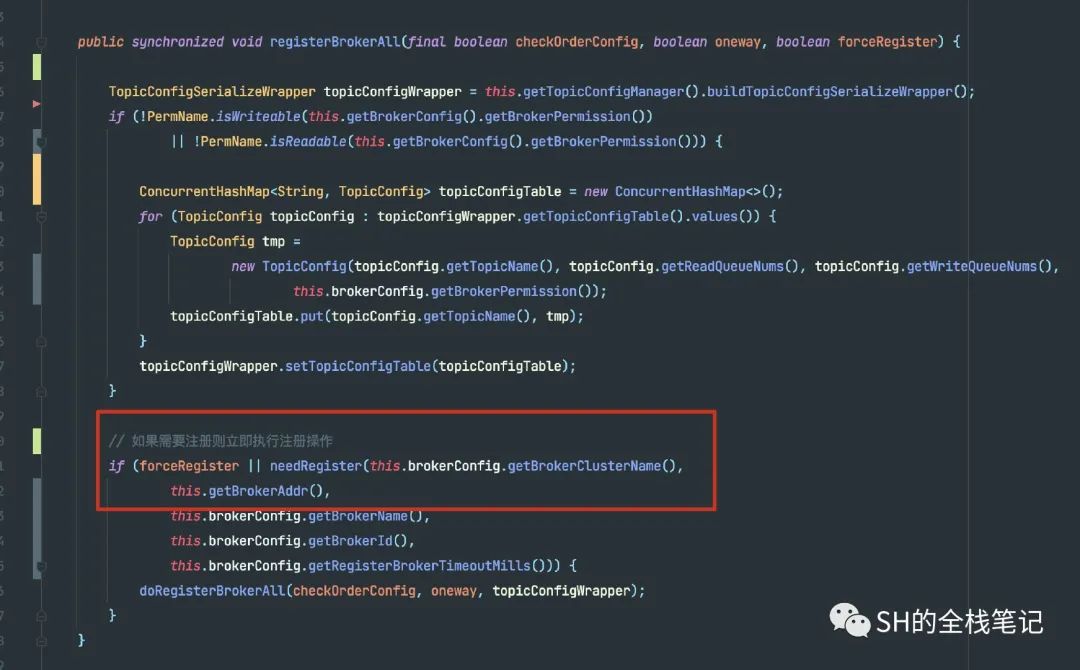
可以看到,这里会判断是否需要进行注册。通过上面的截图可以看到,此时forceRegister的值为true,而是否要注册,决定权就交给了needRegister
为什么需要判断是否需要注册呢?因为Broker一旦注册到了NameServer之后,由于Producer不停的在写入数据,Consumer也在不停的消费数据,Broker也可能因为故障导致某些Topic下的Message Queue等关键的路由信息发生变动。
这样一来,NameServer中的数据和Broker中的数据就会不一致。
如何判断是否需要注册
大致的思路是,Broker会从每一个NameServer中获取到当前Broker的数据,并和当前Broker节点中的数据做对比。但凡有一台NameServer数据和当前Broker不一致,都会进行注册操作。
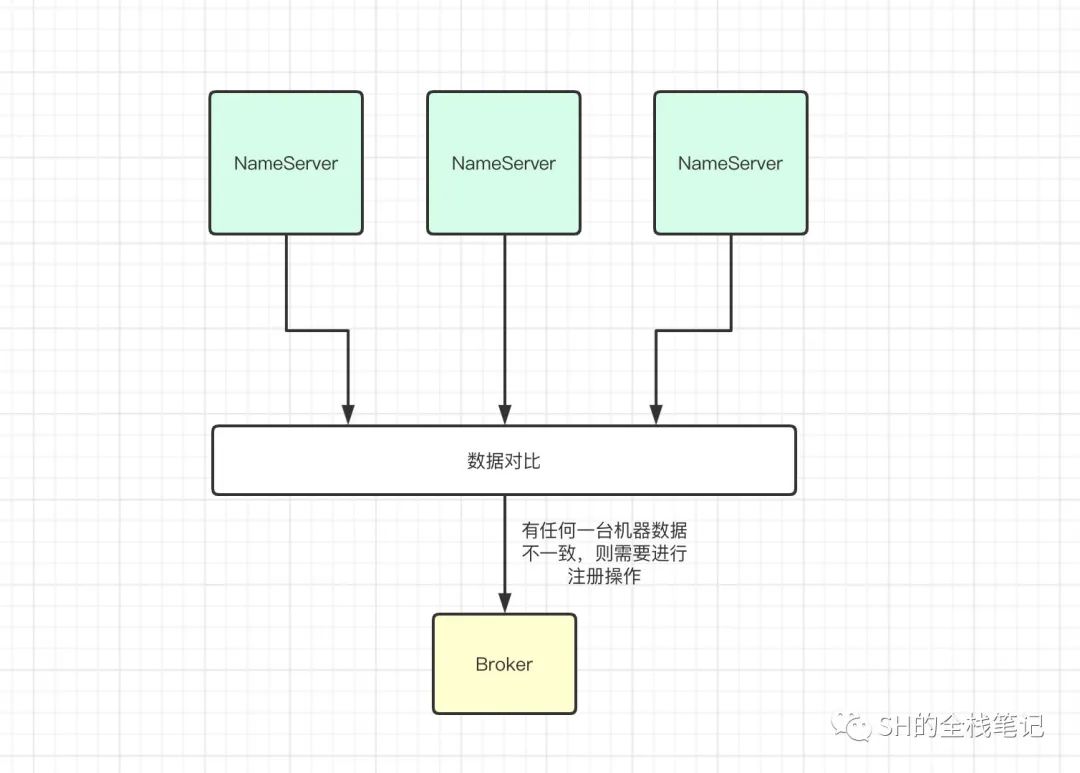
接下来,我们从源码层面验证这个逻辑。关键的逻辑我在图中也标注了出来。
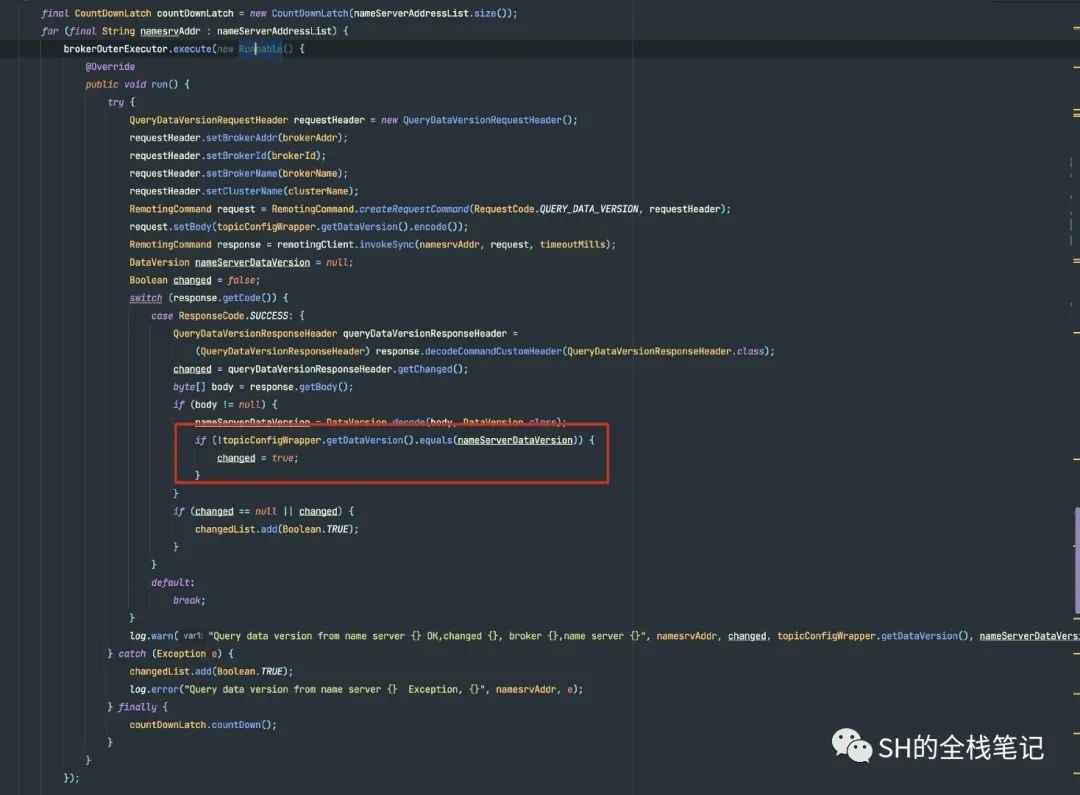
可以看到, 就是通过对比Broker中的数据版本和NameServer中的数据版本来实现的。这个版本,注册的时候会写到注册的数据中存入NameServer中。
这里由于是有多个,所以RocketMQ用线程池来实现了多线程操作,并且用CountDownLatch来等待所有的返回结果。经典的用空间换时间,Golang里面也有类似的操作,那就是sync.waitGroup。
关于任何一个数据不匹配,都会进行重新注册的事实,我们也从源码层面来验证一下。
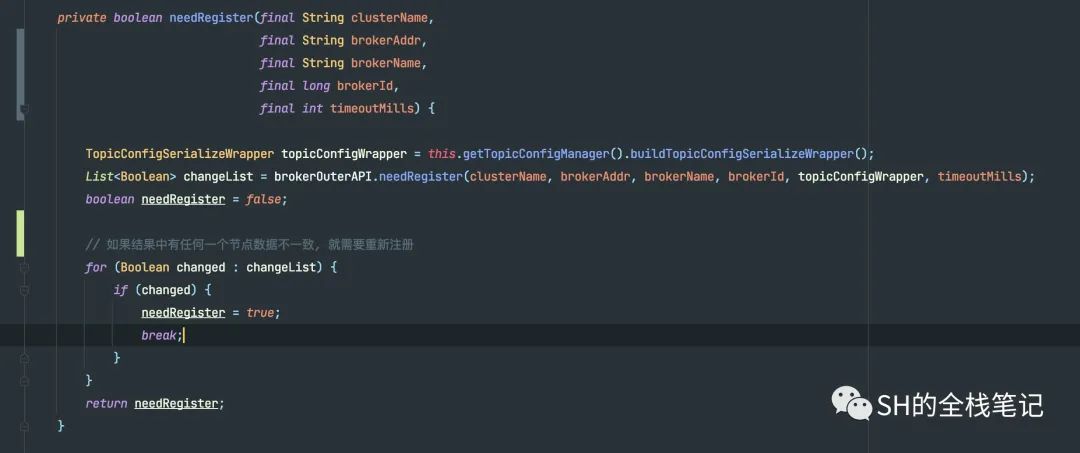
可以看到,如果任何一台NameServer的数据发生了Change,都会break,返回true。
这里的结果列表使用的是CopyOnWriteList来实现的。
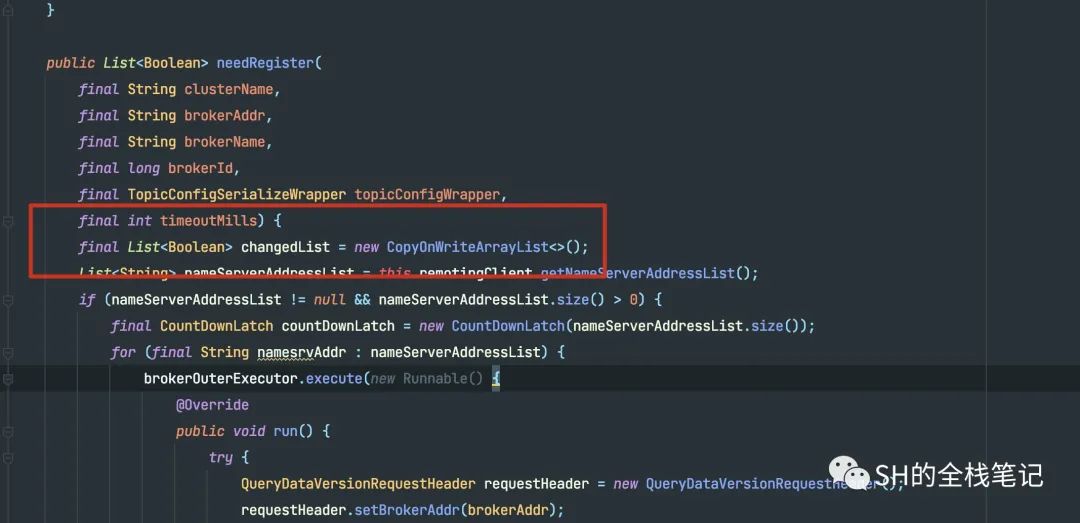
因为这里是多线程去执行的判断逻辑,而正常的列表不是线程安全的。CopyOnWriteArrayList之所以是线程安全的,这归功于COW(Copy On Write),读请求时共用同一个List,涉及到写请求时,会复制出一个List,并在写入数据的时候加入独占锁。比起直接对所有操作加锁,读写锁的形式分离了读、写请求,使其互不影响,只对写请求加锁,降低了加锁的次数、减少了加锁的消耗,提升了整体操作的并发。
执行注册逻辑
这块就是构建数据,然后多线程并发的去发送请求,用CopyOnWriteArrayList来保存结果。不过,上面我们提到过,Broker注册的时候,会把数据版本发送到NameServer并且存储起来,这块我们可以看看发送到NameServer的数据结构。
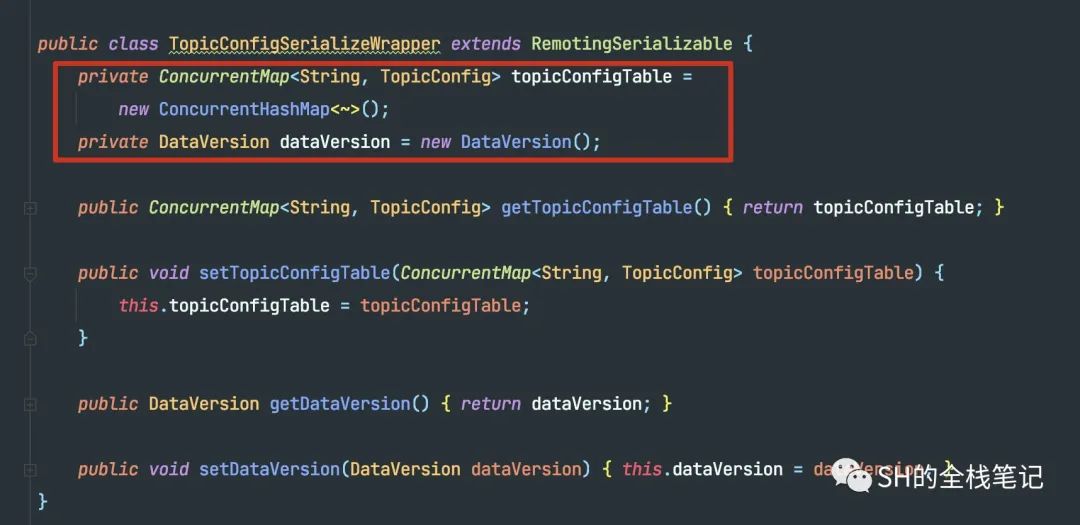
可以看到,Topic的数据分为了两部分,一部分是核心的逻辑,另一部分是DataVersion,也就是我们刚刚一直提到的数据版本。
Broker如何存储数据
刚刚在聊Producer最后提到的是,发送消息到Broker就完了。不知道大家有没有想过Broker是如何存储消息的?
Commit log
先给出流程图
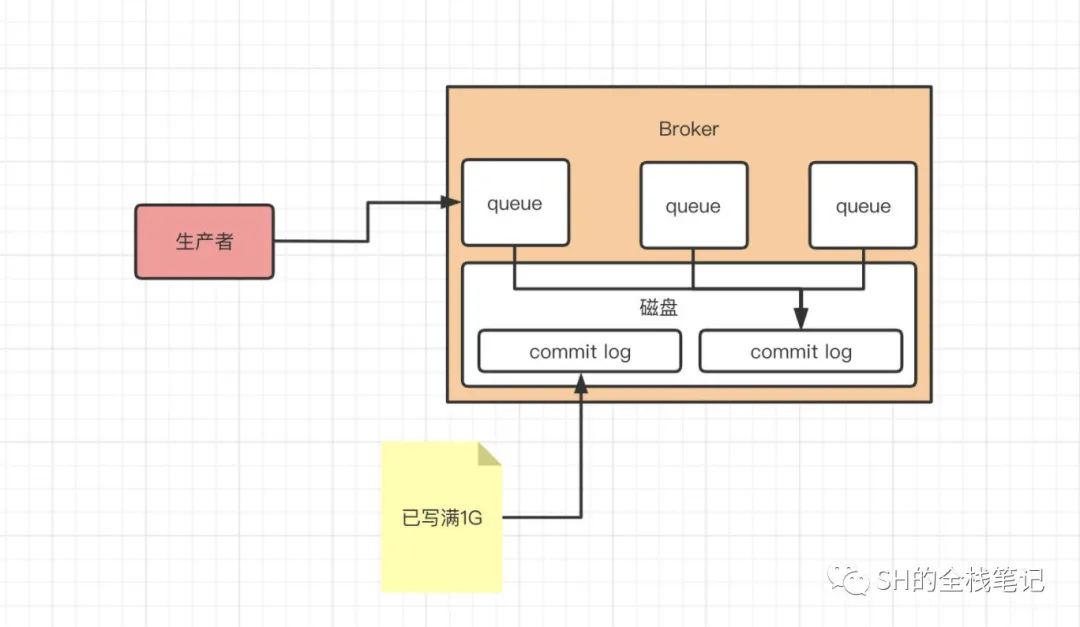
然后给出结论,Producer发送的消息是存储在一种叫commit log的文件中的,Producer端每次写入的消息是不等长的,当该CommitLog文件写入满1G,就会新建另一个新的CommitLog,继续写入。此次采取的是顺序写入。
那么问题来了,Consumer来消费的时候,Broker是如何快速找到对应的消息的呢?我们首先排除遍历文件查找的方法, 因为RocketMQ是以高吞吐、高性能著称的,肯定不可能采取这种对于很慢的操作。那RocketMQ是如何做的呢?
答案是ConsumerQueue
ConsumerQueue
ConsumerQueue是什么?是文件。引入的目的是什么呢?提高消费的性能。
Broker在收到一条消息的时候,写入Commit Log的同时,还会将当前这条消息在commit log中的offset、消息的size和对应的Tag的Hash写入到consumer queue文件中去。
每个MessageQueue都会有对应的ConsumerQueue文件存储在磁盘上,每个ConsumerQueue文件包含了30W条消息,每条消息的size大小为20字节,包含了8字节CommitLog的Offset、4字节的消息长度、8字节的Tag的哈希值。这样一来,每个ConsumerQueue的文件大小就约为5.72M。
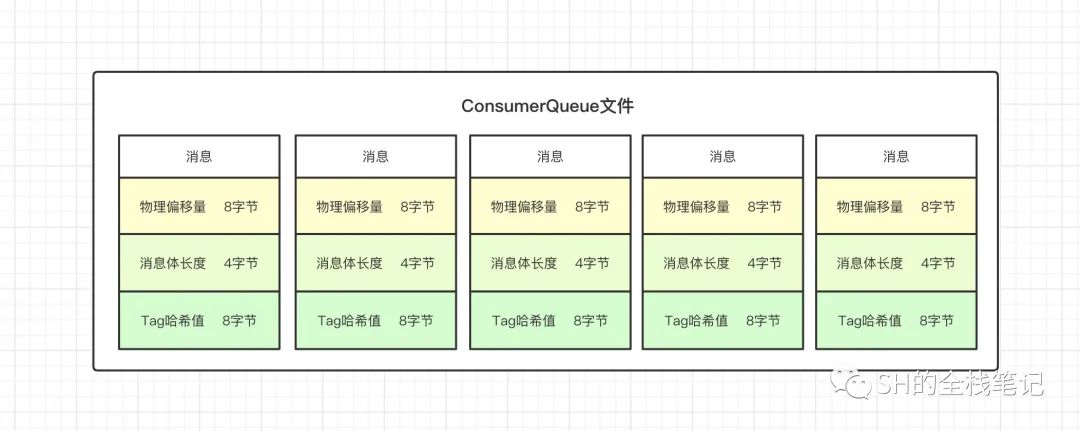
当该ConsumerQueue文件写满了之后,就会再新建一个ConsumerQueue文件,继续写入。
所以,ConsumerQueue文件可以看成是CommitLog文件的索引。
负载均衡
什么意思呢?假设我们总共有6个MessageQueue,然后此时分布在了3台Broker上,每个Broker上包含了两个queue。此时Consumer有3台,我们可以大致的认为每个Consumer负责2个MessageQueue的消费。但是这里有一个原则,那就是一个MessageQueue只能被一台Consumer消费,而一台Consumer可以消费多个MessageQueue。
为什么?道理很简单,RocketMQ支持的顺序消费,是指的分区顺序性,也就是在单个MessageQueue中,消息是具有顺序性的,而如果多台Consumer去消费同一个MessageQueue,就很难去保证顺序消费了。
由于有很多个Consumer在消费多个MessageQueue,所以为了不出现数据倾斜,也为了资源的合理分配利用,在Producer发送消息的时候,需要尽可能的将消息均匀的分发给多个MessageQueue。
同时,上面那种一个Consumer消费了2个MessageQueue的情况,万一这台Consumer挂了呢?这两个MessageQueue不就没人消费了?
以上两种情况分别是Producer端的负载均衡、Consumer端的负载均衡。
Producer端负载均衡
关于Producer端上面的负载均衡,上面的流程图已经给了出来,并且给出了源码的验证。首先是容错策略,会去避开一段时间有问题的Broker,并且加上如果选择了上次的Broker,就会重新进行选择。
Consumer端负载均衡
首先Consumer端的负责均衡可以由两个对象触发:
Broker
Consumer自身
Consumer也会向所有的Broker发送心跳,将消息的消费组名称、订阅关系集合、消息的通信模式和客户端的ID等等。Broker收到了Consumer的心跳之后,会将其存在Broker维护的一个Manager中,名字叫ConsumerManager。当Broker监听到了Consumer数量发生了变动,就会通知Consumer进行Rebalance。
但是如果Broker通知Consumer进行Rebalance的消息丢了呢?这也就是为什么需要第Consumer自身进行触发的原因。Consumer会在启动的时候启动定时任务,周期性的执行rebalance操作。
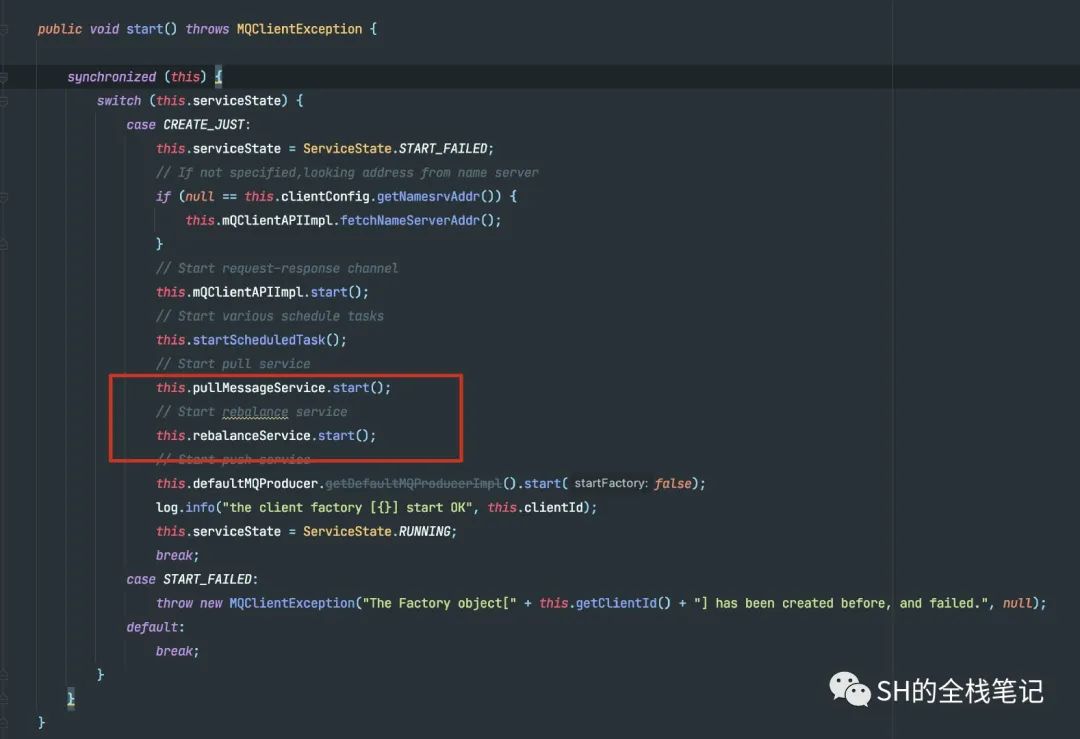
默认是20秒执行一次。具体的代码如下。

具体流程
首先,Consumer的Rebalance会获取到本地缓存的Topic的全部数据,然后向Broker发起请求,拉取该Topic和ConsumerGroup下的所有的消费者信息。此处的Broker数据来源就是Consumer之前的心跳发送过去的数据。然后会对Topic中MessageQueue和消费者ID进行排序,然后用消息队列默认分配算法来进行分配,这里的默认分配策略是平均分配。
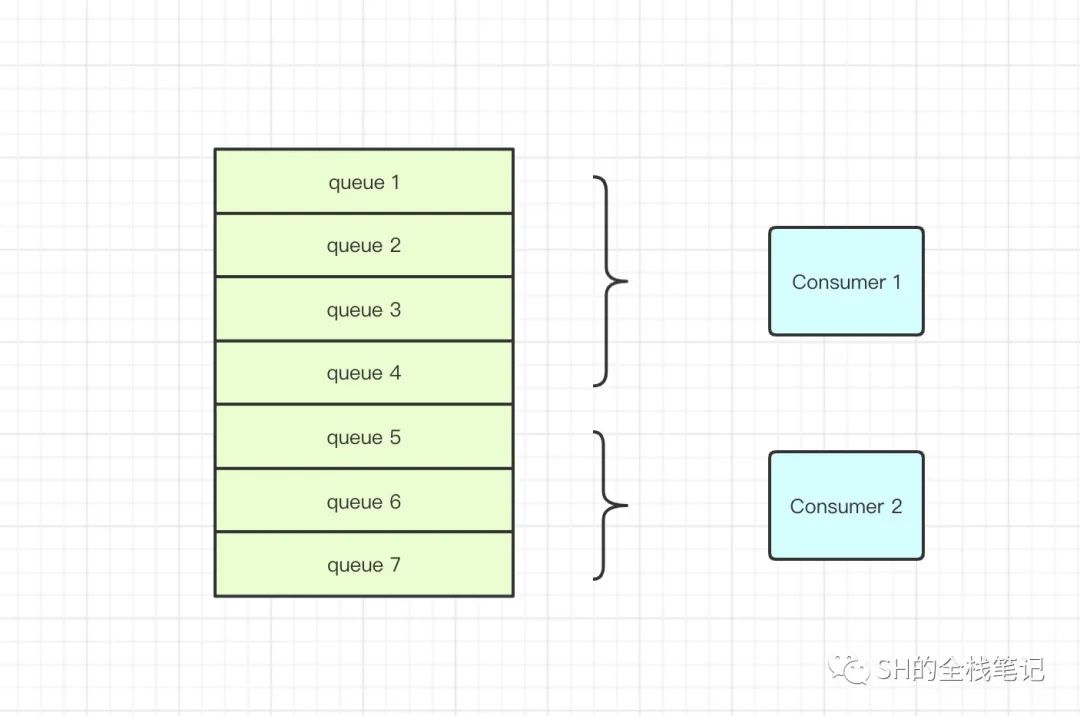
首先会均匀的按照类似分页的思想,将MessageQueue分配给Consumer,如果分配的不均匀,则会依次的将剩下的MessageQueue按照排序的顺序,从上往下的分配。所以在这里Consumer 1被分配到了4个MessageQueue,而Consumer 2被分配到了3个MessageQueue。
Rebalance完了之后,会将结果和Consumer缓存的数据做对比,移除不在ReBalance结果中的MessageQueue,将原本没有的MessageQueue给新增到缓存中。
触发时机
Consumer启动时 启动之后会立马进行Rebalance
Consumer运行中 运行中会监听Broker发送过来的Rebalance消息,以及Consumer自身的定时任务触发的Rebalance
Consumer停止运行 停止时没有直接的调用Rebalance,而是会通知Broker自己下线了,然后Broker会通知其余的Consumer进行Rebalance。
换一个角度来分析,其实就是两个方面,一个是队列信息发生了变化,另一种是消费者发生了变化。
源码验证
然后给出核心的代码验证,获取数据的逻辑如下

验证了我们刚刚说的获取了本地的Topic数据缓存,和从Broker端拉取所有的ConsumerID。
接下来是验证刚说的排序逻辑。
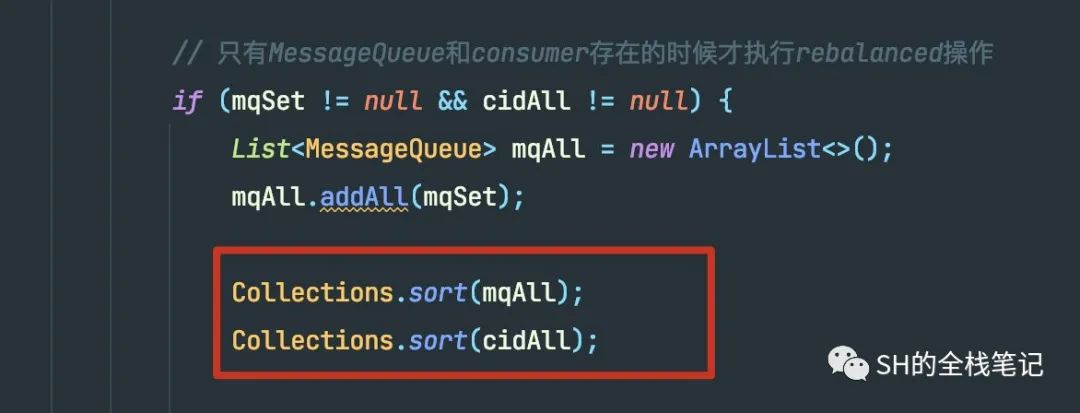
接下来是看判断结果是否发生了变化的源码。
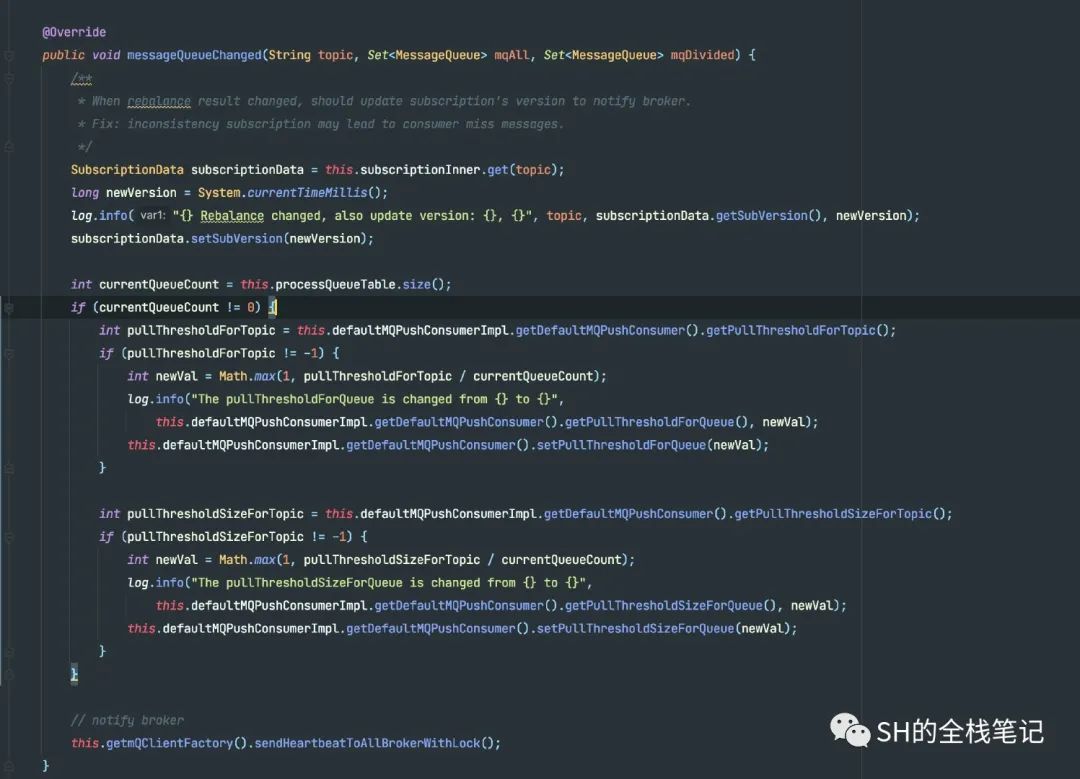
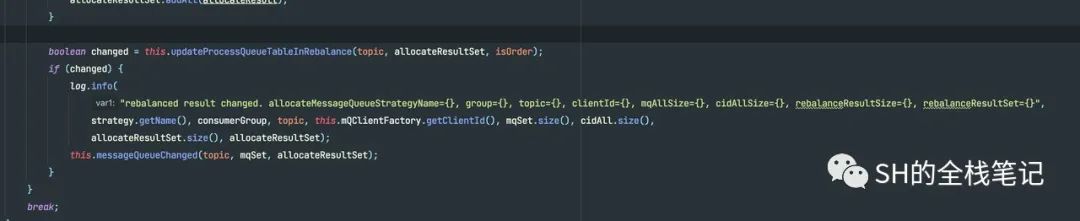
可以看到,Consumer通知Broker策略,其本质上就是发送心跳,将更新后的数据通过心跳发送给所有的Broker。
Consumer更多的细节
可能关于Consumer,我们使用的更多一点。例如我们知道我们可以设置集群消费和广播消息,分别对应RocketMQ中的CLUSTERING和BROADCASTING**。
再比如我们知道,我们可以设置顺序消费和并发消费等等,接下来就让我们用源码来看看这些功能在RocketMQ中是怎么实现的。
消费模型
在Consumer中,默认都是采用集群消费,这块在Consumer的代码中也有体现。
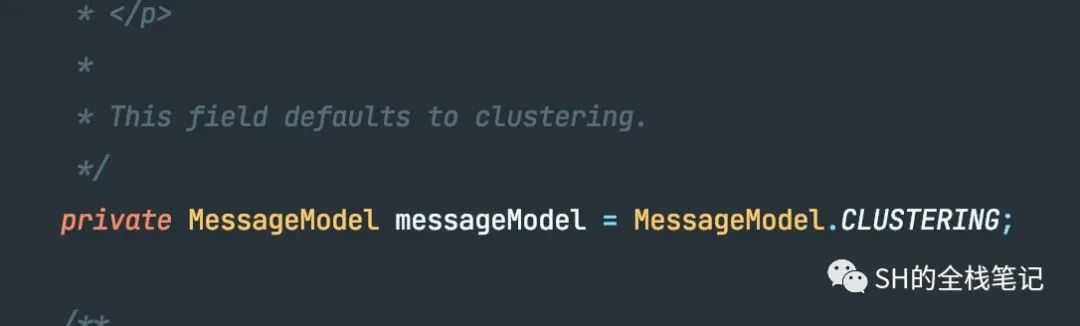
而消费模式的不同,会影响到管理offset的具体实现。
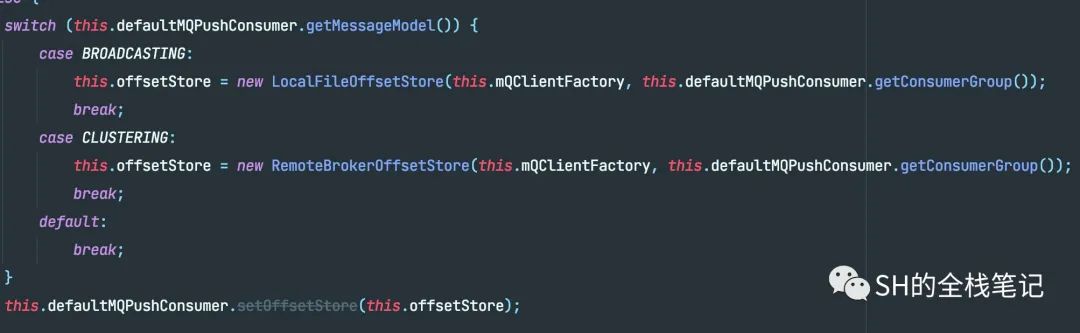
可以看到,当消费模型是广播模式时,Offset的持久化管理会使用实现LocalFileOffsetStorage
当消费模式是集群消费时,则会使用RemoteBrokerOffsetStore。
具体原因是什么呢?首先我们得知道广播模式和集群模式的区别在哪儿:
广播模式下,一条消息会被ConsumerGroup中的每一台机器所消费
集群模式下,一条消息只会被ConsumerGroup中的一台机器消费
所以在广播模式下,每个ConsumerGroup的消费进度都不一样,所以需要由Consumer自身来管理Offset。而集群模式下,同个ConsumerGroup下的消费进度其实是一样的,所以可以交由Broker统一管理。
消费模式
消费模式则分为顺序消费和并发消费,分别对应实现MessageListenerOrderly和MessageListenerConcurrently两种方式。
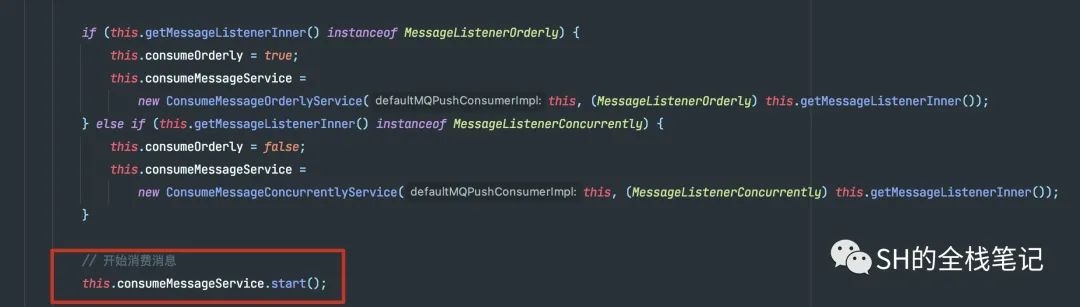
不同的消费方式会采取不同的底层实现,配置完成之后就会调用start。
拉取消息
接下来我们来看一个跟我们最最相关的问题,那就是我们平时消费的消息到底是怎么样从Broker发到的Consumer。在靠近启动Rebalance的地方,Consumer也开启了一个定时拉取消息的线程。
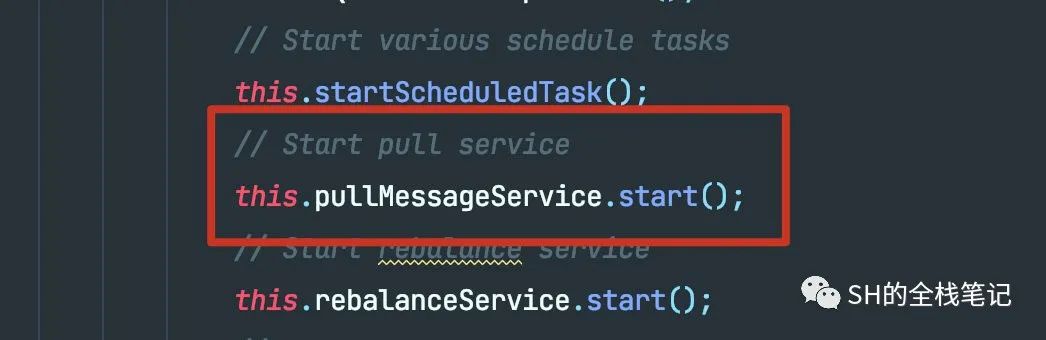
这个线程做了什么事呢?它会不停的从一个维护在内存中的Queue中获取一个在写入的时候就构建好的PullRequest对象,调用具体实现去不停的拉取消息了。
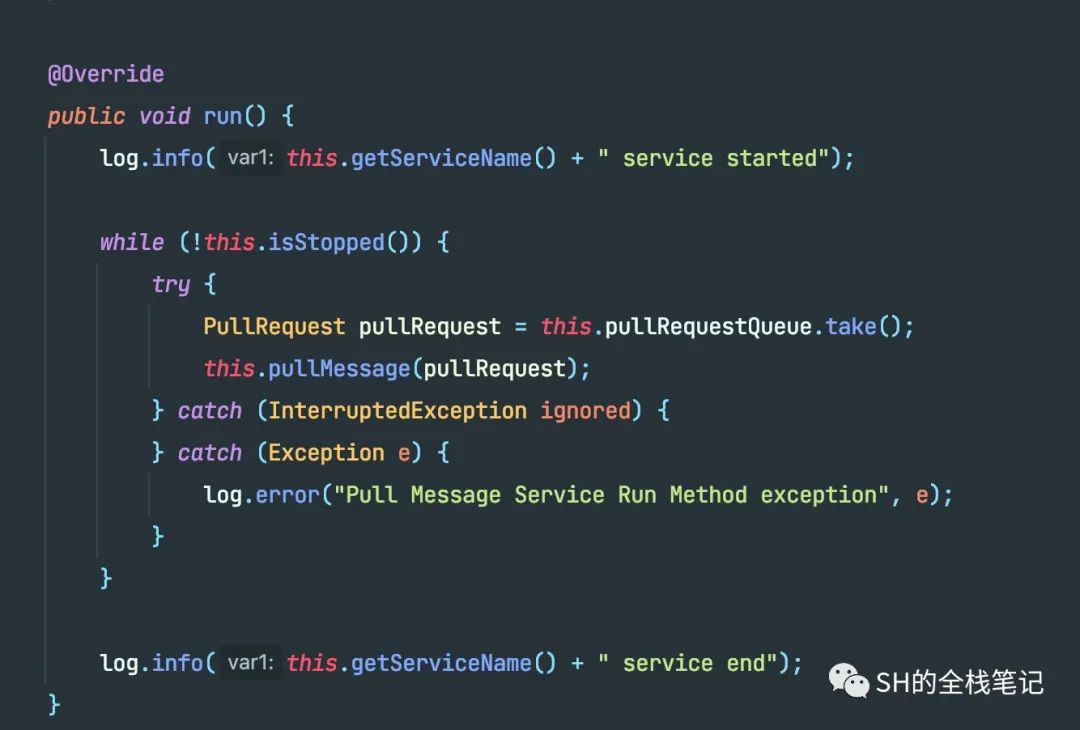
处理消费结果
在这里是否开启AutoCommit,所做的处理差不了很多,大家也都知道,唯一区别就在于是否自动的提交Offset。对于处理成功的逻辑也差不多,我们平时业务逻辑中可能也并不关心消费成功的消息。我们更多关注的是如果消费失败了,RocketMQ是怎么处理的?
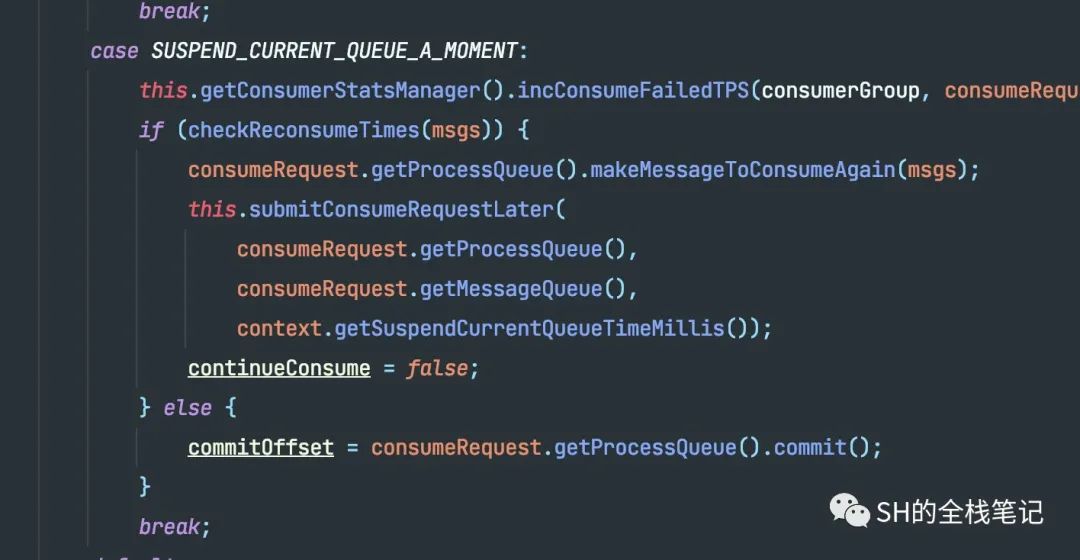
这是在AutoCommit下,如果消费失败了的处理逻辑。会记录一个失败的TPS,然后这里有一个非常关键的逻辑,那就是checkReconsumeTimes。
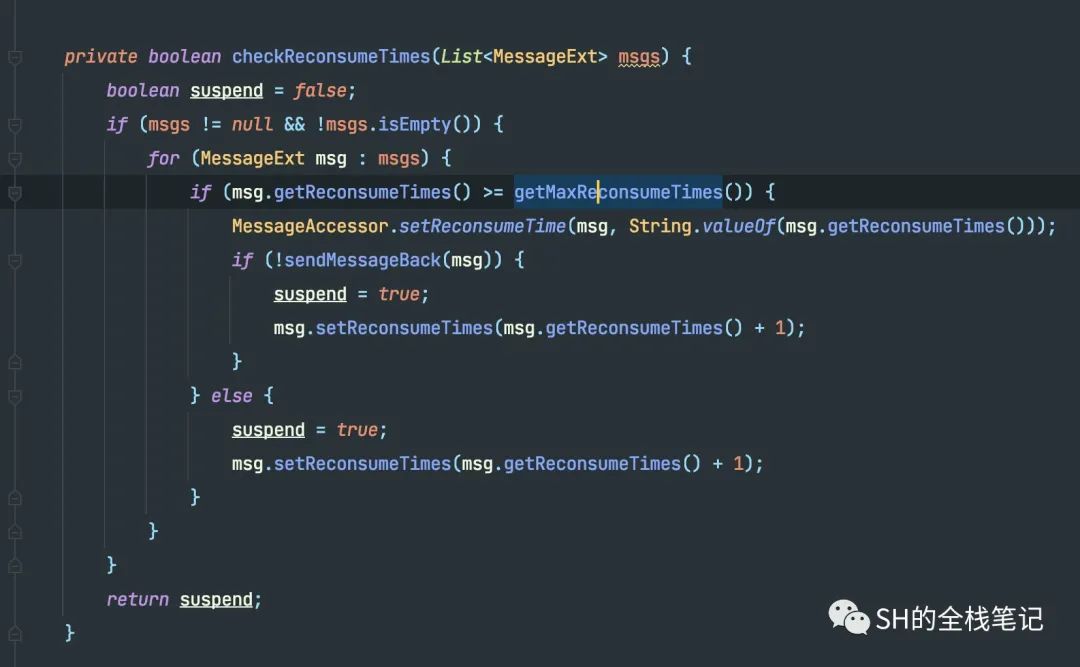
如果当前消息的重试次数,如果大于了最大的重试消费次数,就会把消费发回给Broker。那最大重试次数是如何定义的。

如果值为-1,那么最大次数就是MAX_VALUE,也就是2147483647。这里有点奇怪啊,按照我们平常的认知,难道不是重试16次吗?然后就看到了很骚的一句注释。
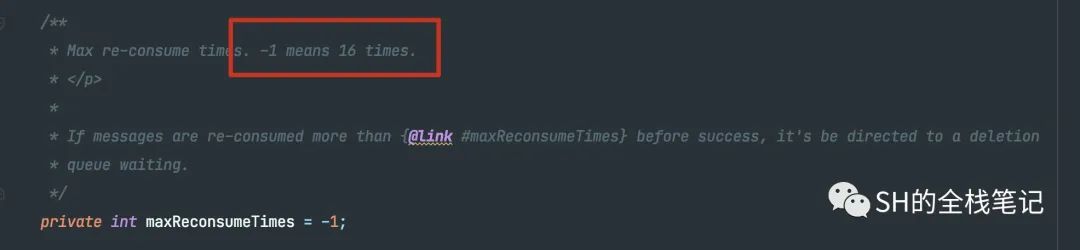
-1 means 16 times,这代码确实有点,一言难尽。
然后,如果超过了最大的次数限制,就会将该消息调用Prodcuer的默认实现,将其发送到死信队列中。当然,死信队列也不是什么特殊的存在,就是一个单独的Topic而已。
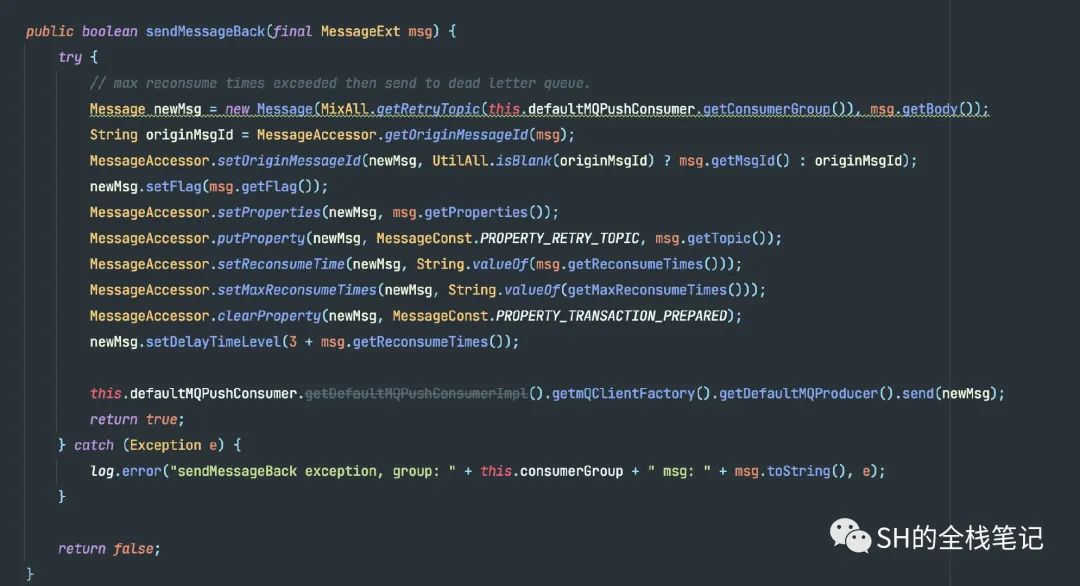
通过getRetryTopic来获取的,默认是给当前的ConsumerGroup名称加上一个前缀。
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号

好文章,我在看❤️
以上是关于RocketMQ基础概念剖析&源码解析的主要内容,如果未能解决你的问题,请参考以下文章
RocketMQ基础概念剖析,并分析一下Producer的底层源码
深度挖掘RocketMQ底层源码「底层源码挖掘系列」透彻剖析贯穿RocketMQ的消费者端的运行核心的流程(上篇)
精华推荐 | 深入浅出 RocketMQ原理及实战「底层源码挖掘系列」透彻剖析贯穿RocketMQ的消费者端的运行核心的流程(上篇)
深度挖掘 RocketMQ底层源码「底层源码挖掘系列」透彻剖析贯穿RocketMQ的消费者端的运行核心的流程(Pull模式-下)