如何用机器学习识别猫叫和狗叫声?
Posted 华为移动服务
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何用机器学习识别猫叫和狗叫声?相关的知识,希望对你有一定的参考价值。
在一些应用项目开发的过程中,有时需要用到语音检测的功能,即识别敲门声、门铃声、汽车喇叭声等功能,对于中小开发者来说,单独开发构建该能力,不免耗时耗力,而华为机器学习服务中的声音识别服务SDK,只需简单集成,端侧就能实现这个功能。
华为机器学习服务声音识别能力
声音识别服务支持通过在线(实时录音)的模式检测声音事件,基于检测到的声音事件能够帮助开发者进行后续指令动作。目前支持13个种类的声音事件,包括:笑声、婴儿或小孩哭声、打鼾声、喷嚏声、叫喊声、猫叫声、狗叫声、流水声(包括水龙头流水声、溪流声、海浪声)、汽车喇叭声、门铃声、敲门声、火灾报警声(包括火灾报警器警报声、烟雾报警器警报声)、警报声(包括消防车警报声、救护车警报声、警车警报声、防空警报声)。
集成准备
开发环境配置
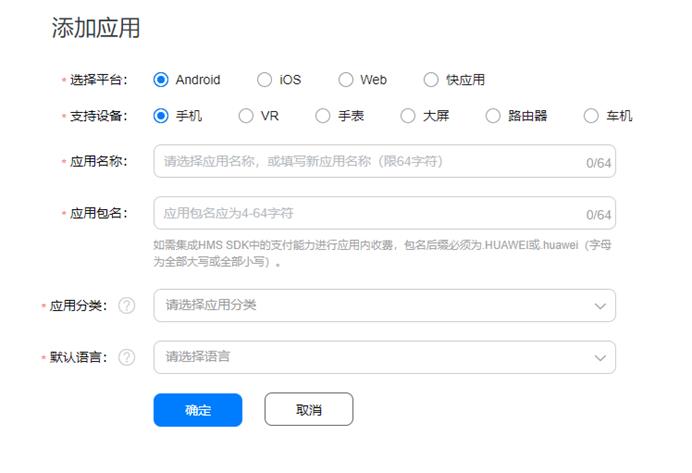
1、需要在华为开发者联盟上创建应用:
2、打开机器学习服务:
具体开启步骤可以查看此链接:https://developer.huawei.com/consumer/cn/doc/development/HMSCore-Guides-V5/enable-service-0000001050038078-V5?ha__source=hms1
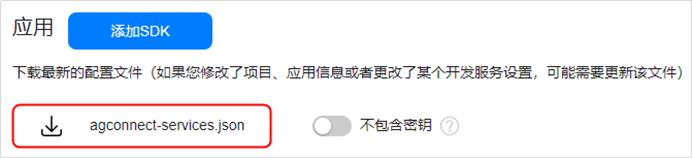
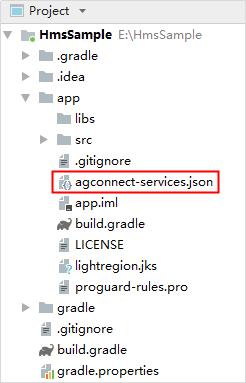
2、创建完应用之后,会自动生成agconnect-services.json文件, 需要手动将agconnect-services.json文件拷贝到应用级根目录下
3、配置HMS Core SDK的Maven仓地址。
关于Maven仓的配置可以查看此链接:https://developer.huawei.com/consumer/cn/doc/development/HMSCore-Guides/config-maven-0000001050040031?ha__source=hms1
4、集成声音识别服务SDK
- 推荐使用Full SDK方式集成,在build.gradle文件中配置相应的sdk
// 引入声音识别集合包
implementation 'com.huawei.hms:ml-speech-semantics-sounddect-sdk:2.1.0.300'
implementation 'com.huawei.hms:ml-speech-semantics-sounddect-model:2.1.0.300'- 根据实际情况声明AGC插件配置,有两种方式
apply plugin: 'com.android.application'
apply plugin: 'com.huawei.agconnect'或
plugins {
id 'com.android.application'
id 'com.huawei.agconnect'
}3. 自动更新机器学习模型
添加如下语句到AndroidManifest.xml文件中,用户从华为应用市场安装您的应用后,将自动更新机器学习模型到设备:
<meta-data
android:name="com.huawei.hms.ml.DEPENDENCY"
android:value= "sounddect"/>应用开发编码阶段
1.取得 麦克风 权限, 如果没有麦克风的权限 会报12203的错误
设置静态权限(必须)
<uses-permission android:name="android.permission.RECORD_AUDIO" />动态权限获取(必须)
ActivityCompat.requestPermissions(
this, new String[]{Manifest.permission.RECORD_AUDIO
}, 1);2.创建MLSoundDector对象
private static final String TAG = "MLSoundDectorDemo";
//语音识别的对象
private MLSoundDector mlSoundDector;
//创建MLSoundDector对象 并 设置回调方法
private void initMLSoundDector(){
mlSoundDector = MLSoundDector.createSoundDector();
mlSoundDector.setSoundDectListener(listener);
}3. 声音识别结果回调,用于获取检测结果,并将回调传入声音识别实例。
//创建声音识别结果回调,用于获取检测结果,并将回调传入声音识别实例。
private MLSoundDectListener listener = new MLSoundDectListener() {
@Override
public void onSoundSuccessResult(Bundle result) {
//识别成功的处理逻辑,识别结果为:0-12(对应MLSoundDectConstants.java中定义的以SOUND_EVENT_TYPE开头命名的13种声音类型)。
int soundType = result.getInt(MLSoundDector.RESULTS_RECOGNIZED);
Log.d(TAG,"声音识别成功:"+soundType);
}
@Override
public void onSoundFailResult(int errCode) {
//识别失败,可能没有授予麦克风权限(Manifest.permission.RECORD_AUDIO)等异常情况。
Log.d(TAG,"声音识别失败:"+errCode);
}
};此代码中只是将声音识别结果的int类型打印了出来,实际编码中,可以将int类型的声音识别结果 转换为 可被用户识别的类型。
声音识别类型的定义:
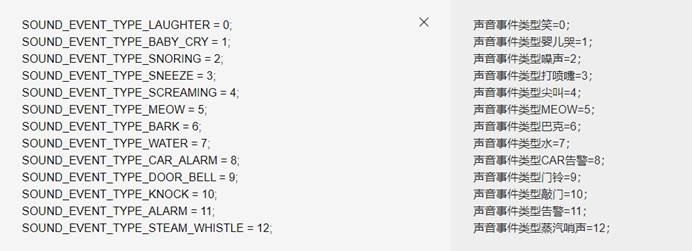
<string-array name="sound_dect_voice_type">
<item>笑声</item>
<item>婴儿或小孩哭声</item>
<item>打鼾声</item>
<item>喷嚏声</item>
<item>叫喊声</item>
<item>猫叫声</item>
<item>狗叫声</item>
<item>流水声</item>
<item>汽车喇叭声</item>
<item>门铃声</item>
<item>敲门声</item>
<item>火灾报警声</item>
<item>警报声</item>
</string-array>3. 开启和关闭语音识别
@Override
public void onClick(View v) {
switch (v.getId()){
case R.id.btn_start_detect:
if (mlSoundDector != null){
boolean isStarted = mlSoundDector.start(this); //context 是上下文
//isStared 等于true表示启动识别成功、isStared等于false表示启动识别失败(原因可能是手机麦克风被系统或其它三方应用占用)
if (isStarted){
Toast.makeText(this,"语音识别开启成功", Toast.LENGTH_SHORT).show();
}
}
break;
case R.id.btn_stop_detect:
if (mlSoundDector != null){
mlSoundDector.stop();
}
break;
}
}4.当页面关闭的时候,可以调用destroy()方法释放资源
@Override
protected void onDestroy() {
super.onDestroy();
if (mlSoundDector != null){
mlSoundDector.destroy();
}
}运行测试
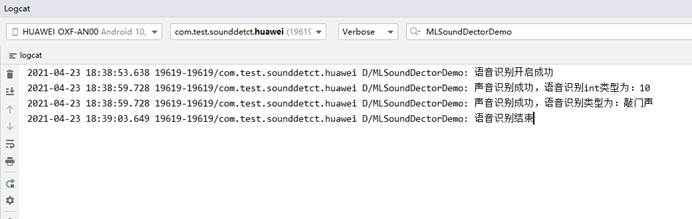
1. 以敲门声为例,预计声音识别类型的输出结果为10
2. 点击开启语音识别按钮、模拟敲门声 ,在AS控制台中可以得到如下日志, 说明集成成功。
其他
1. 声音识别服务属于华为机器学习服务中的一个很小的模块,华为机器学习服务包括6大模块,分别为:文本类、语音语言类、图像类、人脸人体类、自然语言处理类,自定义模型 。
2. 这篇记录文档只是介绍了“语音语言类”这个模块中的“声音识别服务”
3. 如果有读者对华为机器学习服务其他模块感兴趣的话,可以查看华为提供的相关集成文档
>>访问华为机器学习服务官网,了解更多相关内容
>>获取华为机器学习服务开发指导文档
>>华为HMS Core官方论坛
>>华为机器学习服务开源仓库地址:GitHub、Gitee
点击右上角头像右方的关注,第一时间了解华为移动服务最新技术~
以上是关于如何用机器学习识别猫叫和狗叫声?的主要内容,如果未能解决你的问题,请参考以下文章