什么限制了 Redis Cluster 的集群规模
Posted 李木子啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么限制了 Redis Cluster 的集群规模相关的知识,希望对你有一定的参考价值。
前言
很早以前,木子年轻气盛,跟同学飙自行车,结果由于速度过快,得意忘形,直接磕到了马路牙子上,当场右臂骨折。结果第二天,从小学到中学再到大学,一大堆狐朋狗友前赴后继,纷纷前来瞻仰一番他们从没见过的石膏板。看到他们一个个都学会了用笑容来掩饰内心的悲伤,我感到很是欣慰,感动的哭了起来。
血淋淋的教训告诉我们:不要飙车!即使是自行车!

后来经过证实:是同我一起飙车的那个告诉了我们共同的朋友,然后朋友又告诉了朋友的朋友,就这样一传十、十传百,大家都知道了。
大家不妨想一想,是什么起了关键作用,让我受伤了这件事传播得这么快。大家可以再想一想,在 250 万年前,我们人类第一个祖先学会制作工具打猎之后,是依靠什么力量,让制作工具的方式迅速传播,从而推动人类社会的巨大进步,发展到现代社会的?
想必大家都很确定,但又很不情愿的想到,其实这一切都可以归功于两个字--“八卦”。正如《人类简史》中提到的一样,“认知革命”和人类会八卦、虚构故事息息相关,毫不夸张的说,八卦使人类进步。虽然有时候我们痛恨八卦,因为它很多时候传播的都是负面信息,但是不得不承认的是,“八卦”正是能够区分人与其他生物的重要依据。

Gossip 翻译成中文就是流言蜚语或者八卦的意思,在计算机世界,Gossip 协议也是一种基于八卦的协议,它能够使多个节点在相互通信的过程中,最终形成“共同的认知”,从而达到一致的状态。Redis cluster 模式正是通过这种协议来实现节点间信息同步的。
接下来就让我们走进 Redis Cluster 的世界,具体聊一聊 Gossip 协议是如何工作的,以及是什么制约了 Redis 集群模式的规模。

Gossip 协议
Gossip 协议的消息传播方式有两种,分别是反熵和谣言传播。
反熵(Anti Entropy)是指周期性地随机选择其他节点,然后通过互相交换自己的所有数据,来消除彼此之间的差异。反熵的优点很明显,每次比较全量数据,能够尽可能副本之间数据的一致。但是缺点也很明显,每次消息传递都会携带本节点副本的全量数据,如果发生得很频繁,势必会带来很大的通信开销,尤其是当集群中节点数比较多的时候,产生的影响将会更明显。因此,反熵的发生频率一般不会很高。
除了反熵,Gossip 协议还提出了另外一种手段,叫谣言传播(Rumor Mongering)。谣言传播指的是当一个节点有新的数据的时候,每次只会向其他节点同步自己的新数据。这种方式很有效的减轻了集群的通信压力,因为传输的包体积减少了,但是缺点也是有的,由于不是全量,还是有可能会存在数据不一致的情况。
上述的两种消息传播方式都涉及到节点间数据交换,Gossip 协议的数据交换有以下几种方式:
•push(推,我有个小八卦要告诉你):将自己的副本数据推给对方,让对方修复自己的数据;•pull(拉,你有啥八卦快点告诉我):拉取对方的副本数据,修复自己的数据;•push / pull(推拉,我们来交换八卦吧):在向对方发送消息的同时拉取对方的消息,从而可以同时修复自己和对方的数据。
这三种方式类比到我们现实生活中,仔细琢磨琢磨,嗯,确实有那味了。

Redis Cluster 中的 Gossip 实现
接下来我们以最新的 redis 6.2.4 版本为准,来讲解一下 redis 中 gossip 协议的实现。
我们不妨先来看一下一个 gossip 消息的结构,它们被定义在 cluster.h 头文件里面:
typedef struct {
char nodename[CLUSTER_NAMELEN]; // 节点名称,40 字节
uint32_t ping_sent; // 4 字节,最后一次向该节点发送 ping 消息的时间戳
uint32_t pong_received; // 4 字节,最后一次接收该节点 pong 的时间戳
char ip[NET_IP_STR_LEN]; // 46 字节,节点 ip
uint16_t port; // 2 字节,节点端口号
uint16_t cport; // 2 字节,集群端口
uint16_t flags; // 2 字节,继承自 node.flags
uint16_t pport; // 2 字节,较老的版本没有这个字段
uint16_t notused1; // 2 字节,较老版本这个字段的类型是 uint32_t
} clusterMsgDataGossip;
可以看到,每个 gossip 消息体的大小是 104 字节。而每个节点在发送一次 ping 消息的时候,还会额外携带自己维护的集群中 10% 的节点信息,此外每个 ping 消息中还会携带一个长度为 16384 的 BitMap,BitMap 中的每一位都对应一个 hash 槽(slot),如果当前位为 1,则代表这个槽落在了当前节点上面。
这么描述可能有点抽象,不妨我们举个例子:假设我们集群中一共有 1000 个节点,每次 ping 消息会发送 10% 也就是 100 个节点的信息,那么消息体总大小为 104 * 100 = 10400 字节约为 10KB,再加上 BitMap 16384 位,也就是 2KB,那么一次 ping 消息体的大小就是 12KB。有 ping 消息,就会有相应的 pong 响应,每次 pong 的消息跟 ping 是类似的,因此大小也是 12 KB,这样的话,一来一回就是 24KB,妥妥的 2.5 个 string 类型的大 key 了呀。

接下来我们来看一下选取要发送消息的目标节点的具体方法。发送 gossip 消息(ping)的逻辑在 cluster.c 的 clusterCron 方法中,从命名以及注释上就可以看出来这是一个定时方法,它会每秒钟执行十次:
/* This is executed 10 times every second */
void clusterCron(void) {}
这个方法体很长,在这个版本中有 260 行之多,主要处理节点间相互通信以及状态变更、节点建连/断连等问题。
所以为什么要强调是每秒钟执行十次而不是每 100 毫秒执行一次呢?相信大家看到这里的注释都会觉得莫名其妙吧。但其实内部另有玄机,答案就在下述代码:
void clusterCron(void) {
/* 省略若干代码 */
iteration++; /* Number of times this function was called so far. */
/* 省略若干代码 */
/* Ping some random node 1 time every 10 iterations, so that we usually ping
* one random node every second. */
if (!(iteration % 10)) {
int j;
/* Check a few random nodes and ping the one with the oldest
* pong_received time. */
for (j = 0; j < 5; j++) {
de = dictGetRandomKey(server.cluster->nodes);
clusterNode *this = dictGetVal(de);
/* Don't ping nodes disconnected or with a ping currently active. */
if (this->link == NULL || this->ping_sent != 0) continue;
if (this->flags & (CLUSTER_NODE_MYSELF|CLUSTER_NODE_HANDSHAKE))
continue;
if (min_pong_node == NULL || min_pong > this->pong_received) {
min_pong_node = this;
min_pong = this->pong_received;
}
}
if (min_pong_node) {
serverLog(LL_DEBUG,"Pinging node %.40s", min_pong_node->name);
clusterSendPing(min_pong_node->link, CLUSTERMSG_TYPE_PING);
}
}
/* 省略若干代码 */
}
通过一个全局变量的巧妙设计,redis 在每 100 毫秒的定时任务中实现了一个每秒的定时任务。redis cluster 节点每秒都会从本地维护的实例列表里面随机选择五个节点,然后从这五个节点中选择一个最久没有被自己 ping 过的实例,发送 ping 消息给它。

然而这种随机性能够提高选择的效率,但是同时也带来了一个问题:它不能保证选中的节点是集群中最久没有收到 ping 消息的实例,很有可能会出现节点长时间一直收不到消息,导致它本身维护的状态早就过期了。那么有没有什么办法解决这个问题呢?这正是每 100 ms 要解决的问题之一。redis 节点每 100ms 都会遍历一次实例列表,当发现某个节点当前时间与最近收到本节点的 pong 消息时间的差值大于 cluster_node_timeout(可以认为是集群节点不可达的最大的超时时间)的一半并且当前循环还没有发过 ping 消息的时候,它便会立刻向当前节点发起 ping 。代码如下所示:
while((de = dictNext(di)) != NULL) {
/* 省略若干代码 */
/* If we have currently no active ping in this instance, and the
* received PONG is older than half the cluster timeout, send
* a new ping now, to ensure all the nodes are pinged without
* a too big delay. */
if (node->link &&
node->ping_sent == 0 &&
(now - node->pong_received) > server.cluster_node_timeout/2)
{
clusterSendPing(node->link, CLUSTERMSG_TYPE_PING);
continue;
}
/* 省略若干代码 */
}
从这里我们可以发现,当 cluster_node_timeout(默认值 15s)的值越小的时候,触发 ping 的概率就会越大,并且随着集群规模的增大,这个概率会变得更大,极端情况就是每 100ms 都会产生一次 ping 行为。因此为了减少节点通信产生的开销,我们可以自己来调整 cluster-node-timeout 配置项。
但是增大 cluster-node-timeout 的值就万事大吉了吗?我们要知道,有时候实例故障长时间不能被发现要比节点通信的网络开销的影响要大的多,cluster-node-timeout 的值越大就意味着节点间通信的频率越低,节点状态变更被同步到整个集群所需要的时间就越多,这个状态不一致的时间还会随着集群节点的增多而变大。所以在这里我们可以发现一个矛盾点:集群规模越大,节点通信开销越大,并且节点间状态不一致的存留时间也会越大。
•如果想要减少通信开销,那么就需要调大 cluster-node-timeout 的值,这个时候状态不一致的时间便会被进一步放大;•如果想要减少状态不一致的时间,那么就需要调小 cluster-node-timeout 的值,那么通信开销便会被放大。

因此在生产环境中,我们需要根据实际情况不停地尝试,来选取一个两者都能接受的值。
Redis Cluster 的替代方案
Redis Cluster 不适合超大规模集群主要是因为他采用了去中心化的设计,导致每个节点都需要维护所有节点的状态,节点间通信开销会随着节点规模而幂增长(x^2)。其实换一种思路,将去中心化的设置转换成中心化的架构可以很好地解决这个问题。
我们可以以一个五节点集群为例,分别来看一下中心化和去中心化设计的网络拓扑图:
1.去中心化架构
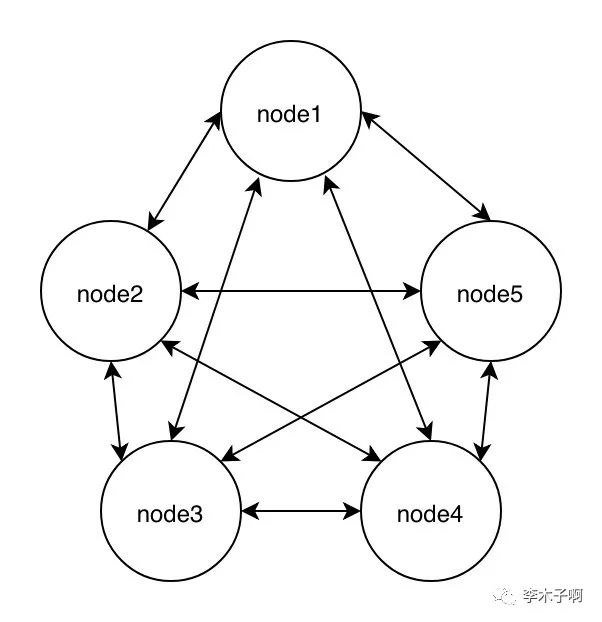
集群中每两个节点之间都需要互相同步状态,网络连接数是 n * (n - 1),在这里 n 的值是 5。
1.中心化架构
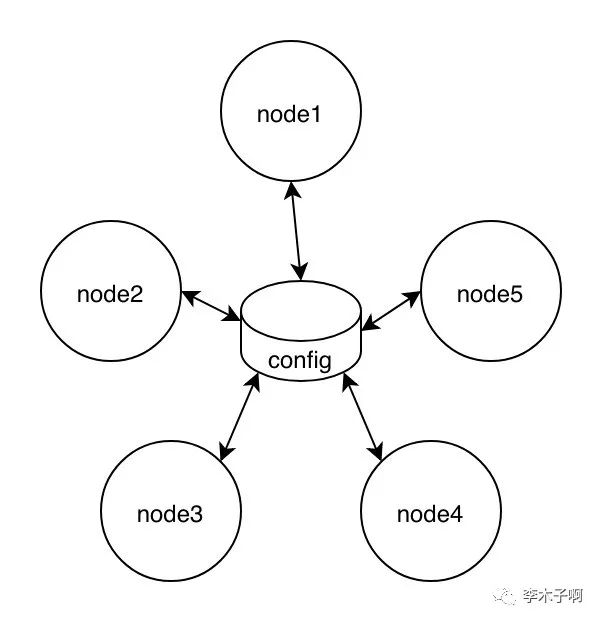
集群中每个节点都要跟 master 节点互相同步状态,网络连接数是 (n - 1) * 2,在这里 n 的值是 5。
可以看到随着节点数量的增加,去中心化设计的方案使得每个节点需要维护的其他节点状态以及产生的节点间通信开销将会成幂增长的趋势。这正是 Redis Cluster 所采用的架构,我们上面已经分析过,它采用的方式是每个节点都保存一份集群配置信息,也就是说每一个节点的状态都会冗余多份,那么真的有必要这样吗?可不可以将集群配置信息统一维护在一个地方呢?
答案是肯定的。利用中心化的架构思路可以很好的实现这点。其主要思路就是添加一个配置中心来统一管理 redis 集群状态,然后添加一个代理层来实现路由转发,这样的话 redis 的功能其实就很纯粹了,只需要负责处理用户请求以及上报节点状态即可。具体思路可以去了解了解 codis / twemproxy 的实现。这里贴出一张 codis 的简易架构图:
通过配置中心统一管理配置信息,可以很大程度上杜绝 redis 节点间的通信,使 redis 要实现的功能尽可能精简,但同时也带来了另外一些问题:
•添加了一个代理层,网络多了一跳,势必会带来性能损耗;•集群架构新增了很多角色,架构的复杂性更高,维护成本也相应的增大。
其实针对第一个问题,还有一种解决方案就是客户端寻址,说白了就是将代理层的操作集成到客户端本身,这样的话能够避免到代理层的访问,性能很高。但是缺点也是有的,那就是大大增加了开发成本,需要定制化 redis 客户端。
结语
本文我们讲解了 Redis Cluster 的 Gossip 实现,主要是通过一种随机的方式来广播自己的状态,这里的随机主要包括目标节点的随机以及消息内容的随机。同时通过去中心化的不足来讲解了制约 Redis Cluster 集群规模的原因,并简单提了两个可替代的解决方案以及他们的优缺点。当然不同的架构都各自有各自的好处,大家适用过程中还是需要根据实际情况,例如业务预期发展规模以及团队开发人力等因素选择适合自己的架构。总之一句话:没有最好的架构,只有最合适的架构。
点个关注,么么哒。
References
[1] Gossip协议:流言蜚语,原来也可以实现一致性: https://time.geekbang.org/column/article/208182[2] redis: https://github.com/redis/redis
以上是关于什么限制了 Redis Cluster 的集群规模的主要内容,如果未能解决你的问题,请参考以下文章