在阿里淘宝 双11 的过程中,长期以来都是在生产环节做全链路压测的,通过实践我们发现在生产环境中做压测,实际上会和一个 IT 组织的结构、成熟度、流程等紧密相关,所以我们把全链路压测从简单的制作范围内脱离出来,变成整个业务连续性的方案。 本文分四个方面为大家阐述:第一,整个全链路压测的意义,为什么要在生产环节上做全链路压测;第二,关于落地的技术点和解决方案;第三,生产过程中做全链路压测流程上的建议,考虑到每个组织的承受度不一样,给大家提供一些建议;第四,如何在第三方实现整个在生产环境中做业务连续性包括压测的结果。
全链路压测的意义
ALIWARE
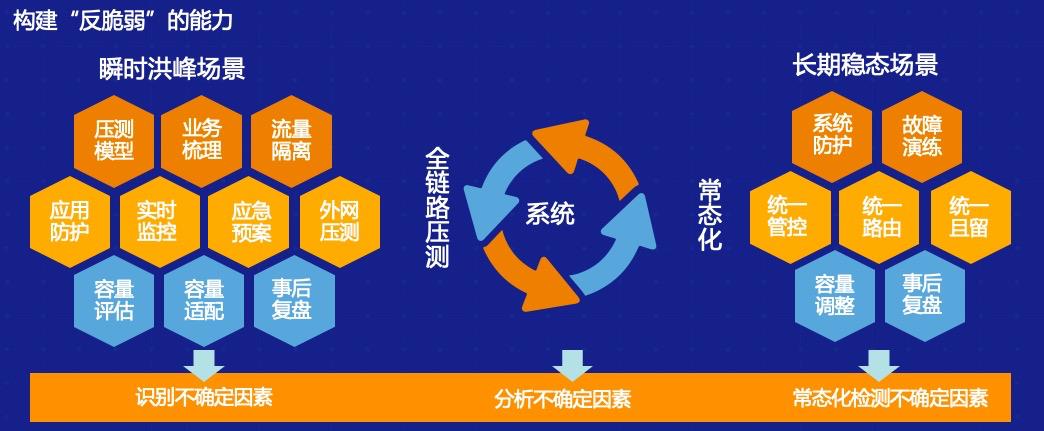
上图显示了三个问题,实际上是不同的 IT 组织在和测试交流的时候,这三个问题是比较有代表性的。 1. 很多测试同行说他们线下也做过性能测试,但是到了线上之后还是存在很多问题,因为不太可能会在线下模拟一个跟线上 1:1 的环境。在有很多第三方接口的情况下,大家也很少会去模拟线上整个场景。因此我们在线下做了很多测试工作后,总结出了为什么很多从线下容量推导到线上容量的公司却最终效果不是很好,就是这样的原因。 2. 现在所有的 IT 组织都在搞 DevOps,我们的功能从一个月迭代一次到现在一周迭代一次,留给测试的时间越来越短。功能测试时间从之前的一周、两周缩短到现在三四天、两三天的时间,那性能测试就没有办法按时上线,很有可能会出现各种各样的性能问题,这会直接影响到企业的品牌影响力。 3. 平时线上水位比较低,很少达到高峰期,但是会出现一些突发情况。比如像去年的疫情使得很多公司的业务变成在线业务。比如教育行业,之前是课堂上老师面对面的教育,现在选择线上在线平台来做,这类突发的情况会使测试工程师,包括开发运维团队受到很大的困扰。在这之前我先介绍一个概念,这个概念是由《黑天鹅》的原作者 Nassim Nicholas Taleb 提出,概念中心是脆弱与反脆弱。 什么是脆弱?脆弱就像玻璃,大家知道玻璃很脆易碎。脆弱的反义词是什么?不是强韧也不是坚韧,可能是反脆弱。什么是反脆弱呢?比如乒乓球,大家知道乒乓球在地上不用很大的力就可以破坏掉,踩一脚就破坏掉了,但是高速运动的情况下,乒乓球我们施加的力度越大,它的反弹力度越大,说明乒乓球在运动过程中有反脆弱的特性。 我们的 IT 系统实际上也是这样的。不管什么代码都不能保证是完全没有问题的,我们的基础设施可能也是脆弱的,像服务器、数据库等总会有局限。我们的框架也总是脆弱的,将这些问题综合在一起,我们希望通过某些手段,比如通过预案、风险的识别,或者通过一些熔断的手段,最终把这些东西组合在一起,让整个 IT 系统有反脆弱的特性。总之,我们希望通过一些手段使得 IT 系统有足够的冗余,而且有足够多的预案应对突发的不确定性风险。 如何打造 IT 系统反脆弱能力呢?我们希望通过一些手段,比如说像线上的压测能力,提供不确定的因素,接着通过在这个过程中实时监控,包括预案的能力,最终把这些不确定性的因素识别出来,并且在线上生产压测过程中对它做一些处理,更多可能会通过事后复盘等方式,做到对不确定性因素的识别。接着我们可能会在生产环境中通过之前的手段,在生产环境上做一个稳定性的常态化压测,实现长期稳定的场景,最终我们可能达到反脆弱能力所需要的整体监控的能力、运营防护能力,以及管控路由能力,这会让整个 IT 系统具备反脆弱的特性。
全链路压测解决方案
ALIWARE
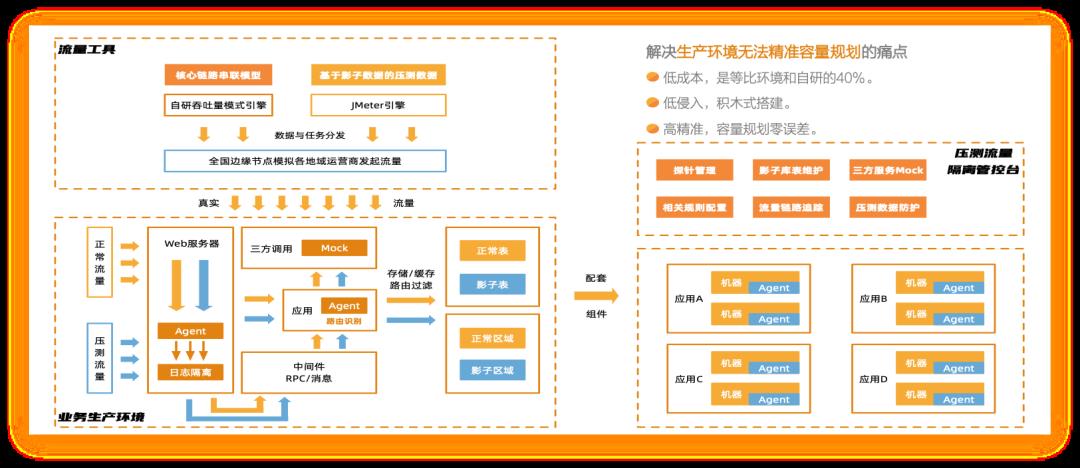
如何在生产环境上做全链路压测?它需要用到哪些技术手段? 1 压测进程演变
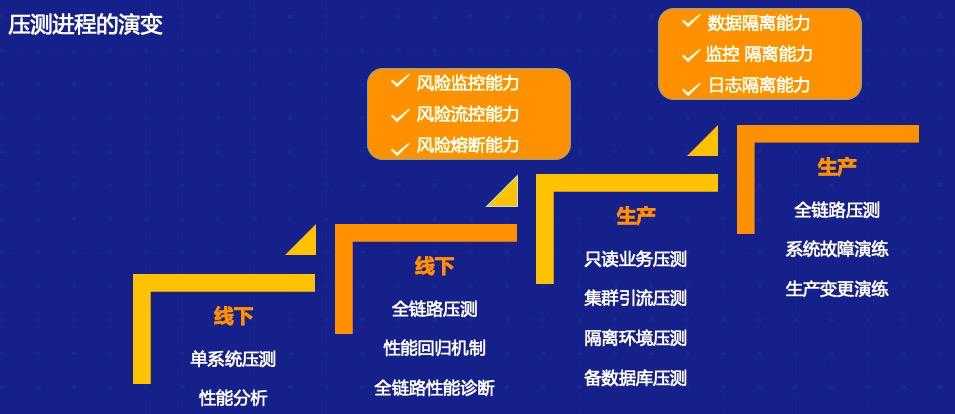
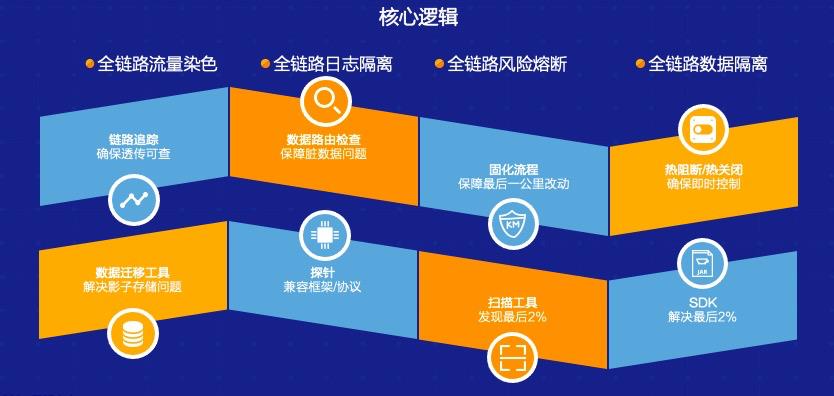
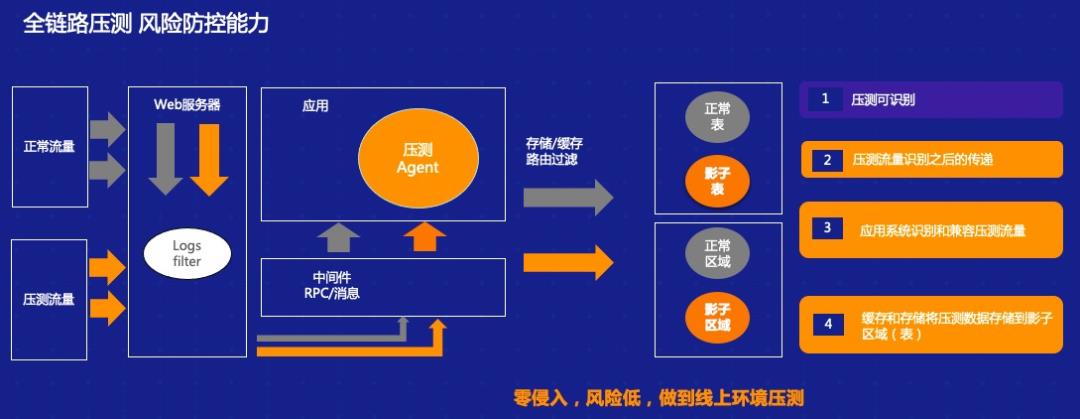
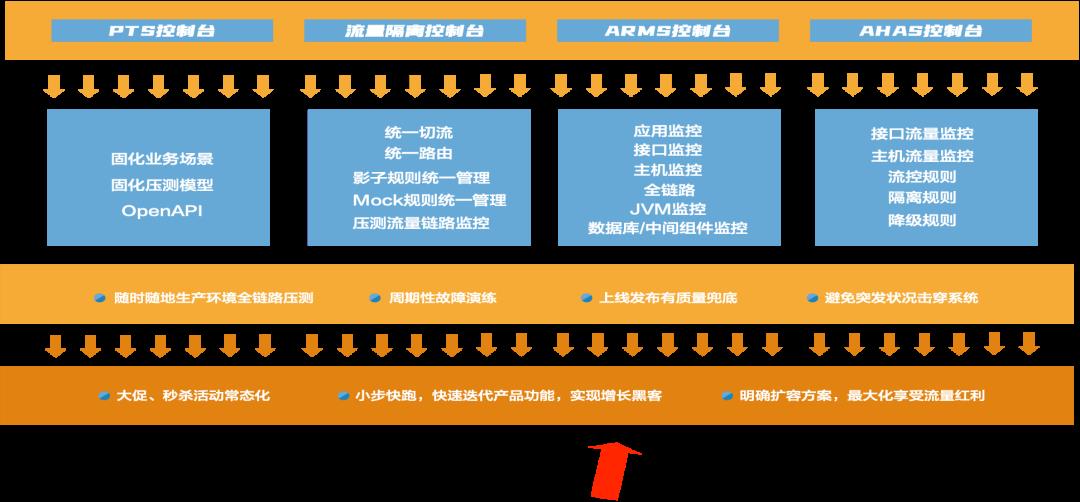
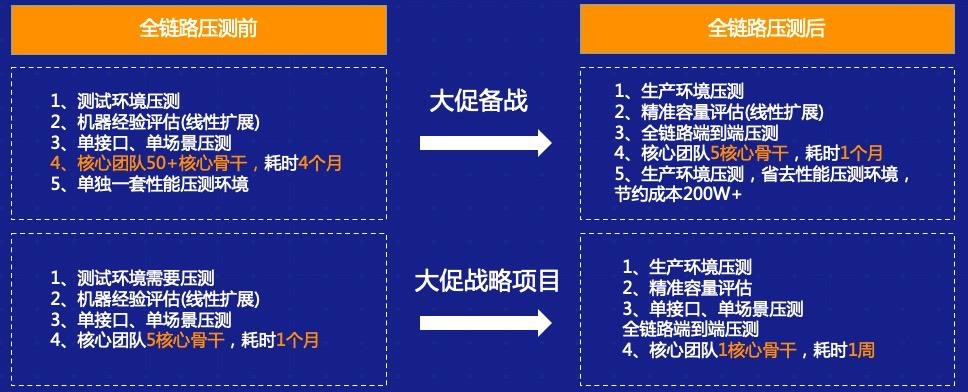
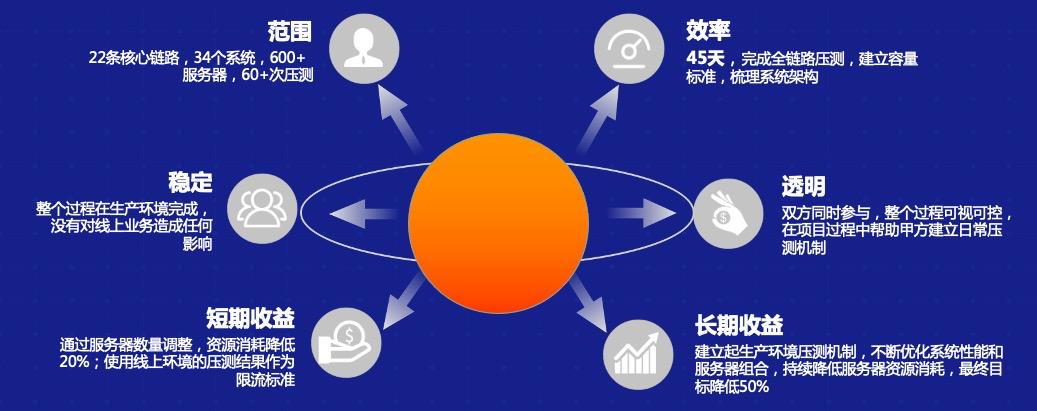
一般情况下,测试是怎么样从线下一点点往线上演变的?我把它分为四个阶段: 1. 目前绝大多数 IT 可以做到的是线下单系统压测,即针对单个接口或者单个场景做压测,同时也会做系统分析和性能分析。但在复杂的业务场景之下,我们可能没办法去充分发现问题,很多都是由开发或者测试同学自发进行的活动。 2. 我们成立了一个类似于测试实验室或者测试组织的机构,这样一个大的部门可能会构造出一批类似于生产环境的性能测试环境,在这上面我们可能会做更多的事情,比如说做一个线下环境的全链路压测,并且我们可以根据之前积累的经验在上面做一些线下的回归,包括性能的诊断等。其实这一步相当于整个测试往前再走一步,对测试环境中的链路做一些分析,在上面演变一些能力,比如说风险的控制等等。 3. 目前绝大部分 IT 企业和互联网企业愿意尝试线上生产环境的业务压测。这部分实际上和之前的第二阶段相差不多,但是在这个过程中人为的把它分为了两层:第一层是单纯的做全链路压测,很多 IT 公司已经在非生产环节中做了只读业务的压测,因为这样不会对数据造成污染。而再往下一层,有些组织可能会在正常生产时段中做进一步的全链路压测,这种情况下我们就会要求这个组织拥有更高的能力。 比如说我们需要对整个压测流量做一些染色,能够区分出来正常的业务数据,正常的流量和非正常的压测流量,可能有的会做一些环境的隔离,而在业务生产期间内我们做生产的压测,需要考虑到整个流量的偏移、限流,包括熔断机制等。不管怎样做业务,可能都会对最终的生产业务造成一定的影响,真正出现问题的时候可能需要有快速的熔断机制。 4. 做到压缩熔断渲染,包括对熔断的机制——有了这样的能力之后,最后一个阶段就是整个生产链路的全链路压测,包括读写,它就具备了基本能力。这个方面我们其实更多的是通过引入库表,加上技术手段,在这个生产上做全链路压测,包括读业务、写业务等,同时我们有系统故障演练和生产变更演练的能力,在这种情况下我们可能最终具备了数据隔离能力、监控隔离能力和日志隔离能力。 2 全链路压测关键技术