机器学习—主要术语(整合版)
Posted 一颗小树x
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习—主要术语(整合版)相关的知识,希望对你有一定的参考价值。
前言
本文参考谷歌官网对机器学习术语的解释,进行总结并加以描述。
什么是机器学习?简单来说,机器学习系统通过学习如何组合输入信息来对未见过的数据做出有用的预测。
目录
经验风险最小化(ERM,empirical risk minimization)
主要术语(基本)
主要包括标签、特征、样本、训练、模型、回归模型、分类模型、泛化、过拟合、预测、平稳性、训练集、验证集、测试集。
标签(label)
标签是我们要预测的事物,在分类任务中的类别,比如是猫或狗;简单线性回归中的y变量;。标签可以是小麦未来的价格、图片中显示的动物品种、音频剪辑的含义或任何实物。
在监督学习中,标签值是样本的“答案”或“结果”部分。
特征(feture)
在进行预测时使用的输入变量。
特征是输入变量,即简单线性回归中的x变量;在分类任务中的输入图像特征。
简单的机器学习项目可能会使用单个特征,而比较复杂的机器学习项目可能会使用数百万个特征,按如下方式制定: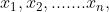
在垃圾邮箱检测器示例中,特征可能包括:
- 电子邮件文件中的字词
- 发件人的地址
- 发送电子邮件的时段
- 电子邮箱包含“一些敏感词”
样本(example)
数据集的一行。在监督学习的样本中,一个样本既有特征,也有标签。在无监督学习的样本中,一个样本只有特征。
样本是指数据的特定示例:x。(x表示一个矢量)将样本分为以下两类:
- 有标签样本
- 无标签样本
有标签样本同时包含特征的标签,即:
labeled examples: {features, label}: (x, y)我们使用有标签样本训练模型;在垃圾邮件检测器示例中,有标签样本是用户明确标记为“垃圾邮件”或“非垃圾邮件”的各个电子邮件。
例如,下表显示了从包含加利福尼亚房价信息的数据集中抽取的5个有标签样本:
| housingMedianAge (特征) | totalRooms (特征) | totalBedrooms (特征) | medianHouseValue (标签) |
|---|---|---|---|
| 15 | 5612 | 1283 | 66900 |
| 19 | 7650 | 1901 | 80100 |
| 17 | 720 | 174 | 85700 |
| 14 | 1501 | 337 | 73400 |
| 20 | 1454 | 326 | 65500 |
无标签样本包含特征,但不包含标签,即:
unlabeled examples: {features, ?}: (x, ?)以下是取自同一住房数据集的3个无标签样本,其中不包含medianHoustonValue:
| housingMedianAge (特征) | totalRooms (特征) | totalBedrooms (特征) |
|---|---|---|
| 42 | 1686 | 361 |
| 34 | 1226 | 180 |
| 33 | 1077 | 271 |
在使用有标签样本训练模型之后,我们会使用该模型预测无标签样本的标签。在垃圾邮件检测器示例中,无标签样本是用户尚未添加标签的新电子邮件。
模型(model)
模型定义了特征与标签之间的关系。比如,垃圾邮件检测模型可能会将某些特征与“垃圾邮件”紧密联系起来。模型生命周期的两个阶段:
- 训练是指创建或学习模型。即:向模型展示有标签样本,让模型逐渐学习特征与标签之间的关系。
- 推断是指将训练后的模型应用于无标签样本。即:使用经过训练的模型做出有用的预测
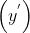 .在推断期间,可以针对新的无标签样本预测medianHouseValue。
.在推断期间,可以针对新的无标签样本预测medianHouseValue。
回归模型(regression model)
一种模型,能够输出连续值(通常为浮点值)。
回归模型可预测连续值。例如,回归模型做出的预测可回答如下问题:
- xxx地方的一栋房产的价值是多少?
- 用户点击此广告的概率是多少?
分类模型(classification model)
用于区分两种或多种离散类别。
分类模型可预测离散值。例如,分类模型做出的预测可回答如下问题:
- 某个指定电子邮件是垃圾邮件还是非垃圾邮件?
- 这是一张狗或是猫的图像?
训练(training)
构成模型中理想参数的过程;训练一个好的模型,主要是得到模型中的参数,包括权重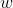 和偏置
和偏置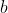 等。
等。
泛化(generalization)
是指模型依据训练时采用的模型,针对未见过的新数据做出争取预测的能力。
过拟合(overfitting)
创建的模型与训练数据过于匹配,以至于模型无法根据新数据做出正确的预测。
预测(perdition)
模型在收到数据样本后的输出。
平稳性(stationarit)
数据集中数据的一种属性,表示数据分布在一个或多个维度保持不变。这种维度最常见的是时间,即:表明平稳性的数据不随时间而变化。
训练集(training set)
数据集的子集,用于训练模型。与验证集和测试集相对。
验证集(validation set)
数据集的一个子集,从训练集分离而来,用于调整超参数。与训练集和测试集相对。
测试集(test set)
数据集的子集,用于在模型经过验证集的初步验证后,进行测试模型。与训练集和验证集相对。
主要术语(进阶版1)
主要包括类别、分类模型、回归模型、收敛、准确率、精确率、召回率、凸集、凸函数、凸优化、激活函数、反向传播算法、批次、批次大小。
类别(class)
类别是标签枚举的一组目标值中的一个。比如:在二分类中,标签组一共有两个,分别为猫、狗;其中“猫”是一个类别;“狗”也是一个类别。
分类模型(classification model)
用于区分两种或多种离散类别。
比如,在猫狗识别中,模型要区分这个输入的图像是“猫”,还是“狗”,这是一个典型的二分类模型。
在语言分类中,模型需要区分输入的是中文、英语、法语、俄语,还是其他语言;这是一个多分类模型。
回归模型(regression model)
用于预测输出连续值,比如浮点值。
比如:在放假预测中,输入一些与房价有关的数据,销售日期、销售价格、卧室数、浴室数、房屋面积、停车面积、房屋评分、建筑面积等等;通过模型来预测房子的价格,比如输出56.78万元。
收敛(convergence)
是指在训练期间达到的一种状态,模型达到稳定状态,即经过一定次数的迭代之后,训练损失和验证损失在每次迭代中的变换都非常小或根本没有变化。
准确率(accuracy)
通常用于分类模型,表示分类模型的正确预测所占的比例。在多分类中,定义:
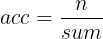
acc是指准确率;n是指正确分类的个数;sum是指总样本数。
比如:一共有100个数据样本,模型正确预测出98个,有2个预测错误了,那么该模型的准确率为:acc = 98 / 100 = 0.98 ,即:98%
精确率(precision)
一种分类模型的指标,是指模型正确预测正类别的频率,即:
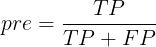
pre是指精确率;TP(正例)是指实际为正,预测为正;FP(假正例)是指实际为负,预测为正。
精确率针对的是正类别,一共预测了若干个正类别(正例 + 假正例),其中有多少个是预测正确的。
准确率针对的是整体数据,包括正类别、负类别(正例 + 负类 +假正例 + 假负例),在整体数据中有多少是预测正确的。
召回率(recall)
一种分类模型指标,是指在所有可能的正类别标签中,
凸集(convex set)
欧几里得空间的一个子集,其中任意两点之间的连线仍完成落在该子集内。
比如,下面的两个图像都是凸集:

相反,下面的两个图形都不是凸集:

凸函数(convex function)
函数图像以上的区域为凸集,典型凸函数的形状类似于字母U,以下是几种凸函数:
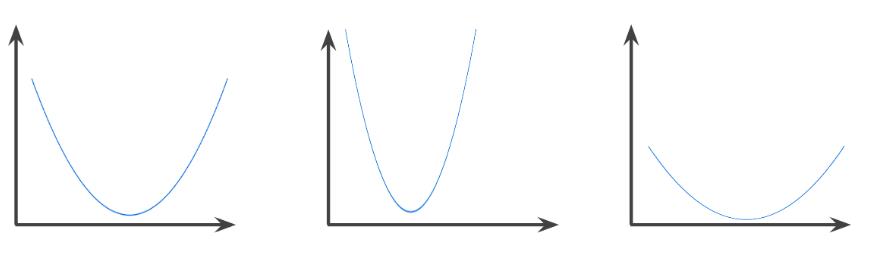
相反,以下函数则不是凸函数,请注意图像上方的区域不是凸集:
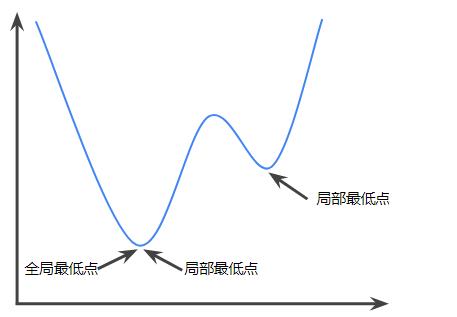
严格凸函数只有一个局部最低点,改点也是全局最低点。
常见的函数都是凸函数:
- L2损失函数
- 对数损失函数
- L1正则化
- L2正则化
梯度下降法的很多变体都一定能找到一个接近严格图函数最小值的点。
随机梯度下降法的很多变体都很高可能(并非一定能找到)接近严格凸函数最小值的点。
两个凸函数的和也是凸函数,比如L2损失函数+L1正则化。
深度模型绝不会是凸函数。但专门针对凸优化设计的算法往往总能在深度网络上找到非常好的解决方案,虽然这些解决方案并不一定对应全局最小值。
凸优化(convex optimization)
使用数学方法寻找凸函数最小值的过程。
机器学习方面的大量研究都是专注于如何通过公式将各种问题表示为凸优化问题,以及如何高效解决这些问题。
激活函数(activation function)
本质是一种函数,通常把输入值映射为另一个值,映射的方式有:线性映射、非线性映射;
比如:在线性映射中,假设激活函数为 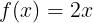 ,即 y = 2x,输入值x, 映射后的输出值y;当输入值为3,经过激活函数映射后,输出值为6。
,即 y = 2x,输入值x, 映射后的输出值y;当输入值为3,经过激活函数映射后,输出值为6。
在非线性映射中,假设激活函数为 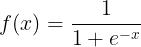 ,输入值x, 映射后的输出值y;输入值为0时,经过激活函数映射后,输出值为0.5。
,输入值x, 映射后的输出值y;输入值为0时,经过激活函数映射后,输出值为0.5。
其实这个非线性映射的激活函数是比较常见的Sigmoid函数,看看它的图像:

反向传播算法(backpropagation)
该算法会先按前向传播方式计算(并缓存)每个节点的输出值,然后再按反向传播遍历图的方式计算损失函数值相对于每个参数的偏导数。
批次(batch)
模型训练的一次迭代(一次梯度更新)中使用的样本集。
批次大小(batch size)
一个批次中的样本数。比如,在随机梯度下降SGD算法中,批次大小为1;在梯度下降算法中,批次大小为整个训练集;
批量梯度下降算中,批次大小可以自定义的,通常取值范围是10到1000之间。比如:训练集为40000个样本,设置批次大小为32,训练一次模型,使用到32个样本。
主要术语(补全中)
主要术语,包括偏差、推断、线性回归、权重、经验风险最小化、均方误差、平方损失函数、损失、梯度下降法、随机梯度下降、批量梯度下降法、参数、超参数、学习率、特征工程、离散特征、独热编码、表示法、特征组合、合成特征、
偏差(bias)
距离原点的截距或偏移。偏差(也称为偏差项)在机器学习模型中用b或
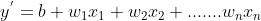
推断(inference)
在机器学习中,推断通常指以下过程:通过将训练过的模型应用于无标签样本来做出雨雪。在统计学中,推断是指在某些观察数据条件下拟合分布参数的过程。(请参阅维基百科中有关统计学推断的文章。)
线性回归(linear regression)
一种回归模型,通过将输入特征进行线性组合输出连续值。
权重(weight)
模型中特征的系数,或深度网络中的边。训练模型的目标是确定每个特征的理想权重。如果权重为0,则相应的特征对模型来说没有任何影响。
经验风险最小化(ERM,empirical risk minimization)
用于选择函数,选择基于训练集的损失降至最低的函数。与结构风险最小化相对。
均方误差(MSE,Mean Squared Error)
每个样本的平均平方损失。MSE的计算方法是平方损失除以样本数。
平方损失函数(squared loss)
在线性回归中使用的损失函数(也称为L2损失函数)。改行可计算模型为有标签样本预测的值,和标签的真实值之差的平方。 由于取平方值,该损失函数会放大不佳预测的影响。与L1损失函数相对,平方损失函数对离群值的反应更强烈。
损失(Loss)
一种衡量指标,用于衡量模型的预测偏离其标签程度。要确定此值,模型需要定义损失函数。例如:线性回归模型参与均方误差MAS损失函数,分类模型采用交叉熵损失函数。
梯度下降法(gradient descent)
一种通过计算梯度,并且将损失将至最低的技术,它以训练数据位条件,来计算损失相对于模型参数的梯度。梯度下降法以迭代方式调整参数,逐渐找到权重和偏差的最佳组合,从而将损失降至最低。
随机梯度下降(SGD)
梯度下降法在大数据集,会出现费时、价值不高等情况。如果我们可以通过更少的计算量得出正确的平均梯度,效果更好。通过从数据集中随机选择样本,来估算出较大的平均值。
原理 它每次迭代只使用一个样本(批量大小为1)。
如果进行足够的迭代,SGD也可以发挥作用,但过程会非常杂乱。“随机”这一术语表示构成各个批量的一个样本都是随机选择的。
批量梯度下降法(BGD)
它是介于全批量迭代与随机选择一个迭代的折中方案。全批量迭代(梯度下降法);随机选择一个迭代(随机梯度下降)。
原理 它从数据集随机选取一部分样本,形成小批量样本,进行迭代。小批量通常包含10-1000个随机选择的样本。BGD可以减少SGD中的杂乱样本数量,但仍然波全批量更高效。
参数(parameter)
机器学习系统自行训练的模型变量。例如,权重。它们的值是机器学习系统通过连续的训练迭代逐渐学习到的;与超参数相对。
超参数(hyperparameter)
在模型训练的连续过程中,需要人工指定和调整的;例如学习率;与参数相对。
学习率(learning rate)
在训练模型时用于梯度下降的一个标量。在每次迭代期间,梯度下降法都会将学习速率与梯度相乘;得出的乘积称为梯度步长。
特征工程(feature engineering)
是指确定哪些特征可能在训练模型方面非常有用,然后将日志文件及其他来源的原始数据转换为所需的特征。特征工程有时称为特征提取。
离散特征(discrete feature)
一种特征,包含有限个可能值。例如,某个值只能是“动物”、或“蔬菜”的特征,这是都能将类别列举出来的。与连续特征相对。
独热编码(one-hot-encoding)
一种稀疏二元向量,其中:
- 一个元素设为1.
- 其他所有元素均设为0 。
独热编码常用语表示拥有 有限个可能值的字符串或标识符。
表示法(representation)
将数据映射到实用特征的过程。
合成特征(synthetic feature)
一种特征,不在输入特征之列,而是从一个或多个输入特征衍生而来。合成特征包括以下类型:
- 对连续特征进行分桶,以分为多个区间分箱。
- 将一个特征值与其他特征值或本身相差(或相除)。
- 创建一个特征组合。
仅通过标准化或缩放创建的特征不属于合成特征。
特征组合(feature cross)
通过将单独的特征进行组合(求笛卡尔积),形成的合成特征。特征组合有助于表达非线性关系。
L1正则化(L1 regularization)
一种正则化,根据权重的绝对值的总和,来惩罚权重。在以来稀疏特征的模型中,L1正则化有助于使不相关或几乎不相关的特征的权重正好为0,从而将这些特征从模型中移除。与L2正则化相对。
L2正则化(L2 regularization)
一种正则化,根据权重的平方和,来惩罚权重。L2正则化有助于使离群值(具有较大正值或较小负责)权重接近于0,但又不正好为0。在线性模型中,L2正则化始终可以进行泛化。
本文参考谷歌官方:https://developers.google.cn/machine-learning/crash-course/framing/ml-terminology
这是机器学习(快速入门)专栏中第一节,后面安排是:
- 机器学习1—主要术语(综述)
- 机器学习2-线性回归
- 机器学习3-训练与损失
- 机器学习4-模型迭代
- 机器学习5-学习率
- 机器学习6-泛化与过拟合
- 机器学习7-数据集划分
- 机器学习8-特征工程
- 机器学习9-正则化L2(简单性)
- 机器学习10-逻辑回归
- 机器学习11-正则化L1(稀疏性)
- 机器学习12-神经网络
- 机器学习13-训练模型的坑
- .........
- ..........
基本写好啦,还没有发布,后面每周发布一到两篇。
以上是关于机器学习—主要术语(整合版)的主要内容,如果未能解决你的问题,请参考以下文章