[新星计划]导师嫌我Sql写的太low?要求我重写还加了三个需求?——二战Spark电影评分数据分析
Posted ChinaManor
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[新星计划]导师嫌我Sql写的太low?要求我重写还加了三个需求?——二战Spark电影评分数据分析相关的知识,希望对你有一定的参考价值。
引言
大家好,我是ChinaManor,直译过来就是中国码农的意思,俺希望自己能成为国家复兴道路的铺路人,大数据领域的耕耘者,平凡但不甘于平庸的人。

这是我的上篇博文,当时仅是做了一个实现案例(demo级别 ),没想到居然让我押中了题,还让我稳稳的及格了(这次测试试卷难度极大,考60分都能在班上排进前10)
不过我在复盘的时候,发现自己的致命弱点:写sql的能力太菜了。。
于是我重做了一遍,并满足了导师提的3个需求:
需求1: 查找电影评分个数超过50,且平均评分较高的前十部电影名称及其对应的平均评分
需求2: 查找每个电影类别及其对应的平均评分
需求3: 查找被评分次数较多的前十部电影
数据介绍:使用的文件movies.csv和ratings.csv
movies.csv该文件是电影数据,对应的为维表数据,其数据格式为
movieId title genres
电影id 电影名称 电影所属分类
样例数据如下所示:逗号分隔
1,Toy Story (1995),Adventure|Animation|Children|Comedy|Fantasy
ratings.csv该文件为定影评分数据,其数据格式为
userId movieId rating timestamp
电影id 电影名称 电影所属分类 时间戳
建表语句
CREATE DATABASE db_movies;
USE db_movies;
CREATE TABLE `ten_movies_avgrating` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增id',
`movieId` int(11) NOT NULL COMMENT '电影id',
`ratingNum` int(11) NOT NULL COMMENT '评分个数',
`title` varchar(100) NOT NULL COMMENT '电影名称',
`avgRating` decimal(10,2) NOT NULL COMMENT '平均评分',
`update_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `movie_id_UNIQUE` (`movieId`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE `genres_average_rating` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增id',
`genres` varchar(100) NOT NULL COMMENT '电影类别',
`avgRating` decimal(10,2) NOT NULL COMMENT '电影类别平均评分',
`update_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `genres_UNIQUE` (`genres`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE `ten_most_rated_films` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增id',
`movieId` int(11) NOT NULL COMMENT '电影Id',
`title` varchar(100) NOT NULL COMMENT '电影名称',
`ratingCnt` int(11) NOT NULL COMMENT '电影被评分的次数',
`update_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
项目结构一览图
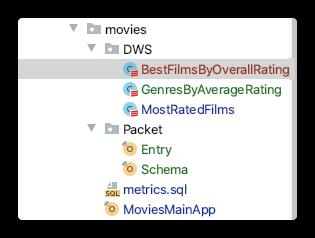
由题意可知
先创建实体类,字段是从建表语句中得来的。

Entry.scala
package cn.movies.Packet
/**
* @author ChinaManor
* #Description Entry
* #Date: 6/6/2021 17:23
*/
object Entry {
case class Movies(
movieId: String, // 电影的id
title: String, // 电影的标题
genres: String // 电影类别
)
case class Ratings(
userId: String, // 用户的id
movieId: String, // 电影的id
rating: String, // 用户评分
timestamp: String // 时间戳
)
// 需求1mysql结果表
case class tenGreatestMoviesByAverageRating(
movieId: String, // 电影的id
ratingNum:String,
title: String, // 电影的标题
avgRating: String // 电影平均评分
)
// 需求2MySQL结果表
case class topGenresByAverageRating(
genres: String, //电影类别
avgRating: String // 平均评分
)
// 需求3MySQL结果表
case class tenMostRatedFilms(
movieId: String, // 电影的id
title: String, // 电影的标题
ratingCnt: String // 电影被评分的次数
)
}
再创建个表结构~~
Schema.scala
package cn.movies.Packet
import org.apache.spark.sql.types.{DataTypes, StructType}
/**
* @author ChinaManor
* #Description Schema
* #Date: 6/6/2021 17:34
*/
object Schema {
class SchemaLoader {
// movies数据集schema信息
private val movieSchema = new StructType()
.add("movieId", DataTypes.StringType, false)
.add("title", DataTypes.StringType, false)
.add("genres", DataTypes.StringType, false)
// ratings数据集schema信息
private val ratingSchema = new StructType()
.add("userId", DataTypes.StringType, false)
.add("movieId", DataTypes.StringType, false)
.add("rating", DataTypes.StringType, false)
.add("timestamp", DataTypes.StringType, false)
def getMovieSchema: StructType = movieSchema
def getRatingSchema: StructType = ratingSchema
}
}
然后开始写Main方法,其实只有区区八十行代码。。。
spark总要有实例对象吧。
// 创建spark session
val spark = SparkSession
.builder
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[4]")
.getOrCreate
然后 new个schema信息
val schemaLoader = new SchemaLoader
然后尝试读取csv文件,
// 读取Movie数据集
val movieDF: DataFrame = readCsvIntoDataSet(spark, MOVIES_CSV_FILE_PATH, schemaLoader.getMovieSchema)
// 读取Rating数据集
val ratingDF: DataFrame = readCsvIntoDataSet(spark, RATINGS_CSV_FILE_PATH, schemaLoader.getRatingSchema)
发现读取方法和路径都没有,于是补救一下
// 文件路径
private val MOVIES_CSV_FILE_PATH = "D:\\\\Users\\\\Administrator\\\\Desktop\\\\exam0601\\\\datas\\\\movies.csv"
private val RATINGS_CSV_FILE_PATH = "D:\\\\Users\\\\Administrator\\\\Desktop\\\\exam0601\\\\datas\\\\ratings.csv"
/**
* 读取数据文件,转成DataFrame
*
* @param spark
* @param path
* @param schema
* @return
*/
def readCsvIntoDataSet(spark: SparkSession, path: String, schema: StructType) = {
val dataDF: DataFrame = spark.read
.format("csv")
.option("header", "true")
.schema(schema)
.load(path)
dataDF
}
紧接着重头戏来了。。
写sql语句,在大数据行业懂得写sql就等于会了80%

WITH ratings_filter_cnt AS (
SELECT
movieId,
count( * ) AS rating_cnt,
Round(avg( rating ),2) AS avg_rating
FROM
ratings
GROUP BY
movieId
HAVING
count( * ) >= 50
),
ratings_filter_score AS (
SELECT
movieId, -- 电影id
rating_cnt, -- 个数
avg_rating -- 电影平均评分
FROM ratings_filter_cnt
ORDER BY avg_rating DESC -- 平均评分降序排序
LIMIT 10 -- 平均分较高的前十部电影
)
SELECT
m.movieId,
r.rating_cnt AS ratingNum,
m.title,
r.avg_rating AS avgRating
FROM
ratings_filter_score r
JOIN movies m ON m.movieId = r.movieId ORDER BY r.avg_rating DESC
关键点在于
WITH XXX AS SELECT

最后保存写入mysql表中
def saveToMysql(reportDF: DataFrame) = {
// TODO: 使用SparkSQL提供内置Jdbc数据源保存数据
reportDF
.coalesce(1)
.write
// 追加模式,将数据追加到MySQL表中,再次运行,主键存在,报错异常
.mode(SaveMode.Append)
// 覆盖模式,无需测试,直接将以前数据全部删除,再次重新重建表,肯定不行
//.mode(SaveMode.Overwrite)
.format("jdbc")
.option("driver", "com.mysql.jdbc.Driver")
.option("url", "jdbc:mysql://192.168.88.100:3306/db_movies?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true")
.option("user", "root")
.option("password", "123456")
.option("dbtable", "db_movies.ten_most_rated_films")
.save()
}
另外两个需求的SQL:
// 需求2:查找每个电影类别及其对应的平均评分
WITH explode_movies AS (
SELECT
movieId,
title,
category
FROM
movies lateral VIEW explode ( split ( genres, "\\\\|" ) ) temp AS category //爆炸函数拆一下|
)
SELECT
m.category AS genres,
Round(avg( r.rating ),2) AS avgRating
FROM
explode_movies m
JOIN ratings r ON m.movieId = r.movieId
GROUP BY
m.category
ORDER BY avgRating DESC
// 需求3:查找被评分次数较多的前十部电影
WITH rating_group AS (
SELECT
movieId,
count( * ) AS ratingCnt
FROM ratings
GROUP BY movieId
),
rating_filter AS (
SELECT
movieId,
ratingCnt
FROM rating_group
ORDER BY ratingCnt DESC
LIMIT 10
)
SELECT
m.movieId,
m.title,
r.ratingCnt
FROM
rating_filter r
JOIN movies m ON r.movieId = m.movieId ORDER BY r.ratingCnt DESC
总结
以上便是spark电影评分数据分析二次改写,比之前一篇sql更复杂,需求更多,
希望今晚的考试顺利通关@~@
如果需要完整版的代码可以私信我获取
愿你读过之后有自己的收获,如果有收获不妨一键三连一下~
以上是关于[新星计划]导师嫌我Sql写的太low?要求我重写还加了三个需求?——二战Spark电影评分数据分析的主要内容,如果未能解决你的问题,请参考以下文章