项目需求与技术架构
Posted Vics异地我就
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了项目需求与技术架构相关的知识,希望对你有一定的参考价值。
目录
知识点01:大数据业务需求
-
目标:了解常见大数据平台的业务需求
-
实施
-
大数据业务需求本质:通过对公司所有数据的处理和分析,提取数据中的价值,为公司挣更多的钱
-
数据分析:对公司中的业务数据进行分析处理,根据业务需求实现运营支撑
-
赚钱的实现:买卖产品
-
需求:需要更多的客户
-
实现:推广拉新
-
打广告:100万
-
砍价:100万
-
评价:好与不好的指标:用户播放量、点击量、注册量
-
数据分析:对所有广告和砍价的数据进行分析
-
广告:只要播放、点击、注册记录这个广告的数据
-
砍价:只要分享、点击、注册记录这个链接的分享数据
-
-
-
需求:用户注册了,怎么能让用户消费呢?
-
指标反映推广方式促进用户消费:首单转化率
-
-
解决:优惠券、现金券、优惠活动
-
需求:怎么能让大量的用户留存?
-
指标:留存率
-
-
-
推荐系统:基于对用户数据的分析,构建用户画像,精准把握用户需求,实现精准推荐
-
兴趣爱好:颜色、品牌、价格区间、之前购买信息
-
-
风控系统:安全领域、金融领域
-
统计分析一个恶意访问,拦截和屏蔽恶意访问
-
信用风控
-
-
机器学习:人脸识别、无人驾驶、自动驾驶
-
通过数据分析基于模型来实现自动化
-
-
-
小结
-
了解常见的大数据平台业务需求
-
知识点02:在线教育项目需求
-
目标:掌握在线教育项目需求
-
实施
-
行业:线上教育行业
-
产品:课程
-
目标:实现用户的转化运营分析,提高转化率,实现用户的学习管理分析,提高学习效率
-
业务流程
-
step1:用户访问网站或者APP
-
访问用户
-
step2:用户会咨询详细信息
-
咨询用户
-
-
step3:销售专员会联系用户
-
意向用户
-
-
step4:转化成功以后实现用户报名
-
报名用户
-
-
step5:学员学习,验证学习的效果
-
-
整体需求:提高报名率
-
分析流失用户的原因:基于不同角度去判断用户不报名的原因
-
为什么访问的人没有咨询?
-
网站的内容不吸引人
-
产品做的不好
-
价格高了
-
没有合适的校区、或者学科
-
-
为什么有意向最终没有报名?
-
产品不认可
-
销售的原因
-
-
-
实现学习质量的管理:基于不同维度分析学员学习质量差的原因
-
反馈分析
-
考试分析
-
考勤分析
-
作业分析
-
……
-
-
-
项目需求
-
需求1:实现不同维度下的用户转化率分析
-
需求2:实现不同维度下的学员考勤指标分析
-
-
项目看板模块
-
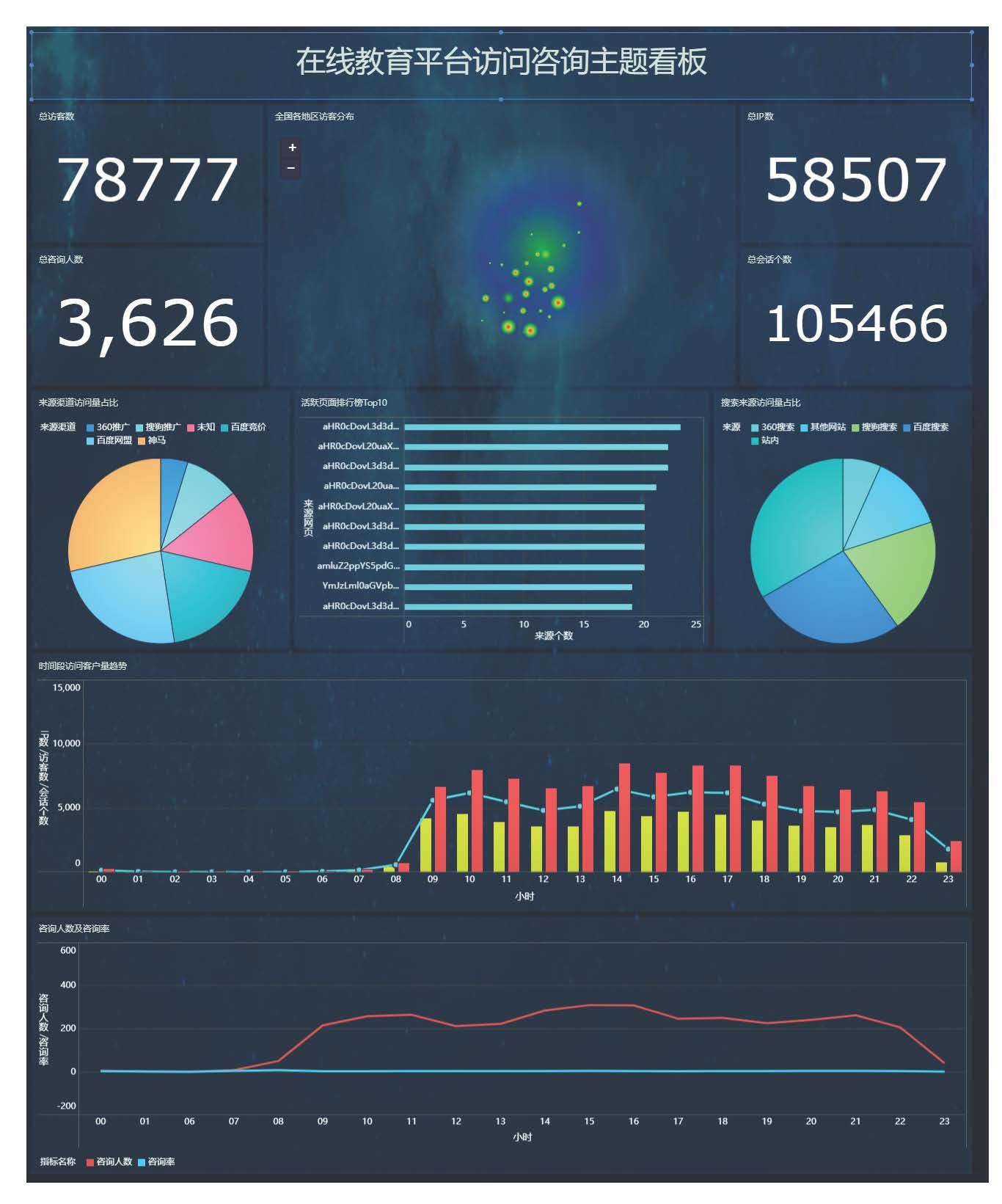
访问分析主题:分析不同维度下的用户访问信息
-
咨询分析主题:分析不同维度下的用户咨询信息
-
咨询率 = 咨询人数 / 访问人数
-
-
意向分析主题:分析不同维度下的用户意向信息
-
报名分析主题:分析不同维度下的用户报名信息
-
报名率 = 报名人数 / 意向人数
-
-
考勤分析主题:分析不同维度下的学员考勤信息
-
出勤率、迟到率、请假率、旷课率
-
-
-
项目效果
知识点03:大数据业务需求
-
目标:了解常见大数据平台的业务需求
-
实施
-
大数据业务需求本质:通过对公司所有数据的处理和分析,提取数据中的价值,为公司挣更多的钱
-
数据分析:对公司中的业务数据进行分析处理,根据业务需求实现运营支撑
-
赚钱的实现:买卖产品
-
需求:需要更多的客户
-
实现:推广拉新
-
打广告:100万
-
砍价:100万
-
评价:好与不好的指标:用户播放量、点击量、注册量
-
数据分析:对所有广告和砍价的数据进行分析
-
广告:只要播放、点击、注册记录这个广告的数据
-
砍价:只要分享、点击、注册记录这个链接的分享数据
-
-
-
需求:用户注册了,怎么能让用户消费呢?
-
指标反映推广方式促进用户消费:首单转化率
-
-
解决:优惠券、现金券、优惠活动
-
需求:怎么能让大量的用户留存?
-
指标:留存率
-
-
-
推荐系统:基于对用户数据的分析,构建用户画像,精准把握用户需求,实现精准推荐
-
兴趣爱好:颜色、品牌、价格区间、之前购买信息
-
-
风控系统:安全领域、金融领域
-
统计分析一个恶意访问,拦截和屏蔽恶意访问
-
信用风控
-
-
机器学习:人脸识别、无人驾驶、自动驾驶
-
通过数据分析基于模型来实现自动化
-
-
-
小结
-
了解常见的大数据平台业务需求
-
-
知识点04:在线教育项目需求
-
目标:掌握在线教育项目需求
-
实施
-
行业:线上教育行业
-
产品:课程
-
目标:实现用户的转化运营分析,提高转化率,实现用户的学习管理分析,提高学习效率
-
业务流程
-
step1:用户访问网站或者APP
-
访问用户
-
step2:用户会咨询详细信息
-
咨询用户
-
-
step3:销售专员会联系用户
-
意向用户
-
-
step4:转化成功以后实现用户报名
-
报名用户
-
-
step5:学员学习,验证学习的效果
-
-
整体需求:提高报名率
-
分析流失用户的原因:基于不同角度去判断用户不报名的原因
-
为什么访问的人没有咨询?
-
网站的内容不吸引人
-
产品做的不好
-
价格高了
-
没有合适的校区、或者学科
-
-
为什么有意向最终没有报名?
-
产品不认可
-
销售的原因
-
-
-
实现学习质量的管理:基于不同维度分析学员学习质量差的原因
-
反馈分析
-
考试分析
-
考勤分析
-
作业分析
-
……
-
-
-
项目需求
-
需求1:实现不同维度下的用户转化率分析
-
需求2:实现不同维度下的学员考勤指标分析
-
-
项目看板模块
-
访问分析主题:分析不同维度下的用户访问信息
-
咨询分析主题:分析不同维度下的用户咨询信息
-
咨询率 = 咨询人数 / 访问人数
-
-
意向分析主题:分析不同维度下的用户意向信息
-
报名分析主题:分析不同维度下的用户报名信息
-
报名率 = 报名人数 / 意向人数
-
-
考勤分析主题:分析不同维度下的学员考勤信息
-
出勤率、迟到率、请假率、旷课率
-
-
-
项目效果
-
-
-
小结
-
在线教育项目中的需求和模块是什么?
-
需求
-
统计不同维度下的转化率
-
访问转咨询率
-
意向转报名率
-
-
统计不同维度下的考勤指标
-
出勤率、迟到率、请假率、旷课率
-
-
-
模块
-
访问
-
咨询
-
意向
-
报名
-
考勤
-
-
-
知识点05:业务流程:数据来源
-
目标:了解常见的数据来源
-
实施
-
业务实现流程
-
数据生成:根据不同数据类型生成在不同的地方
-
数据采集:将所有原始数据采集到大数据平台中
-
数据存储:大数据平台分布式存储:数据仓库
-
数据处理:根据业务需求开发分布式程序对数据仓库中的数据进行处理
-
数据应用:报表
-
-
*业务数据*:用于支撑业务平台而实现的业务存储
-
存储:RDBMS
-
内容:用户数据、商品数据、订单存储
-
-
用户行为数据:用于记录用户在平台上所有的操作行为
-
存储:日志服务器中的日志
-
内容:用户在平台上所有的操作行为:注册、登陆、浏览、收藏、添加购物车、搜索、支付、提交订单
-
-
爬虫数据:爬虫组根据实际的数据需求,爬取其他网络平台的数据
-
运维日志:为了构建自动化运维平台,分析处理所有机器和程序的运营日志,提供给运维做监控
-
第三方数据:购买的数据,合作方的数据
-
-
小结
-
了解常见的数据来源即可
-
-
知识点06:业务流程:数据采集及存储
-
目标:了解数据采集及数据的存储过程
-
实施
-
数据采集
-
利用数据采集的工具,将需要的数据采集到大数据存储平台中
-
针对业务需求和数据源的存储类型不一样,会使用不同的工具来实现不同场景下的数据采集
-
Flume:实时数据流采集:文件的数据
-
Sqoop:离线数据库采集工具:数据库
-
导入:mysql =》 HDFS
-
InputFormat:DBInputFormat
-
OutputFormat:TextOutputFormat
-
-
导出:HDFS =》 MySQL
-
InputFormat:TextInputFormat
-
OutputFormat:DBOutputFormat
-
-
-
-
数据存储:统一化的数据管理和存储,数据仓库设计模型
-
工具:Hive【Hadoop】
-
ETL:过滤、补全、转换
-
分层:规范了数据处理的过程
-
建模:数据表的设计
-
-
-
小结
-
了解数据采集及数据的存储过程
-
-
知识点07:业务流程:数据处理及应用
-
目标:了解数据处理及数据的应用过程
-
实施
-
数据处理:通过分布式计算的程序根据业务需求对数据仓库中的数据进行分析处理,保存对应的结果
-
处理:写程序
-
MapReduce:基于Java代码
-
HDFS文件
-
-
HiveQL:基于SQL开发
-
Hive表
-
-
-
结果:MYSQL
-
-
数据应用:报表
-
工具:FineBI
-
-
整体流程
-
数据生成
-
数据采集
-
数据存储
-
数据处理
-
数据应用
-
-
-
小结
-
了解数据处理及数据的应用过程
-
-
知识点08:技术架构:常用技术选型
-
目标:了解大数据平台的常用技术选型
-
实施
-
数据采集
-
Flume:实时数据流采集
-
Sqoop:离线数据库采集
-
Logstash:全场景数据采集工具
-
Beats:轻量级数据采集工具,FileBeat
-
Canal:实时数据库采集
-
-
数据存储
-
Zookeeper:分布式协调服务,本质依旧是一个存储系统,只能存储少量数据
-
辅助选举
-
共享存储:元数据
-
-
HDFS:分布式文件系统,以文件的方式来管理数据
-
Hive:数据仓库,以表的方式来管理数据
-
Redis:纯内存式的KV结构的NoSQL数据库
-
Hbase:基于Hadoop的一个按列存储的NoSQL数据库
-
Kafka:分布式实时消息队列
-
ElasticSearch:全文检索引擎
-
MySQL:关系型业务数据库
-
场景一:保存工具的元数据
-
Hive、Hue、Oozie
-
-
场景二:存储分析的结果
-
-
-
数据处理
-
MapReduce:离线批处理系统,第一代计算引擎
-
Hive:基于SQL的MapReduce/Tez/Spark引擎
-
Spark:分布式技术栈
-
Core:类似于MapReduce
-
SQL:类似于Hive
-
Streaming:流式实时计算
-
-
Flink:实时计算工具
-
Impala、Presto、Kylin
-
-
其他工具
-
可视化:Hue
-
集群管理:Cloudera Manager、Ambari
-
任务流调度:Oozie、Azkaban、AirFlow
-
……
-
-
-
小结
-
了解大数据平台的常用技术选型
-
-
知识点09:技术架构:基础平台架构
-
目标:了解大数据的基础平台架构
-
实施
-
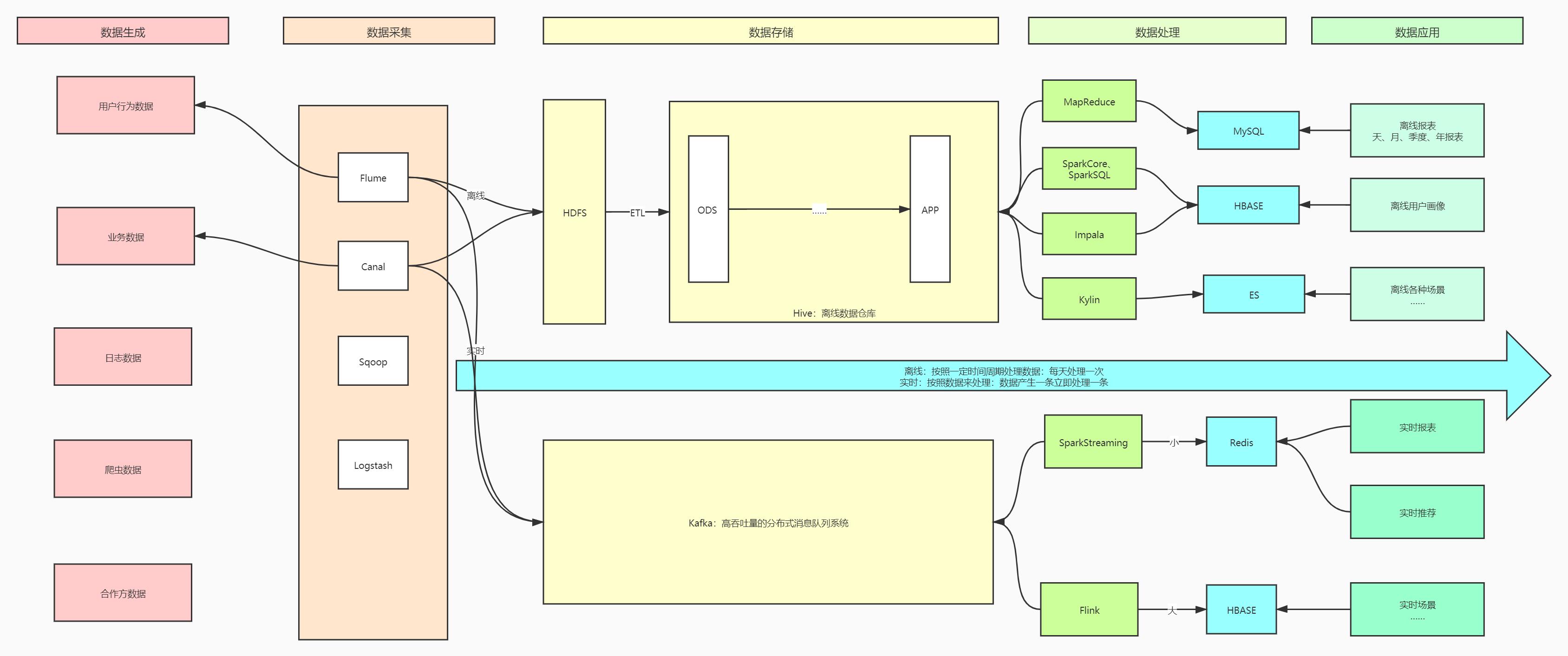
Lambda架构:离线和实时是两套架构
-
离线:以时间为单位的批处理,每天处理一次,时效性低
-
-
实时:以数据为单位的数据流处理,每产生一条就处理一次,时效性非常高
-
-
Kappa架构:将离线和实时统一通过实时架构来实现
-
-
小结
-
了解大数据的基础平台架构
-
-
知识点10:技术架构:在线教育项目架构
-
目标:掌握在线教育项目架构
-
实施
-
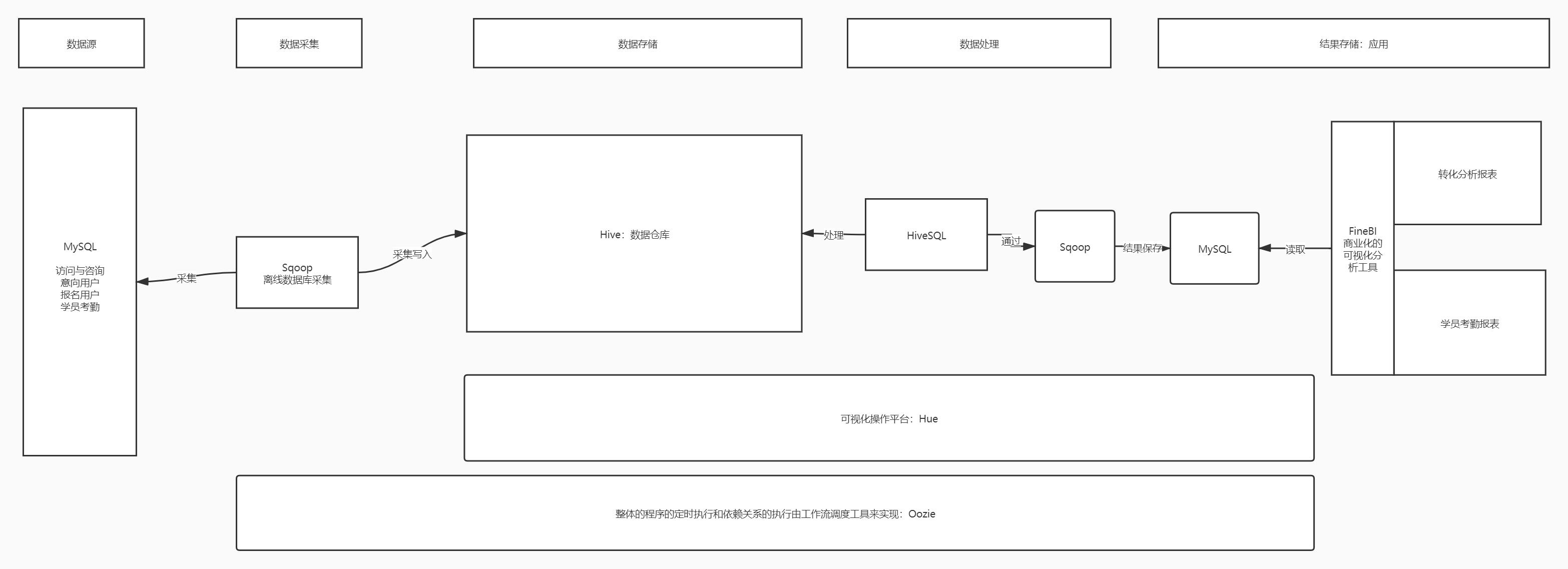
要求:必须要自己画出项目架构图
-
数据生成:业务数据库
-
访问与咨询数据:客服系统:MySQL
-
意向与报名数据:CRM营销系统:MySQL
-
学员考勤数据:学员管理系统:MySQL
-
-
数据采集:Sqoop实现增量采集
-
数据存储:Hive构建数据仓库
-
数据处理:HiveQL:MR实现分析处理
-
数据应用:MySQL + FineBI构建报表
-
任务调度:Oozie
-
可视化交互:Hue
-
集群管理:Cloudera Manager
-
-
-
小结
-
整个项目架构中使用到了哪些技术?
-
数据生成:MySQL
-
数据采集:Sqoop
-
数据存储:Hive
-
数据处理:HiveSQL
-
结果保存:MySQL
-
报表工具:FIneBI
-
可视化工具:Hue
-
任务流调度:Oozie
-
集群管理:Cloudera Manager
-
-
-
知识点11:平台搭建:命令行部署
-
目标:了解大数据平台命令行部署方式的优缺点
-
实施
-
过程
-
-
-
优点
-
灵活性和安全性、自定义的程度最高
-
-
缺点
-
如果集群的机器比较多,安装和管理就比较麻烦
-
如果有一台的配置改变了,其他的都要手动同步
-
-
小结
-
了解大数据平台命令行部署方式的优缺点
-
-
知识点12:平台搭建:集群管理工具部署
-
目标:掌握集群管理工具部署方式的原理及优缺点
-
实施
-
工具
-
Cloudera Manager:Cloudera 公司研发的产品
-
优点:可以快速部署和监控所有Cloudera的大数据产品,稳定
-
缺点:不支持未发布的产品
-
-
Ambari:Apache社区的开源集群管理工具
-
-
过程
-
step1:准备好所有软件安装包:Hadoop、Spark、Flink、Hbase……
-
step2:先手动安装CM【分布式架构】
-
主:CM-server
-
从:CM-agent
-
-
step3:可以通过CM来管理所有机器上所有软件的安装
-
提供一个管理界面:所有机器节点、所有软件
-
可以自由的选择每个软件安装在哪些机器上
-
-
-
原理
-
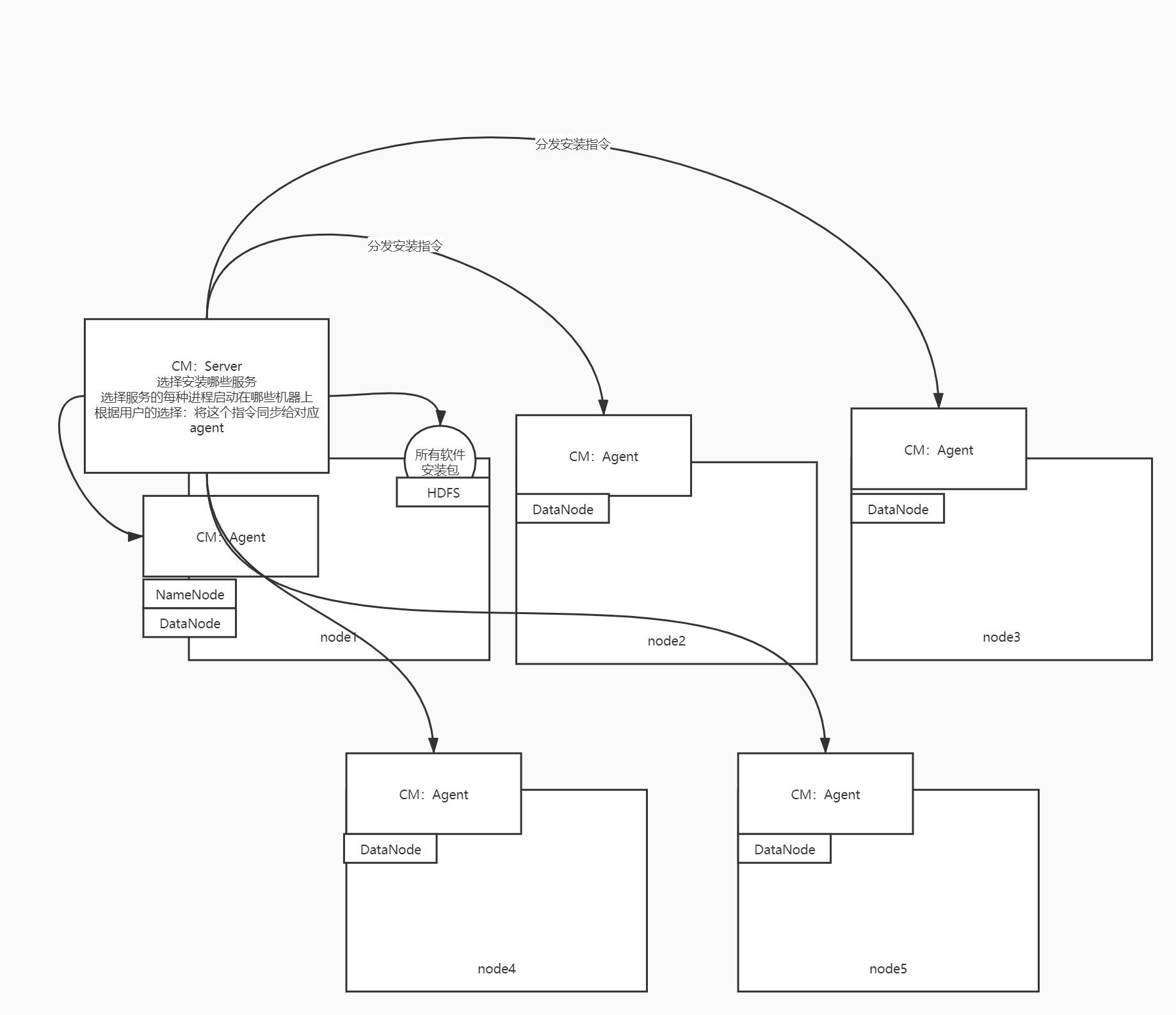
-
-
优点
-
由管理工具来实现批量化的同步操作:安装、配置
-
有监控管理:进程监控、资源监控
-
可以所有程序管理:不需要命令行,通过可视化界面来管理所有进程
-
-
缺点
-
Cloudera Manager:对很多非Cloudera公司的产品不兼容
-
Ambari:Bug比较多,兼容性较差
-
-
小结
-
了解常用的集群管理工具的基本原理
-
-
知识点13:Cloudera Manager平台使用
-
目标:了解CM平台的基本使用
-
实施
-
step1:启动虚拟机
-
Linux用户名:root 密码:123456
-
IP地址及主机名,配置Windows映射
192.168.88.150 hadoop01 192.168.88.151 hadoop02
-
-
-
step2:访问CM管理界面
-
注意:虚拟机启动以后,等待一会,才能访问,如果等待一会还不行,就再等一会
-
管理界面
hadoop01:7180 或者 192.168.88.150:7180 CM用户名:admin 密码:admin
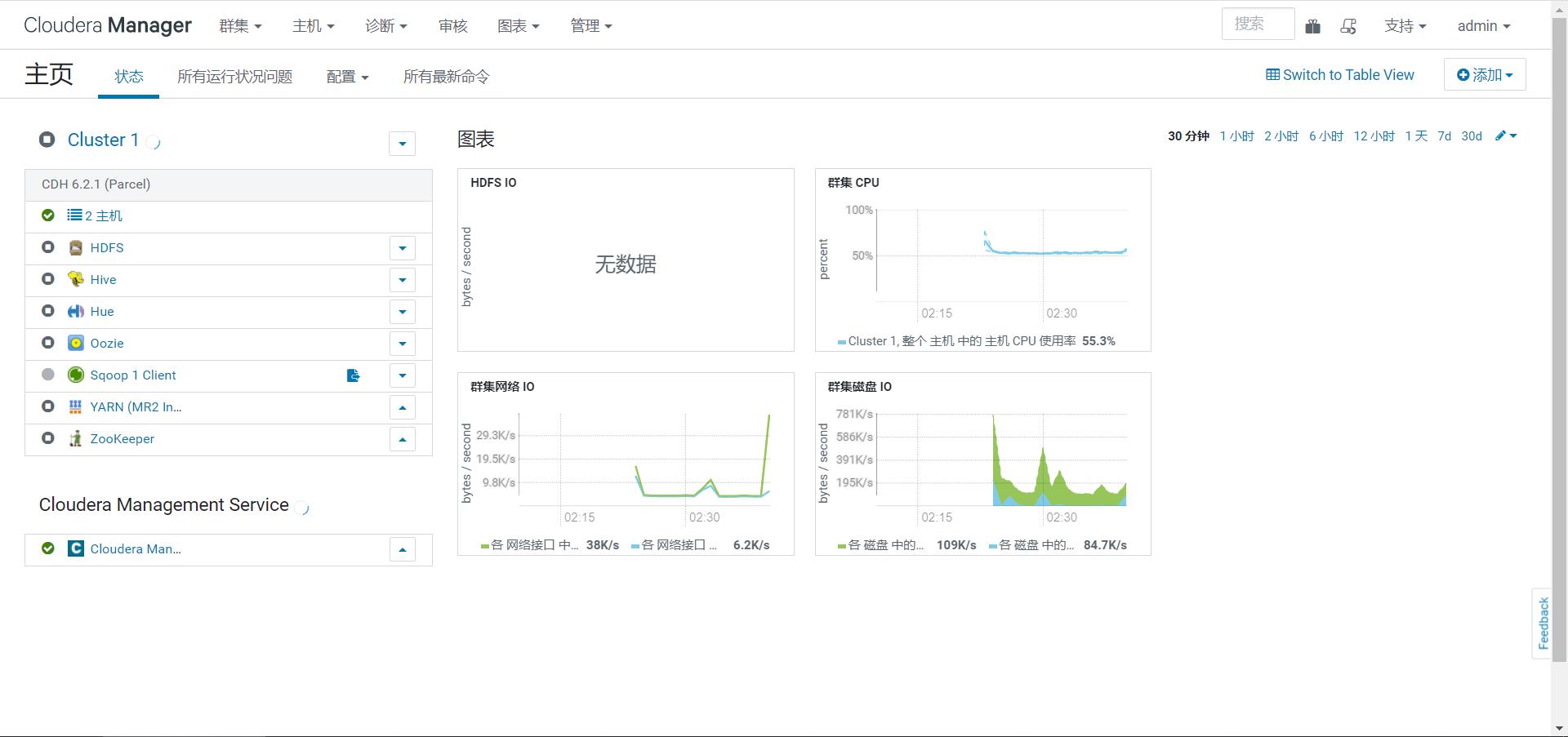
-
-
step3:管理主机,查看主机状态
-
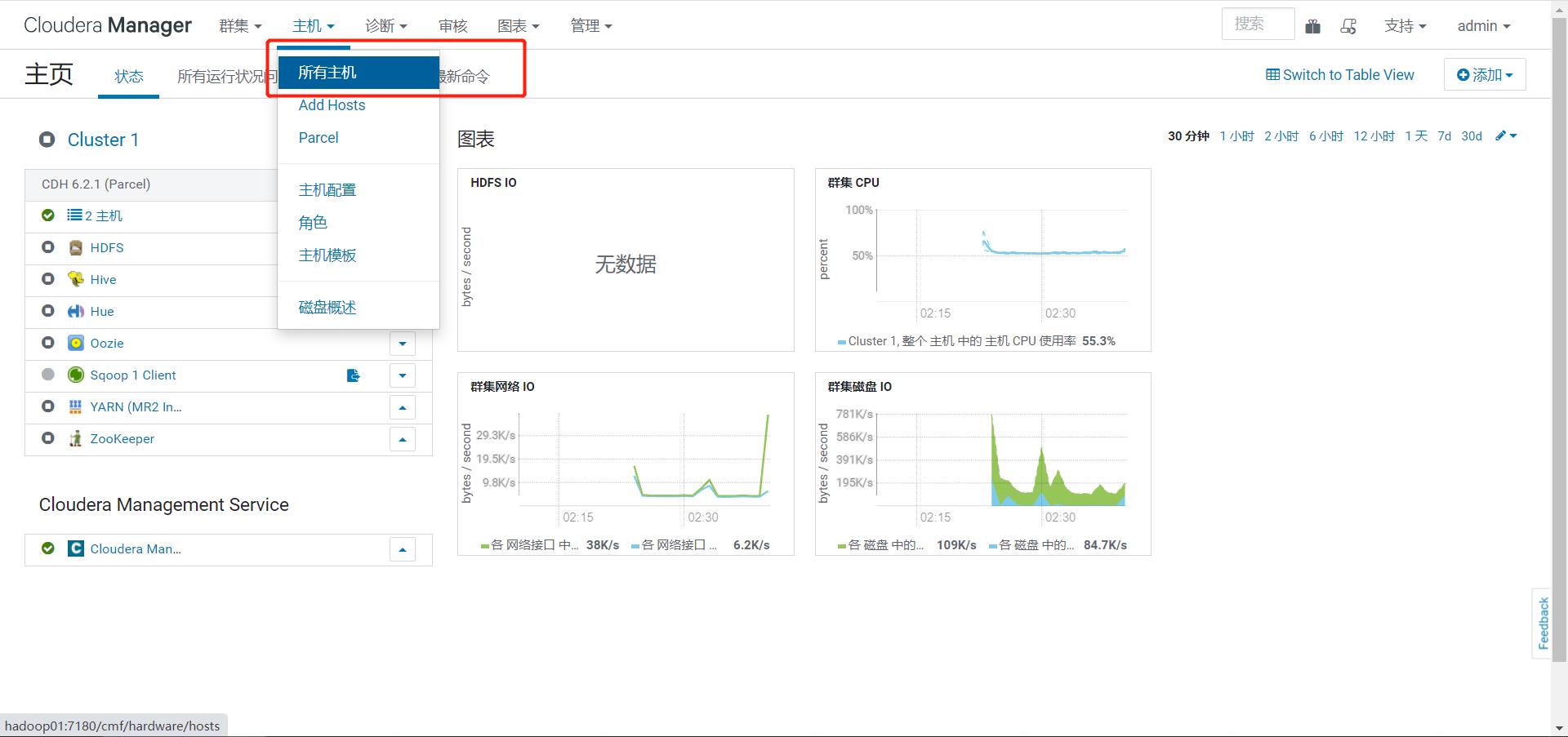
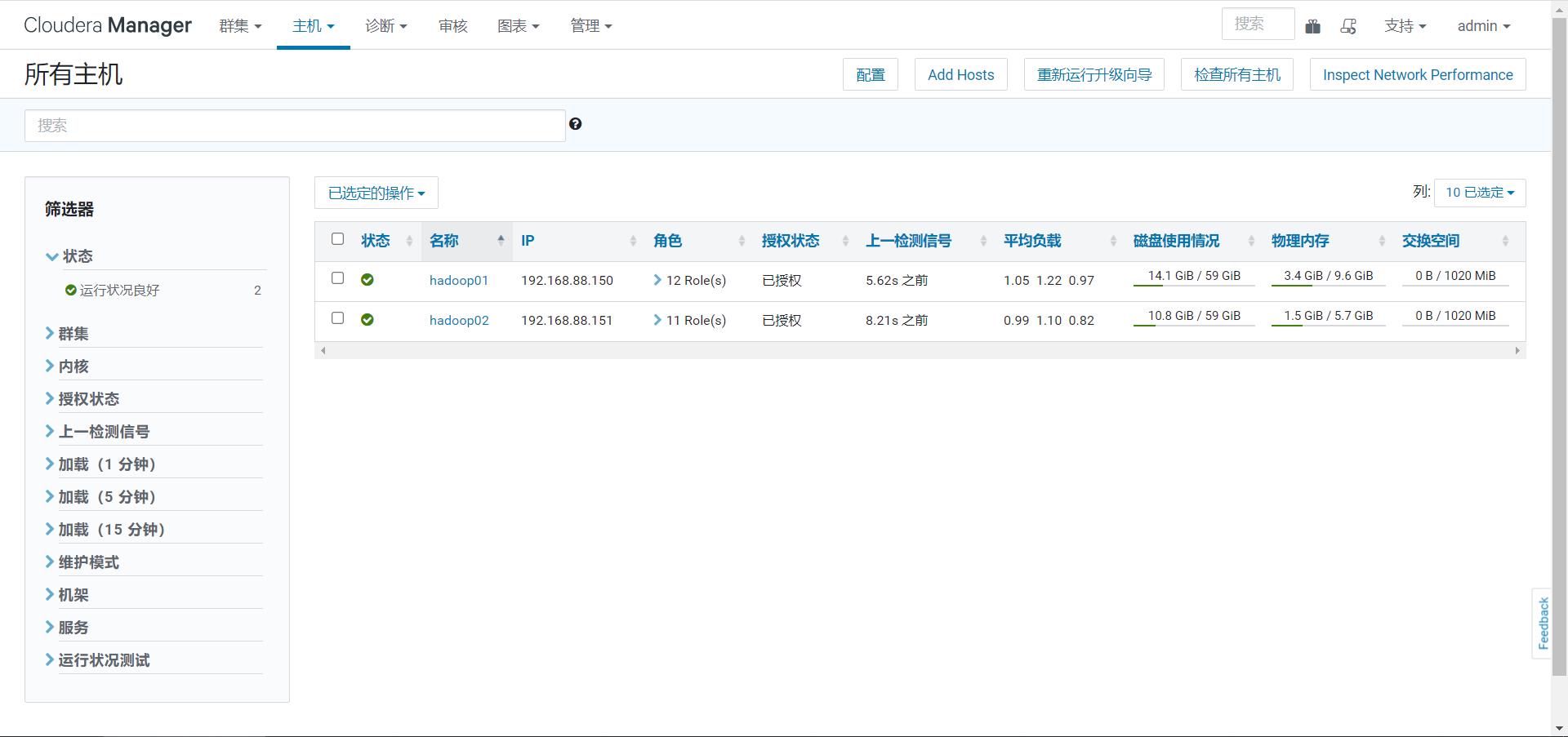
-
step4:启动管理服务
-
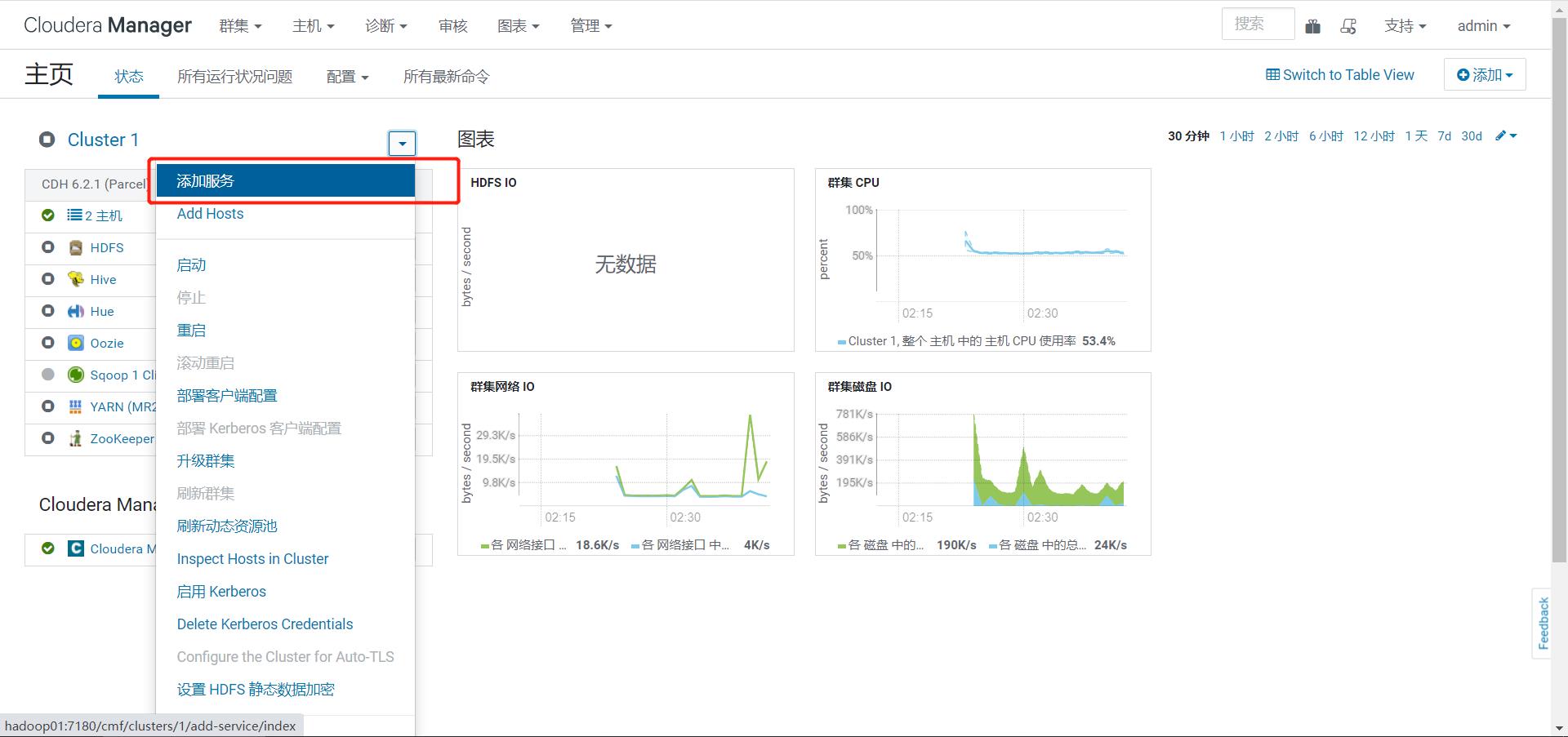
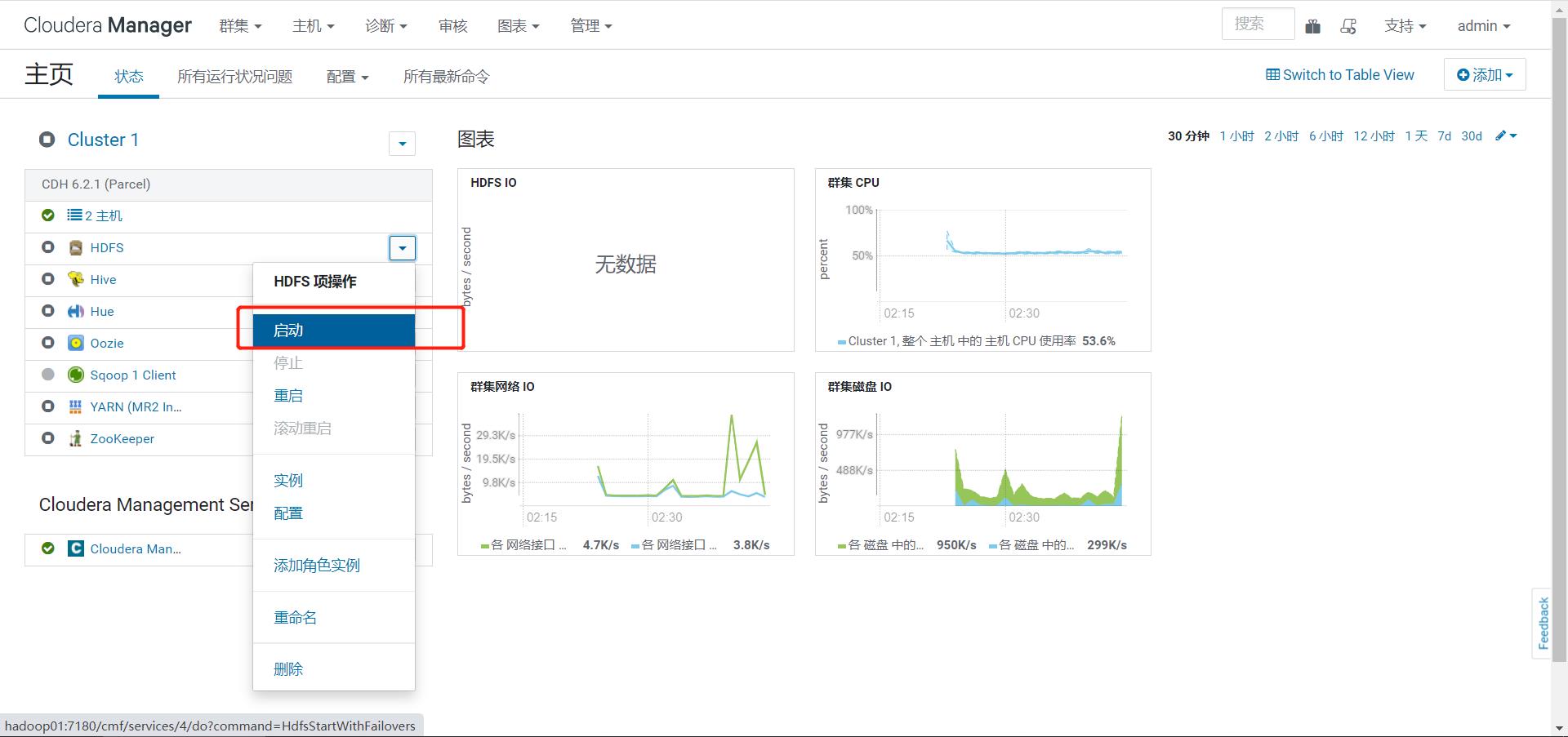
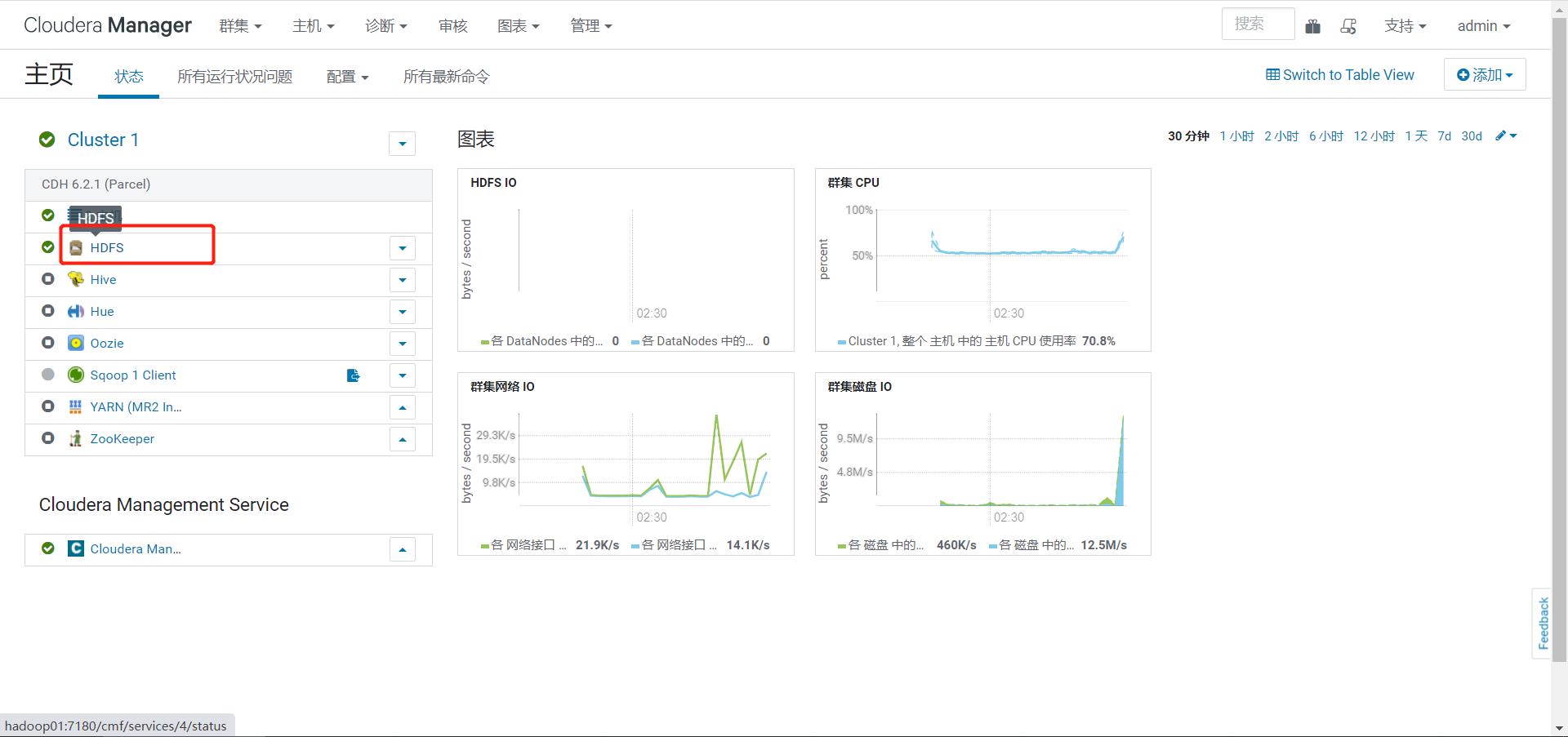
-
step5:查看服务状态、进程、配置
-
-
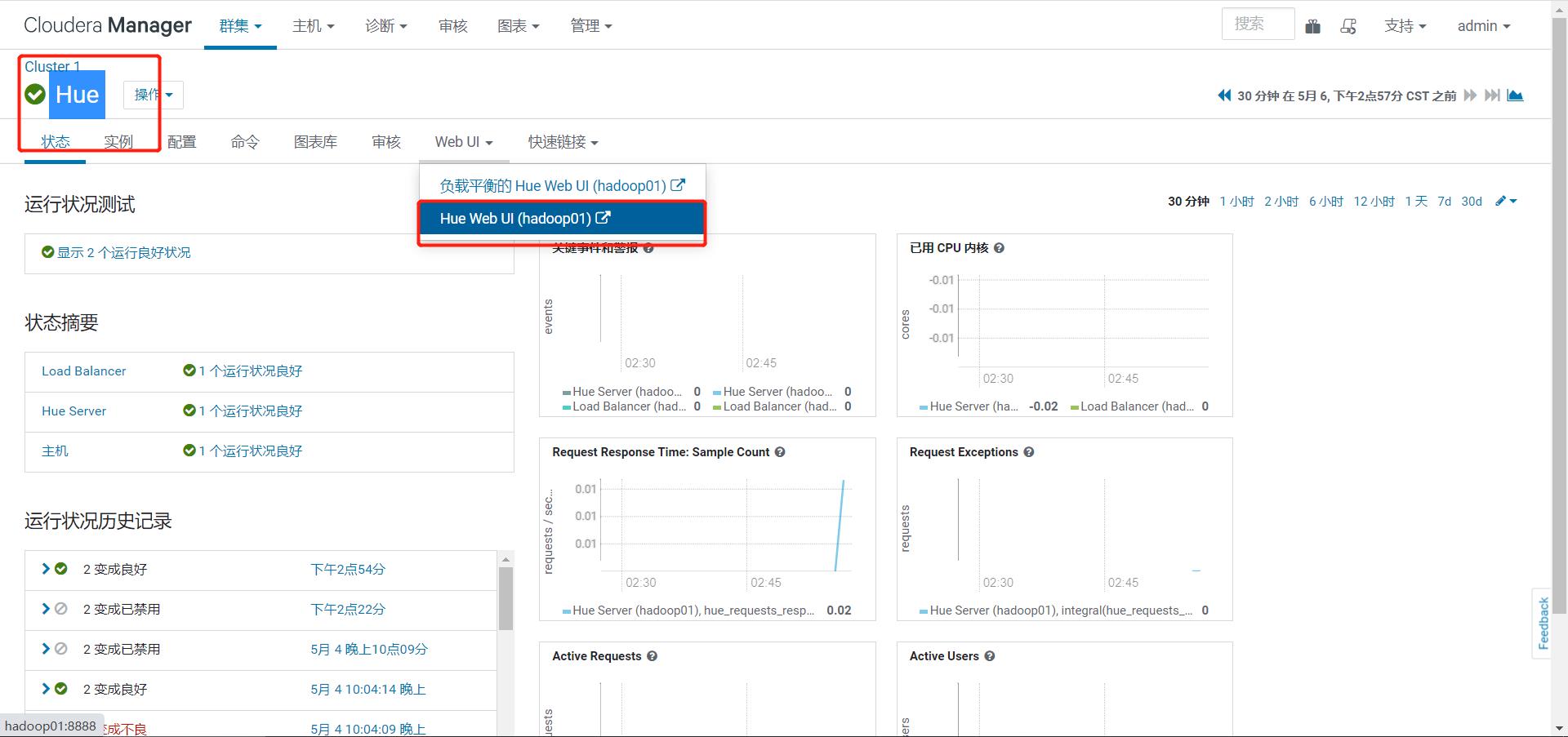
step6:使用Hue
Hue的用户名:hue Hue的密 码:hue
-
Hue是一个统一化的客户端工具
-
访问HDFS、YARN、Hive、MySQL
-
-
进入Hue
-
-
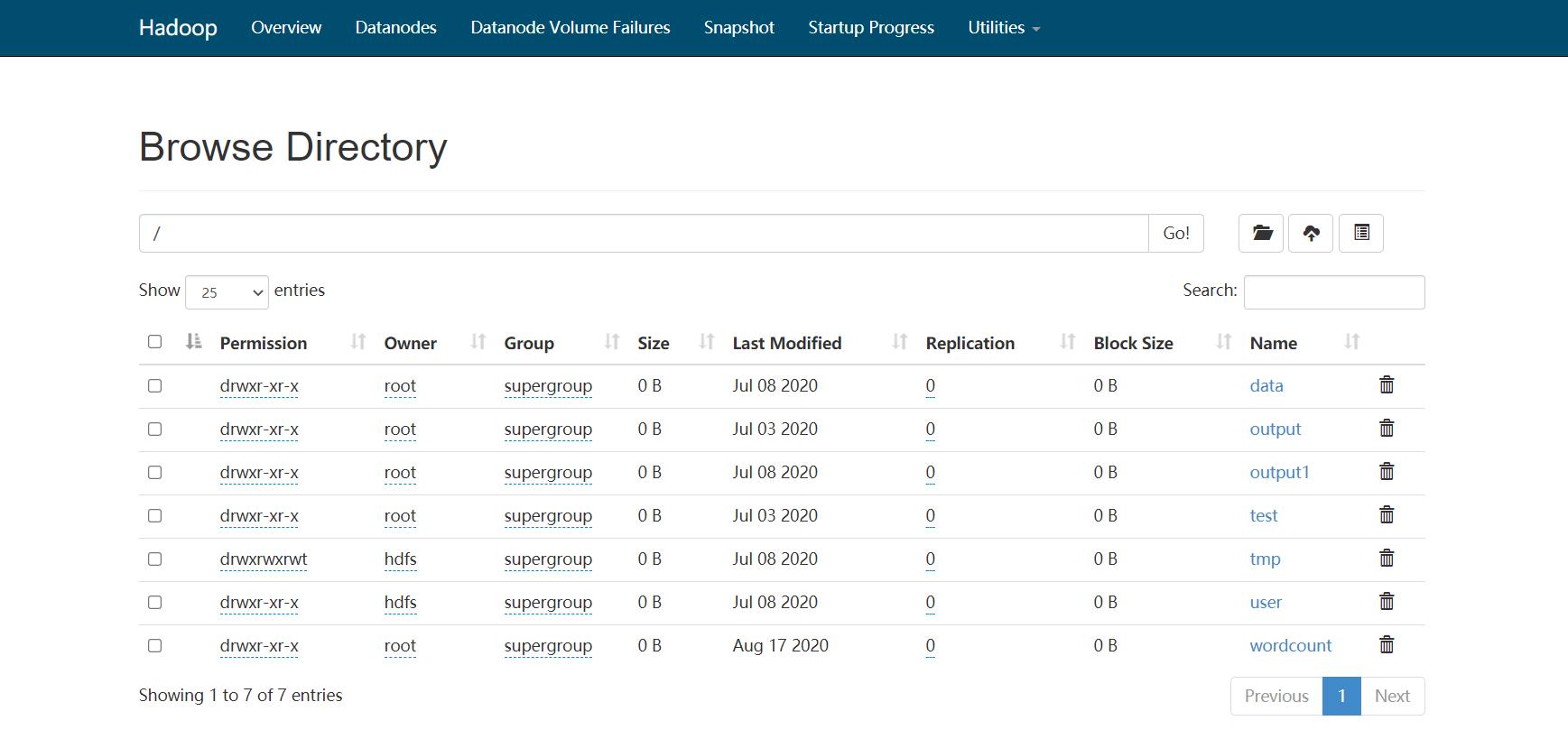
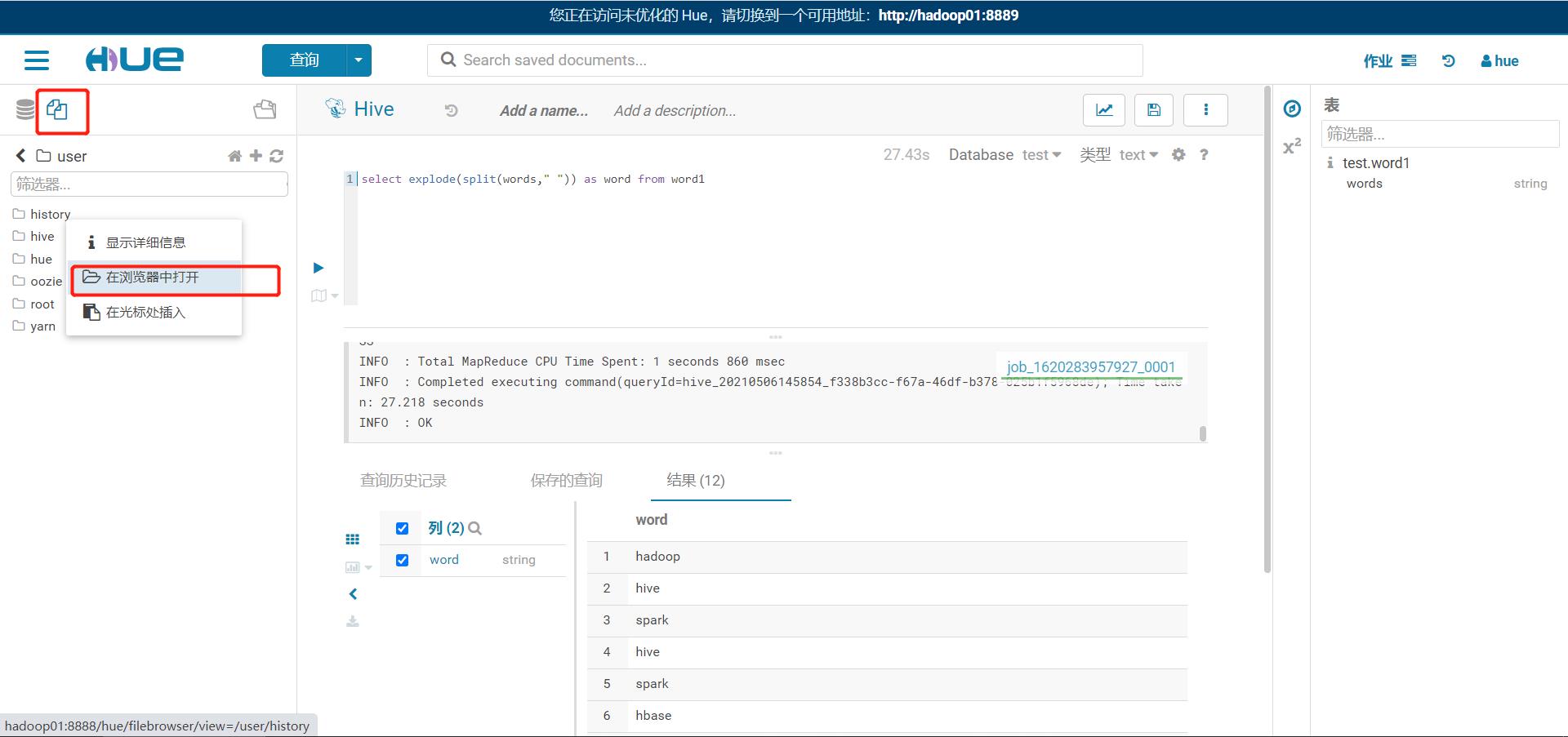
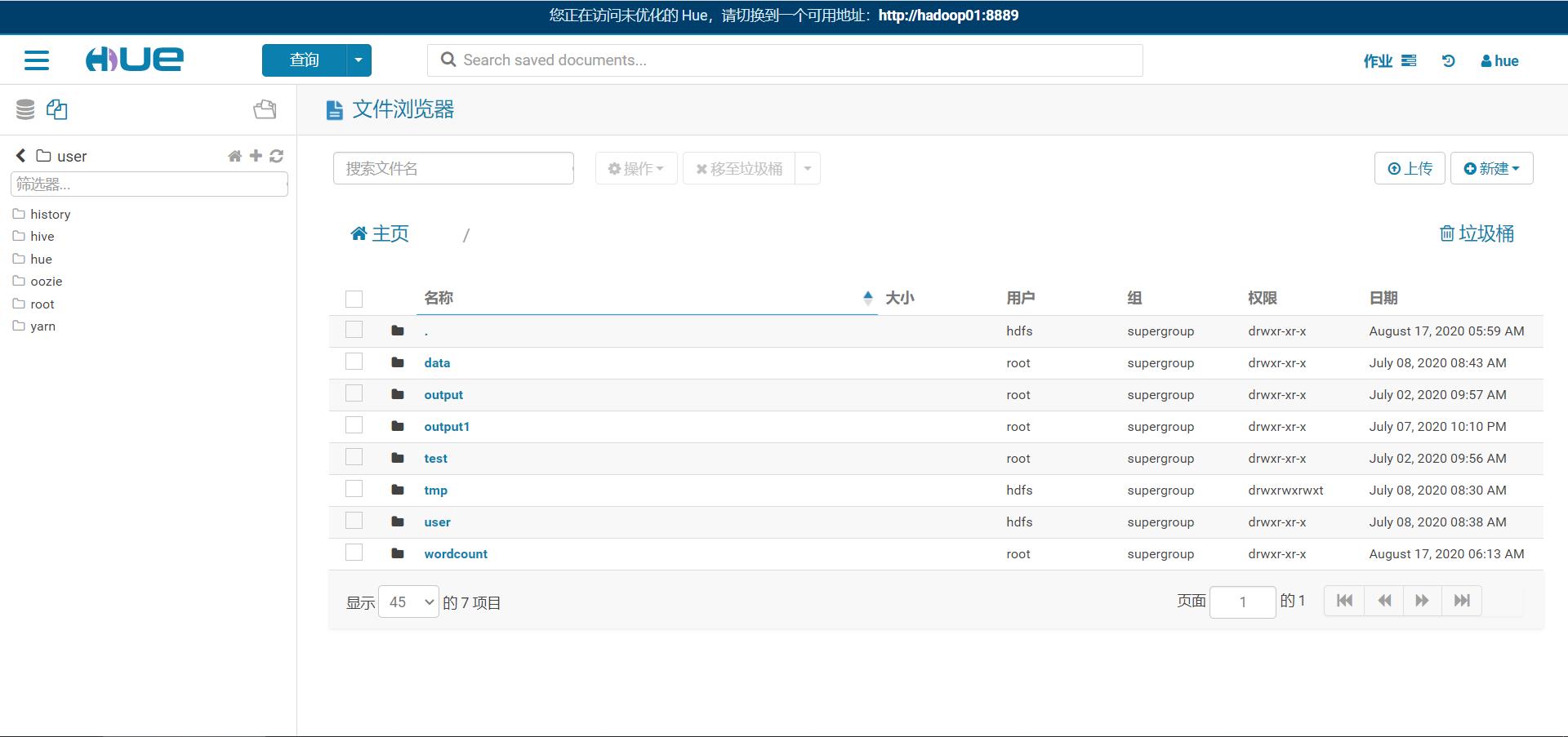
HDFS
-
-
YARN
-
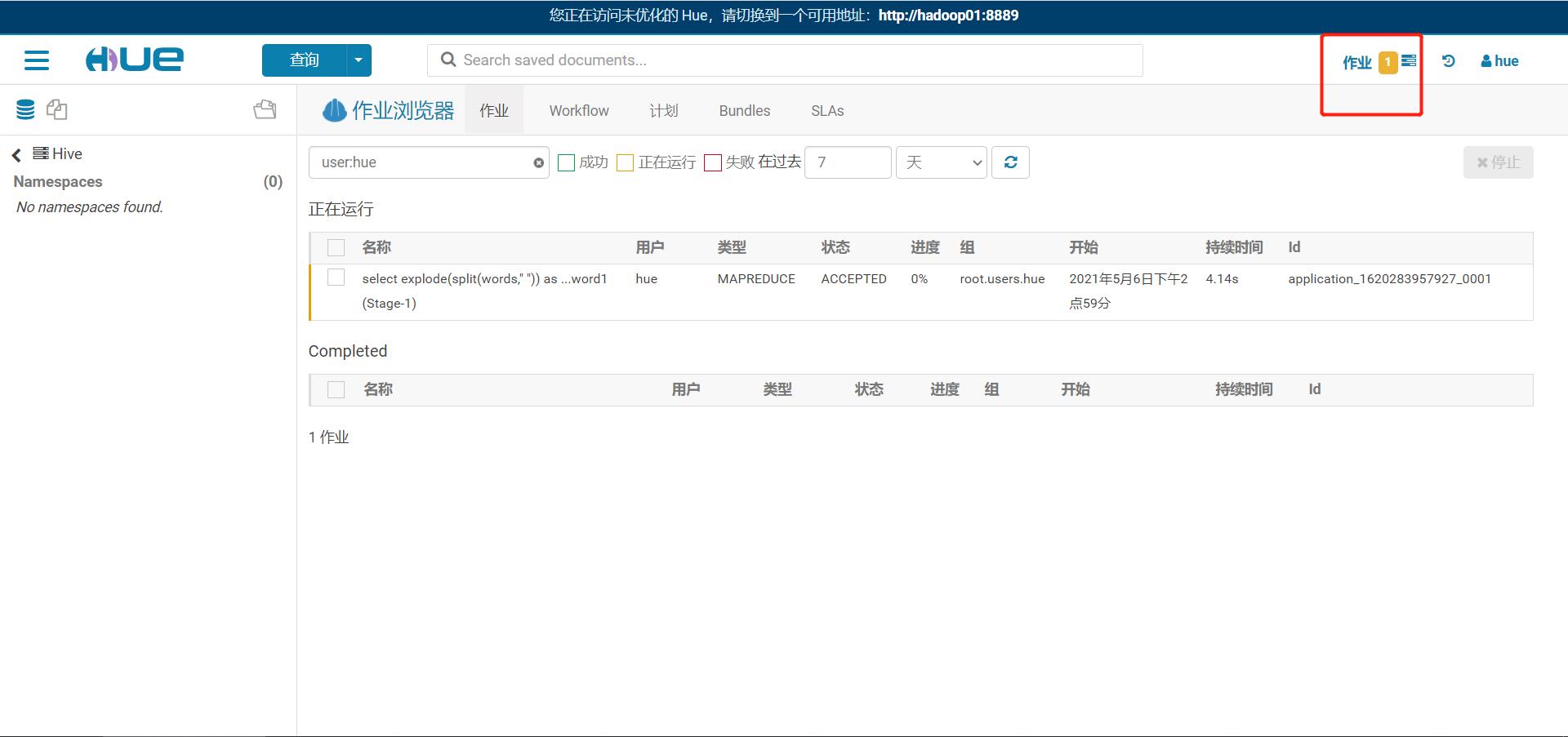
-
Hive
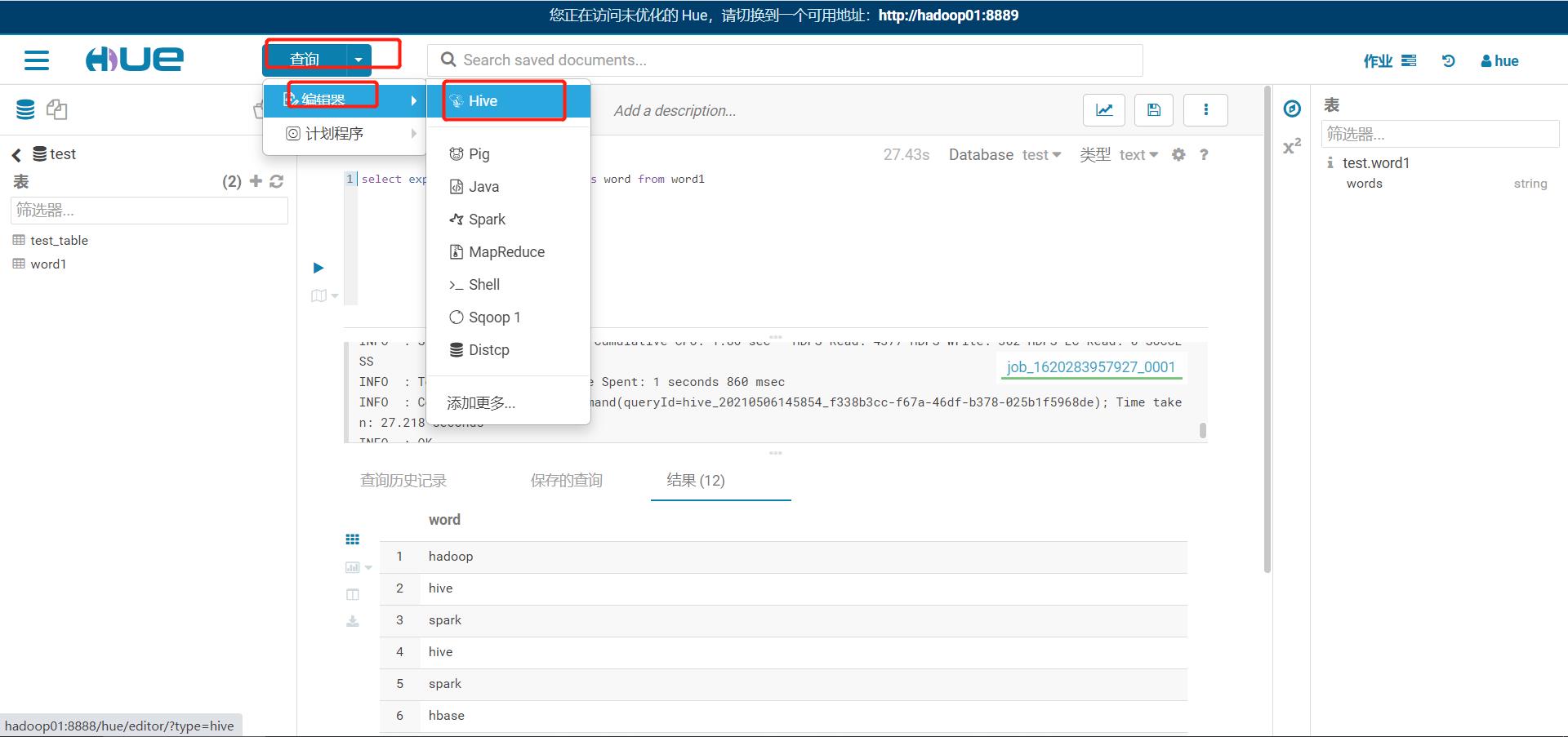
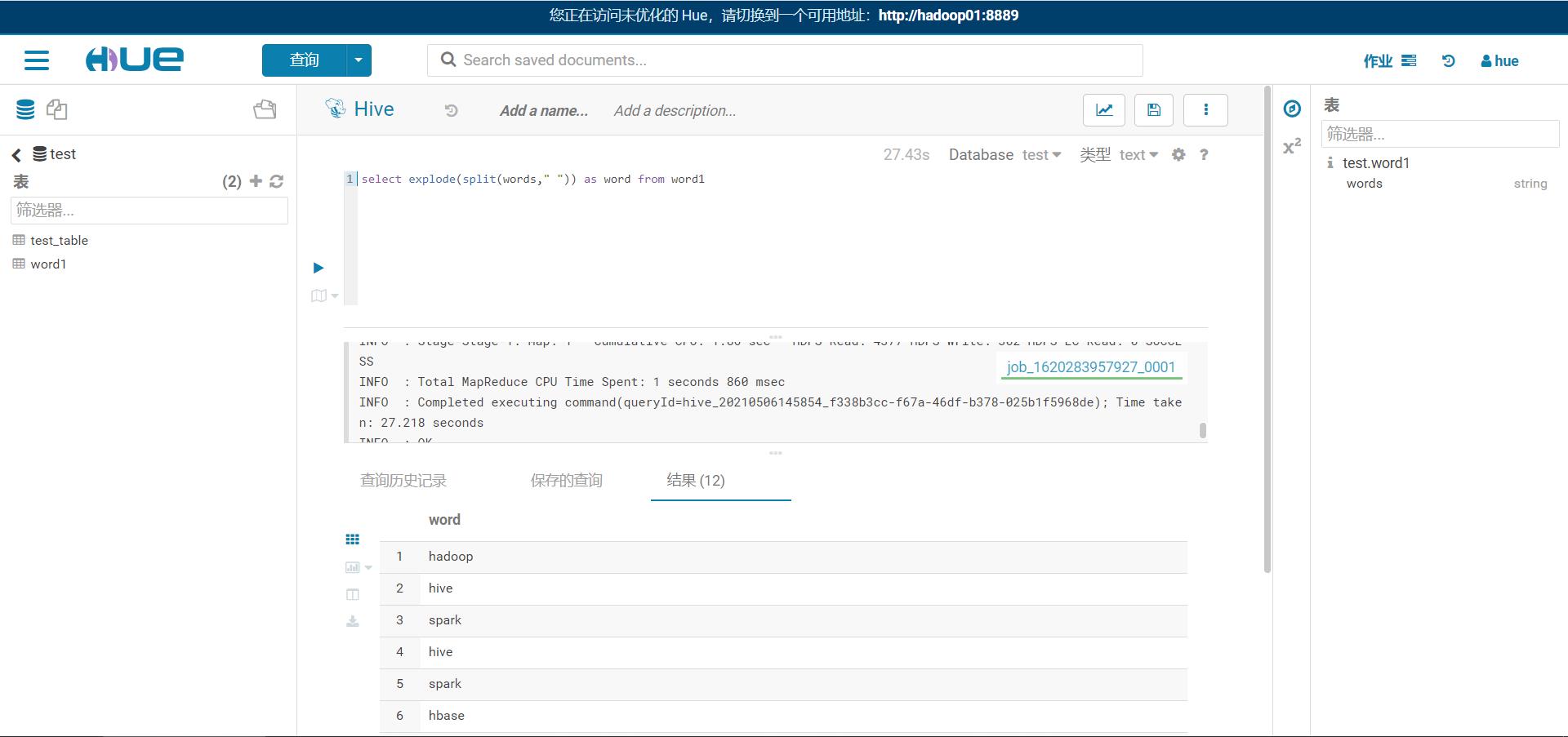
-
-
小结
-
了解CM平台的使用即可
-
-
知识点14:项目虚拟机环境
-
目标:实现配置启动项目使用的虚拟机环境
-
实施
-
step1:安装虚拟机
-
以第一台为例
-
找到.vmx结尾的文件,双击打开这个文件
-
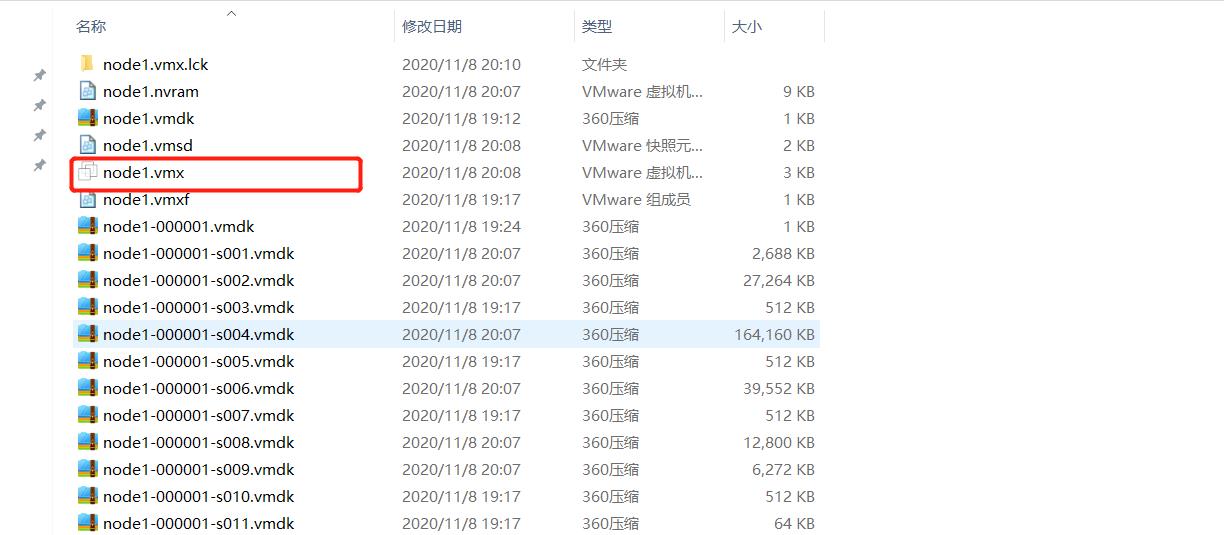
-
如果提示用哪个软件打开,选择VMware WorkStation打开
-
-
修改资源配置:自己合理的调整机器资源
-
16GB内存:6-4-6 或者 4-4-4
-
-
启动三台机器
-
-
-
-
step2:启动环境测试
-
构建CRT远程连接
三台机器的地址 192.168.88.221 node1 192.168.88.222 node2 192.168.88.223 node3 用户名和密码 root 123456
-
如果我的网段不是88,怎么办?
-
要么自己修改三台机器的IP地址和映射
-
/etc/sysconfig/network-scripts/ifcfg-ens33
-
/etc/hosts
-
-
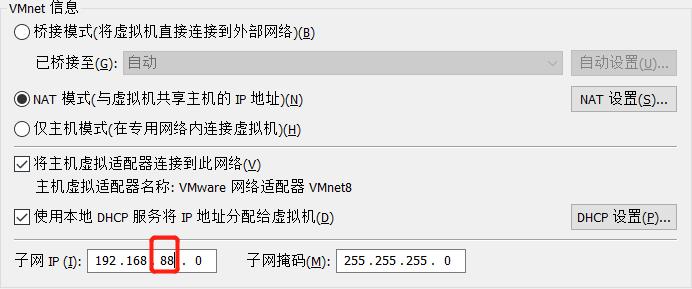
要么将VM网段修改为88
-
-
-
-
-
- 上不了外网:ping不通外网 - 解决:保证这几个地方是一致的 - VM的网关  - Linux机器中的网关地址是一致的  - 本地的虚拟网卡地址必须为.1 
-
每台机器安装软件
软件/机器 node1 node2 node3 Hadoop * * * Hive * Sqoop * Flume * Oozie * Hue * MySQL * -
- 启动Hue - 第一台机器:start-hue.sh - 关闭 - 第一台机器 - stop-dfs.sh - stop-oozie.sh - 第二台机器 - mr-jobhistory-daemon.sh stop historyserver - 第三台机器 - stop-yarn.sh
-
启动Hive
-
第三台机器
-
start-metastore.sh
-
start-hiveserver2.sh
-
start-beeline.sh
-
-
启动oozie
-
第一台机器:start-oozie.sh
-
启动Hive
-
第三台机器
-
start-metastore.sh
-
start-hiveserver2.sh
-
start-beeline.sh
-
-
启动oozie
-
第一台机器:start-oozie.sh
-
-
启动Hive
-
第三台机器
-
start-metastore.sh
-
start-hiveserver2.sh
-
start-beeline.sh
-
-
启动oozie
-
第一台机器:start-oozie.sh
-
-
-
 小结
小结-
实现启动测试即可
-
-
知识点15:Hue的使用
-
目标:了解Hue的基本使用
-
实施
-
启动
-
启动:start-hue.sh
-
访问:node1:8888
-
192.168.88.221:8888
-
-
登录
-
hue用户:root
-
hue密码:123456
-
-
-
-
-
HDFS
-
-
YARN
-
-
Hive
-
-
小结
-
了解Hue的基本使用
-
-
知识点16:数据生成:数据源
-
目标:了解业务数据与用户行为数据的生成
-
实施
-
业务数据
-
存储:数据库
-
目的:为了满足业务需求而实现的业务存储
-
例如:电商:注册登录、浏览商品、下订单、查询订单
-
常见:用户数据、商品数据、订单数据
-

-
-
-
用户行为数据
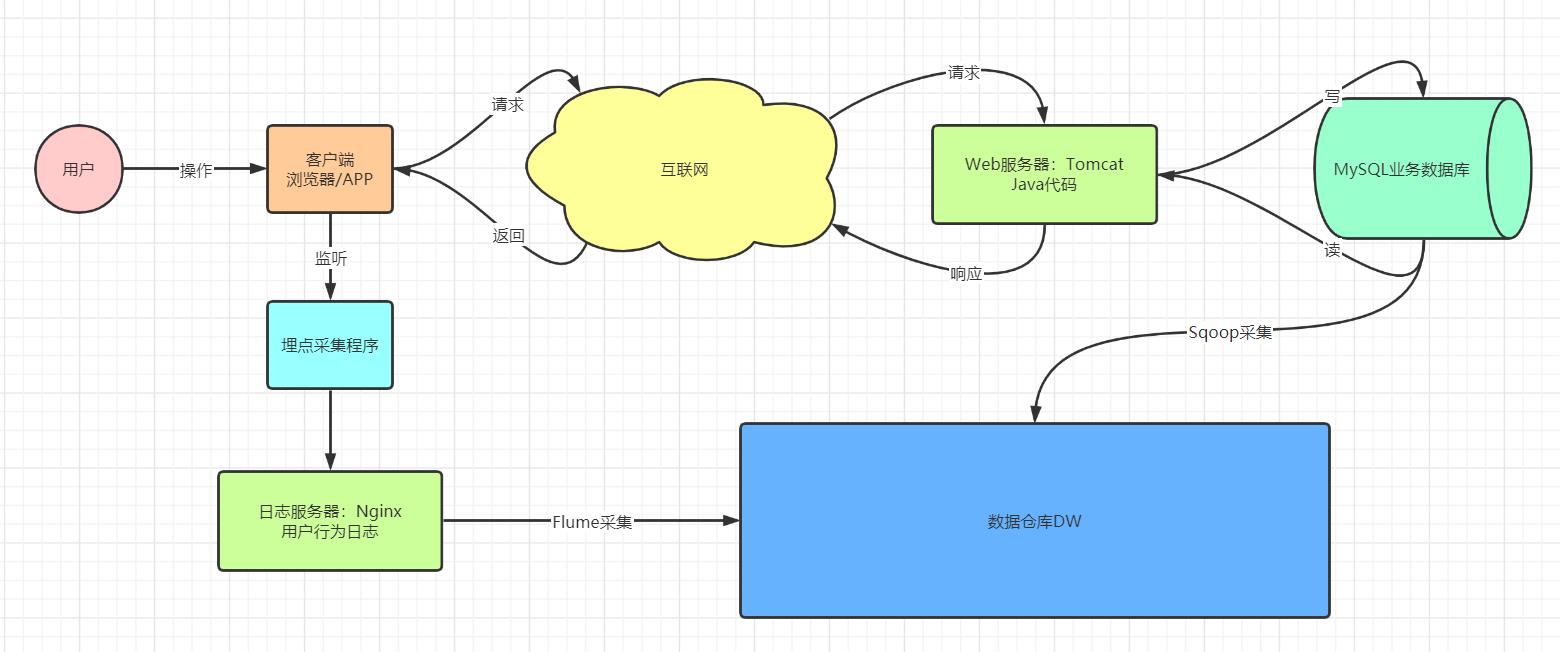
-
存储:日志文件
-
目的:用于记录用户在网站或者APP上的所有的操作行为
-
例如:用户浏览、搜索、支付
-
常见:用户操作的行为数据
-
-
-
小结
-
了解业务数据与用户行为数据的生成
-
-
知识点17:数据生成:用户行为数据演示
-
目标:了解用户行为数据的生成
-
实施
-
用户访问网页
-
-
-
埋点收集数据
-

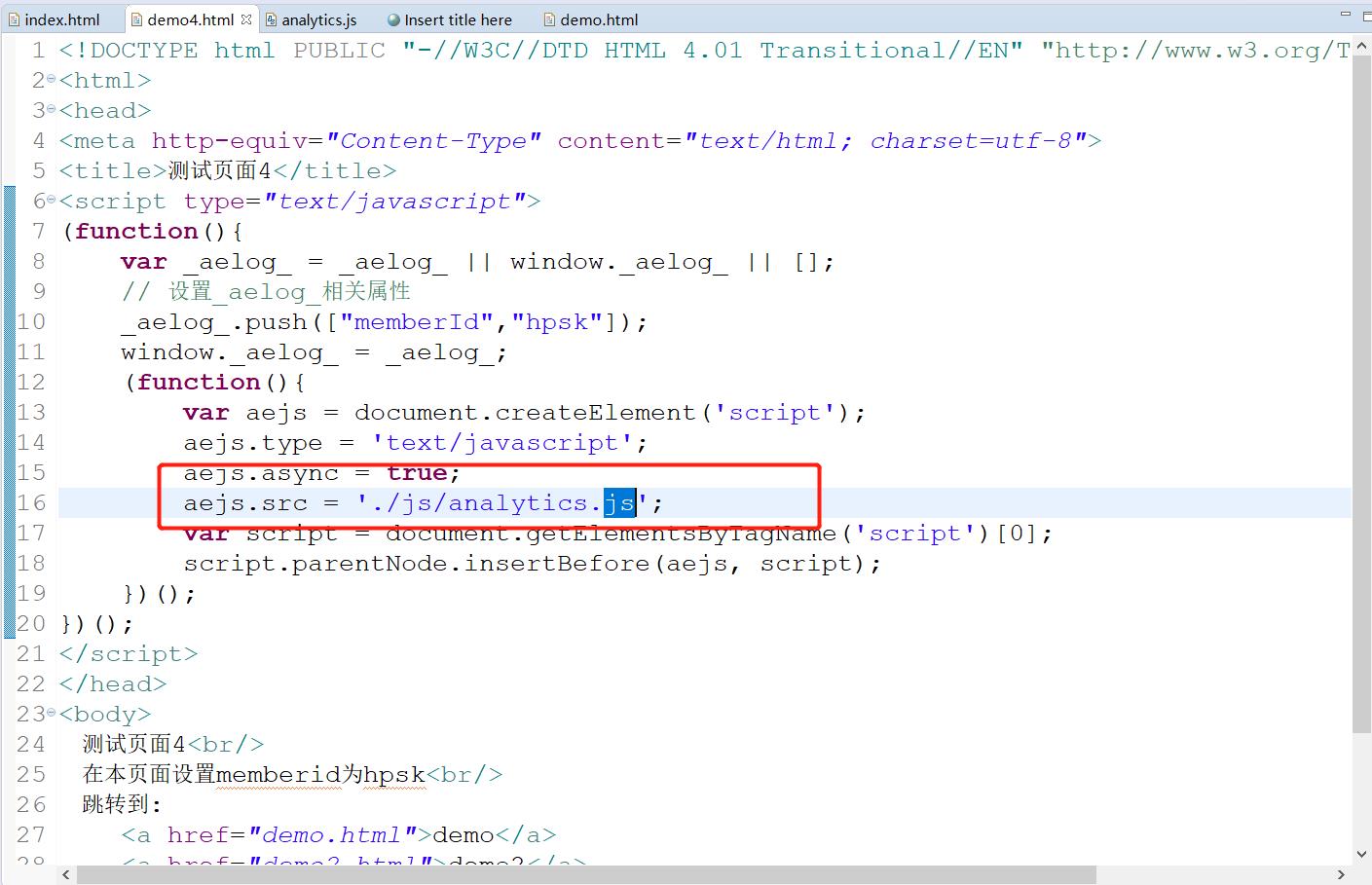
-
发送给日志服务器
-

-
日志服务器记录用户行为日志
-

-
小结
-
了解用户行为数据的生成
-
-
知识点18:数据生成:数据内容
-
目标:了解常见数据中的字段内容
-
实施
192.168.88.1^A1622813825.320^A192.168.88.130^A/hpsk.jpg?en=e_pv&p_url=http%3A%2F%2Flocalhost%3A8080%2Fhpsk_sdk%2Fdemo2.html&p_ref=http%3A%2F%2Flocalhost%3A8080%2Fhpsk_sdk%2Fdemo3.html&tt=%E6%B5%8B%E8%AF%95%E9%A1%B5%E9%9D%A22&ver=1&pl=website&sdk=js&u_ud=76F7E288-5249-477D-A9F6-474A0F8C354A&u_sd=674C0680-6F68-4D5A-AC1A-02F4E25C956F&c_time=1622882616691&l=zh-CN&b_iev=Mozilla%2F5.0%20(Windows%20NT%2010.0%3B%20Win64%3B%20x64)%20AppleWebKit%2F537.36%20(KHTML%2C%20like%20Gecko)%20Chrome%2F91.0.4472.77%20Safari%2F537.36&b_rst=1536*864
-
是不是所有的数据包含的字段是一样的?
-
不同的行为产生的数据字段是不一样
-
浏览:当前正在访问的页面、前一个页面、IP
-
支付:当前正在访问的页面、前一个页面、IP、订单id、订单总金额、支付总金额、支付方式……
-
-
基本的数据
-
客户端的IP地址:192.168.88.1
-
通过IP得到地区的信息,经纬度
-
通过IP地址来定位用户的家庭住址或者公司地址
-
-
服务端时间:1622813825.320
-
用户做这个操作的时间
-
-
请求服务端地址:192.168.88.130
-
URI:请求连接
-
请求页面地址:/hpsk.jpg
-
用户具体的行为:en=e_pv&
-
PV:访问页面的个数
select count(p_url) as pv
-
-
-
-
-
- UV:用户的个数 ``` select count(distinct u_ud) as uv ``` - 访问次数 ``` select u_ud,count(distinct u_sd) as vist_count from table group by u_ud ```
- …… - 当前正在访问的页面p_url=http%3A%2F%2Flocalhost%3A8080%2Fhpsk_sdk%2Fdemo2.html - 前一个页面p_ref=http%3A%2F%2Flocalhost%3A8080%2Fhpsk_sdk%2Fdemo3.html - 访问页面的标题:tt=%E6%B5%8B%E8%AF%95%E9%A1%B5%E9%9D%A22 - 客户端版本:ver=1 - 平台信息:pl=website& - 埋点采集的类型:sdk=js& - 访客id:u_ud=76F7E288-5249-477D-A9F6-474A0F8C354A& - 会话ID:u_sd=674C0680-6F68-4D5A-AC1A-02F4E25C956F& - 客户端时间:c_time=1622882616691& - 客户端语言:l=zh-CN& - 客户端版本:一般用于提取浏览器的信息和操作系统信息b_iev=Mozilla%2F5.0%20(Windows%20NT%2010.0%3B%20Win64%3B%20x64)%20AppleWebKit%2F537.36%20(KHTML%2C%20like%20Gecko)%20Chrome%2F91.0.4472.77%20Safari%2F537.36& - 分辨率信息:b_rst=1536*864
-
小结
-
了解常见数据中的字段内容
-
-
商业化大数据分析平台
-
百度统计
-
友盟
-
易分析
-
神策
-
-
-
以上是关于项目需求与技术架构的主要内容,如果未能解决你的问题,请参考以下文章