信号处理基于小波变换的语音增强matlab源码
Posted MatlabQQ1575304183
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了信号处理基于小波变换的语音增强matlab源码相关的知识,希望对你有一定的参考价值。
一、简介
语音通信是人类传播信息,进行交流时使用最多、最自然、最基本的一种手段。而这种通信中的信息载体—语音信号却是一种时变的、非平稳的信号,只有在很短的一段时间内(通常为10~30ms)才被认为是平稳的。在语音的产生、处理和传输过程中,不可避免地会受到环境噪声的干扰,使得语音信号处理系统,如语音编码和语音识别系统的性能大大降低。为了改善语音质量,提高语音的可懂度,人们根据语音和噪声的特点,采取各种语音增强方法抑制背景噪声。但是语音信号去噪是一个很复杂的问题,必须考虑语音本身的特点、千变万化的噪声的特点、人耳对语音的感知特性以及大脑如何处理信号等问题,所以,语音增强技术的研究是语音信号处理中永恒的课题。
尽管语音信号的去噪理论和方法目前还远远没有解决,但是40多年来,研究者们针对不同的噪声、不同的应用对加性噪声提出了很多方法。流行的语音增强方法有维纳滤波、卡尔曼滤波、谱减法和自适应滤波等。其中维纳滤波是在平稳条件下的基于最小均方误差的最优估计,但对语音这种非平稳信号不是很适合;卡尔曼滤波克服了维纳滤波的平稳条件,在非平稳条件下也可保证最小均方误差最优,但是仅适用于清音;谱减法是常用的一种方法,但是在信噪比低的情况下,对语音的可位度和自然度损害较大,并且重建语音中产生了音乐噪声;自适应滤波是效果最好的一种语音增强方法,但是由于需要一个在实际环境中很难获得的参考噪声源,实际工作中并不好用,而且和谱减法一样伴有音乐噪声。同时,以上各种方法在进行语音增强时,都需要知道噪声的一些特征或统计特性,而在没有噪声先验知识的情况下,从带噪语音信号中提取语音信号是比较困难的。
小波变换是近10年来迅速发展起来的一种时频局部分析方法,它克服了短时傅里叶变换固定分辨率的缺点,能够将信号在多尺度多分辨率上进行小波分解,各尺度上分解得到的小波系数代表信号在不同分辨率上的信息。同时小波变换与人耳的听觉特性非常相似,便于研究者利用人耳的听觉特性,是分析语音这种非平稳信号的有力工具,所以近年来很多研究者都利用小波变换来处理语音信号。小波变换法去噪的原理是:语音信号的能量集中在低频段,而噪声能量则主要集中在高频段,这样就可将噪声小波系数占主要成分的那些尺度上的噪声小波分量置零或给予很小的权重,然后用处理后的小波系数重构恢复信号。同时,随着小波变换理论的发展,小波变换去噪不断丰富,并且取得了良好的效果,如1992年Mallat提出了利用小波变换模极大值去噪,Donobo在1995年提出了非线性小波变换阈值去噪,这种方法使得小波去噪得到广乏运用,吸引了众多的研究者。
1、小波分解
在语音增强中,分解信号的目的是把信号的能量集中到某些频带的少数系数上,便于有效抑制噪声。在采用小波变换的方法中,研究者们一般采用正交小波,因为正交小波变换能最大程度地去除原信号中的相关性,将其能量集中在少数稀疏的、幅度相对较大的小波系数上。小波分解只是将每一级的低频成分逐级往下分解,对于高频成分不再作分解。这种分解方式不能满足既想得到好的时间分辨率又想拥有好的频率分辨率的场合,于是研究者们开始采用正交小波包来分解语音信号,这样便于利用人耳听觉掩蔽效应来进行语音增强。如有文献利用小波包算法有灵活的时频分析能力以及能较好地利用人耳基底膜的频率分析特性,按照Bark刻度与频率刻度之间的转换关系,采用固定小波包分解方式把0~4000 Hz频带分成了52个频段,对应18个Bark刻度,从而在单声道条件下,其语音增强效果比传统的谱减法有更高的清晰度和可懂度。而有文献在利用小波包分解时,采用5级分解,得到17个频带与Bark刻度对应,有文献采用6级分解,得到24个临界带。它们的目的都是为了充分地利用人耳的听觉特性,在进行语音增强时不需要把噪声完全抑制,只要残留的噪声不被感知即可,以便在去噪的同时减少不必要的语音失真。
通常研究者在采用小波包分解时一般采用固定的分解级数,且一般在5级以上。大量的实验表明,小波分解级数对算法的降噪效果影响很大,分解级数过多,会造成信号的某些重要的局部特性丢失,信噪比反而下降,且运算量大,延时大;分解级数太小,则噪声对应的模极大值不能足够衰减,信号和噪声不能很好地区分,使得降噪效果不理想,信噪比提高有限,因此采用固定小波分解级数在很大程度上限制了算法的降噪性能.为此,有文献提出了一种新颖的分解级数自适应选择方法,该方法有效提高了小波闽值降噪算法的性能,但进一步引人时延和计算量。
由于第一代小波存在时延大、算法相对复杂、对内存的需求大等缺点,文献采用了自适应提升小波进行语音增强。实验表明该方法在算法复杂度降低的同时,能大大消除噪声且保持了语音良好的可懂度。
由小波理论可知:正交小波分解在分解过程中,不能保证中间过程的线性相位,这不利于语音信号的处理,而双正交小波分解则能够保证中间过程的相位不发生失真。为此,本文利用双正交小波包进行语音去噪,取得了不错的效果.同时,由于小波分解最终依赖滤波器组实现,不可避免地带来时延,限制了小波理论的应用范围。为此,有必要设计低时延的滤波器来实现小波分解,为小波理论的进一步应用打下坚实的基础。
总之,在采用小波分解的研究过程中,从最初的小波分解发展到小波包分解、利用人耳听觉特性进行小波包分解、自适应地选择分解级数、提升小波分解、为保证线性相位采用双正交小波包分解以及设计低时延的滤波器,都是为后续的处理工作做出充分的准备,以便更好地提高去噪性能。
2、模极大值去噪法
模极大值去噪的原理是:语音信号的模极大值随着尺度的增大而增大或不变,而噪声的模极大值却随着尺度的增大而减小。人们根据此特性,去除噪声的模极大值,保留语音的模极大值,然后利用保留的模极大值重构语音,达到去除噪声的目的。模极大值去噪的具体步骤是:对含噪语音进行离散二进小波变换,分解尺度一般为4或5;求每个尺度上小波系数对应的模极大值点;在最大尺度上,选取阑值,则模极大值小于该闷值的点被置零,反之不变;搜索传播点,保留语音产生的模极大值点,去除噪声产生的模极大值点;利用各尺度保留的模极大值点,重构去噪语音。
基于小波变换模极大值的去噪方法虽然具有很好的理论基础,但是在实际应用中存在很多影响计算精度的因素,去噪的效果并不满意。有文献利用小波变换频响特性的插值法重建低尺度上的小波变换模极大值,最后根据压缩映射原理构造解析形式的迭代投影算子方法重构信号,但是这种方法提高的性能有限。同时,该方法在具体操作上有许多待解决的技术间题,如分解尺度取多大适合;重构只用有限个模极大值点,这样重构的信号肯定与原始信号有误差,那么如何构造与原始信号相似的小波系数等,这些都限制了该方法的进一步应用。目前研究这种方法的文献很少。
3、相关去噪法
相关性去噪法的原理是:语音信号的小波系数在各尺度间具有较强的相关性,而噪声的小波系数在各尺度间没有明显的相关性。相关性去噪法的主要步骤是:计算相邻尺度同一空间位置小波系数的相关性CWj,k,CWj,k=wj,kwj+1,k,j代表尺度,k代表位置,wj,k表示第j尺度的第k个小波系数。wj+1,k表示第j+1尺度的第k个小波系数。比较相关性与小波系数的大小,如果相关性大,则说明是信号,小波系数保留;反之,认为是噪声,该小波系数置零。利用处理后的小波系数重构去噪信号。
该方法中,相关性的计算增强了信号的边缘特性,更便于提取信号的特征。有文献利用该方法进行去噪取得了较好的效果。
不过在该方法中,一旦小波分解的过程有偏差,则计算出的相关性不能准确代表k点的真实相关性,依赖相关性去噪法的性能则降低。有文献介绍了一种区域相关的去噪方法,较好解决了以上问题。该方法主要考虑了k点处的小波系数,也考虑了k点附近的小波系数,从而减弱了小波系数偏差带来的影响。但是该方法每一个点都要计算相关系数,计算相对复杂,并没有引起广泛的研究。
4、阈值去噪法
1995年,阂值去噪法首次由Donob。提出,他提出的非线性小波变换阈值去噪[Ca)使得小波去噪得到深人研究和广泛应用。
阈值去噪法的理论依据是:噪声的小波系数和有用信号的小波系数在幅值上存在不同的表现形式,在低频段,语音信号的小波系数值大于噪声的小波系数值,在高频段,反之。这样对各层小波系数设定一个适当的闽值将信号与噪声分开。该算法的具体步骤为:对含噪信号进行小波变换;对小波系数进行非线性闷值处理;利用处理后的小波系数重构去噪信号。
在小波阈值去噪方法中,有2个关键的问题:(1)阈值施加方法;(2)对阈值的具体估计。这两个问题直接影响着去噪的性能。
5、混合去噪法
纯粹的小波去噪方法尽管能取得较好的效果,但是在低信噪比和有色噪声的情况下,语音的可佳度并不是很高。为了能利用小波变换的优点以及更好地去除噪声,现在的研究趋势是把各种小波方法相融合或小波方法与其他方法相结合。有文献为了消除音乐噪声,提出了基于小波阈值的低方差谱估计方法,实验表明多带谱估计结合小波阈值能够抑制音乐噪声,增强语音的质量比谱减法好。不过这种方法对有色噪声的处理效果次于高斯白噪声。有文献在小波域对低尺度小波系数采用自适应滤波,对高尺度系数采用谱减法或维纳滤波等方法。
实验表明这种方法结合了小波去噪、自适应滤波和谱减法的优点,对语音的损害小于阈值去噪,同时也减少了音乐噪声,不过引人了计算复杂度和时延。为了防止高频中的清音作为噪声被去除,有文献首先根据小波系数的能量进行清浊判断,如果是清音,则只对最小尺度的低频成分去噪,以便保留清音,否则对所有尺度去噪,从而在抑制噪声的同时尽可能地保留清音信息,提高增强语音自然度,降低增强语音的失真度,但是在有色噪声的情况下,噪声去得不干净。有文献采用的语音增强方法,添加的步骤是:含噪语音首先由小波变换分解成若干临界带,然后由前向反馈子系统提取一系列分量,利用平均归一化时频能量来引导前向反馈子系统阈值,抑制稳定噪声,同时,利用改进的小波阈值抑制非稳定噪声和有色噪声,最后利用固定的软阈值对清音进行语音增强。该方法结合人工神经网络的去噪方法已经被成功用在语音识别领域,只不过时延大而不能用在实时处理中。有文献在小波域引人卡尔曼滤波,成功地把卡尔曼滤波的优点和小波分解能够模拟人耳感知特性的优点结合起来,在一定程度上能抑制非稳定噪声和有色噪声,并且语音有很少的失真。有文献在小波域引人谱减法来计算掩蔽阈值和最优加权系数,引人基于噪声估计的参数法对清音进行增强,取得了很好的去除多种噪声的性能,只是算法更加复杂。考虑到虽然上述方法能够在一定程度上去除稳定、非稳定、白噪声和有色噪声,但是当信噪比很低的情况下,去噪效果欠佳,而且仍然含有少量音乐噪声,有文献提出了利用仿生小波变换来对语音进行分解的方法。该仿生小波变换相对于小波变换的优点在于它在时频域的尺度不仅可以根据信号的频率进行调节,而且可以随信号的瞬时幅度以及一阶徽分系数自适应调节。实验表明,该方法能更好地保留原始纯净语音。如果能够在仿生小波的基础上应用以上的各种方法,应该能得到更好的效果。
二、源代码
clear all;
%读入语音文件%
[speech,fs,nbits]=wavread('1.wav');
%定义参数%
winsize=256;
n=0.04;
size=length(speech);
numofwin=floor(size/winsize);
ham=hamming(winsize)';
hamwin=zeros(1,size);
enhanced=zeros(1,size);
x=speech'+n* randn(1,size);
noisy=n* randn(1,winsize);
N=fft(noisy);
nmag=abs(N);
%分帧%
for q=1:2*numofwin-1
frame=x(1+(q-1)* winsize/2:winsize+(q-1)* winsize/2);
hamwin(1+(q-1)* winsize/2:winsize+(q-1)* winsize/2)=...
hamwin(1+(q-1)* winsize/2:winsize+(q-1)* winsize/2)+ham;
y=fft(frame.* ham);
mag=abs(y);
phase=angle(y);
%幅度谱减%
for i=1:winsize
if mag(i)- nmag(i)>0
clean(i)=mag(i)- nmag(i);
else
clean(i)=0;
end
end
%在频域中重新合成%
spectral=clean.* exp(j* phase);
%反傅里叶变换并重叠相加%
enhanced(1+(q-1)* winsize/2:winsize+(q-1)* winsize/2)=...
enhanced(1+(q-1)* winsize/2:winsize+(q-1)* winsize/2)+real(ifft(spectral));
end
%除去汉明窗引起的增益%
for i=1:size
if hamwin(i)==0
enhanced(i)=0;
else
enhanced(i)=enhanced(i)/hamwin(i);
end
end
recoefs1(i)=sgn(recoefs1(i))*(0.003*abs(recoefs1(i))-0.000003)/0.002;
otherwise recoefs1(i)=recoefs1(i);
end
elseif output1(i)==0
recoefs1(i)=recoefs1(i);
end
end
count5=fix(count3/zhen);
for i=1:count5
n=160*(i-1)+1:160+160*(i-1);
s=sound(n);
w=hamming(160);
sw=s.*w;
a=aryule(sw,10);
sw=filter(a,1,sw);
sw=sw/sum(sw);
r=xcorr(sw,'biased');
corr=max(r);
if corr>=0.8
output2(i)=0;
elseif corr<=0.1
output2(i)=1;
end
end
for i=1:count5
n=160*(i-1)+1:160+160*(i-1);
if output2(i)==1
switch abs(recoefs2(i))
case abs(recoefs2(i))<=0.002
recoefs2(i)=0;
case abs(recoefs2(i))>0.002 & abs(recoefs2(i))<=0.003
recoefs2(i)=sgn(recoefs2(i))*(0.003*abs(recoefs2(i))-0.000003)/0.002;
otherwise recoefs2(i)=recoefs2(i);
end
elseif output2(i)==0
recoefs2(i)=recoefs2(i);
end
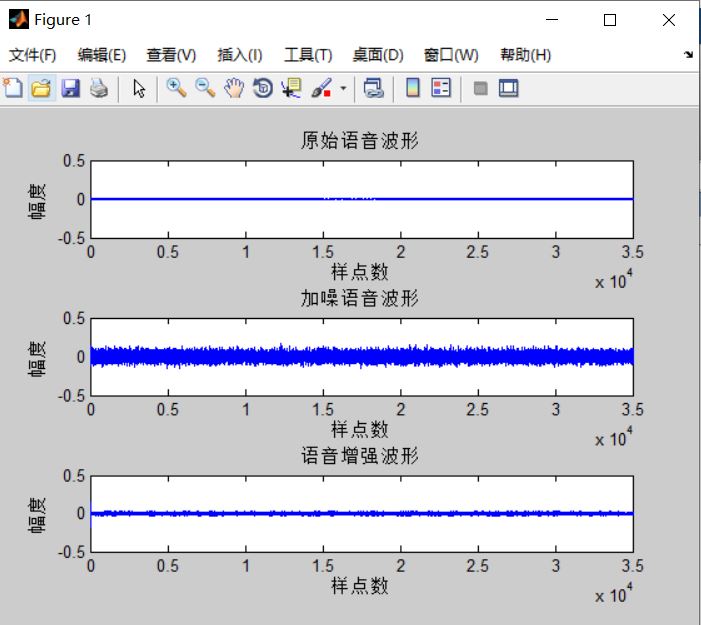
end三、运行结果
完整代码或者仿真咨询添加QQ1575304183
以上是关于信号处理基于小波变换的语音增强matlab源码的主要内容,如果未能解决你的问题,请参考以下文章
语音增强基于matlab多维谱自适应小波语音信号去噪含Matlab源码 1972期
语音隐藏基于matlab小波变换DWT结合离散余弦变换DCT音频数字水印嵌入提取含Matlab源码 2131期
语音隐藏基于matlab小波变换DWT结合离散余弦变换DCT音频数字水印嵌入提取含Matlab源码 2131期