详解AWK的用法
Posted 世界美好與你環環相扣
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了详解AWK的用法相关的知识,希望对你有一定的参考价值。
Awk工具介绍
AwK是一种处理文本文件的语言,是一个强大的文本分析工具。
它是专门为文本处理设计的编程语言,也是行处理软件,通常用于扫描、过滤、统计汇总工作。数据可以来自标准输入也可以是管道或文件
20世纪70年代诞生于贝尔实验室,现在centos7用的是gawk
工作原理:
Awk逐行读取文件,默认以空格为分隔符进行分隔。
当读到第一行时,匹配条件,然后执行指定动作,再接着读取第二行数据处理,不会默认输出。
如果没有定义匹配条件默认是匹配所有数据行,awk隐含循环,条件匹配多少次动作就会执行多少次。
格式: awk 选项 '模式或条件 {编辑指令} ’ 文件
awk -f 脚本文件
在 Awk语句中,模式部分决定何时对数据进行操作,若省略则后续动作时刻保持执行状态,模式可以为条件语句、复合语句或正则表达式等。每条编辑指令可以包含多条语句,多条语句之间要使用分号或者空格分隔的多个{}区域。常用选项-F定义字段分隔符,默认以空格或者制表符作为分隔符。
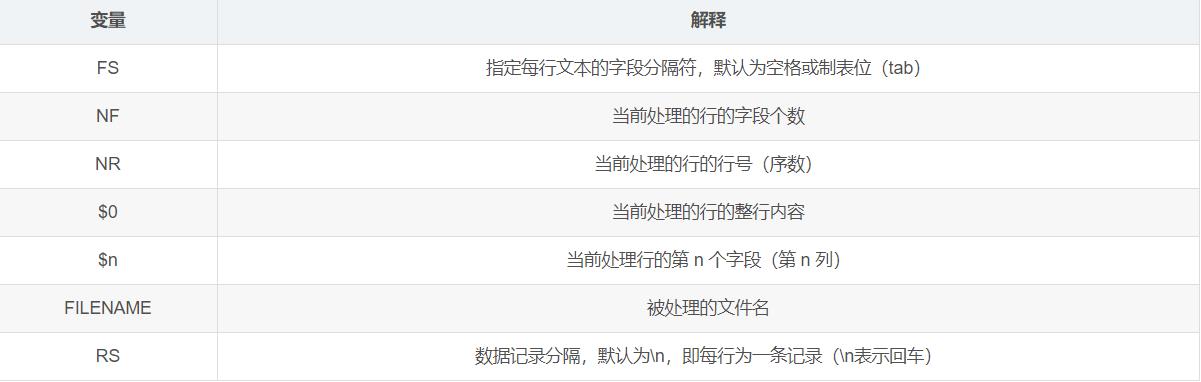
Awk提供了很多内置变量,经常用于处理文本,了解这些内置变量的使用是很有必要的,如下表
按字段输出文本
awk '{print}' a.test 输出所有内容,等同于cat test.txt
awk '{print $0}' a.test 输出所有内容,等同于cat test.txt
awk '{print $1}' a.test 打印第一列//awk默认把一行当做一列,如果没有指定分隔符,默认以空格或tab键分隔
awk -F: '{print $5}' a.test 指定“:”为分隔符,打印第5列的内容
awk -Fx '{print $1}' a.test 指定“x”为分隔符,打印第1列的内容
awk '{print $1" " $2 }' a.test //显示一个空格,空格需要用双引号引起来,如果不用引号默认以变量看待,如果是常量就需要双引号引起来
awk '{print $1,$2 }' a.test //逗号有空格效果
awk -F: '{print $1"---"$2}' a.test //第一列和第二列内容以"---"间隔
awk -F: '{print "用户名"$1"的uid是"$3}' a.test 常量以用""引起来
awk -F: '{print $0}' a.test 处理整行内容
awk -F[:/] '{print $2}' a.test //定义多个分隔符,只要看到其中一个都算作分隔符
awk -F: '{print NF}' a.test 打印每行有多少列
wk '{print $3}' test.txt 输出每行中(以空格或制表位分隔)的第 3 个字段
awk '{print $1,$3}' test.txt 输出每行中的第 1、3 个字段
awk -F: '$2=="!!"{print}' /etc/shadow '输出密码为空的用户的shadow 记录'
awk 'BEGIN {FS=":"}; $2=="!!"{print}' /etc/shadow '输出密码为空的用户的shadow 记录
awk -F: '$7~"/bash"{print $1}' /etc/passwd '输出以冒号分隔且第 7 个字段中包含/bash 的行的第 1 个字段'
awk '($1~"nfs")&&(NF==8){print $1,$2}' /etc/services '输出包含 8 个字段且第 1 个字段中包含 nfs 的行的第 1、2 个字段'
awk -F: '($7!="/bin/bash")&&($7!="/sbin/nologin"){print}' /etc/passwd '输出第 7 个字段既不为/bin/bash 也不为/sbin/nologin 的所有行
按行输出文本
awk '{print}' test.txt '输出所有内容,等同于cat test.txt'
awk '{print $0}' test.txt '输出所有内容,等同于cat test.txt'
awk 'NR==1,NR==3{print}' test.txt '输出第1~3行内容'
awk '(NR>=1)&&(NR<=3){print}' test.txt '输出第1~3行内容'
awk 'NR==1||NR==3{print}' test.txt '输出1行,第3行内容'
awk '(NR%2)==1{print}' test.txt '输出所有奇数行内容'
awk '(NR%2)==0{print}' test.txt '输出所有偶数行内容'
awk '/^root/{print}' /etc/passwd '输出以root开头的行'
awk '/nologin$/{print}' /etc/passwd '输出以 nologin 结尾的行'
awk 'BEGIN {x=0} ; /\\/bin\\/bash$/{x++};END {print x}' /etc/passwd '统计以/bin/bash 结尾的行数,等同于 grep -c "/bin/bash$" /etc/passwd '
awk 'BEGIN{RS=""};END{print NR}' /etc/squid/squid.conf '统计以空行分隔的文本段落数'
awk -F: '/root/{print $0}' a.test 包含root的行
awk -F: '/root/{print $1}' a.test 包含root的行的第一列
awk -F: '/root/{print $1,$6}' a.test 包含root的行第一列和第六列
awk -F: '{print NF}' a.test 显示每一行的列数
awk -F[:/] '{print NR}' a.test 显示行号
awk -F: '{print NR,$0}' a.test 打印文本内容并显示行号
awk 'NR==2' /etc/passwd 打印第二行,不加print也一样,默认就是打印
awk -F: 'NR==2{print $1}' /etc/passwd 打印第二行第一列内容
awk 'END {print NR}' /etc/passwd 打印总行数
awk 'END{print $0}' /etc/passwd 打印文件最后一行内容
awk -F: '$1=="ntp"{print NR,$0}' /etc/shadow 打印第一列内容为ntp的行,并显示行号
awk -F: '{print "第"NR"行有"NF"列"}' /etc/passwd //第几行有几列
通过管道、双引号调用 Shell 命令
(1)操作命令放在{}中
(2)管道符号前面的命令输出的内容交给管道符号后面的命令处理
(3)结合正则表达式,正则表达式同样要被包围
(4)调用的shell命令需要用""引起来
(5){}中多个命令之间用;分隔
awk -F: '/bash$/{print | "wc -l"}' /etc/passwd '调用wc -l 命令统计以bash结尾的用户个数,等同于 grep -c "bash$" /etc/passwd '
awk 'BEGIN {while ("w" | getline) n++ ; {print n-2}}' '调用w 命令,并用来统计在线用户数'
ifconfig ens33 | awk '/netmask/{print "本机的ip地址是"$2}' ens33网卡的ip地址
df -h | awk 'NR==2{print $4}' 根分区的可用量
逐行执行开始之前执行什么任务,结束之后再执行什么任务,用BEGIN、END
BEGIN一般用来做初始化操作,仅在读取数据记录之前执行一次
END一般用来做汇总操作,仅在读取完数据记录之后执行一次
awk的运算
awk 'BEGIN{x=10;print x}'
awk 'BEGIN{x=10;print x+1}'
awk 'BEGIN{x=10;x++;print x}'
awk 'BEGIN{print x+1}' //不指定初始值,初始值就为0,如果是字符串,则默认为空
awk 'BEGIN{print 2.5+3.5}' //小数也可以运算
awk 'BEGIN{print 2^3}' //^和**都是幂运算
模糊匹配
awk -F: '$1~/ro/' /etc/passwd //模糊匹配,只要有ro就匹配上,用~表示包含
awk -F: '$7!~/nologin$/{print $1,$7}' a.test 第七列不包含nologin结尾的第一行和第七行
数值与字符串的比较
比较符号:== != <= >= < >
awk 'NR<5' a.test 打印文件前四行
awk -F: '$3==0' /etc/passwd 文件第三列等于0的行
awk -F: '$1=="root"{print}' /etc/passwd 文件第一列是root的行
逻辑运算 && ||
awk -F: '$3>10 && $3<1000' /etc/passwd
awk -F: '$3<10 || $3>=1000' /etc/passwd
seq 200 | awk '$1%7==0 && $1~/7/' 打印1-200之间所有能被7整除并且包含数字7的整数数字
其他内置变量的用法FS、OFS、NR、FNR、RS、ORS
awk 'BEGIN{FS=":"}{print $1}' a.test //在打印之前定义字段分隔符为冒号
awk 'BEGIN{FS=":";OFS="XXX"}{print $1,$2}' a.test //OFS定义了输出时以什么分隔,$1$2中间要用逗号分隔,因为逗号默认被映射为OFS变量,而这个变量默认是空格
awk 'BEGIN{RS=":"}{print $0}' /etc/passwd //RS:指定以什么为换行符,这里指定是冒号
awk 'BEGIN{ORS="aaa"}{print $0}' a.test 定义以什么连接行
awk 'BEGIN{ORS=" "}{print $0}' /etc/passwd //把多行合并成一行输出,输出的时候自定义以空格分隔每行,本来默认的是回车键
awk高级用法
定义引用变量
a=100
awk -v b="$a" 'BEGIN{print b}' //将系统的变量a,在awk里赋值为变量b,然后调用变量b
awk 'BEGIN{print "'$a'"}' /直接调用的话需要先用双引号再用单引号
awk -vc=1000 'BEGIN{print c}' //awk直接定义变量并引用
1
调用函数getline,读取一行数据的时候并不是得到当前行而是当前行的下一行
seq 10 | awk '{getline;print $0}' //显示偶数行
seq 10 | awk '{print $0;getline}' //显示奇数行
awk的if语句也分为单分支、双分支和多分支
单分支为if(){}
双分支为 if(){}} else{}
多分支为if(){} else if(){} else{}
awk -F: '{if($3<10){print $0}}' /etc/passwd //第三列小于10的打印整行
awk -F: '{if($3<10){print $3} else {print $1}}' /etc/passwd //第三列小于10的打印第三列,否则打印第一列
awk命令总结
(1)一般输出关于段,列的信息使用awk,其他的使用sed或grep更加方便
(2)awk输出的奇偶行都使用绝对路径
(3)sed输出的奇偶行都使用相对路径
(4)使用awk调用shell命令,统计数量时,n是个变量,可自定义
(5)若没有定义n的初始值,则n=0
(6)awk判断条件中双引号之间的内容,如果有特殊符号不需要使用转义符
(6)FS在{}中间使用,F在{}外面使用
以上是关于详解AWK的用法的主要内容,如果未能解决你的问题,请参考以下文章