为了九月秋招,现在开始面试打卡——第五天
Posted Code_BinBin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为了九月秋招,现在开始面试打卡——第五天相关的知识,希望对你有一定的参考价值。
昨天以为乐队表演,所以没有面试题打卡,今天刚吃完饭,我又要继续开始打卡了。

HashMap扩容优化:
扩容以后,1.7对元素进行rehash算法,计算原来每个元素在扩容之后的哈希表中的位置,1.8借助2倍扩容机制,元素不需要进行重新计算位置
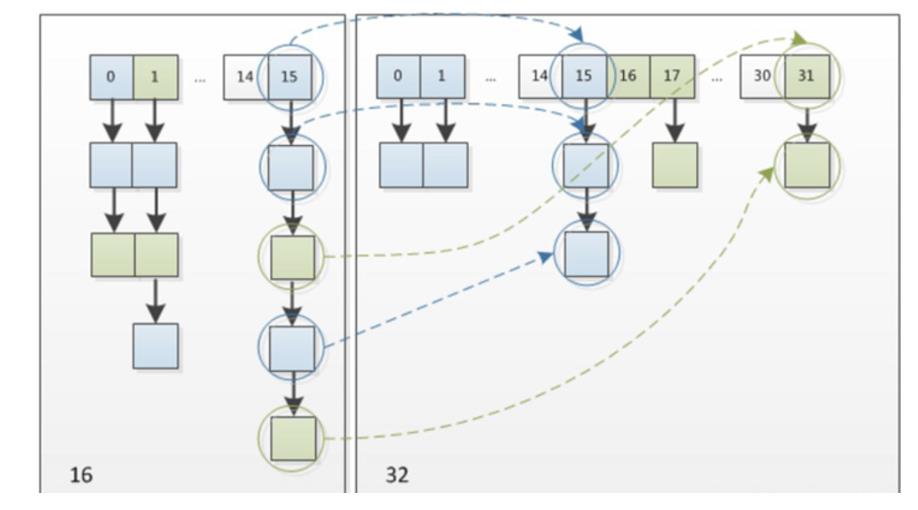
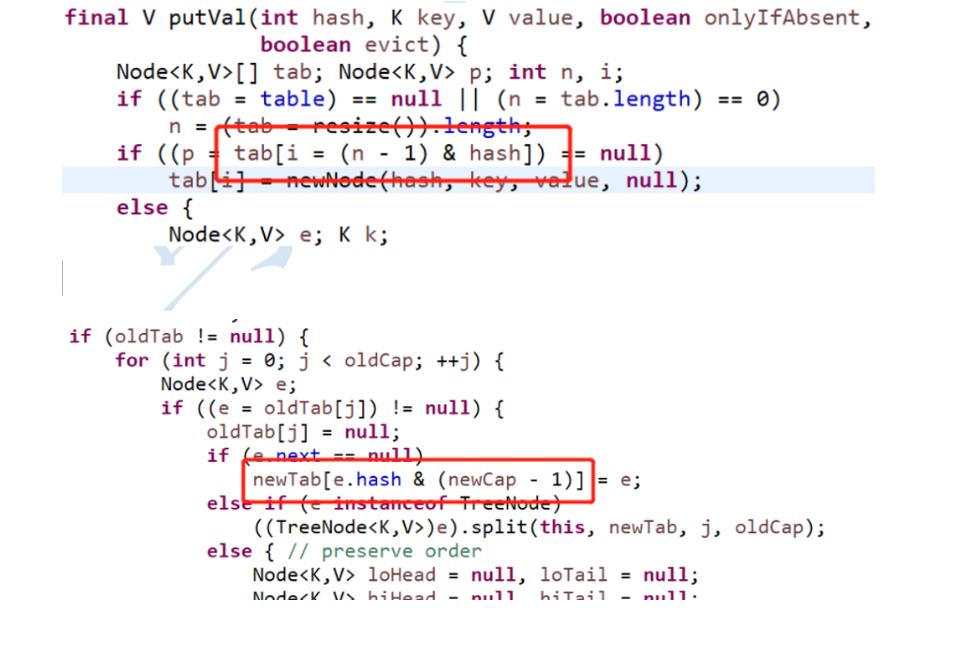
JDK 1.8 在扩容时并没有像 JDK 1.7 那样,重新计算每个元素的哈希值,而是通过高位运算**(e.hash & oldCap)**来确定元素是否需要移动,比如 key1 的信息如下:

使用 e.hash & oldCap 得到的结果,高一位为 0,当结果为 0 时表示元素在扩容时位置不会发生任何变化,而 key 2 信息如下

高一位为 1,当结果为 1 时,表示元素在扩容时位置发生了变化,新的下标位置等于原下标位置 + 原数组长度**hashmap,**不必像1.7一样全部重新计算位置
为什么hashmap扩容的时候是两倍?
查看源代码
在存入元素时,放入元素位置有一个 (n-1)&hash 的一个算法,和hash&(newCap-1),这里用到了一个&位运算符
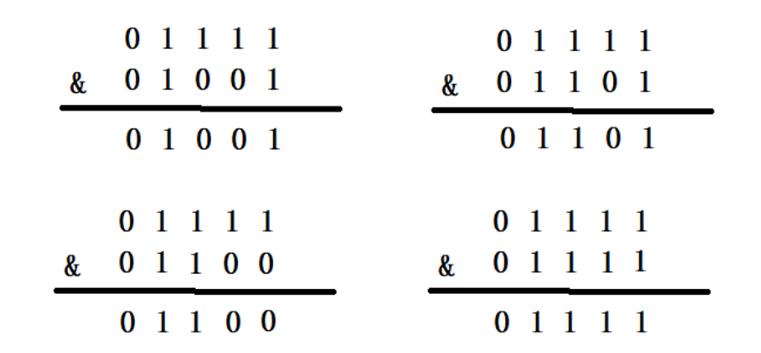
当HashMap的容量是16时,它的二进制是10000,(n-1)的二进制是01111,与hash值得计算结果如下
下面就来看一下HashMap的容量不是2的n次幂的情况,当容量为10时,二进制为01010,(n-1)的二进制是01001,向里面添加同样的元素,结果为
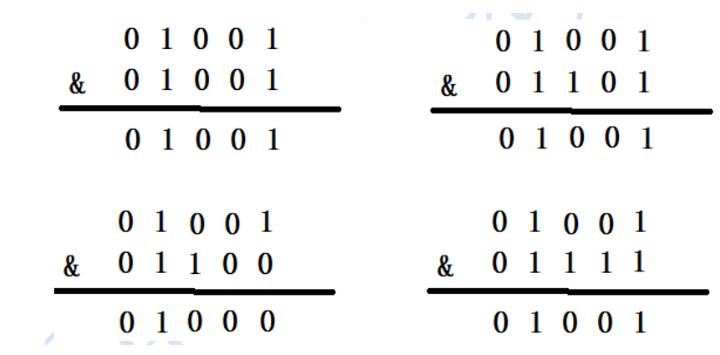
可以看出,有三个不同的元素进过&运算得出了同样的结果,严重的hash碰撞了
只有当n的值是2的N次幂的时候,进行&位运算的时候,才可以只看后几位,而不需要全部进行计算
hashmap线程安全的方式?
HashMap不是线程安全的,往往在写程序时需要通过一些方法来回避.其实JDK原生的提供了2种方法让HashMap支持线程安全.
方法一:通过Collections.synchronizedMap()返回一个新的Map,这个新的map就是线程安全的. 这个要求大家习惯基于接口编程,因为返回的并不是HashMap,而是一个Map的实现.
方法二:重新改写了HashMap,具体的可以查看java.util.concurrent.ConcurrentHashMap. 这个方法比方法一有了很大的改进.
方法一特点:
通过Collections.synchronizedMap()来封装所有不安全的HashMap的方法,就连toString, hashCode都进行了封装. 封装的关键点有2处,1)使用了经典的synchronized来进行互斥, 2)使用了代理模式new了一个新的类,这个类同样实现了Map接口.在Hashmap上面,synchronized锁住的是对象,所以第一个申请的得到锁,其他线程将进入阻塞,等待唤醒. 优点:代码实现十分简单,一看就懂.缺点:从锁的角度来看,方法一直接使用了锁住方法,基本上是锁住了尽可能大的代码块.性能会比较差.
方法二特点:
重新写了HashMap,比较大的改变有如下几点.使用了新的锁机制,把HashMap进行了拆分,拆分成了多个独立的块,这样在高并发的情况下减少了锁冲突的可能,使用的是NonfairSync. 这个特性调用CAS指令来确保原子性与互斥性.当如果多个线程恰好操作到同一个segment上面,那么只会有一个线程得到运行.
优点:需要互斥的代码段比较少,性能会比较好. ConcurrentHashMap把整个Map切分成了多个块,发生锁碰撞的几率大大降低,性能会比较好. 缺点:代码繁琐
自定义异常在生产中如何应用
Java虽然提供了丰富的异常处理类,但是在项目中还会经常使用自定义异常,其主要原因是Java提供的异常类在某些情况下还是不能满足实际需球。例如以下情况:
1、系统中有些错误是符合Java语法,但不符合业务逻辑。
2、在分层的软件结构中,通常是在表现层统一对系统其他层次的异常进行捕获处理。
如何实现一个IOC容器?
IOC(Inversion of Control),意思是控制反转,不是什么技术,而是一种设计思想,IOC意味着将你设计好的对象交给容器控制,而不是传统的在你的对象内部直接控制。
在传统的程序设计中,我们直接在对象内部通过new进行对象创建,是程序主动去创建依赖对象,而IOC是有专门的容器来进行对象的创建,即IOC容器来控制对象的创建。
在传统的应用程序中,我们是在对象中主动控制去直接获取依赖对象,这个是正转,反转是由容器来帮忙创建及注入依赖对象,在这个过程过程中,由容器帮我们查找级注入依赖对象,对象只是被动的接受依赖对象。
1、先准备一个基本的容器对象,包含一些map结构的集合,用来方便后续过程中存储具体的对象
2、进行配置文件的读取工作或者注解的解析工作,将需要创建的bean对象都封装成BeanDefinition对象存储在容器中
3、容器将封装好的BeanDefinition对象通过反射的方式进行实例化,完成对象的实例化工作
4、进行对象的初始化操作,也就是给类中的对应属性值就行设置,也就是进行依赖注入,完成整个对象的创建,变成一个完整的bean对象,存储在容器的某个map结构中
5、通过容器对象来获取对象,进行对象的获取和逻辑处理工作
6、提供销毁操作,当对象不用或者容器关闭的时候,将无用的对象进行销毁
说说你对Spring 的理解?
官网地址:https://spring.io/projects/spring-framework#overview
压缩包下载地址:https://repo.spring.io/release/org/springframework/spring/
源码地址:https://github.com/spring-projects/spring-framework
Spring makes it easy to create Java enterprise applications. It provides everything you need to embrace the Java language in an enterprise environment, with support for Groovy and Kotlin as alternative languages on the JVM, and with the flexibility to create many kinds of architectures depending on an application’s needs. As of Spring Framework 5.1, Spring requires JDK 8+ (Java SE 8+) and provides out-of-the-box support for JDK 11 LTS. Java SE 8 update 60 is suggested as the minimum patch release for Java 8, but it is generally recommended to use a recent patch release.
Spring supports a wide range of application scenarios. In a large enterprise, applications often exist for a long time and have to run on a JDK and application server whose upgrade cycle is beyond developer control. Others may run as a single jar with the server embedded, possibly in a cloud environment. Yet others may be standalone applications (such as batch or integration workloads) that do not need a server.
Spring is open source. It has a large and active community that provides continuous feedback based on a diverse range of real-world use cases. This has helped Spring to successfully evolve over a very long time.
Spring 使创建 Java 企业应用程序变得更加容易。它提供了在企业环境中接受 Java 语言所需的一切,,并支持 Groovy 和 Kotlin 作为 JVM 上的替代语言,并可根据应用程序的需要灵活地创建多种体系结构。 从 Spring Framework 5.0 开始,Spring 需要 JDK 8(Java SE 8+),并且已经为 JDK 9 提供了现成的支持。
Spring支持各种应用场景, 在大型企业中, 应用程序通常需要运行很长时间,而且必须运行在 jdk 和应用服务器上,这种场景开发人员无法控制其升级周期。 其他可能作为一个单独的jar嵌入到服务器去运行,也有可能在云环境中。还有一些可能是不需要服务器的独立应用程序(如批处理或集成的工作任务)。
Spring 是开源的。它拥有一个庞大而且活跃的社区,提供不同范围的,真实用户的持续反馈。这也帮助Spring不断地改进,不断发展。
你觉得Spring的核心是什么?
spring是一个开源框架。
spring是为了简化企业开发而生的,使得开发变得更加优雅和简洁。
spring是一个IOC和AOP的容器框架。
IOC:控制反转
AOP:面向切面编程
容器:包含并管理应用对象的生命周期,就好比用桶装水一样,spring就是桶,而对象就是水
说一下使用spring的优势?
1、Spring通过DI、AOP和消除样板式代码来简化企业级Java开发
2、Spring框架之外还存在一个构建在核心框架之上的庞大生态圈,它将Spring扩展到不同的领域,如Web服务、REST、移动开发以及NoSQL
3、低侵入式设计,代码的污染极低
4、独立于各种应用服务器,基于Spring框架的应用,可以真正实现Write Once,Run Anywhere的承诺
5、Spring的IoC容器降低了业务对象替换的复杂性,提高了组件之间的解耦
6、Spring的AOP支持允许将一些通用任务如安全、事务、日志等进行集中式处理,从而提供了更好的复用
7、Spring的ORM和DAO提供了与第三方持久层框架的的良好整合,并简化了底层的数据库访问
8、Spring的高度开放性,并不强制应用完全依赖于Spring,开发者可自由选用Spring框架的部分或全部
Spring是如何简化开发的?
基于POJO的轻量级和最小侵入性编程
通过依赖注入和面向接口实现松耦合
基于切面和惯例进行声明式编程
通过切面和模板减少样板式代码
说说你对Aop的理解?
AOP全称叫做 Aspect Oriented Programming 面向切面编程。它是为解耦而生的,解耦是程序员编码开发过程中一直追求的境界,AOP在业务类的隔离上,绝对是做到了解耦,在这里面有几个核心的概念:
-
切面(Aspect): 指关注点模块化,这个关注点可能会横切多个对象。事务管理是企业级Java应用中有关横切关注点的例子。 在Spring AOP中,切面可以使用通用类基于模式的方式(schema-based approach)或者在普通类中以
@Aspect注解(@AspectJ 注解方式)来实现。 -
连接点(Join point): 在程序执行过程中某个特定的点,例如某个方法调用的时间点或者处理异常的时间点。在Spring AOP中,一个连接点总是代表一个方法的执行。
-
通知(Advice): 在切面的某个特定的连接点上执行的动作。通知有多种类型,包括“around”, “before” and “after”等等。通知的类型将在后面的章节进行讨论。 许多AOP框架,包括Spring在内,都是以拦截器做通知模型的,并维护着一个以连接点为中心的拦截器链。
-
切点(Pointcut): 匹配连接点的断言。通知和切点表达式相关联,并在满足这个切点的连接点上运行(例如,当执行某个特定名称的方法时)。切点表达式如何和连接点匹配是AOP的核心:Spring默认使用AspectJ切点语义。
-
引入(Introduction): 声明额外的方法或者某个类型的字段。Spring允许引入新的接口(以及一个对应的实现)到任何被通知的对象上。例如,可以使用引入来使bean实现
IsModified接口, 以便简化缓存机制(在AspectJ社区,引入也被称为内部类型声明(inter))。 -
目标对象(Target object): 被一个或者多个切面所通知的对象。也被称作被通知(advised)对象。既然Spring AOP是通过运行时代理实现的,那么这个对象永远是一个被代理(proxied)的对象。
-
AOP代理(AOP proxy):AOP框架创建的对象,用来实现切面契约(aspect contract)(包括通知方法执行等功能)。在Spring中,AOP代理可以是JDK动态代理或CGLIB代理。
-
织入(Weaving): 把切面连接到其它的应用程序类型或者对象上,并创建一个被被通知的对象的过程。这个过程可以在编译时(例如使用AspectJ编译器)、类加载时或运行时中完成。 Spring和其他纯Java AOP框架一样,是在运行时完成织入的。
这些概念都太学术了,如果更简单的解释呢,其实非常简单:
任何一个系统都是由不同的组件组成的,每个组件负责一块特定的功能,当然会存在很多组件是跟业务无关的,例如日志、事务、权限等核心服务组件,这些核心服务组件经常融入到具体的业务逻辑中,如果我们为每一个具体业务逻辑操作都添加这样的代码,很明显代码冗余太多,因此我们需要将这些公共的代码逻辑抽象出来变成一个切面,然后注入到目标对象(具体业务)中去,AOP正是基于这样的一个思路实现的,通过动态代理的方式,将需要注入切面的对象进行代理,在进行调用的时候,将公共的逻辑直接添加进去,而不需要修改原有业务的逻辑代码,只需要在原来的业务逻辑基础之上做一些增强功能即可。
说说你对IOC的理解?
IoC is also known as dependency injection (DI). It is a process whereby objects define their dependencies (that is, the other objects they work with) only through constructor arguments, arguments to a factory method, or properties that are set on the object instance after it is constructed or returned from a factory method. The container then injects those dependencies when it creates the bean. This process is fundamentally the inverse (hence the name, Inversion of Control) of the bean itself controlling the instantiation or location of its dependencies by using direct construction of classes or a mechanism such as the Service Locator pattern.
IOC与大家熟知的依赖注入同理,. 这是一个通过依赖注入对象的过程 也就是说,它们所使用的对象,是通过构造函数参数,工厂方法的参数或这是从工厂方法的构造函数或返回值的对象实例设置的属性,然后容器在创建bean时注入这些需要的依赖。 这个过程相对普通创建对象的过程是反向的(因此称之为IoC),bean本身通过直接构造类来控制依赖关系的实例化或位置,或提供诸如服务定位器模式之类的机制。
如果这个过程比较难理解的话,那么可以想象自己找女朋友和婚介公司找女朋友的过程。如果这个过程能够想明白的话,那么我们现在回答上面的问题:
1、谁控制谁:在之前的编码过程中,都是需要什么对象自己去创建什么对象,有程序员自己来控制对象,而有了IOC容器之后,就会变成由IOC容器来控制对象,
2、控制什么:在实现过程中所需要的对象及需要依赖的对象
3、什么是反转:在没有IOC容器之前我们都是在对象中主动去创建依赖的对象,这是正转的,而有了IOC之后,依赖的对象直接由IOC容器创建后注入到对象中,由主动创建变成了被动接受,这是反转
4、哪些方面被反转:依赖的对象
以上是关于为了九月秋招,现在开始面试打卡——第五天的主要内容,如果未能解决你的问题,请参考以下文章