java 生成pdf
Posted QQ_851228082
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java 生成pdf相关的知识,希望对你有一定的参考价值。
java生成pdf技术选型
技术选型
java生成pdf最终选择itext7+pdfhtml+freemarker。为什么使用这个组合呢?生成pdf,通常会用html转pdf,这是因为html+css便于调节样式,否则使用原生库,用java直接生成pdf,太繁琐,改一点样式都要改java代码;所以首先要用html,那就要找个模板引擎将数据填充到html,如果不用模板引擎,用js填充的话,就得用到浏览器引擎解析js,js发送http request获取数据,挺麻烦的,所以不如用模板引擎;有了模板引擎,还要有html-pdf转化器,可以将填充后的html转化为pdf;基于以上分析,必须要用到html+css、模板引擎、html-pdf转化器,相应的最终选择itext7+pdfhtml+freemarker。
- itext7是itext的最新版本,功能丰富并较itext5做了很大优化;
- pdfhtml是itext的套件之一,底层依赖itext,它支持html5、css3,能将html转换为pdf;
- freemarker是apache的模板引擎,用来将数据填充到html;
itext7+pdfhtml+freemarker vs flyingsaucer+itext5 vs wkhtmlTopdf
- flyingsaucer与pdfhtml作用相同,用来将html转为pdf,但只支持css2,并且底层依赖itext5(最新的是itext7),非官方的,所以放弃;
- wkhtmlTopdf使用浏览器引擎解析html,然后将html转换为pdf,所以还原度较高,但是命令行式的,并且要预先安装,每次导出pdf就是执行一次shell命令,这就等于从jvm开了一个进程,从性能、繁琐性考虑,放弃;
字体
itext分为3种字体,Standard Type 1 Fonts (14种)、shipped fonts(12种)、系统字体,Standard Type 1 Fonts 因为版权问题不允许嵌套到pdf中,
Standard Type 1 Fonts
| 字体 | 变种 |
|---|---|
| Times | Times-Roman |
| Times | Times-Bold |
| Times | Times-Italic |
| Times | Times-BoldItalic |
| Helvetica | Helvetica |
| Helvetica | Helvetica-Bold |
| Helvetica | Helvetica-Oblique |
| Helvetica | Helvetica-BoldOblique |
| Courier | Courier |
| Courier | Courier-Bold |
| Courier | Courier-Oblique |
| Courier | Courier-BoldOblique |
| Symbol | Symbol |
| ZapfDingbats | ZapfDingbats |
可以看到Times 、Helvetica、Courier每种都有4中变种分别是常规、加粗、倾斜、加粗倾斜,共12种,再加上Symbol、ZapfDingbats一共14种,这些字体只包含了西方字符,所以用这些字体生成汉语肯定是不显示的;因为版权问题,这些字体不能嵌套到pdf中,itext假设pdf 阅读器会搭载这些字体或者操作系统有这些字体;
shipped fonts
shipped fonts含有sans 、serif 、monospaced 3种字体,类似的每种有4种变体,常规字体、加粗字体、倾斜字体、加粗倾斜字体,默认嵌套。
系统字体
系统字体指的是,操作系统上的字体,比如在windows中,字体路径是C:\\Windows\\Fonts,最好不要注册系统字体,因为会加载很多字体,这会消耗资源且顺序不可控,所以,在不同操作系统上,pdf可能表现不一样。
html生成pdf关键代码
springboot中,生成pdf的核心代码
ConverterProperties converterProperties = new ConverterProperties();
DefaultFontProvider fontProvider = new DefaultFontProvider(false,
false,false,"simfang");
Class<MyController> myControllerClass = MyController.class;
logger.info("TreatmentController的ClassLoader是:{}",myControllerClass.getClassLoader());
String fontPath = myControllerClass.getResource("/simfang.ttf").toString();
fontProvider.addFont(fontPath);
//注意templates以/结尾表示文件夹
String baseUri = myControllerClass.getResource("/templates/").toString();
logger.info("itext的baseUri是:{}",baseUri);
converterProperties.setBaseUri(baseUri);
converterProperties.setFontProvider(fontProvider);
HtmlConverter.convertToPdf(byteArrayInputStream,
response.getOutputStream(), converterProperties);
注意,
DefaultFontProvider(false,
false,false,"simfang");
利用了构造方法
DefaultFontProvider(registerStandardPdfFonts,
registerShippedFonts,registerSystemFonts,defaultFontFamily);
表示不注册标准字体、不注册搭载字体、不注册系统字体、默认字体是仿宋,推荐这样使用,可确保字体的唯一性。
设置baseuri
springboot中设置图片、字体等的baseuri,注意文件夹以/结尾
//注意templates以/结尾表示文件夹
String baseUri = myControllerClass.getResource("/templates/").toString();
logger.info("itext的baseUri是:{}",baseUri);
常见问题
pdf分页
pdf分页用css来实现,在想分页的地方添加
page-break-after:always;
pdf页码和页脚
用css来实现
@page {
@bottom-left {
font-size: 12px;
content: "这就是页脚";
}
@bottom-right {
/*这是当前页、总页数*/
content: counter(page) "/" counter(pages);
}
margin-bottom: 70px;
}

如果首页不想要页脚和页码,则利用:first伪元素
@page:first{
@bottom-left {
content: none;
}
@bottom-right {
content: none;
}
}
页码不正确,多了一页
可能是在最后一页,设置了分页导致,去掉就好了。
pdf不显示汉字、乱码
-
不显示,不显示有两种原因
- 字体用的不对。不显示是因为字体用的不对,比如用了
Helvetica字体,这个字体只有英语字母、英文符号等字符,汉字用这个字体,肯定不会显示。 - 字体未嵌入到pdf,字体包含目标字符,但未嵌入到pdf中,在其他电脑上打开时,恰巧这个电脑没有所使用的字体那么也不会显示,这个时候就要将字体内嵌到pdf中,当然pdf阅读器也可能使用相近字体替代,这时“替代字体”就是“实际字体”;
- 字体用的不对。不显示是因为字体用的不对,比如用了
-
乱码
乱码指的是,对字体使用了错误的编码。比如仿宋,你用Helvetica去编码肯定不行。编码指的是字符编码,iso8859-1、gbk、unicode之类的
怎样查看pdf字体?
-
查看pdf使用的全部字体
- 使用Adobe Acrobat打开pdf,查看pdf字体,文件---->属性—>字体或者使用快捷键
ctrl+d 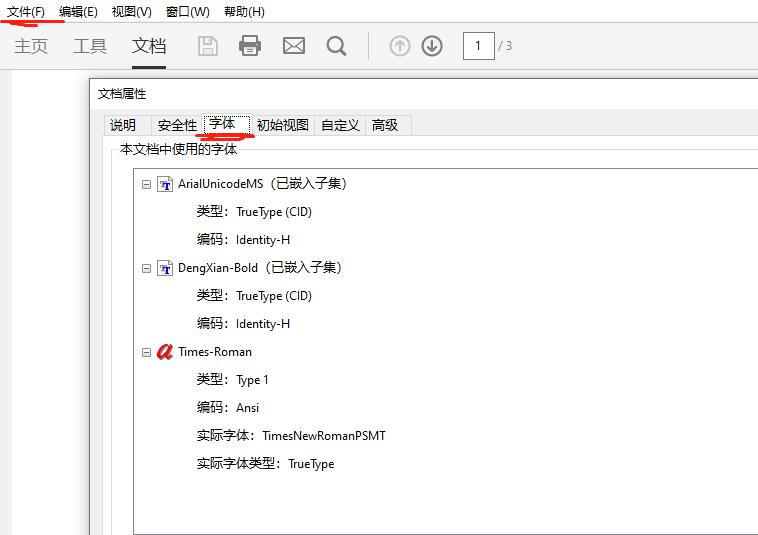
- 使用Adobe Acrobat打开pdf,查看pdf字体,文件---->属性—>字体或者使用快捷键
-
查看某个文字或者段落使用的字体
- 在选中目标文字,右击编辑文本,右侧显示字体。
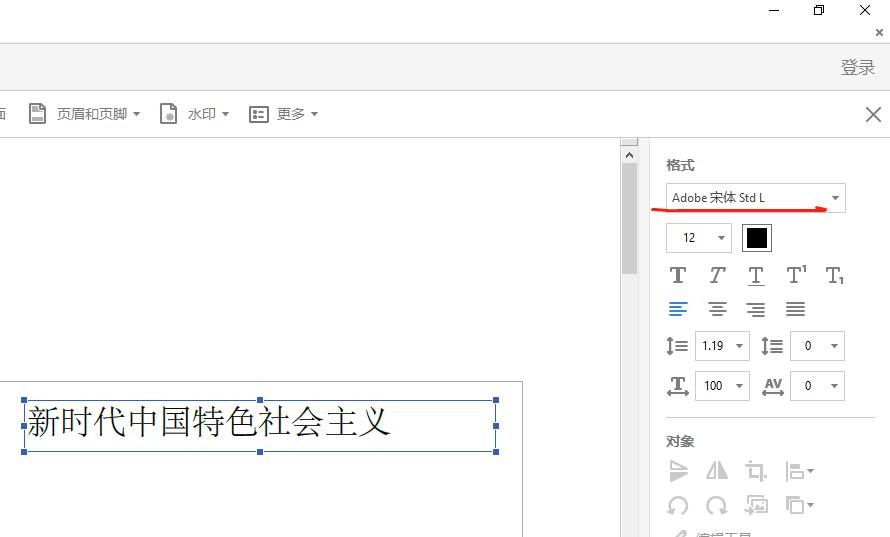
windows上生成的pdf与linux生成的pdf,字体不一样
查看pdf字体,发现使用了很多字体,怀疑是用了系统字体,将registerSystemFonts设置为false后修复。
type1、ttf、ottf、cid名字解释
- type1就是上文提到的
Standard Type 1 Fonts,是adobe公司推出的,也叫PostScript Type 1 简称ps1,不再推荐使用,基于adobe pdf阅读器已经搭载了该字体的假设,不允许内嵌到pdf。 - true type是apple和微软开发的,晚于type1,并且逐渐成为主流,adobe目前转向true type,比type1支持更多的字符集、布局,
ttf就是true type font的缩写。 - open type 跨平台的, Adobe and Microsoft出品,adobe已经将他的字体库全部转为open type,
otf就是open type font的缩写,跨平台支持苹果和windows,支持更多的字符集和排版特性。基于true type的open type字体结尾是ttf - eof= Embedded OpenType,它是对OpenType 字体的压缩版,被微软设计用来在web网页中嵌入使用。只有微软的IE浏览器支持,跟WOFF正好相反
- woff=Web Open Font Format ,在web页面中的一种字体格式,它其实是 OpenType 或者 TrueType被压缩了并且带有一些元数据。woff主要有两个目的,第一它是专门用来当作web字体的而不是桌面字体,第二减少web字体在网络传输时的延迟。woff2是woff的下一代字体,比woff平均大小能小30%,传输速度更快。
- cid是
character id的意思,一般是type1、true type - type1、ttf、otf、woff、woff2的不同
文档
itext官网---->developer---->knowledge base—>Ebooks
https://stackoverflow.com/questions/83320/what-is-the-difference-between-truetype-fonts-and-type-1-fonts
以上是关于java 生成pdf的主要内容,如果未能解决你的问题,请参考以下文章
Java使用Flying Saucer实现HTML代码生成PDF文档