COMP9313_WEEK1_2_课程简介
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了COMP9313_WEEK1_2_课程简介相关的知识,希望对你有一定的参考价值。
参考技术A 声明:由于本人也是处于学习阶段,有些理解可能并不深刻,甚至会携带一定错误,因此请以批判的态度来进行阅读,如有错误,请留言或直接联系本人。课程内容介绍
大数据的多种定义及解释:
1)Big data is a term for data sets that are so voluminous or complex that traditional data processing application software are inadequate to deal with them
2)Challenges include: capture, storage, analysis, data curation, search, sharing, transfer, visualization, querying, updating and information privacy.
3)The term "big data" often refers simply to the use of predictive analytics, user behaviour analytics, or certain other advanced data analytics methods that extract value from data, and seldom to a particular size of data set
4)Analysis of data sets can find new correlations to "spot business trends, prevent diseases, combat crime and so on."
大数据处理应用生态环境:
1)Hadoop MapReduce
2)Spark
3)NoSQL (e.g., HBase, MongoDB, Neo4j)
4)Pregel 等
大数据的产生环境:1. 社会; 2. 国土安全; 3. 用户跟踪调查; 4. 实时搜索; 5. 电子商务; 6. 金融服务等等
大数据的特征(3V):1. volume; 2. variety; 3. velocity
1)Volume:即为容量,因为近些年来,数据体量增长速率非常快(每年40%左右)。因此,数据的总体容量变得越来越大。
2)Variety:即为种类,数据的种类由单一种类发展成纷繁复杂的各种类型的数据。包括但不限于:Relational Data (Tables/Transaction/Legacy Data);Text Data (Web);Semi-structured;Data (XML) ;Graph Data;Social Network, Semantic Web (RDF), … ;Streaming Data (You can only scan the data once)。而且数据来源也呈现多元化。
3)Velocity:即为速度(产生速度),由于数据的产生速度非常迅速,因此数据的处理必须得到加快才能使得一些实时信息得到利用,否则将会错失很多机会。这里包括但不限于:E-Promotions;Healthcare monitoring; Disaster management and response等信息的实施产生和实时处理。
Extended Big data特征(6V):
1)Volume: In a big data environment, the amounts of data collected and processed are much larger than those stored in typical relational databases.
2)Variety: Big data consists of a rich variety of data types.
3)Velocity: Big data arrives to the organization at high speeds and from multiple sources simultaneously.
4)Veracity(准确性): Data quality issues are particularly challenging in a big data context.(这里着重讲求数据的quality,只有有质量的,能够让人信任的数据才是可用的数据)
5)Visibility/Visualization(可视化): After big data being processed, we need a way of presenting the data in a manner that’s readable and accessible. (这里讲求的是数据的可读性和可理解性,因为一堆数据单一的陈列出来可能难以阅读及难以理解,如果将数据做成图表或归纳为结论,数据才能提供给一些非数据处理或数据分析人士使用,那么数据的价值才能体现)
6)Value(数据的价值性): Ultimately, big data is meaningless if it does not provide value toward some meaningful goal.(这里讲求数据是要有其使用价值的,所以,数据的清洗尤为重要,这项步骤将无用的数据筛出去,留下有用的数据来用作分析。因此本人认为,数据的使用领域也是非常重要,如消费者购物篮存放的物品数据对于电商是金矿,然而对于银行业可能没什么直接的作用。)
大数据的存储一直是个挑战,具体包括但不限于以下几点:
1)Data Volumes are massive
2)Reliability of Storing PBs of data is challenging
3)All kinds of failures: Disk/Hardware/Network Failures
4)Probability of failures simply increase with the number of machines
那如何解决这一问题以及其他的大数据处理问题呢?于是分布式系统基础构架诞生。Hadoop就是其中一员。(来自维基百科:分布式系统是一组电脑,通过网络相互链接传递消息与通信后并协调它们的行为而形成的系统。组件之间彼此进行交互以实现一个共同的目标。把需要进行大量计算的工程数据分区成小块,由多台计算机分别计算,再上传运算结果后,将结果统一合并得出数据结论的科学。)
Hadoop:
1)Open-source data storage and processing platform;
2)核心由2部分组成:HDFS和MapReduce
(HDFS(Hadoop Distributed File System):Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。HDFS在最开始是作为Apache Nutch搜索引擎项目的基础架构而开发的。HDFS是Apache Hadoop Core项目的一部分)
(MapReduce:
Hadoop Map/Reduce是一个使用简易的软件框架,基于它写出来的应用程序能够运行在由上千个商用机器组成的大型集群上,并以一种可靠容错的方式并行处理上T级别的数据集。
一个Map/Reduce 作业(job) 通常会把输入的数据集切分为若干独立的数据块,由 map任务(task)以完全并行的方式处理它们。框架会对map的输出先进行排序, 然后把结果输入给reduce任务。通常作业的输入和输出都会被存储在文件系统中。 整个框架负责任务的调度和监控,以及重新执行已经失败的任务。
通常,Map/Reduce框架和分布式文件系统是运行在一组相同的节点上的,也就是说,计算节点和存储节点通常在一起。这种配置允许框架在那些已经存好数据的节点上高效地调度任务,这可以使整个集群的网络带宽被非常高效地利用)
详细内容请查看Apache Hadoop官方文档: http://hadoop.apache.org/ ;http:/ hadoop.apache.org/docs/r1.0.4/cn/index.html
(1)Data Access :HBase, Hive, Pig, Mahout
(2)Tools:Hue, Sqoop
(3)Monitoring:Greenplum, Cloudera
Hadoop的布局:
Hadoop1.0与2.0的构架:
Hadoop提供的功能:
1)Redundant, Fault-tolerant data storage
2)Parallel computation framework
3)Job coordination
Hadoop的优点:
1)Cheaper:Scales to Petabytes or more easily
2)Faster:Parallel data processing
3)Better:Suited for particular types of big data problems
Hadoop的Map/Reduce功能的详细讲解:
对于典型的大数据而问题:
1)Iterate over a large number of records
2)Extract something of interest from each
3)Shuffle and sort intermediate results
4)Aggregate intermediate results
5)Generate final output
步骤1、2属于Map(得到未排序的中间值);步骤4、5属于Reduce;第3步属于将数据进行整理排序得到排序后的中间值,方便后面的Reduce时的统计
老师给了我们一段话来Mapreduce:
这里,第一步时map,将句子split成单个的词,然后将词作key,用计数单位作value(当然其他情况下value可能不是计数单位);第二步,需要shuffle/sort这些dict(字典)(就是按照一定排列顺序排列,并将相同key的dict排在一起);最后一步Reduce,将所有key相同的dict聚类到一起,形成一个新的dict(就如6个<the, 1>聚类得到1个<the, 6>, 这里没有要求区分大小写,所以大小写忽略)。
2020_1课程设计—基于BC的证书格式转换工具的设计与实现—Week 3
本周计划
- 对项目进行完善总结
- 增加对BouncyCastle、Certificate、CertificateFactory的认识
- 尝试使用Junit对部分代码进行单元测试
学习记录
代码优化
代码结构
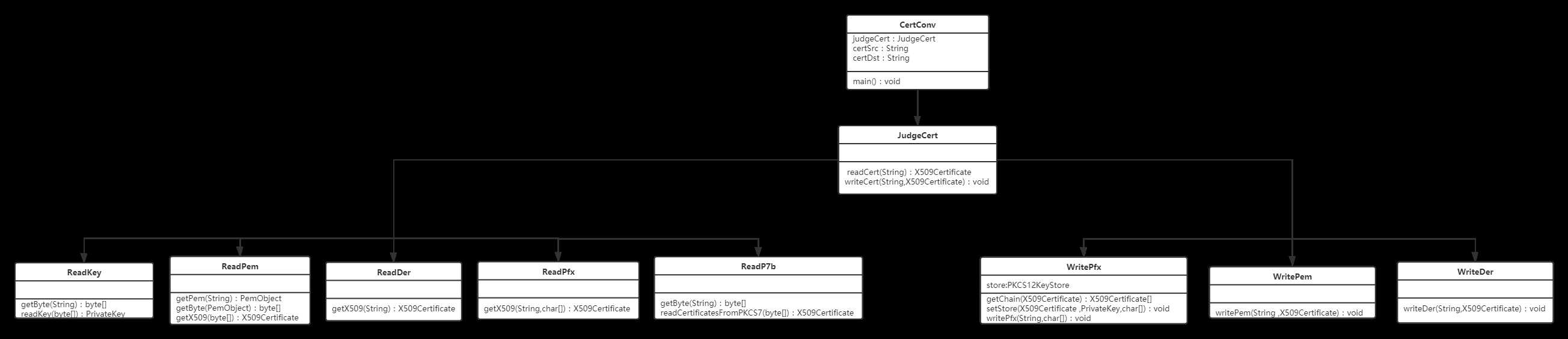
代码细节处理
-
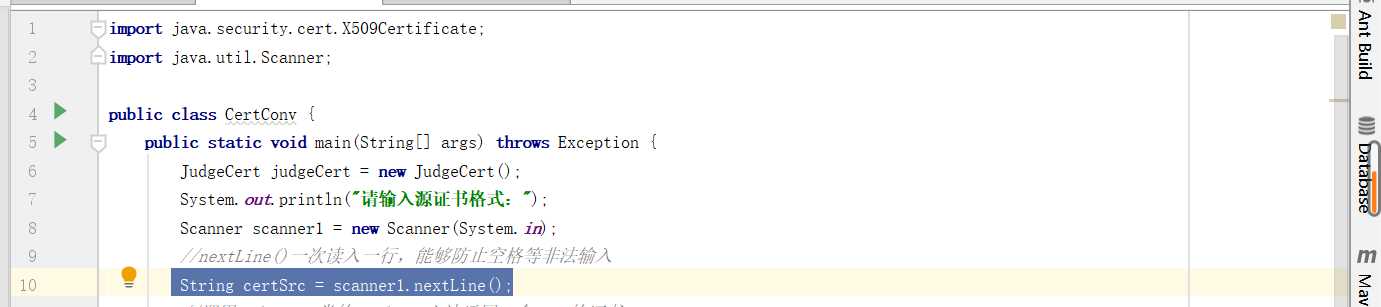
scanner.nextLine(),一次读入一行,方便后续equal判断输入情况
-
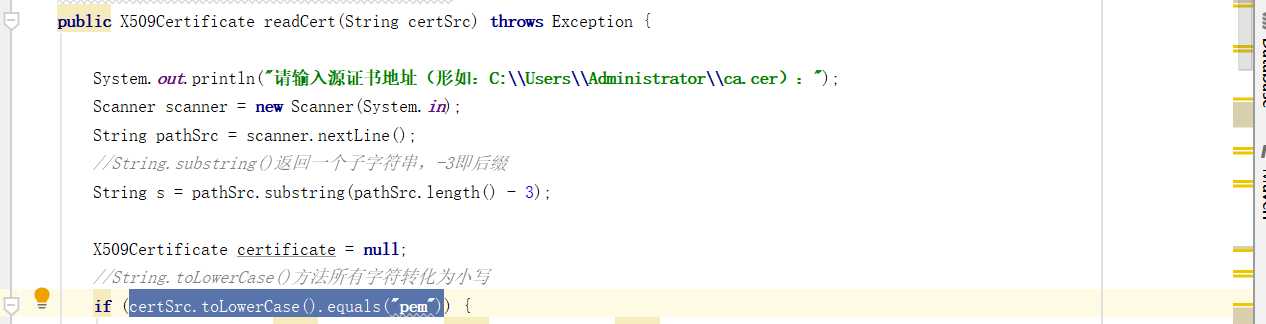
String.toLowerCase()方法,将字符串转化为小写,如此可以规避大小写造成的问题
-
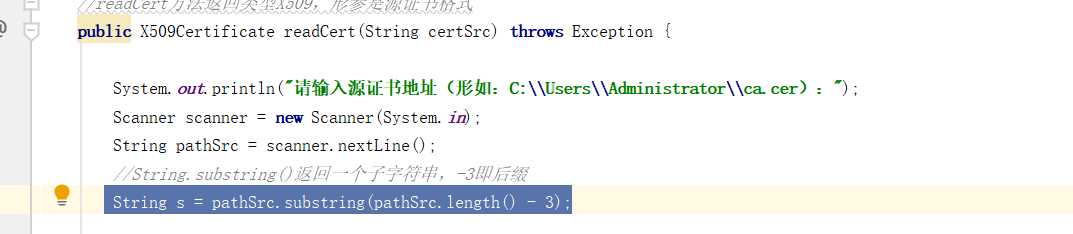
String.substring(),可以通过返回子字符串的方式检测后缀名
单元测试
检测异常抛出情况
- Try…catch方法:检测是否抛出异常、检测异常抛出类型
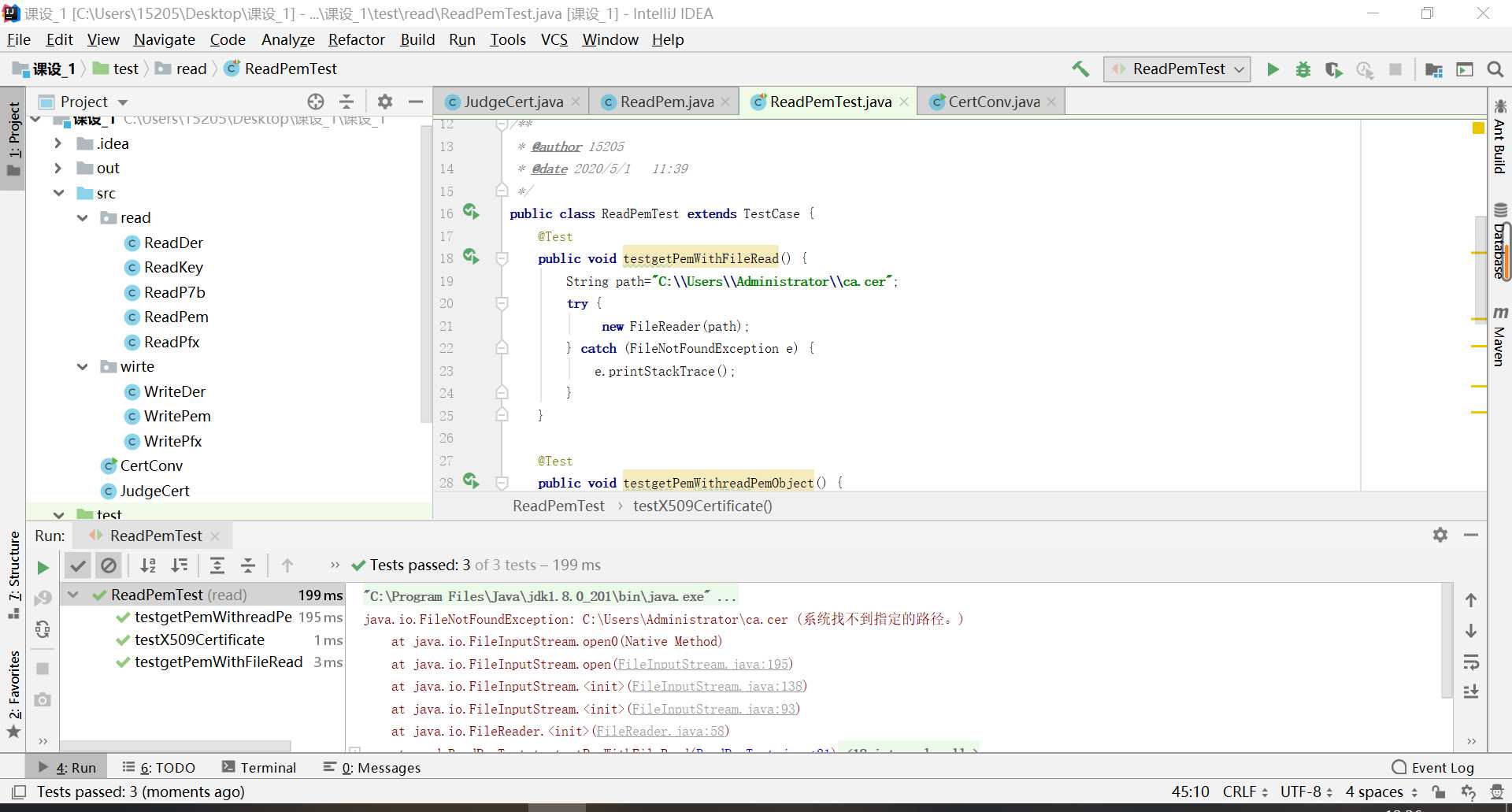
测试System.exit情况
-
遇到不显示通不通过状况,处于中断状态
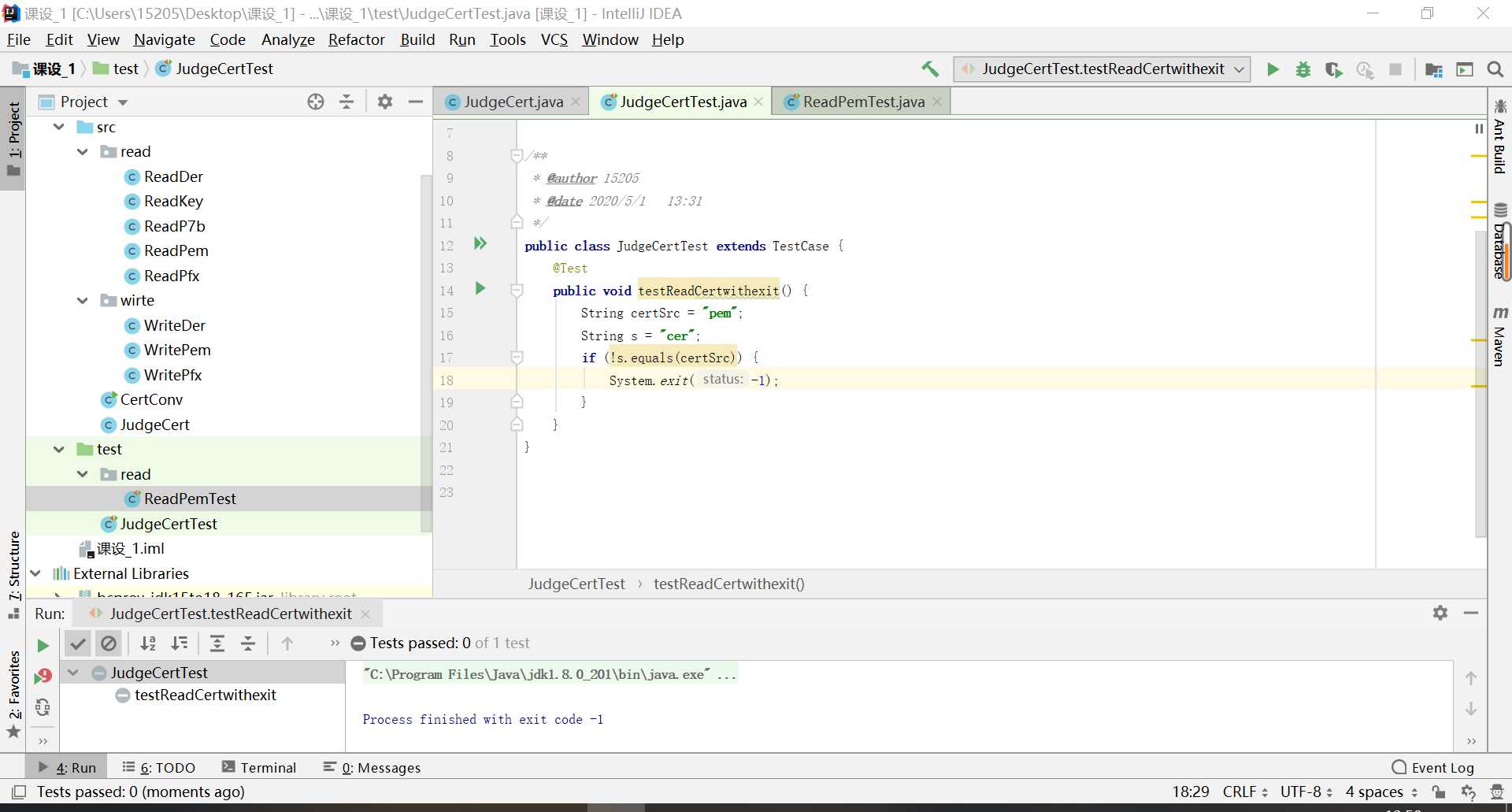
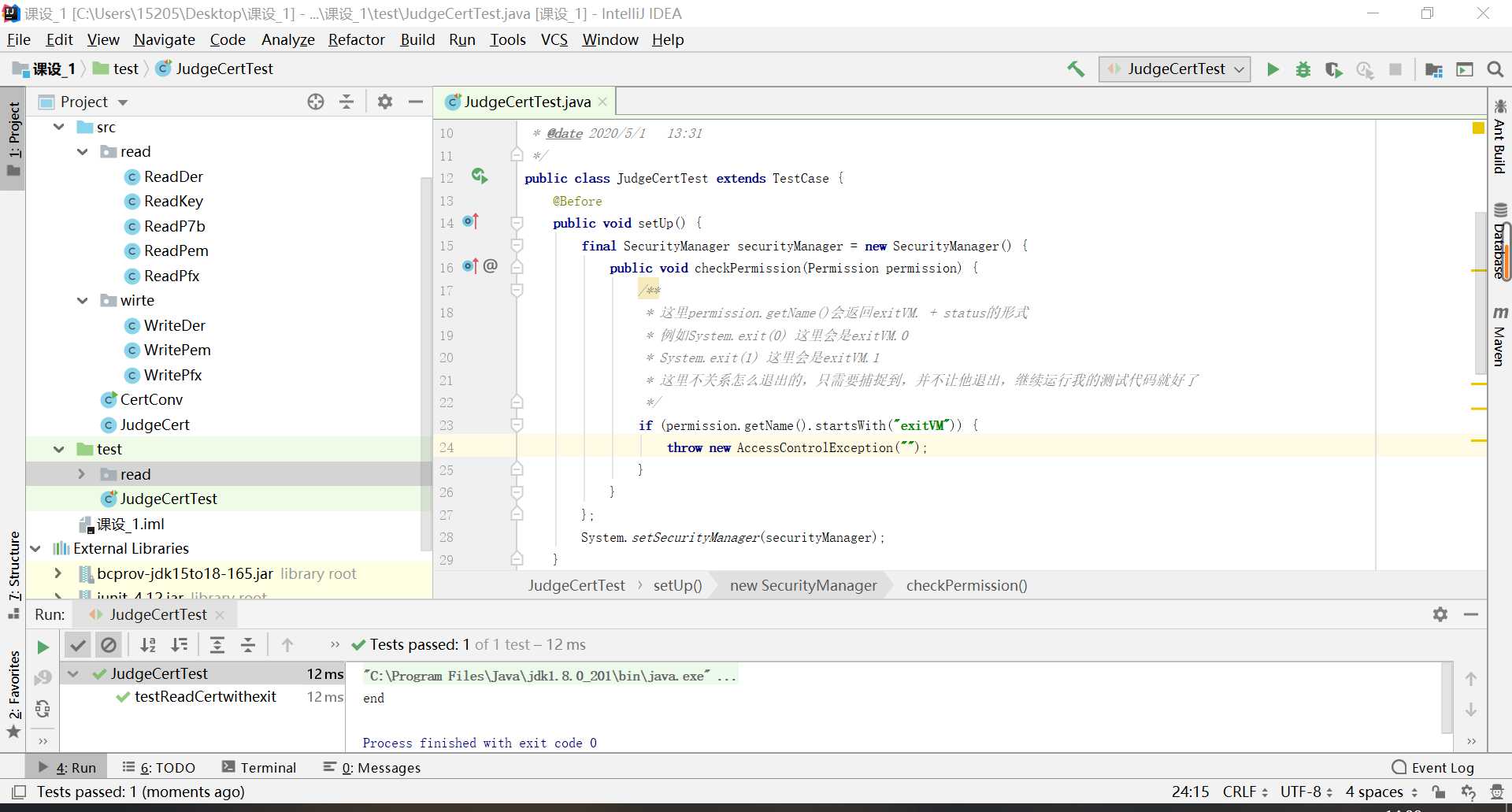
-
使用checkPermission方法内部抛出异常解决
码云链接
参考资料
END
以上是关于COMP9313_WEEK1_2_课程简介的主要内容,如果未能解决你的问题,请参考以下文章