C语言进阶数据的存储
Posted SuchABigBug
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C语言进阶数据的存储相关的知识,希望对你有一定的参考价值。
一、数据在内存中存储
- 一般局部变量是放在栈区上的,栈区的习惯是:先使用高地址,再使用低地址
- 相反数组随着下标的增长,地址是由低到高变化的
int a = 10;
int b = 20;
printf("%p %p\\n", &a, &b);
int arr[] = {10,20};
printf("%p %p \\n", &arr[0], &arr[1]);
Output:

数据在内存中以2进制的形式存储
对于整数来说:
整数二进制有3种表示形式:原码,反码,补码
正整数:原码,反码,补码相同
负整数:原码,反码,补码要进行计算
举个例子:
int a = -10;
原码:
10000000 00000000 000000000 00001010
反码:
11111111 11111111 111111111 11110101
补码:
11111111 11111111 111111111 11110110
F F F F F F F 6
我们可以再举个例子:
1 - 1;
但在计算机中没有减法(CPU只有加法器),只有通过相加也就是1+( -1 )
00000000 000000000 00000000 00000001 // 1的原反补都相同
11111111 111111111 11111111 11111111
00000000 000000000 00000000 00000000 //得到0
二、大小端概念
我们首先要搞清楚给定一个 变量 int a = 0x11223344; 44是低位字序,从右往左变高位字序。
================================
低地址 高地址
11 22 33 44 //大端字节序
44 33 22 11 //小端字节序
================================
大端字节序:把数据的低位字节序的内容存放在高地址处,高位字节序的内容存放在低地址处
小端字节序:把数据的低位字节序的内容存放在低地址处,高位字节序的内容存放在高地址处
三、无符号/有符号

答案是-1 -1 255, 因为第一第二个是有符号,最后一个无符号,整形提升后-1的补码都是1111
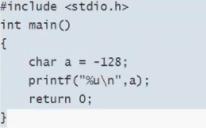
这里的%u表示十进制无符号整形数,而%ld和%d则位十进制有符号整型数
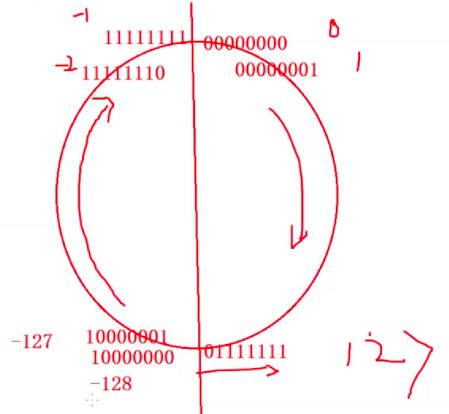
因此这里-128为10000000,这里的char类型是有符号的char发生了整型提升,
高位的1就认为是符号位,补的都是1,因此为11111111 11111111 11111111 10000000
那么算出来就是4,294,967,168
char的无符号的取值范围为-128~127, 而有符号位的最大就是255了。
如果文章对你有帮助来个赞👍 ,Thank you for watching~ 😃
以上是关于C语言进阶数据的存储的主要内容,如果未能解决你的问题,请参考以下文章
我的C语言学习进阶之旅解决 Visual Studio 2019 报错:错误 C4996 ‘fscanf‘: This function or variable may be unsafe.(代码片段
我的C语言学习进阶之旅解决 Visual Studio 2019 报错:错误 C4996 ‘fscanf‘: This function or variable may be unsafe.(代码片段