Netty系列二Netty原理篇
Posted roykingw
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Netty系列二Netty原理篇相关的知识,希望对你有一定的参考价值。
文章目录
配合示例代码。
这一篇主要是来理解Netty的基础架构模型,为下一章节的Netty实战做铺垫。
一、Netty概述
1、关于Netty
Netty的官网地址是 http://netty.io。官网首页就对Netty做了一个整体的介绍:
Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients.
Netty是一个异步、事件驱动的网络应用框架,用于快速开发可维护的高性能协议服务器和客户端。
所以Netty实际上是针对NIO(异步、事件驱动)封装的一个应用框架。他极大的简化java开发TCP、UDP的网络套接字服务。并且,Netty也帮我们考虑到了非常多性能以及可维护性的问题。他总结了非常多的网络应用开发经验,支持非常多的高效网络传输协议,比如FTP、SMTP、HTTP还有WebSocket等常用协议,并且也可以支持自定义协议。
在他的官网,还有一张图整体描述了Netty的组成。这些模块都是我们需要一一了解的地方。
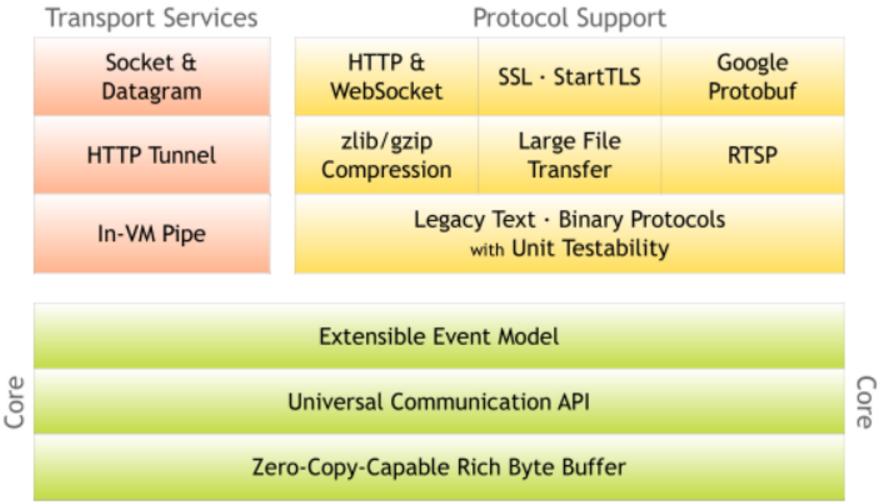
Netty的使用也是非常广泛。但是大部分情况下,我们都很少关注到他的存在。一般的开发过程中,也很少直接使用Netty,但是很多大型的应框架都在用Netty作为底层的IO框架。像Dubbo、RocketMQ、Hadoop、Spark等非常多的成熟框架都在使用Netty作为底层IO框架。而Netty强大的网络协议支持也使得Netty的使用并不受语言的限制。像大型游戏、聊天工具等很多非java的使用场景
然后,关于Netty的版本,Netty现在整体分为3.x和4.x两个大的版本,还有一个5.x版本已经被官方废弃,不再支持。所以现在还是使用4.x版本。目前最新的版本是4.1.65。
二、Netty整体架构设计
1、Reactor模型
Netty是基于NIO做的封装,他也是对传统BIO进行的优化。这里先要简单回顾一下BIO的设计模型。
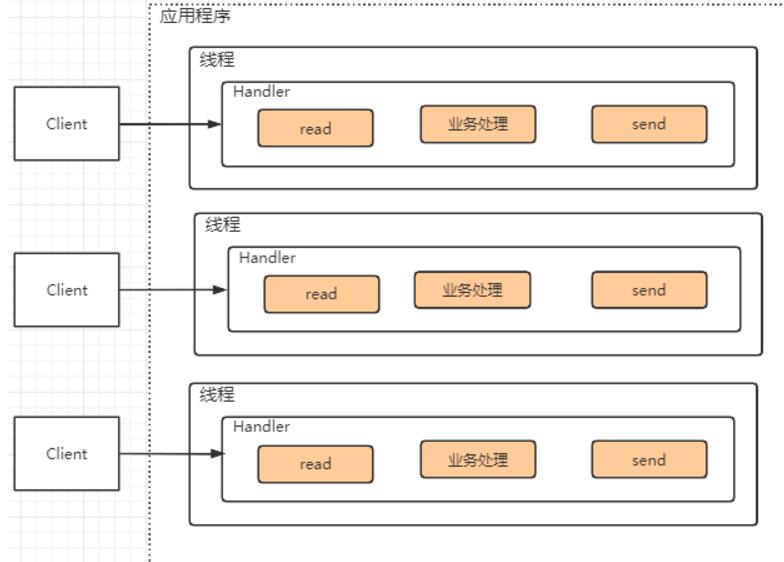
传统BIO模式有两个明显的特点,一是采用阻塞IO的方式获取客户端输入的数据。二是服务端会给每个客户端启动一个独立的线程来完成数据的输入、业务处理、输出这整个过程。
他的问题也很明显:1、当并发数很大时,就会创建大量的线程,占用的资源也会很大。2,连接连接后,如果当前线程暂时没有数据可读,该线程就会阻塞在read操作,造成线程资源浪费。
Netty针对传统BIO的这两个缺点,都有对应的优化方案:1、对于线程过多的问题,采用多路复用机制,多个连接共用一个阻塞对象,应用程序只需要在一个阻塞对象进行等待,无需阻塞等待所有连接。并且,采用事件驱动的机制来处理新的连接请求或者数据请求。阻塞线程可以休眠或者做其他事情,当有请求事件时,由操作系统来通知线程,进行业务处理。这种模式也就成为Reactor模式。2、对于线程资源浪费的问题,基于线程池复用线程资源,可以让一个线程处理多个连接的业务。
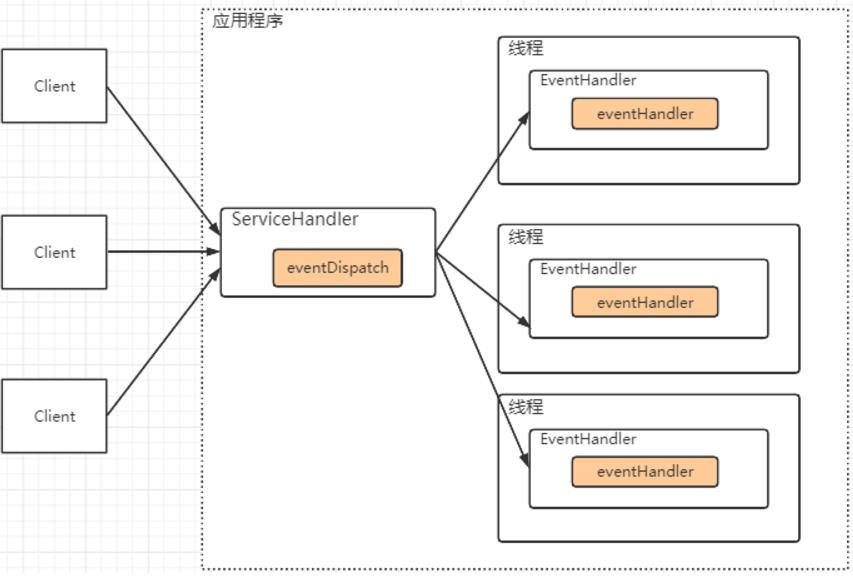
Reactor模式整体上由Reactor和Handler两个核心组件组成。
1、Reactor 在一个单独的线程中运行,负责监听和分发事件,分发给适当的处理程序来对 IO 事件做出
反应。 它就像公司的电话接线员,它接听来自客户的电话并将线路转移到适当的联系人;
2、Handlers:处理程序执行 I/O 事件要完成的实际事件,类似于客户想要与之交谈的公司中的实际官员。Reactor
通过调度适当的处理程序来响应 I/O 事件,处理程序执行非阻塞操作。
2、Reactor模型分类
Reactor模型在具体实现时,会根据Reactor的数量和处理资源的线程池个数,分成三种不同的典型实现方式:
1、单Reactor单线程
2、单Reactor多线程
3、多Reactor多线程
2.1 单Reactor单线程
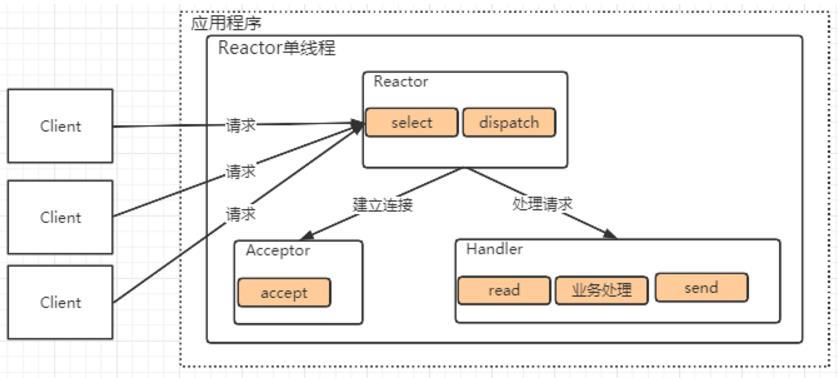
这里面:
1、select就是一个多路复用器。应用程序通过select就可以通过一个阻塞线程来监听多个客户端的连接请求。
2、Reactor对象通过Select监听客户端发送的请求事件,收到请求后通过Dispatch分发。
3、如果是建立连接的请求事件,就会有一个专门的Acceptor来处理请求。并创建一个Handler对象处理连接完成后的后续业务处理。
4、如果不是建立连接事件,则Reactor会分发调用连接对应的Handler来响应。
5、Handler会完成从 read 到 业务处理 再到 send 的完整业务流程。
这种模型的优点是模型简单,所有业务都在一个线程中完成,这样就没有进程通信、线程资源竞争等这些问题。这也导致他的业务处理速度是非常快的。
他的缺点也比较明显:1、性能问题。只有一个线程,无法发挥多核CPU的性能。Handler很容易造成性能瓶颈。这也导致他连接的客户端数量比较少。2、可靠性问题。如果线程出现意外终止或者进入死循环,会导致整个通信系统模块不可用。
我们之间做的NIO的Demo以及聊天室都是属于这种模型。
2.2 单Reactor多线程
单Reactor单线程模型的性能处理瓶颈还是在于Handler。为了提升Handler的性能,就产生了单Reactor多线程模型。
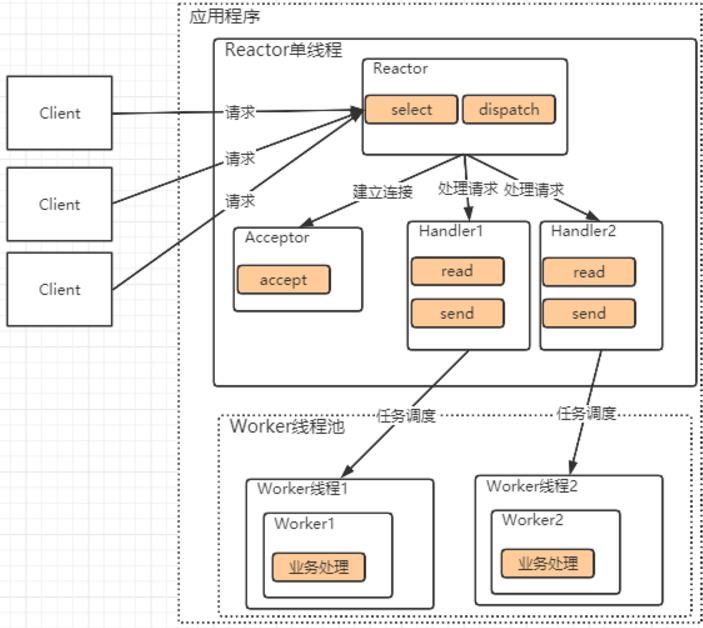
这其中: 对连接请求的处理还是与之前的单Reactor单线程模型一样的。但是在Handler中处理数据请求时,Handler只负责响应事件,不做具体的业务处理。通过read读取数据后,会分发给后面的worker线程池来处理具体业务。而Worker线程池会分配独立线程完整真正的业务,并将结果返回给handler。handler再将响应结果通过send返回给client。
这种模型的优点是可以充分利用多核CPU的处理能力。将最复杂多变的业务处理逻辑由单线程升级为线程池,也给变成模型提供了比较好的扩展性。
而他的缺点主要是多线程数据共享和访问比较复杂。在高并发场景下,业务处理逻辑不再成为性能瓶颈后,reactor单线程处理事件的监听和响应,就容易成为性能瓶颈。
2.3 多Reactor多线程
单Reactor多线程模型的性能瓶颈在于Reactor。为了提升Reactor的性能,就产生了多Reactor多线程模型,或者叫主从Reactor多线程模型:
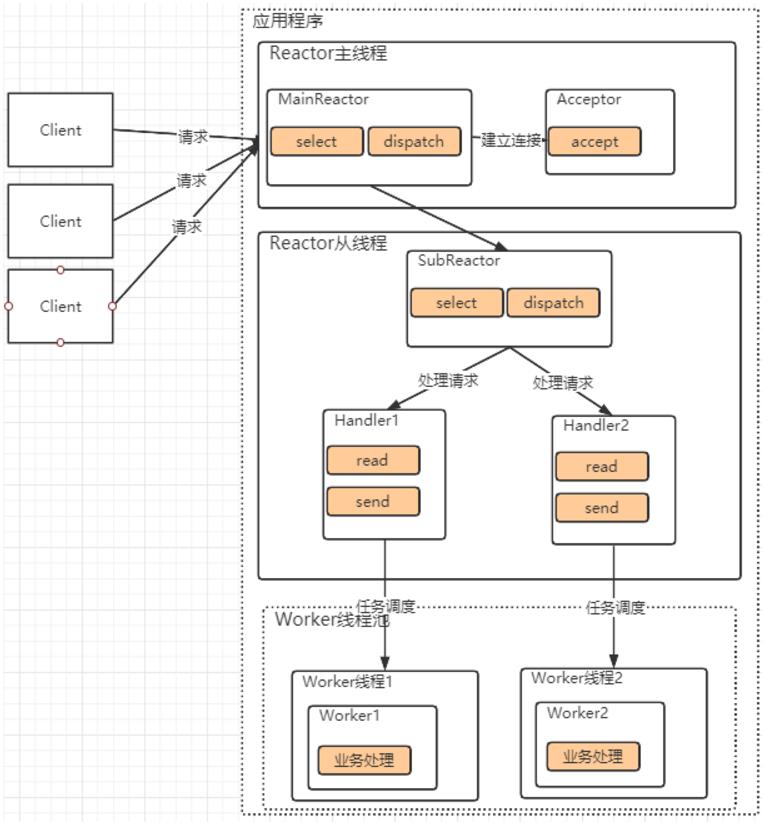
这其中:在之前单Reactor多线程模型的基础上,在原Reactor的基础上增加了一个从Reactor。主Reactor只负责处理连接请求,而数据请求交由从Reactor来进行处理。后续的任务调度方式与之前单Reactor多线程模型是一样的。
这种模型的父线程与子线程的数据交互直接明确,父线程只需要接收新连接,这基本不太会成为性能瓶颈。而子线程完成后续业务处理。然后子线程直接将数据返回给客户端,也不再需要父线程的参与。这样可以通过扩展子Reactor的数量,来提升整体的性能上限。
这也是最为常用的一种网络IO编程模型。网上还有另外一种非常多见的多Reactor描述图:
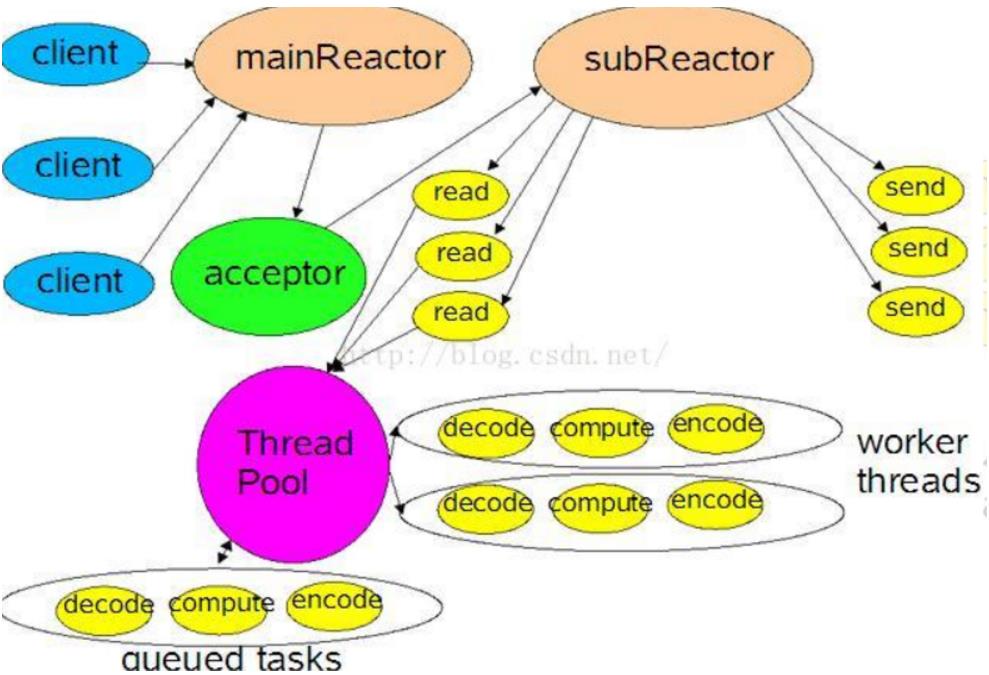
这个图来自于java的IO和并发包的奠基人 Doug Lea。基本的意思还是一样的。
这种模型极大的提升了网络IO的性能,一个server可以非常高效的处理非常多客户端的请求。要说缺点的话,大概就在于编程实现的复杂度比较高。很多经典的应用像 nginx、memcached包括Netty都是采用的这种模型。
三、Netty快速入门
Netty框架就是基于这种多Reactor多线程模型的一种应用框架,他极大的简化了开发过程。他的整体编程模型如下面这个图,对应上一个模型图,还是比较能找到对应关系的
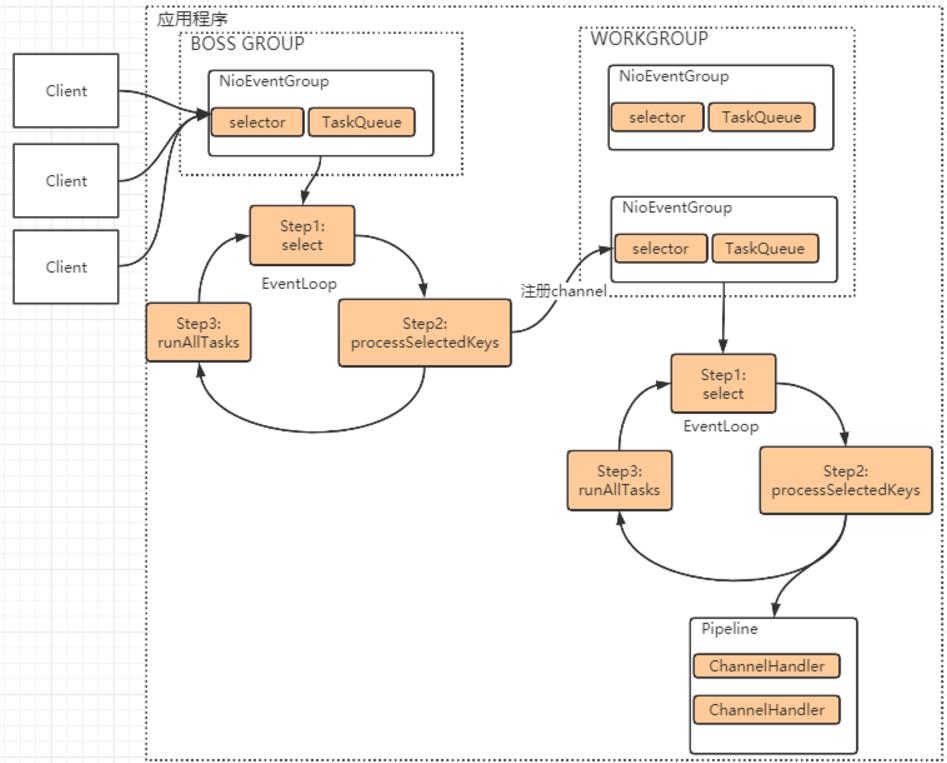
理解了这个图,也就基本理解了Netty应用的大致编程方式:
1、Netty抽象出两组线程池 BossGroup和WorkerGroup(也有叫做ParentGroup,SubGroup)。BossGroup专门负责接收客户端的连接请求,WorkerGroup专门负责网络的数据读写请求。在编程开发时,一般只需要负责声明就可以了,具体他们的分工都是Netty框架帮我们做的事情。
2、BossGroup和WorkerGroup的本质其实是线程池,但是他们的类型是NioEventLoopGroup。
3、NioEventLoopGroup相当于一个事件循环组,组中有多个事件循环,NioEventLoop。
4、NioEventLoop表示一个不断循环的执行处理任务的线程。里面也有一个selector,用于监听并绑定客户端的socket网络连接。
5、WorkerGroup只处理网络的数据读写请求以及与客户端的交互。而业务请求同样交由一个NioEventLoop循环处理。
6、对客户端的数据读写请求都交由一个Pipeline来处理。这个Pipeline可以理解以为一个任务序列,里面每一个 ChannelHandler就是对客户请求信息的一次处理。通常这也是开发Netty应用时主要的定制开发部分。
一般在进行基于Netty的应用开发时,就第1步和第6步需要进行定制开发。其他的部分都是以一种基本的模版式的代码调用NettyAPI,交由Netty来处理即可。
然后,我们可以来写一个简单的Demo体验一下Netty的开发模式。在Demo中的com.roy.netty.basic包下有一个简单的Demo。完成了客户端与服务端的简单双向通信。
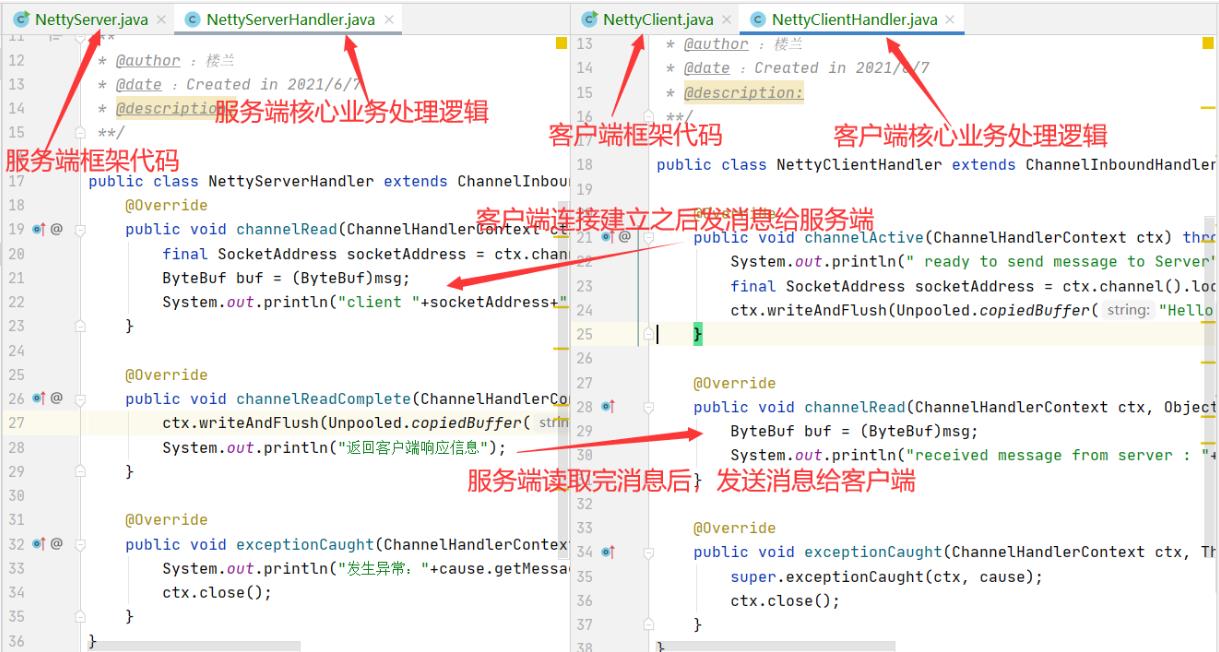
Netty的基础编程模型:
1、服务端使用ServerBootStrap来启动,而客户端使用BootStrap来启动。
2、根据Reactor模型,服务端需要定义两个NIO线程池,BossGroup和WorkerGroup。BossGroup负责连接请求,WorkerGroup负责数据请求。而客户端不需要处理连接请求,只需要一个Group来负责服务端的数据请求即可。
3、给启动器bootstrap设置属性时, channel方法指定通道实现类,服务端设置NioserverSocketChannel.class,客户端使用NioSocketChannel.class。
4、另外bootstrap的其他属性, option表示BossGroup的属性。chileOption表示WorkerGroup的属性。handler表示BossGroup的属性,childHandler表示WorkerGroup的属性。但是BossGroup通常只负责处理连接请求,处理逻辑是比较固定的,所以通常情况下是不需要配置的。当然,如果需要扩展,也可以自行配置。例如Netty提供了一个LoggingHandler来处理log4j的日志记录方式。
5、配置handler一般都是通过定义一个ChannelInitializer来构建任务列表。一般情况下都是通过SocketChannel的pipeline来构建一系列的任务处理列表。这个列表由一系列的Handler组成,每个消息都会经过这些Handler层层处理。这里也是服务定制最多的地方。Netty本身提供了非常多的消息处理器,而具体产品也会扩展出自己的处理器。
6、后面建立的几个绑定端口、等待服务的代码基本上是固定的。绝大部分情况下,就当作模版代码记住就行了。这里由于Netty的所有IO请求都是异步的,所以Netty中需要通过注册监听的方式才能及时把握服务器运行的情况。当然,你也可以使用future.awaitUninterruptibly()方法,强行以同步的方式获取服务运行情况。但是这时官方非常不推荐的。另外对于future,有isDone(),isSuccess(),isCancelled()三种服务状态可以处理。具体可以参见下ChannelFuture.java源码中的注释。
了解了这个简单的Demo后,官方的大部分简单示例也就可以去看了。比如像io.netty.example.discard,io.netty.example.echo等。
四、Netty核心组件
1、BootStrap和ServerBootStrap
这是Netty的启动引导类,服务端与客户端的服务启动过程都通过这个引导类来进行操作。在设置属性时,有几个属性要关注下。
option和childoption用来分别给bossGroup和workerGroup设置属性。所有的属性都在ChannelOptions类当中。这里就总结一下几个常用的属性:
-
ChannelOption SO_BACKLOG
这个是Socket参数,服务端接受连接的队列长度。如果队列已满,客户端连接将被拒绝。默认值 ,windows为200,其他为128。 这个参数还涉及到TCP的三次握手。实际上服务端会维护两个队列,客户端第一次请求后,连接会进入第一个队列,服务端响应连接之后,将连接移动到第二个队列。三次握手连接建立完成后,就从队列中移除,进入后面的WorkGroup了。这个SO_BACKLOG实际上是配置这两个队列的连接数上限。
-
ChannelOption SO_RCVBUF
Socket参数,TCP数据接收缓冲区大小。该缓冲区即TCP接收滑动窗口,linux操作系统可使用命令:cat /proc/sys/net/ipv4/tcp_rmem查询其大小。一般情况下,该值可由用户在任意时刻设置,但当设置值超过64KB时,需要在连接到远端之前设置。
- ChannelOption SO_KEEPALIVE
Socket参数,连接保活,默认值为False。启用该功能时,TCP会主动探测空闲连接的有效性。可以将此功能视为TCP的心跳机制,需要注意的是:默认的心跳间隔是7200s即2小时。Netty默认关闭该功能。
- ChannelOption TCP_NODELAY
TCP参数,立即发送数据,默认值为Ture(Netty默认为True而操作系统默认为False)。该值设置Nagle算法的启用,改算法将小的碎片数据连接成更大的报文来最小化所发送的报文的数量,如果需要发送一些较小的报文,则需要禁用该算法。Netty默认禁用该算法,从而最小化报文传输延时。
常用的属性就总结这几个把。另外,关于其他的所有属性。从网上找了一些资料,仅供参考把。
Channel配置参数:
1、通用参数
CONNECT_TIMEOUT_MILLIS : Netty参数,连接超时毫秒数,默认值30000毫秒即30秒。 MAX_MESSAGES_PER_READ Netty参数,一次Loop读取的最大消息数,对于ServerChannel或者NioByteChannel,默认值为16,其他Channel默认值为1。默认值这样设置,是因为:ServerChannel需要接受足够多的连接,保证大吞吐量,NioByteChannel可以减少不必要的系统调用select。 WRITE_SPIN_COUNT Netty参数,一个Loop写操作执行的最大次数,默认值为16。也就是说,对于大数据量的写操作至多进行16次,如果16次仍没有全部写完数据,此时会提交一个新的写任务给EventLoop,任务将在下次调度继续执行。这样,其他的写请求才能被响应不会因为单个大数据量写请求而耽误。 ALLOCATOR Netty参数,ByteBuf的分配器,默认值为ByteBufAllocator.DEFAULT,4.0版本为UnpooledByteBufAllocator,4.1版本为PooledByteBufAllocator。该值也可以使用系统参数io.netty.allocator.type配置,使用字符串值:"unpooled","pooled"。 RCVBUF_ALLOCATOR Netty参数,用于Channel分配接受Buffer的分配器,默认值为AdaptiveRecvByteBufAllocator.DEFAULT,是一个自适应的接受缓冲区分配器,能根据接受到的数据自动调节大小。可选值为FixedRecvByteBufAllocator,固定大小的接受缓冲区分配器。 AUTO_READ Netty参数,自动读取,默认值为True。Netty只在必要的时候才设置关心相应的I/O事件。对于读操作,需要调用channel.read()设置关心的I/O事件为OP_READ,这样若有数据到达才能读取以供用户处理。该值为True时,每次读操作完毕后会自动调用channel.read(),从而有数据到达便能读取;否则,需要用户手动调用channel.read()。需要注意的是:当调用config.setAutoRead(boolean)方法时,如果状态由false变为true,将会调用channel.read()方法读取数据;由true变为false,将调用config.autoReadCleared()方法终止数据读取。 WRITE_BUFFER_HIGH_WATER_MARK Netty参数,写高水位标记,默认值64KB。如果Netty的写缓冲区中的字节超过该值,Channel的isWritable()返回False。 WRITE_BUFFER_LOW_WATER_MARK Netty参数,写低水位标记,默认值32KB。当Netty的写缓冲区中的字节超过高水位之后若下降到低水位,则Channel的isWritable()返回True。写高低水位标记使用户可以控制写入数据速度,从而实现流量控制。推荐做法是:每次调用channl.write(msg)方法首先调用channel.isWritable()判断是否可写。 MESSAGE_SIZE_ESTIMATOR Netty参数,消息大小估算器,默认为DefaultMessageSizeEstimator.DEFAULT。估算ByteBuf、ByteBufHolder和FileRegion的大小,其中ByteBuf和ByteBufHolder为实际大小,FileRegion估算值为0。该值估算的字节数在计算水位时使用,FileRegion为0可知FileRegion不影响高低水位。 SINGLE_EVENTEXECUTOR_PER_GROUP Netty参数,单线程执行ChannelPipeline中的事件,默认值为True。该值控制执行ChannelPipeline中执行ChannelHandler的线程。如果为Trye,整个pipeline由一个线程执行,这样不需要进行线程切换以及线程同步,是Netty4的推荐做法;如果为False,ChannelHandler中的处理过程会由Group中的不同线程执行。2、SocketChannel参数
SO_RCVBUF Socket参数,TCP数据接收缓冲区大小。该缓冲区即TCP接收滑动窗口,linux操作系统可使用命令:cat /proc/sys/net/ipv4/tcp_rmem查询其大小。一般情况下,该值可由用户在任意时刻设置,但当设置值超过64KB时,需要在连接到远端之前设置。 SO_SNDBUF Socket参数,TCP数据发送缓冲区大小。该缓冲区即TCP发送滑动窗口,linux操作系统可使用命令:cat /proc/sys/net/ipv4/tcp_smem查询其大小。 TCP_NODELAY TCP参数,立即发送数据,默认值为Ture(Netty默认为True而操作系统默认为False)。该值设置Nagle算法的启用,改算法将小的碎片数据连接成更大的报文来最小化所发送的报文的数量,如果需要发送一些较小的报文,则需要禁用该算法。Netty默认禁用该算法,从而最小化报文传输延时。 SO_KEEPALIVE Socket参数,连接保活,默认值为False。启用该功能时,TCP会主动探测空闲连接的有效性。可以将此功能视为TCP的心跳机制,需要注意的是:默认的心跳间隔是7200s即2小时。Netty默认关闭该功能。 SO_REUSEADDR Socket参数,地址复用,默认值False。有四种情况可以使用:(1).当有一个有相同本地地址和端口的socket1处于TIME_WAIT状态时,而你希望启动的程序的socket2要占用该地址和端口,比如重启服务且保持先前端口。(2).有多块网卡或用IP Alias技术的机器在同一端口启动多个进程,但每个进程绑定的本地IP地址不能相同。(3).单个进程绑定相同的端口到多个socket上,但每个socket绑定的ip地址不同。(4).完全相同的地址和端口的重复绑定。但这只用于UDP的多播,不用于TCP。 SO_LINGER Socket参数,关闭Socket的延迟时间,默认值为-1,表示禁用该功能。-1表示socket.close()方法立即返回,但OS底层会将发送缓冲区全部发送到对端。0表示socket.close()方法立即返回,OS放弃发送缓冲区的数据直接向对端发送RST包,对端收到复位错误。非0整数值表示调用socket.close()方法的线程被阻塞直到延迟时间到或发送缓冲区中的数据发送完毕,若超时,则对端会收到复位错误。 IP_TOS IP参数,设置IP头部的Type-of-Service字段,用于描述IP包的优先级和QoS选项。 ALLOW_HALF_CLOSURE Netty参数,一个连接的远端关闭时本地端是否关闭,默认值为False。值为False时,连接自动关闭;为True时,触发ChannelInboundHandler的userEventTriggered()方法,事件为ChannelInputShutdownEvent。3、 ServerSocketChannel参数
SO_RCVBUF 已说明,需要注意的是:当设置值超过64KB时,需要在绑定到本地端口前设置。该值设置的是由ServerSocketChannel使用accept接受的SocketChannel的接收缓冲区。 SO_REUSEADDR 已说明 SO_BACKLOG Socket参数,服务端接受连接的队列长度,如果队列已满,客户端连接将被拒绝。默认值,Windows为200,其他为128。4、DatagramChannel参数
SO_BROADCAST: Socket参数,设置广播模式。 SO_RCVBUF: 已说明 SO_SNDBUF:已说明 SO_REUSEADDR:已说明 IP_MULTICAST_LOOP_DISABLED: 对应IP参数IP_MULTICAST_LOOP,设置本地回环接口的多播功能。由于IP_MULTICAST_LOOP返回True表示关闭,所以Netty加上后缀_DISABLED防止歧义。 IP_MULTICAST_ADDR: 对应IP参数IP_MULTICAST_IF,设置对应地址的网卡为多播模式。 IP_MULTICAST_IF: 对应IP参数IP_MULTICAST_IF2,同上但支持IPV6。 IP_MULTICAST_TTL: IP参数,多播数据报的time-to-live即存活跳数。 IP_TOS: 已说明 DATAGRAM_CHANNEL_ACTIVE_ON_REGISTRATION: Netty参数,DatagramChannel注册的EventLoop即表示已激活。
2、Future和ChannelFuture
Netty中所有的IO操作都是异步的,每一步操作都不能立即得到结果。所以都需要以监听的方式来异步接收操作结果。具体的实现方式就是通过Future和ChannelFuture。常用的方法有 channel()方法返回IO操作的通道。 sync()方法等待异步操作执行完毕。
3、Channel
Channel是Netty进行网络通信的通道,所有的数据交互,IO操作都需要通过channel。跟我们之前在NIO部分的理解是差不多的。
但是在Netty中,Netty支持多种不同的网络协议, TCP、UDP都支持,同时还支持一个SCTP协议,这也是一个网络传输层协议,可以简单认为是一种跟TCP、UDP类似,并且兼有两种协议特征的一种通信协议。不同的协议,数据交互的方式不不同,也就需要有不同的实现类。
- 针对TCP协议,服务端常用NioServerSocketChannel类。 客户端常用NioSocketChannel。
- 针对UDP协议,常用NioDatagramChannel类。
- 针对SCTP协议,服务端常用NioSctpServerChannel,客户端常用NioSctpChannel。
为什么只有UDP的客户端和服务端是使用同一个类?UDP只管传数据,不管是否接收,所以客户端和服务端的处理是一样的。而TCP协议就不通了, 三次握手,四次挥手,客户端和服务端做的事情都是不一样的。
另外,我们这里使用的ServerBootStrap其实都是支持TCP协议的。channel方法需要传入的是一个ServerChannel的实现类。一般情况下都使用NioServerSocketChannel,这表示使用Nio的多路复用器来实现交互,这种机制会按照操作系统不同,去选择对应的多路复用器实现。其他几种机制一般很少用。了解一下就可以了。OioServerSocketChannel这个是Old-Blocking-IO,即传动阻塞的BIO模型。EpollServerSocketChannel 这个是使用Linux的EPoll机制来实现Selector多路复用机制,这种机制可以极大化Selector的性能,但是很明显,他需要操作系统支持。另外还一个KQueueServerSocketChannel是Mac系统下的多路复用机制,同样,他也需要操作系统支持。然后还有SctpServerChannel是支持SCTP协议的Channel。
4、Pipeline和ChannelPipeline
这是整个Netty应用开发过程中最重要的地方。在Netty中,每个SocketChannel都有且仅有一个ChannelPipeline与之对应。他是一个ChannelHandler的集合,负责处理和拦截inbound入站和outbound出站的事件和操作。ChannelPipeline实现了一种高级形式的拦截过滤器模式,用户可以完全控制事务的处理顺序和处理方式,以及各个ChannelHandler之间的交互方式。
他常用的方法就是 addFirst()和addLast()。通过这两个方法来构建一个消息处理链。
5、ChannelHandlerContext
这个对象是在整个Pipeline中传递的上下文,包含了非常多的信息。每个ChannelHandler都会接收这个上下文对象,并进行处理。
常用的方法有 close()关闭通道,channel()获得客户端通道,writeAndFlush()写消息到通道中。
6、ChannelHandler及其实现类
这是整个应用开发过程中最需要定制的地方。ChannelHandler是一个接口,在他下面有两个主要的接口ChannelInboundHandler和ChannelOutboundHandler,分别处理入站事件和出站事件。针对每个接口都有对应的Adapter适配器,一般都是基于这些适配器来扩展自己的业务逻辑。这里面有个ChannelDuplexHandler,他即出了入站事件又处理出站事件,是一个全能的适配器,但是同样的,他的定制开发也是比较复杂的。像RocketMQ中就是从这个ChannelDuplexHandler扩展出自己的Netty服务的。
关于入站和出站是需要特别注意的事情,基本上成型一点的应用都需要做入站和出站处理。比如,网络IO的数据只能是0和1这样的数据流,在Netty中对应ByteBuf对象。而实际业务往往是针对一些数据结构,比如Int,String这样的基础类型或者是POJO这样的自定义类型。这时在做网络传输时,就都需要进行转码。通常服务端接受请求即入站时,需要一系列的decoder将字节流转换成本地数据结构,而服务端往客户端发消息,即出站时,又需要一系列对应的encoder将本地数据结构转换成字节流。
然后,在扩展自己的业务实现时,都会通过自定义一个Handler类,继承对应的Adapter,然后重写对应的方法实现业务逻辑。在这些Adapter的方法中,体现了一个消息在handler中的完整生命周期。业务方法只需要选择对应的业务部分实现即可。
7、EventLoopGroup和其实现类NioEventLoopGroup
EventLoopGroup是一组EventLoop的抽象,Netty为了更好的利用多核CPU资源,一般会有多个EventLoop同时工作,每个EventLoop维护一个Selector实例。通常服务端都会提供两个Group 。BossGroup负责处理客户端的连接请求,并将SocketChannel交给WorkerEventLoopGroup进行IO处理。
EventLoopGroup提供了next接口,可以从组里面按照一定规则获取其中一个EventLoop来处理任务。关于这个next方法,可以简单参看一下DefaultEventExecutorChooserFactory这个类的源码。Netty提供了两种任务选择器来实现这个next方法。 一个是PowerOfTwoEventExecutorChooser,另一个是GenericEventExecutorChooser。如果设置的线程数是2的指数,就使用第一个,否则默认使用第二个。然后他们会有不同的选择下一个线程的实现。其中GenericEventExecutorChooser是所有线程依次轮询的方式。而PowerOfTwoEventExecutorChooser的实现效果是线程两两组合,相互交互2次(也就是总共处理4次)后,转到另外两个线程。这有什么用呢?Netty给NioEventLoopGroup配置的默认线程数是CPU核心数*2。结合这个默认参数,PowerOfTwoEventExecutorChooser实现的效果就是CPU核心的轮询,即让一个CPU核心处理完后,再切换到另一个CPU核心处理。这种方式,线程之间的切换效率比较高,CPU的利用率也就更高,这也是为什么建议配置的线程数是CPU核心数*2的原因。
如何判断一个数字是不是2的指数? return (val & -val) == val;
8、Unpooled类
Netty提供了一个专门的Unpooled类来操作缓冲区,也就是Netty的树容器。他的作用类似于NIO中的ByteBuffer,主要是用来操作Netty中的ByteBuf的。开发中用得比较多的是两个静态方法 wrappedBuffer 和 copiedBuffer。这两个方法都有很多重载的方法。 他们的区别在于,wrappedBuffer是对原数据进行封装,原数据的任何改动都会直接影响得到的ByteBuf。而copiedBuffer是对原数据进行复制,原数据的改动不会影响ByteBuf。所以通常情况下用copiedBuffer方法比较多。
另外,他与NIO的ByteBuffer的一个很明显的区别在于,NIO的ByteBuffer在读写操作切换时需要调用一下flip()方法进行模式反转。但是Netty的ByteBuf就不需要读写切换。这是因为在Netty的ByteBuf中为读写操作单独维护了readerIndex和writerIndex两个标志位。每次wirteByte()后,会把writerIndex往后移动一位,直到达到容量上限capacity()。再接下来每次readByte(),就会把readerIndex往后移动一位,直到达到writerIndex所在的位置。
总结
通过这一章节,对Netty的基础原理有了部分理解,也需要结合一些简单的Demo完成简单的IO交互。接下来,就可以进入实战部分,处理更复杂的网络场景,在实战部分对这些底层原理进行进一步的理解。
以上是关于Netty系列二Netty原理篇的主要内容,如果未能解决你的问题,请参考以下文章