Elasticsearch初步学习(仿京东搜索爬虫)
Posted 程序dunk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch初步学习(仿京东搜索爬虫)相关的知识,希望对你有一定的参考价值。
个人博客欢迎访问
微信搜索程序dunk,关注公众号,获取项目、博客源码
我们面前无所不有,我们面前一无所有 ——查尔斯·狄更斯
目录
大数据背景介绍
Lucene作者 Doug Cutting
搜索引擎发展史
正如查尔斯·狄更斯在《双城记》中所述,在信息爆炸的当下,我们面前无所不有;而个人信息过载已经成为越来越多的人的负担,我们面前一无所有
如何摆脱过载的信息束缚,高效地找到自己需要的信息呢?——答案就是搜索引擎,借助搜索引擎实现
搜索引擎分类
宏观而言,搜索引擎的发展经历了五个阶段和两大类
五个阶段
- FTP文件检索阶段:搜索引擎会告诉用户从哪一个FTP地址可以下载被搜索的文件,代表作:Archie
- 分类目录导航阶段:该阶段的搜索引擎就是一个导航网站,网站中都是网址分类陈列,用户在互联网上常用的网址在这里一应俱全,我们常用的好123、搜狗浏览器主页、UC导航等都是这类导航页面
- 文本相关性检索阶段:引入了全文搜索技术,来保证搜索引擎检索到的网页标题和网页内容强一致,摒弃了单纯依赖网页标题和网页地址来判断网页内容的方法,代表作是Alta Vista、Excite等
- 网页链接分析阶段:
- 这个阶段的搜索引擎所使用的网站链接形式与当前基本相同,在该阶段,外部链接表示推荐
- 因此通过计算每个网站的推荐链接数量,就可以判断一个网站的流行性和重要性
- 于是,搜索引擎通过结合网页内容的重要性和相似度来改善搜索的信息质量
- 代表作:Google
- 用户意图识别阶段
- 以用户为中心作为设计的初心,搜索引擎力求理解每一位用户的真正搜索诉求,力求千人千面,追求个性化识别和反馈
- 比如输入”小米“,想要一个小米电子产品的用户和一个想要购买小米视频的用户,他们的搜索结果不同
两大类
- 站内搜索:
- 近几年发展比较迅猛,各大网站平台纷纷上线了转内搜索,如SNS平台中的微博、人人网等,如电商平台中的京东、淘宝等
- 另外,区块链内容搜索是近两年新的站内搜索形式,比如比特币区块链的搜索内容在比特币公链上,但比特币共公链的节点所在的区域却是分布式的
- 站外搜索:全网搜索,如谷歌、百度等等
Elasticsearch
简介
- Elasticsearch是一个分布式、高扩展、高实时的搜索与数据分析引擎。
- Elasticsearch提供了搜集、分析、存储数据三大功能,其主要特点有:分布式、零配置、易装易用、自动发现、索引自动分片、索引副本机制、RESTful风格接口、多数据源和自动搜索负载
- Elasticsearch并非从零起步,而是站在巨人的肩膀上。Elasticsearch基于Java编写,其内部使用Lucene做索引与搜索。通过进一步封装Lucene,向开放人员屏蔽了Lucene的复杂性只需要使用一套简单一致的RESTfulAPI即可。
- 除此之外,Elasticsearch还解决了检索相关数据、返回统计结果、响应速度等相关问题,因此Elasticsearch能做到分布式环境下的实时文档存储和实时分析搜索。实时存储文档,每个字段都可以被索引与搜索
- Elasticsearch能都胜任成百上千个服务节点的分布式扩展,支持PB级别结构化或者非结构化海量数据的处理
- 7.0版本中引入内存断路器、引入Elasticsearch的全新集群协调层——Zen2、支持更快的前k个查询、引入Function score2.0等,提高了可用性、性能和用户体验,使Elasticsearch变得更快、更安全、更易于使用
Lucene和Elasticsearch的关系
- Lucene是一个免费、开源、高兴能、纯java编写的全文搜索引擎
- Lucene是Apache的顶级项目
- ElasticSearch 和 Solr 都是基于 Lucene 的搜索引擎,是对 Lucene 的封装,Lucene仅仅是一个工具包,它并非一个完整的全文搜索引擎,这个Lucene的初衷有关,Lucene主要问软件开发人员提供一个简单易用的工具包,主要提供倒排索引的查询,以便软件开发人员在其业务系统中实现全文搜索功能
使用场景
站内搜索,用户行为,社交数据,异常讨论,开源代码,电商商品,日志分析,价格监控,商业智能等等
Elasticsearch和Solr的区别
- 当单纯的对已有数据进行搜索时,Solr 更快
- 当实时建立索引时,Solr 会产生 io 阻塞,查询性能较差,ElasticSearch 具有明显的优势
- 随着数据量的增加,Solr 的搜索效率会变得更低,而 ElasticSearch 却没有明显的变化
- 转变搜索基础设施后从 Solr 到 ElasticSearch 可以大幅度提高搜索性能
- ElasticSearch 开箱即用,Solr 需要安装
- Solr 利用 Zookeeper 进行分布式管理,而 ElasticSearch 自身带有分布式协调管理功能
- Solr 支持更多格式的数据,例如 JSON、XML、CSV,而 ElasticSearch 仅支持 JSON 文件格式
- Solr 官方提供的功能更多,而 ElasticSearch 本身更注重于核心功能,高级功能多由第三方插件提供,例如图形化界面需要 kibana 友好支撑
- Solr 查询快,但更新索引时慢,用于电商等查询多的应用。ElasticSearch 建立索引快即实时性查询快,用于 facebook、新浪等搜索应用
- Solr 是传统搜索应用的有力解决方案,ElasticSearch 更适用于新兴的实时搜索应用
REST是什么
REST的英文是Representational State Transfer,中文翻译”表述性状态转移“,一种软件架构风格、设计风格,而不是标准,只是提供了一组设计原则和约束条件,是所有Web应用都应该遵守的架构设计指导原则。它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
REST的关键原则
- Resource(资源):表示为所有事务定义ID
- Hypertext Driver(超文本驱动):表示所有事物链接在一起
- Uniform Interface(统一接口):表示使用标准的方法
- Representation(资源的表述):表示资源多重表述的方法
- State Transfer(状态转移):表示无状态通信
Resource
资源其实可以看做一种看待服务器的方式
- 一个资源可以由一个或者多个URI来标识。URI既是资源的名称,也是资源在Web上的地址,对某个资源感兴趣的客户端,可以通过资源的URI与其进行交互访问并获取
- 将服务器看做由很多离散的资源组成,资源可以是一文件系统的一个文件,也可以是数据库中的一张表
- 资源意味着为所有事务定义ID,在Web开发中,每个事务都是可被标志的,都会拥有一个ID,代表ID的统一概念是URI
- URI(Uniform Resource Identifier):统一资源标识符,包括URL和URN
- URL(Uniform Resource Locator):统一资源定位符,常见的有Web URL和FTP URL
- URN(Uniform Resource Name):统一资源名称,例如:tel:+1-888-888-8888
- URI(Uniform Resource Identifier):统一资源标识符,包括URL和URN
- 设计URI的四个原则
- 它们是名词
- 区分单复数
- URI有长度限制,建议小于1KB
- 在URI中不要放未加密的敏感信息
超文本驱动
意味着所有事物链接在一起
- 核心就是超媒体,换句话说就是链接的思想
- 引入链接后,Web应用可以看做一个有很多状态组成的有限状态机,资源之间通过超链接相互关联
- URI是全球表针,所以构成Web的所有资源都是可以相互连通的
- 客户端可以通过链接将应用从一个状态转变为另一个状态
统一接口
统一接口意味着使用标准的方法
四个HTTP方法:POST、GET、PUT、DELETE
Elasticsearch中的Rest命令说明
| method | url地址 | 描述 |
|---|---|---|
| PUT | localhost:9200/index/type/documentId | 创建文档(指定文档id) |
| POST | localhost:9200/index/type/ | 创建文档(随机文档id) |
| POST | localhost:9200/index/type/documentId/_update | 修改文档 |
| DELETE | localhost:9200/index/type/documentId | 删除文档 |
| GET | localhost:9200/index/type/documentId | 查询文档通过文档id |
| POST | localhost:9200/index/type/_search | 查询所有数据 |
资源表述
资源的表示是对一段资源在某个特定时刻的状态的描述。资源可以在客户端——服务器之间传递
资源的表述有很多格式:html、XML、JSON、文本、图片、音频、视频等
状态转移
意味着无状态通信
无状态即服务器的变化 对客户端是不可见的,主要为了保证架构设计的可伸缩性和可扩展
搜索技术基本知识
数据搜索方式
搜索引擎主要是对数据进行检索。而研发过程中不难发现,数据有两种类型,即结构化数据和非结构化数据
- 结构化
- 结构化数据:结构化数据一般我们会放入关系性数据库如mysql和Oracle等,这是因为结构化数据有固定的数据格式和有限个数的字段,因此通过二维化的表结构来承载
- 结构化搜索:因为关系型数据库往往支持索引,因此结构化数据可以通过关系型数据库来完成搜索和查找,常用的方式有顺序扫描、关键字精确匹配等,对于复杂的关键字匹配可以使用like关键字匹配
- 非结构化
- 非结构化数据:非结构化数据一般会放入MongoDB中,这是因为非结构化数据的数据长度不定且无固定数据格式
- 非结构化搜索:对于非结构化数据而言,顺序扫描是效率很低的方法,因此引入全文搜索技术
- 全文搜索过程中,一般需要提取非结构化数据中的有效信息,重新组织数据的承载结构形式,而检索数据时,需要基于新结构化数据展开,从而达到提高搜索速度的目的(空间换时间的做法)
搜索引擎的工作原理
搜索引擎的工作原理
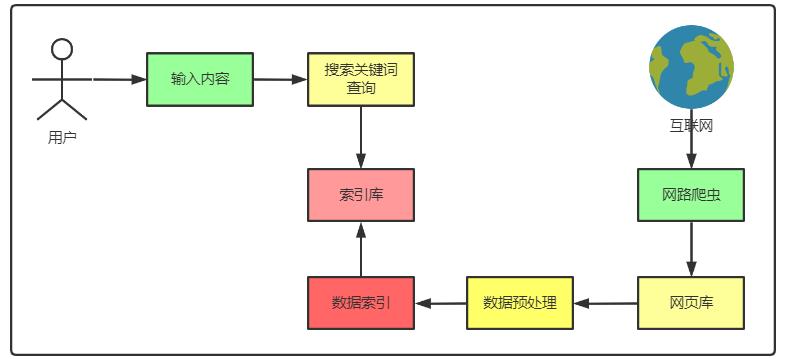
搜索引擎的工作原理分为两个阶段
- 网页数据爬取和索引阶段
- 网络爬虫用于爬取互联网上的网页,爬取到一个新的网页后继续通过该页面中的链接爬取其他网页
- 网页被网络爬虫爬取后,会被存入网页库,以备进行数据预处理,因为页面有一定的重复性,所以在把新的网页插入网页库之前需要查重
- 预处理不断地从网页中取出网页进行必要的预处理,取出噪声内容(广告、导航条、声明文字)、关键词处理、网页链接关系计算等,此外,网页上还有文件文档(PDF、WORD、WPS等)、多媒体文件等,都需要预处理
- 预处理后,要进行索引过程,索引过程先后经历正向索引和倒排索引阶段,最终简历索引库,随着不断的加入网页库,索引库的更新和维护往往也是增量进行的
- 搜索阶段
- 用户输入的关键字同样会经过预处理,如删除不必要的标点符号、停用词、空格等
- 然后从索引库中查询需要的内容进行排序,返回给用户
网络爬虫工作原理
网络爬虫有多个不同称谓,如网络探测器、Spider蜘蛛等,取意的原因是网页爬取程序像虫子一样在网络间爬来爬取,从一个网页链接爬到另一个网页链接
- 网络爬虫用于爬取互联网上的网页,爬取到一个新的网页后继续通过该页面中的链接爬取其他网页,如此循环,直到所有的内容都被爬取完
- 为了提高效率,一般采用并行爬取的方式,多个网络爬虫在并行爬取过程中,不重复的爬取一个网页尤为重要
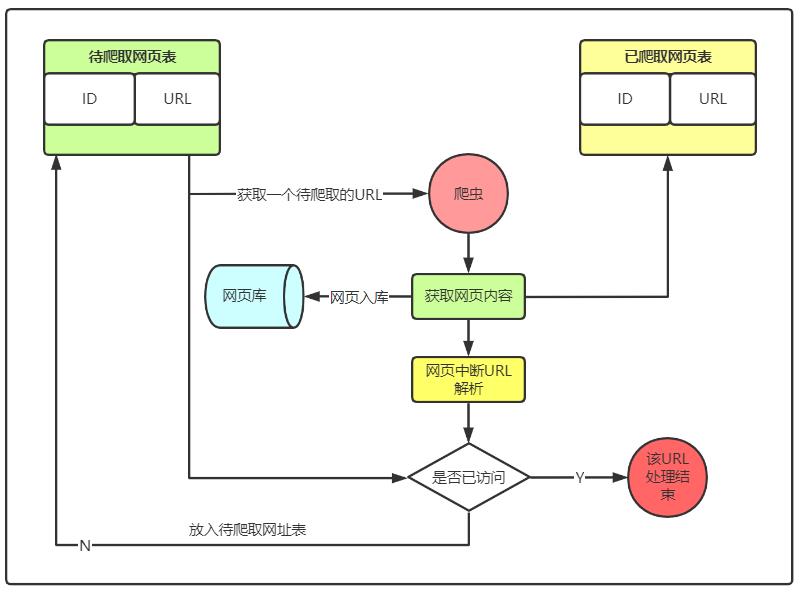
- 网页爬取的方式
- 先深度后广度(一般采用)
- 先广度后深度
- 收录模式
- 增量收集:搜索新的网页,搜集更新,不覆盖,设计复杂、时效性好
- 全量收集:更新全部数据,开销大、成本高、时效性不高、网路带宽消耗大、耗时比较长,一般都是定期展开
我们可以基于现有的爬虫框架来实现对网络数据的爬取,java语言技术栈可以使用WebMagic、Gecco;Python语言栈使用Scrapy;GO语言使用YiSpider
网页分析
在搜索引擎中,爬虫爬取了对应的网页之后,会将网页存储到服务器的原始数据库中,之后,搜索引擎会对这些网页进行分析并确定各网页的重要性,即会影响用户检索的排名结果
所以在此,我们需要对搜索引擎的网页分析算法进行简单了解
搜索引擎的网页分析算法主要分为3类:基于用户行为的网页分析算法、基于网络拓扑的网页分析算法、基于网页内容的网页分析算法
- 基于用户行为的网页分析算法:基于用户行为的网页分析算法是比较好理解的。这种算法中,会依据用户对这些网页的访问行为,对这些网页进行评价,比如,依据用户对该网页的访问频率、用户对网页的访问时长、用户的单击率等信息对网页进行综合评价
- 基于网络拓扑的网页分析算法:基于网络拓扑的网页分析算法是依靠网页的链接关系、结构关系、已知网页或数据等对网页进行分析的一种算法,所谓拓扑,简单来说即结构关系的意思
- 基于网页粒度的分析算法
- 基于网页块粒度的分析算法
- 基于网站粒度的分析算法
- PageRank算法是一种比较典型的基于网页粒度的分析算法。相信很多朋友都听过Page-Rank算法,它是谷歌搜索引擎的核心算法,简单来说,它会根据网页之间的链接关系对网页的权重进行计算,并可以依靠这些计算出来的权重,对网页进行排名
- 基于网页内容的网页分析算法:在基于网页内容的网页分析算法中,会依据网页的数据、文本等网页内容特征,对网页进行相应的评价
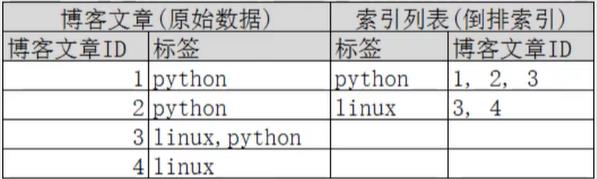
倒排索引
正向索引
在搜索引擎中每个文件都对应一个文件ID,文件内容被表示为一系列关键词的集合(实际上在搜索引擎索引库中,关键词也已经转换为关键词ID)。例如“文档1”经过分词,提取了20个关键词,每个关键词都会记录它在文档中的出现次数和出现位置。
正向索引的结构
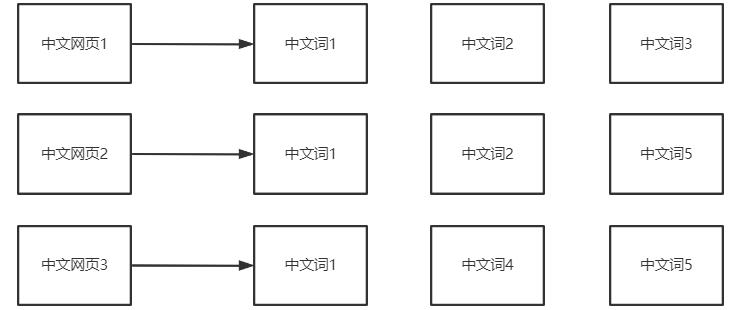
一般是通过key,去找value。
倒排索引
所以,搜索引擎会将正向索引重新构建为倒排索引,即把文件ID对应到关键词的映射转换为关键词到文件ID的映射,每个关键词都对应着一系列的文件,这些文件中都出现这个关键词。
得到倒排索引的结构如下:
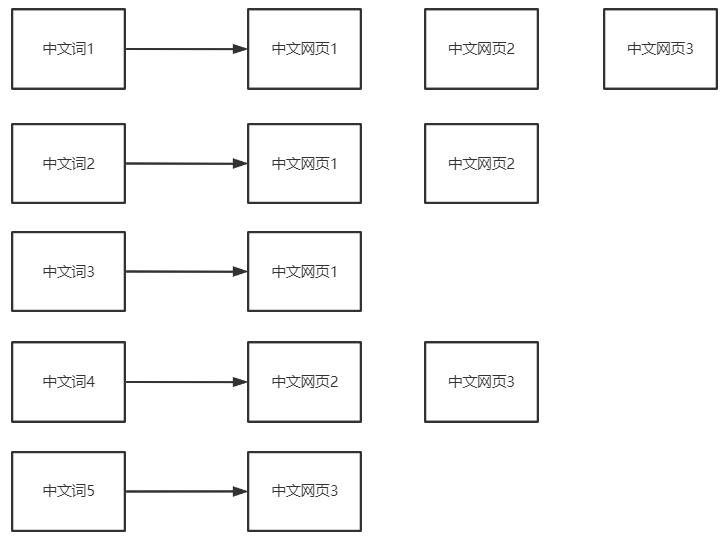
基于词做索引明显比基于字做索引内容要少的多,因而查询会更高效(所以引入了中文分词器(ik分词器))
倒排序中三个名词
- 词条(Term):索引里面最小的存储单元和查询单元,英文环境就是一个单词,中文环境词条指的是分词后的一个词组
- 字典(Term Dictionary):词条的集合,一般由网页或者文章集合中出现过的所有词构成的字符串集合
- 倒序表(Post List):记录词出现在那些文档里、出现的位置和频率等,如下图
安装
ElasticSearch下载
熟悉目录
bin: 启动文件config: 配置文件log4j: 日志文件jvm.options: java 虚拟机先关的配置elasticsearch.xml: elasticsearch 的配置文件lib: 相关 jar 包logs: 日志modules: 功能模块plugins: 插件 ik
安装elasticsearch-head-master
启动elasticsearch-head-master
cnpm install
npm run start
开启跨域配置
\\elasticsearch-7.13.1\\config\\elasticsearch.yml
#开启http跨域
http.cors.enabled: true
#允许所有人可以访问
http.cors.allow-origin: "*"
访问9200端口
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FoZteADV-1623243865535)(https://gitee.com/zhang-songyao/blog-images/raw/master/20210606145636.png)]
安装Kibana
汉化插件
\\kibana-7.13.1-windows-x86_64\\config\\kibana.yml
i18n.locale: "zh-CN"
ES核心概念
ElasticSearch是面向文档的,关系型数据库和ElasticSearch客观对比
| Relational DB | ElasticSearch |
|---|---|
| 数据库(Database) | 索引(index) |
| 表(table) | types(慢慢废弃) |
| 行(rows) | 文档(documents) |
| 字段(columns) | fields |
ElasticSearch集群中可以包含多个索引(数据库),每个索引可以包含多个类型(表),每个类型下可以包含多个文档(行),每个文档中可以包含多个字段(列)
物理设计
ElasticSearch在后台吧多个所以划分成多个分片,每个分片可以在集群中的不同服务器迁移
逻辑分页
一个类型中,包含多个文档,比如说文档1,文档2,当我们索引一篇文档时,可以通过这样的顺序找到它:索引>类型>文档ID,通过这个组合我们就能索引到某个具体的文档。注意:ID不必是整数,实际上它是个字符串
文档
文档(Document):一般搜索引擎的处理对象是互联网网页,而文档这个概念要更宽泛些,代表以文本形式存在的存储对象,相比网页来说,涵盖更多种形式,比如Word,PDF,html,XML等不同格式的文件都可以称之为文档。再比如一封邮件,一条短信,一条微博也可以称之为文档。在本书后续内容,很多情况下会使用文档来表征文本信息
ElasticSearch中,文档有几个重要属性:
- 自我包含,一篇文档同时包含字段和对应的值,也就是同时包含keyvalue!
- 可以是层次型的,一个文档中包含自文档,复杂的逻辑实体就是这么来的!(就是一个JSON对象,FastJson进行转换!)
- 灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在elasticsearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
尽管我们可以随意的新增或者忽略某个字段,但是,每个字段的类型非常重要,比如一个年龄字段类型,可以是字符串也可以是整形。因为ElasticSearch会保存字段和类型之间的映射及其他的设置,这种映射具体到每个映射的每种类型,这也是为什么在ElasticSearch中,类型有时候也称为映射类型。
类型
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。类型中对于字段的定义称为映射,比如name映射为字符串类型。我们说文档是无模式的,它们不需要拥有映射中所定义的所有字段,比如新增一个字段,那么 ElasticSearch是怎么做的呢?
ElasticSearch会自动的将新字段加入映射,但是这个字段的不确定它是什么类型, ElasticSearch就开始猜,如果这个值是18,那么ElasticSearch会认为它是整形,但是 ElasticSearch也可能猜不对,所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后再使用
索引
就是数据库
索引是映射类型的容器, ElasticSearch中的索引是一个非常大的文档集合,索引存储了映射类型的字段和其他设置。然后它们被存储到了各个分片上了。我们来研究下分片是如何工作的
物理设计:节点和分片如何工作
一个集群至少有一个节点,而一个节点就是一个 ElasticSearch进程,节点可以有多个索引默认的,如果你创建索引,那么索引将会有个5个分片( primary shard又称主分片)构成的,每个主分片会有一个副本( replica shard,又称复制分片)
主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不至于丢失。实际上,一个分片是一个 Lucene索引,一个包含倒排索引的文件目录,倒排索引的结构使得 ElasticSearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字
ELK简介
ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件。新增了一个FileBeat,它是一个轻量级的日志收集处理工具(Agent),Filebeat占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具。
Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
Filebeat隶属于Beats。目前Beats包含四种工具:
- Packetbeat(搜集网络流量数据)
- Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
- Filebeat(搜集文件数据)
- Winlogbeat(搜集 Windows 事件日志数据)
IK分词器
安装
注意版本一定要和ElasticSearch版本一致!!!!
解压放在\\elasticsearch-7.13.1\\plugins\\ik目录下,注意是编译打包过得文件
重启ElasticSearch,插件加载完毕

通过elasticsearch-plugin插件查看加载的插件

什么是分词器
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,比如”我爱长安”会被分为”我”、”爱”、”长”、”安”、这显然是不符合要求的,所以我们需要安装中文分词器来解决这个问题
iK提供了两个分词算法: ik_smart(最小分词器)和 ik_max_word(最细粒度划分),其中 ik_smart为最少切分, ik_max_word为最细粒度划分
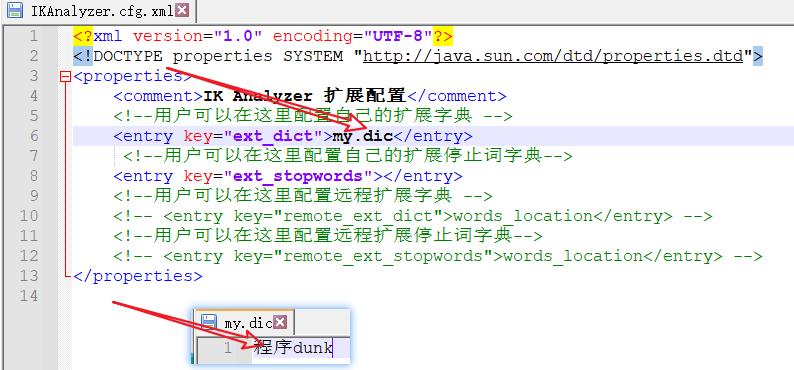
扩展字典
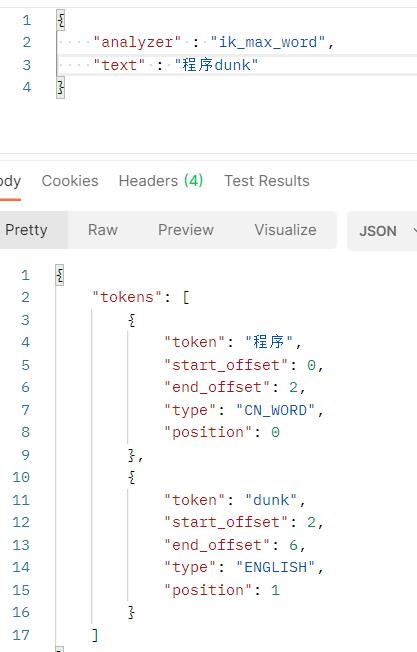
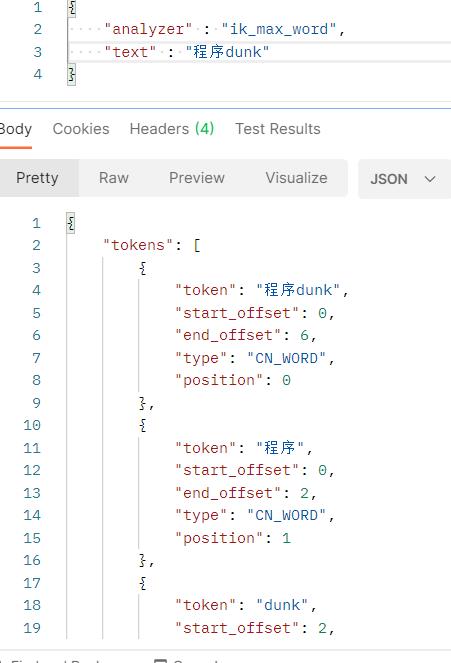
使用分词器查询程序dunk可以看到
GET _analyze
{
"analyzer" : "ik_max_word",
"text" : "程序dunk"
}
如果想要吧程序dunk当做一个词语,那么需要在elasticsearch-7.13.1\\plugins\\ik\\config路径下自己扩展字典
重启服务,可以看到分词器,将程序dunk单独划分了出来
索引的操作
添加索引、同时添加数据
PUT test1/type1/1
{
"name" : "dunk_code",
"age" : 18
}
单纯创建索引
PUT test2
{
"mappings": {
"properties": {
"name" : {
"type": "text"
},
"age" : {
"type": "long"
},
"birthday" : {
"type": "date"
}
}
}
}
修改索引的值
POST /test1/type1/1/_update
{
"doc" : {
"name" : "程序dunk"
}
}
删除索引
DELETE test1/type1/1
查询
//查询该索引的信息
GET test1/
//查询索引下指定文档id信息
GET test1/type1/1
//精确查询name为dunk_code的信息
GET test1/type1/_search?q=name : dunk_code
复杂搜索
创建索引
PUT /xauat/student/1
{
"name" : "程序dunk",
"age" : 21,
"desc" : "必进大厂",
"tags" : ["编程", "篮球", "游戏"]
}
匹配查询
_query
GET /xauat/student/_search
{
"query" : {
"match": {
"name" : "程序"
}
}
}
结果过滤
_source:保留那些数据
"_source" : ["name","desc"]
排序
sort
"sort" : [
{
"age" : {
"order" : "asc"
}
}
]
分页
from :开始页
size:页码
"from" : 0,
"size" : 2
布尔值查询
must : and
GET /xauat/student/_search
{
"query" : {
"bool": {
"must": [
{
"match" : {
"name" : "dunk"
}
},
{
"match": {
"age" : 30
}
}
]
}
}
}
should:or
GET /xauat/student/_search
{
"query" : {
"bool": {
"should": [
{
"match" : {
"name" : "dunk"
}
},
{
"match": {
"age" : 30
}
}
]
}
}
}
must_not:not
过滤条件
filter
GET /xauat/student/_search
{
"query" : {
"bool": {
"must": [
{
"match" : {
"name" : "dunk"
}
}
],
"filter": {
"range" : {
"age" : {
"gte" : 21,
"lte" : 30
}
}
}
}
}
}
- gt:大于
- gte:大于等于
- lt:小于
- lte:小于等于
- eq:相等
精确查询
term 查询是直接通过倒排索引指定的词条进行精确查找!
关于分词:
- term:直接查询精确的
- match : 会使用分词器解析
两个类型 text keyword
- text 会被分词器解析
- keyword 不会被分词器解析
高亮查询
高亮:highlight
前缀:pre_tags
后缀:post_tags
GET /xauat/student/_search
{
"query" : {
"term": {
"name" : "dunk"
}
},
"highlight" : {
"pre_tags": "<p class='key' style='color:red'>",
"post_tags": "</p>",
"fields": {
"name" : {}
}
}
}
SpringBoot集成ElasticSearch
创建SpringBoot项目
导入SpringData Elasticsearch依赖

索引操作
@Test
//创建索引
void testCreateIndex() throws IOException {
CreateIndexRequest request = new CreateIndexRequest("xauat");
client.indices().create(request, RequestOptions.DEFAULT);
}
@Test
//判断是否存在索引
void isExistIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("xauat");
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
@Test
//删除索引
void deleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("xauat");
AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);
System.out.println(delete.isAcknowledged());
}
文档操作
@Test
//创建文档
void createDocument() throws IOException {
//创建请求
IndexRequest request = new IndexRequest("xauat");
//创建对象
Student student = new Student("王五",
40, "编程大佬", Arrays.asList("编程", "学习"));
//设置请求
request.id("6");
request.timeout(TimeValue.timeValueMillis(1));
//将数据转为json格式放入请求
request.source(JSON.toJSONString(student), XContentType.JSON);
//发送请求
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
//获取响应结果
System.out.println(indexResponse.toString());
//响应状态
System.out.println(indexResponse.status());
}
@Test
//获取文档
void getDocument() throws IOException {
GetRequest request = new GetRequest("xauat", "6");
//判断是否存在
boolean exists = client.exists(request, RequestOptions.DEFAULT);
System.out.println(exists)以上是关于Elasticsearch初步学习(仿京东搜索爬虫)的主要内容,如果未能解决你的问题,请参考以下文章