电子病历实体识别数据处理多个文件读取
Posted 炫云云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了电子病历实体识别数据处理多个文件读取相关的知识,希望对你有一定的参考价值。
数据格式
电子病历包含四个部分:

每个部分都有相关的病历和实体标签:


其中病史特点-1.txt等格式是病历实体标签内容:
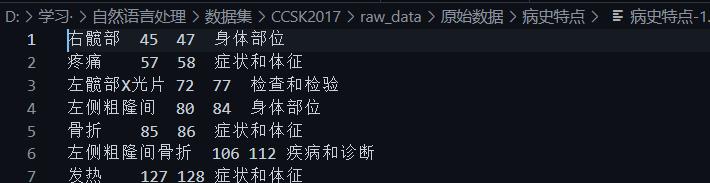
其中病史特点-1.txtoriginal.txt等格式是病历内容:

数据描述
病史特点-1.txt等实体标签内容:
每一行包括:
| 实体名字 | 起始下标 | 结尾下标 | 实体类别 |
|---|
实体类别定义
- 症状和体征 :症状是患者描述的主观感受、体征则是外部观察到的客观事实。举例来说,流鼻涕、头昏及体温超过摄氏三十八度,这三者都是感冒的元素:但流鼻水及头昏是感冒的症状;而体温超过三十八度,则是感冒的体征。
- 检查和检验 :指通过实验室技术、医疗仪器设备为临床诊断、治疗所提供的依据。
- 疾病和诊断 :疾病是机体在一定的条件下,受病因损害作用后,因自稳调节紊乱而发生的异常生命活动过程;诊断,是指根据症状来识别病人所患何病。
- 治疗 :通常是指干预或改变特定健康状态的过程。为解除病痛所进行的活动,如药物、手术等。
- 身体部位 :指疾病、症状和体征发生的人体解剖学部位。
数据处理
1、json格式

需要将实体类别映射成英文:
'检查和检验': 'CHECK',
'症状和体征': 'SIGNS',
'疾病和诊断': 'DISEASE',
'治疗': 'TREATMENT',
'身体部位': 'BODY'
再将实体类别打上BIO标签:
'O': 0,
'B-TREATMENT': 1,
'I-TREATMENT': 2,
'B-BODY': 3,
'I-BODY': 4,
'B-SIGNS': 5,
'I-SIGNS': 6,
'B-CHECK': 7,
'I-CHECK': 8,
'B-DISEASE': 9,
'I-DISEASE': 10
定义路径和映射字典:
path = r"D:\\学习·\\自然语言处理\\数据集\\CCSK2017"
self.raw_data_path = os.path.join(path, 'raw_data/原始数据')
self.process_data_path = os.path.join(path, 'raw_data/data.json')
self.cn2en_dict = {
'检查和检验': 'CHECK',
'症状和体征': 'SIGNS',
'疾病和诊断': 'DISEASE',
'治疗': 'TREATMENT',
'身体部位': 'BODY'}
获取文件夹名称:
['一般项目', '出院情况', '病史特点', '诊疗经过']
使用 os.listdir()
list_dir = os.listdir(self.raw_data_path)
循环读取文件夹内容
for dir in list_dir:
dir_path = self.raw_data_path + '/' + dir
files = os.listdir(dir_path)
for file in files:
"""
一般项目、出院情况、病史特点、诊疗经过里面的文件
"""
file_path = dir_path + '/' + file
if 'original' not in file_path:
continue
其中 dir_path:
D:\\学习·\\自然语言处理\\数据集\\CCSK2017\\raw_data/原始数据/一般项目
D:\\学习·\\自然语言处理\\数据集\\CCSK2017\\raw_data/原始数据/出院情况
D:\\学习·\\自然语言处理\\数据集\\CCSK2017\\raw_data/原始数据/病史特点
D:\\学习·\\自然语言处理\\数据集\\CCSK2017\\raw_data/原始数据/诊疗经过
files:
读取1.txtoriginal.txt和1.txt的格式的文件
文件——rstrip() 、lstrip()和 strip()、zip() 函数
content_filepath = file_path
tag_filepath = content_filepath.replace('.txtoriginal', '')
with open(content_filepath, 'r', encoding = 'utf-8') as f:
content = f.read().strip()
with open(tag_filepath, 'r', encoding = 'utf-8') as l_f:
res = l_f.readlines()
tag_content = ['O'] * len(content)#其他类型标签
content = [i for i in content]
for r in res:
r = r.strip().split('\\t')
tag, s_i, e_i, entity_class = r[0], int(r[1]), int(r[2]), r[3]
entity_class = self.cn2en_dict.get(entity_class)
"""打上B-TREATMENT','I-TREATMENT',等BI命名实体识别标签
"""
for i in range(s_i, e_i + 1):
if i == s_i:
tag_content[i] = 'B-' + entity_class
else:
tag_content[i] = 'I-' + entity_class
assert len(tag_content) == len(content)
其中
content’: [‘女’, ‘性’, ‘,’, ‘8’, ‘8’, ‘岁’, ‘,’, ‘农’, ‘民’, ‘,’, ‘双’, ‘滦’, ‘区’, ‘应’, ‘营’, ‘子’, ‘村’, ‘人’, ‘,’,
‘主’, ‘因’, ‘右’, ‘髋’, ‘部’, ‘摔’, ‘伤’, ‘后’, ‘疼’, ‘痛’, ‘肿’, ‘胀’, ‘,’, ‘活’, ‘动’, ‘受’, ‘限’, ‘5’, ‘小’,
‘时’, ‘于’, ‘2’, ‘0’, ‘1’, ‘6’, ‘-’, ‘1’, ‘0’, ‘-’, ‘2’, ‘9’, ‘;’, ‘1’, ‘1’, ‘:’, ‘1’, ‘2’, ‘入’, ‘院’, ‘。’],
tag, s_i, e_i, entity_class : 实体名字 、 起始下标、 结尾下标 、 实体类别
tag_content:[‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’,
‘B-BODY’, ‘I-BODY’, ‘I-BODY’, ‘O’, ‘O’, ‘O’, ‘B-SIGNS’, ‘I-SIGNS’, ‘B-SIGNS’, ‘I-SIGNS’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’,
‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’]
然后使用 write_jsonline() 把读取内容保存到json格式
代码
# -*- coding: utf-8 -*-
# @Time : 2021/5/28
# refer to : Benqi
# @Author : xuanyunyun
import os
from ccks2020.tools import write_jsonline, read_jsonline
class DataTransfer(object):
def __init__(self):
path = r"D:\\学习·\\自然语言处理\\数据集\\CCSK2017"
self.raw_data_path = os.path.join(path, 'raw_data/原始数据')
self.process_data_path = os.path.join(path, 'raw_data/data.json')
self.cn2en_dict = {
'检查和检验': 'CHECK',
'症状和体征': 'SIGNS',
'疾病和诊断': 'DISEASE',
'治疗': 'TREATMENT',
'身体部位': 'BODY'}
self.tag2i_dict = {
'O': 0,
'B-TREATMENT': 1,
'I-TREATMENT': 2,
'B-BODY': 3,
'I-BODY': 4,
'B-SIGNS': 5,
'I-SIGNS': 6,
'B-CHECK': 7,
'I-CHECK': 8,
'B-DISEASE': 9,
'I-DISEASE': 10
}
def single_file2jsonl(self, path):
content_filepath = path#D:\\学习·\\自然语言处理\\数据集\\CCSK2017\\CCKS2017-master\\data2/training dataset v4/一般项目/一般项目-1.txtoriginal.txt
tag_filepath = content_filepath.replace('.txtoriginal', '')#D:\\学习·\\自然语言处理\\数据集\\CCSK2017\\CCKS2017-master\\data2/training dataset v4/一般项目/一般项目-1.txt
with open(content_filepath, 'r', encoding = 'utf-8') as f:
content = f.read().strip()
with open(tag_filepath, 'r', encoding = 'utf-8') as tag_f:
res = tag_f.readlines()
tag_content = ['O'] * len(content)#其他类型标签
content = [i for i in content]
"""'content': ['女', '性', ',', '8', '8', '岁', ',', '农', '民', ',', '双', '滦', '区', '应', '营', '子', '村', '人', ',',
'主', '因', '右', '髋', '部', '摔', '伤', '后', '疼', '痛', '肿', '胀', ',', '活', '动', '受', '限', '5', '小',
'时', '于', '2', '0', '1', '6', '-', '1', '0', '-', '2', '9', ';', '1', '1', ':', '1', '2', '入', '院', '。'],
"""
for r in res:
r = r.strip().split('\\t')
tag, s_i, e_i, entity_class = r[0], int(r[1]), int(r[2]), r[3]
"""
右髋部 45 47 身体部位
"""
entity_class = self.cn2en_dict.get(entity_class)
"""打上B-TREATMENT','I-TREATMENT',等BI命名实体识别标签
"""
for i in range(s_i, e_i + 1):
if i == s_i:
tag_content[i] = 'B-' + entity_class
else:
tag_content[i] = 'I-' + entity_class
assert len(tag_content) == len(content)
res_dic = {'content': content, 'tag': tag_content}
return res_dic
def transfer(self):
list_dir = os.listdir(self.raw_data_path)[1:]#['result', '一般项目', '出院情况', '病史特点', '诊疗经过']
res_jsonl = []
for dir in list_dir:
dir_path = self.raw_data_path + '/' + dir
"""dir_path:
D:\\学习·\\自然语言处理\\数据集\\CCSK2017\\raw_data/原始数据/一般项目
D:\\学习·\\自然语言处理\\数据集\\CCSK2017\\raw_data/原始数据/出院情况
D:\\学习·\\自然语言处理\\数据集\\CCSK2017\\raw_data/原始数据/病史特点
D:\\学习·\\自然语言处理\\数据集\\CCSK2017\\raw_data/原始数据/诊疗经过
"""
files = os.listdir(dir_path)
for file in files:
"""
一般项目、出院情况、病史特点、诊疗经过里面的文件
"""
file_path = dir_path + '/' + file
if 'original' not in file_path: #file_path只是包含original的文件
continue
res_dic = self.single_file2jsonl(file_path)
res_jsonl.append(res_dic)
"""
{'content': ['女', '性', ',', '8', '8', '岁', ',', '农', '民', ',', '双', '滦', '区', '应', '营', '子', '村', '人', ',',
'主', '因', '右', '髋', '部', '摔', '伤', '后', '疼', '痛', '肿', '胀', ',', '活', '动', '受', '限', '5', '小', '时', '于', '
2', '0', '1', '6', '-', '1', '0', '-', '2', '9', ';', '1', '1', ':', '1', '2', '入', '院', '。'],
'tag': ['O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O',
'B-BODY', 'I-BODY', 'I-BODY', 'O', 'O', 'O', 'B-SIGNS', 'I-SIGNS', 'B-SIGNS', 'I-SIGNS', 'O', 'O', 'O', 'O', 'O',
'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O']}
"""
write_jsonline(self.process_data_path, res_jsonl)
if __name__ == '__main__':
data_trans = DataTransfer()
data_trans.transfer()
以上是关于电子病历实体识别数据处理多个文件读取的主要内容,如果未能解决你的问题,请参考以下文章