论文泛读114通过数据增强和基本原理训练的跨语言句子选择
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读114通过数据增强和基本原理训练的跨语言句子选择相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《Cross-language Sentence Selection via Data Augmentation and Rationale Training》
一、摘要
本文提出了一种在低资源环境中进行跨语言句子选择的方法。它在嘈杂的平行句子数据上使用数据增强和负采样技术来直接学习基于跨语言嵌入的查询相关性模型。结果表明,这种方法的性能与在相同并行数据上训练的多个最先进的机器翻译 + 单语检索系统一样好或更好。此外,当应用基本原理训练次要目标来鼓励模型匹配来自基于短语的统计机器翻译模型的词对齐提示时,在三种语言对(英语-索马里语、英语-斯瓦希里语和英语-他加禄语)中可以看到一致的改进在各种最先进的基线上。
二、结论
在这项工作中,我们提出了一个基于监督跨语言嵌入的查询相关性模型,SECLR-RT,并应用了一个基本的训练目标来进一步提高模型的性能。在跨语言句子选择任务中,最终的SECLR-RT模型优于一系列基线方法。对数据消融和中心性的研究进一步表明了我们的模型在处理低资源设置和减少中心结构方面的有效性。在未来的工作中,我们希望将我们的句子级查询相关性方法应用到下游NLP任务中,例如查询聚焦的摘要和开放领域的问题回答。
三、方法
- 首先
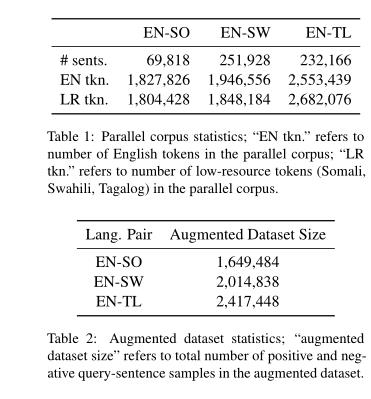
将机器翻译的平行句子语料库转换成具有二元相关性判断的跨语言查询句子对,用于训练我们的SECLR模型。 - SECLR模型
使用SMT中的单词对齐完成基本原理训练方法。
结果:
以上是关于论文泛读114通过数据增强和基本原理训练的跨语言句子选择的主要内容,如果未能解决你的问题,请参考以下文章
论文泛读147ChineseBERT:通过字形和拼音信息增强的中文预训练
论文泛读154ERNIE 3.0:大规模知识增强语言理解和生成的预训练