HiveSql&SparkSql —— 使用left semi join做inexists类型子查询优化
Posted 扫地增
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HiveSql&SparkSql —— 使用left semi join做inexists类型子查询优化相关的知识,希望对你有一定的参考价值。
LEFT SEMI JOIN(左半连接)介绍
SEMI JOIN(即等价于LEFT SEMI JOIN)最主要的使用场景就是解决EXISTS IN。LEFT SEMI JOIN(左半连接)是IN/EXISTS子查询的一种更高效的实现。LEFT SEMI JOIN虽然含有LEFT,但其实现效果等价于INNER JOIN,但是JOIN结果只取原左表中的列。
优化实例
实例表准备:
CREATE TABLE test.user1(
`id` bigint
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS textfile
LOCATION '/big-data/test/user1';
CREATE TABLE test.user2(
`id` bigint,
`role` string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS textfile
LOCATION '/big-data/test/user2';
实例数据准备:
insert into test.user1 values(-1);
insert into test.user1 values(1);
insert into test.user2 values(-1,'C1');
insert into test.user2 values(1,'C1');
insert into test.user2 values(1,'C2');
数据测试:
JOIN
--join的select的结果中可以有t1(左表),t2(右表)两张表的字段
SELECT
t1.id,
t2.role
FROM test.user1 t1
JOIN test.user2 t2
ON t1.id=t2.id;
结果:

left semi join
--left semi join的select的结果中只允许出现t1(左表)表的字段
SELECT
t1.id
FROM test.user1 t1
LEFT SEMI JOIN test.user2 t2
ON t1.id=t2.id;
--等价于
SELECT
t1.id
FROM test.user1 t1
WHERE id IN (
SELECT
id
FROM test.user2
);
--等价于
SELECT
t1.id
FROM test.user1 t1
WHERE EXISTS (
SELECT 1
FROM test.user2 t2
WHERE t1.id=t2.id
);
结果:
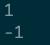
异常:
这样如果结果涉及查询右表中的字段就会报错写会报错:
SELECT
t1.id,
t2.role
FROM test.user1 t1
LEFT SEMI JOIN test.user2 t2
ON t1.id=t2.id;
结果:

join on与left semi join的联系
他们都是
hive join方式的一种,join on属于common join(shuffle join/reduce join),而left semi join则属于map join(broadcast join)的一种变体,从名字可以看出他们的实现原理有差异。
join on与left semi join的区别
(1)
Left Semi Join,也叫半连接,是从分布式数据库中借鉴过来的方法。它的产生动机是:对于reduce side join,跨机器的数据传输量非常大,这成了join操作的一个瓶颈,如果能够在map端过滤掉不会参加join操作的数据,则可以大大节省网络IO,提升执行效率。
实现方法: 选取一个小表,假设是File1,将其参与join的key抽取出来,保存到文件File3中,File3文件一般很小,可以放到内存中。在map阶段,使用DistributedCache将File3复制到各个TaskTracker上,然后将File2中不在File3中的key对应的记录过滤掉,剩下的reduce阶段的工作与reduce side join相同。
left semi join是只传递表的join key给map阶段 , 如果key足够小还是执行map join, 如果不是则还是common join。关于common join(shuffle join/reduce join)的原理请参考文末refer。
(2)left semi join子句中右边的表只能在ON子句中设置过滤条件,在WHERE子句、SELECT子句或其他地方过滤都不行。
(3)对待右表中重复key的处理方式差异:因为 left semi join 是 in(keySet) 的关系,遇到右表重复记录,左表会跳过,而 join on 则会一直遍历。left semi join中最后的结果是这会造成性能,以及join结果上的差异。
(4)left semi join中最后 select 的结果只许出现左表,因为右表只有join key参与关联计算了,而 join on 默认是整个关系模型都参与计算了。
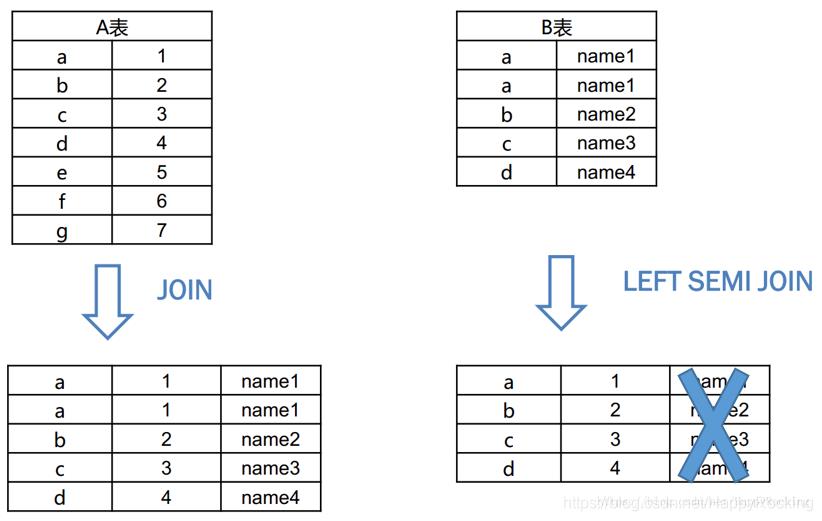
这里借鉴网上一个实例图在解释下:
比如以下A表和B表进行join 或 left semi join,然后 select 出所有字段,结果区别如下:(蓝色叉的那一列实际是不存在left semi join中的,因为最后 select的结果只许出现左表。)
写在最后
对于大多数情况下 JOIN ON 和left semi on是对等的,在右表存在重复数据记录时,导致结果差异,所以大家在使用的时候最好能了解这两种方式的原理,是否和我们想要的数据效果一致。
以上是关于HiveSql&SparkSql —— 使用left semi join做inexists类型子查询优化的主要内容,如果未能解决你的问题,请参考以下文章