资源依赖的“诅咒” | 原有深度学习框架的缺陷①
Posted OneFlow深度学习框架
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了资源依赖的“诅咒” | 原有深度学习框架的缺陷①相关的知识,希望对你有一定的参考价值。

为什么要重新设计一个像OneFlow这样的分布式深度学习框架?
一个显而易见的出发点是,我们看到了原有的主流深度学习框架的本质不足。尤其在抽象层面和API层面,它们的设计有种种不足,导致开发者在使用时带来了极大不便,尽管他们正在试图解决一些缺陷,但有些重要问题依然被忽视了。
为此,我们将推出三篇系列文章,详细论述原有主流深度学习框架的运行时系统的三大不足,此为第1篇内容。本文将介绍资源依赖的重要性,以及原有框架在应对该难题上的局限性,最后,本文将介绍OneFlow框架如何在设计之初就简单、优雅地解决了这一难题。
撰文 | 袁进辉
1、算子之间的三种依赖关系
无论是动态执行还是静态执行,算子(op)之间的依赖关系都可以用数据流图来描述。一般来说,算子之间产生依赖关系的原因有以下三种:
数据依赖:消费者对生产者的依赖,因生产-消费关系传递而产生的依赖,譬如算子A–>B–>C 表示B需要使用A生成的数据,C需要使用B生成的数据,实际上C依赖于A,但A和C之间并不需要有一条边显式的描述这个依赖关系;
控制依赖:两个原本没有生产和消费关系的op A和B,因某种需求而希望他们按特定顺序发生,可以通过在这两个op之间引入控制边(control edge),A–>B以确保B永远在A后面发生;
共享资源形成的依赖:两个原本没有生产和消费关系的op A 和B,因共享某一个互斥的资源而导致二者不可能同时发生所形成的依赖,要么A先于B发生,要么B先于A发生;
值得注意的是,原有的主流深度学习框架的调度器对前两种类型的依赖关系都有显式的描述和处理,但无一例外都忽视了第三种依赖关系的处理。
本文用一个简单的例子来论证:
-
忽略因共享资源而形成的依赖是深度学习框架设计上的致命不足,这个问题会降低系统的安全性和稳定性;
-
在现有框架的设计体系内解决这一问题不是不可能,但难度比较大,且会破坏系统抽象的优雅性;
-
OneFlow中基于actor机制可以比较简单的解决这个问题。
2、关于资源依赖的一个思想实验
原有的主流深度学习框架中,数据和控制的依赖关系都是用执行图的边来表示。在每个op完成后,调度器会更新和检查剩余op的依赖关系,并确定哪个算子满足执行条件(即其依赖关系已全部解决)。
由于分布式深度学习中依赖关系和资源管理的复杂性,许多情况下会更加复杂(例如,为了避免内存不足的错误或死锁,尽量减少等待等情况)。

图1. 一个可能导致现有框架中的调度器出现死锁的例子
图1展示了一个简单的例子:M1和M2是两个数据搬运算子,分别为同一设备上的两个算子O1和O2服务,也就是O1 消费M1搬运到该设备上的数据,O2消费M2搬运到该设备上数据。
M1和 M2之间没有依赖关系,M1需要1个单元的设备内存来存放它的执行结果,M2需要2个单元的设备内存来存放它的执行结果。
O1和O2之间没有依赖关系,O1需要3个单元的设备内存来放置它的执行结果,O2需要2个单元的设备内存来放置它的执行结果。
在某一时刻,M1和 M2都在执行消耗了各自的内存之后,空闲的内存容量只能满足O2的需求,而不能满足O1的需求,尽管在调度器来看,O1和O2都满足了执行条件,因为它们的输入数据都已经就绪,而这正是所有深度学习框架(如TensorFlow)中调度器的执行机制。
对于这个例子描述的情况,是先调度 O1 还是O2,我们可以分两种情况讨论:
-
如果O2先被调度,它可以成功执行并消费内存中M2的输出。O2完成之后,O2的输入和输出就可以被释放
(状态4)。然后O1就可以被调度并成功执行。 -
如果是O1先被调度,那么剩余内存对O1来说是不够的,但调度器在发射O1指令的时刻并不关心也不知道当前的内存是否能满足O1的需求。
如果O1被调度到当前调度器正在执行的内核线程上(即 TensorFlow executor中的 inline execution的情况,kernel 的Compute 函数就在调度器所在线程上执行),O1的Compute 函数在执行过程中为其输出分配内存时才会发现系统资源不够,也许会立刻报OOM (out of memory)的错误,或者在此处循环重试,直到分配成功,但该内核线程将被阻塞。
如果只有这一个内核线程运行调度器,那么即使当前设备内存对O2来说是足够的,O2也永远不会被调度出去。
当然,如果不止一个内核线程在执行调度器,那么即使一个调度线程被O1阻塞,还有另一个操作系统线程来执行O2。
如果不允许O1在调度器当前所在的线程上执行,也就是O1必须被发送到另外一个内核线程上去执行,那么另外执行O1的线程会被阻塞,但调度器不会被阻塞,O2仍会被调度出去,并成功执行,当O2执行结束后,O1所在的线程最终会成功执行。
上面两种方式“如果”可以成功执行O2,但框架仍然需要处理一个棘手的问题,即为动态线程池确定适当的线程数量,并实现一个支持复杂 的retry机制的自定义内存分配器。如果固定线程池的大小,当并行度超过线程池的线程数时,仍有可能发生死锁。
为了避免上述的死锁,就需要在运行前做静态资源规划,当发现有资源共享且可能发生死锁时,就提前规定一个适当地执行顺序,譬如O2必须在O1之前执行,在TensorFlow中可以通过在O2和O1之间添加一条控制边来实现。
然而,原有的主流框架全都没有进行静态资源规划来避免这种死锁风险。
在流水线执行中,这种情况会变得更加棘手。例如,在由几个连续的op组成的流水线中,每个op可能有多个实例,每个实例在运行时对应于不同的数据批次。
在图1的第2步中,除了O2,下一个数据批次对应的M1或M2 都满足执行条件,如果调度器启动 在调度O2之前,先调度搬运下一数据批次的M1或M2,它们将消耗部分或全部可用设备内存, O1和O2就更不能成功执行,数据搬运算子的输出也不会被消费和释放,这就会死锁。
此外,当 O1和O2有下游算子时,O2执行之后,可能下游算子又满足了执行条件,进一步增加了调度的复杂度。
3、借助控制边规定算子的执行顺序并非易事
通过添加控制边来规定算子的顺序的前提是,找到一个在资源约束下能成功执行且最优的执行顺序,这本身就很困难。下面,让我们考虑深度学习框架里常见的数据加载流水线的例子来说明这个问题。

图2. 流水线设计:横向表示时间,纵向自上而下表示流水线的几个阶段,数据加载、预处理、copyh2d和计算(其中计算环节是瓶颈)
图2说明了深度学习框架中常见的通过流水线设计来重叠数据加载、预处理、copyh2d(即把数据从主机内存复制到设备内存)和计算的过程,采用双缓冲技术来实现这种流水线。每个算子都有2个单元的内存配合,蓝色和灰色表示有数据占用,而空白表示内存处于空闲。
如图所示,在同一批次(例如batch 6) 中,下游算子依赖于上游算子(例如,batch 6),preprocess依赖于data loader,而copyh2d依赖于preprocess,compute依赖于copyh2d。当流水线进入稳定阶段时,背压机制使得其他算子均以耗时最长的算子的速度执行(即图中的“计算”过程)。
这就导致了一些反直觉的依赖关系(如虚线所示),即新批次上的上游算子依赖于老批次的下游算子。例如,copyh2d的batch 4的执行依赖于computation的batch 2。这种流水线效应很难通过用控制边指定执行顺序来完成。
原有框架的运行时和调度机制很难(如果不是不可能的话)优雅地支持这种需求,所以现有框架在核心图执行器(graph executor)之外借助另外的模块来支持这种流水线功能,例如Nvidia DALI和TensorFlow中的dataset API。
4、通过定制内存分配器支持双缓冲流水线
你可能会好奇,是否有可能用现有框架的核心机制来实现双缓冲?
图3就展示了在TensorFlow里实现双缓冲的一个潜在方案,也就是添加一个自定义的内存分配器,这个内存分配器限制每个算子只能分配到两份内存。
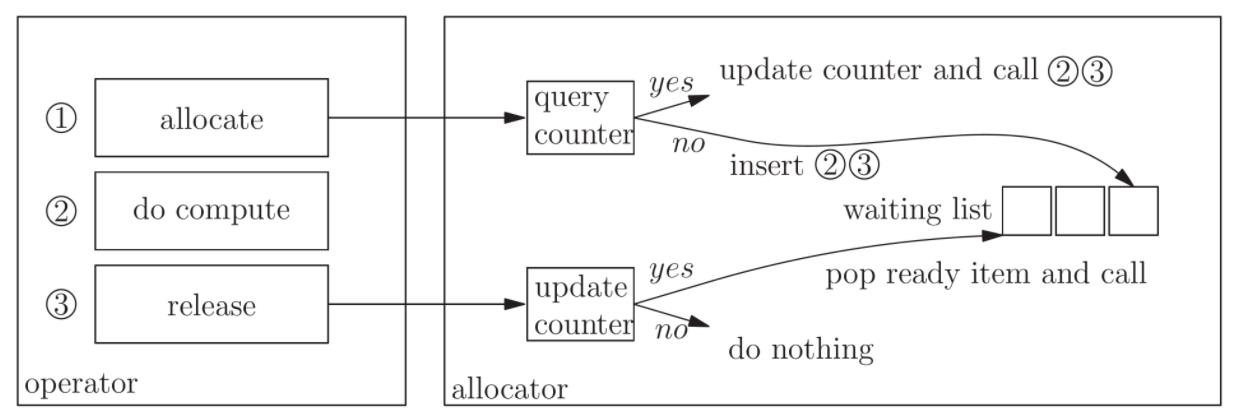
图3. 自定义分配器,支持双缓冲
- 当一个算子使用分配器分配内存时,分配器会查询一个计数器,查询该算子是否有空闲的缓冲区可以使用。如果有,它就为该算子分配一个缓冲区,让该算子继续执行,并在该算子完成计算后释放缓冲区。如果这个算子的两个缓冲区都已被占用,分配器会将步骤2(do compute)和步骤3 (release) 放入一个等待列表中。
- 当一个算子向分配器释放其内存时,分配器更新与该算子对应的空闲缓冲区的计数器,并检查等待列表中是否有请求该缓冲区的算子。如果有,就从等待列表中弹出处于就绪状态的算子,执行步骤2和步骤3。
通过定制一个这样的内存分配器可能是通过最小的改动就可以支持起来双缓冲,然而,这样的做法在软件工程中是不好的,因为它将调度器的部分责任推卸给了自定义分配器,而且需要把调度器模块暴露给自定义分配器。
5、如何优雅解决资源依赖问题?
上述思想实验所揭示的麻烦的根源是,原有框架没有考虑共享资源引入的隐式依赖,没有显式的表达这种依赖关系,把成功执行完全寄希望于运气,也就是“运行时”的动态状况,只不过大部分情况都能成功执行罢了。
具体到工程实现,现有的框架的调度器只要看到一个op的输入数据就绪,就认为这个op可以“发射”出去,在发射出去后执行时才会去为这个op的输出数据分配内存,这个分配内存的逻辑和op的计算逻辑没有分开。
OneFlow的与众不同之处在于,编译器会分析每个op的最优内存配额,在运行时每个op的内存配额都是固定的,调度器在检查一个op是否可以被“发射”时,不仅看它的输入数据是否就绪,而且会看它的内存配额是否还有空闲,只有当输入和输出的条件都满足时,这个op才会被发射出去,一旦发射出去,这个op就一定可以一路畅通无阻的执行成功,确保不会被阻塞。
事实证明,这样一个小小的改变,大大简化了系统的复杂度,使得原本棘手的很多问题迎刃而解。感兴趣的朋友可以去看看OneFlow的actor机制。
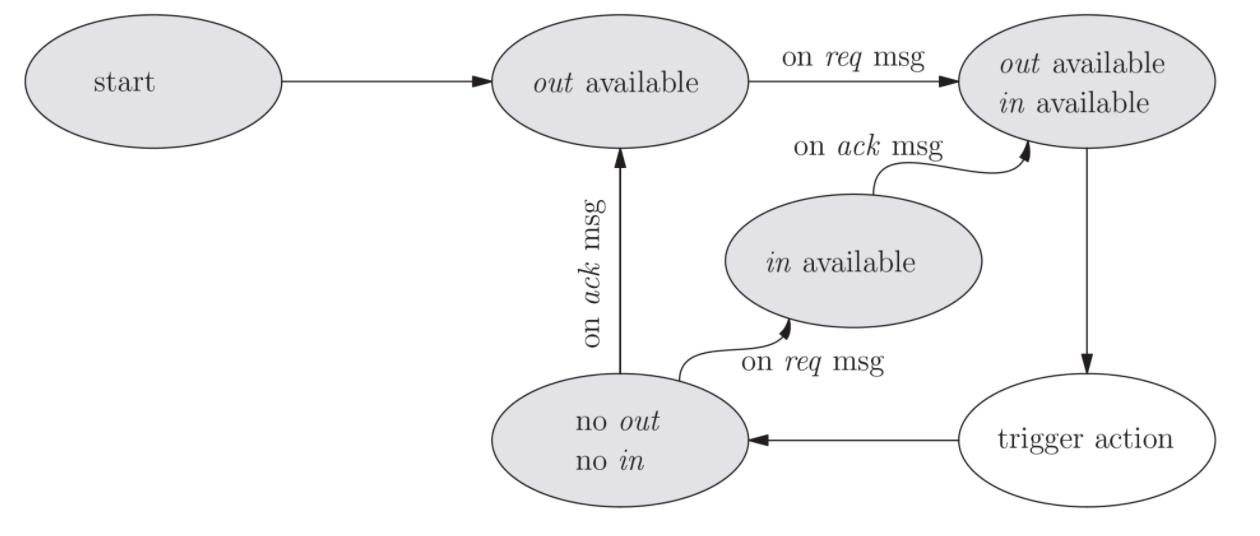
图4. 一个op的状态机,只有当输入(in)和输出(out)都就绪的时候才满足触发条件
迄今为止,研发深度学习框架的同行极少有人意识到这一问题,几乎所有框架都是把为一个op的输出数据分配内存的逻辑放在该op的计算逻辑里,且没有分离。
当然也有例外。最近,华为的MindSpore正在把底层的图执行器由旧版设计改造成和OneFlow一样的actor机制。
在MindSpore的新版设计里,判断一个op是否可以执行的条件仍只看其输入数据是否就绪,但相对于TensorFlow等框架有一处进步,就是把为一个op的输出数据分配内存的逻辑和这个op的计算逻辑解耦,专门设计了一个负责分配内存的actor来执行内存分配,当这个actor成功分配内存之后再发消息给需要这个内存的op,从而这个op可以畅通无阻的执行下去。
这种设计可能比上文讨论的定制allocator好一点,不过,还是不如OneFlow中的机制简洁。
刚才说到,谷歌的TensorFlow解决这个问题也非常困难,不过他们应该已经意识到这个问题了。他们正在开发新一代的运行时系统TensorFlow Runtime,目标是在未来完全取代现在TensorFlow臃肿不堪的运行时系统。在新版的设计方案里, 他们对本文讨论的问题具有非常清晰深刻的认识,譬如,在他们的设计文档里有这样一些描述:
Existing TF kernels encapsulate shape computation and memory allocation within the kernel implementation, making some graph compiler optimizations challenging or infeasible, such as reusing buffers across kernels. In TFRT kernels, shape computation and memory allocation will be hoisted out of the opaque C++ kernel implementations.
A core design principle of TFRT is that kernel executions are never allowed to block, as this allows us to have a fine-grained control over the number of compute threads and the thread switching behavior, which is important for achieving high CPU utilization.
感兴趣的朋友可以去研究一下新版TensorFlow Runtime的实现,在这一版里,他们的确把“优雅”作为设计目标之一。
然而,本文分析的这一问题,在OneFlow设计之初就已经考虑到了,并且使用了迄今为止我们仍觉得可能是最简单的方法。
注:题图源自pixaby
欢迎下载体验OneFlow新一代开源深度学习框架:https://github.com/Oneflow-Inc/oneflow
以上是关于资源依赖的“诅咒” | 原有深度学习框架的缺陷①的主要内容,如果未能解决你的问题,请参考以下文章