《S2R-DepthNet:Learning a Generalizable Depth-specific Structural Representation》论文笔记
Posted m_buddy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《S2R-DepthNet:Learning a Generalizable Depth-specific Structural Representation》论文笔记相关的知识,希望对你有一定的参考价值。
参考代码:
- 官方:S2R-DepthNet,但是2021-0607通过该入口无法进入了,后续再观察。
- 未知版本:S2R-DepthNet
1. 概述
导读:这篇文章经过分析人对场景的3D感知,发现场景中的空间结构信息在深度感知中扮演了至关重要的作用。因而文章首先学习得到一个针对深度的结构表达,这个表达中抓住了深度估计中的关键信息,排除一些数据中无关的风格信息。这样使得深度网络着力关注场景的结构信息,使得即使在合成数据场景训练的模型也具有良好的泛化能力。文章方法的组成可以划分为下面的3个部分:
1)用于提取结构信息的STE(structure extraction)模块,它通过将图像进行分解得到domain-invariant的结构信息,以及与数据自身相关的domain-specific风格信息;
2)通过DSA(Depth-specific attention)模块构建一个上面STE结构图的attention map,再与之相乘从而进一步提纯STE模块得到结构图;
3)使用DP(depth prediction)模块在结构特征表达的基础上实现深度估计;
由于文章的方法使用结构信息作为深度估计的参考,因而在没有相应真实数据加入的情况下也取得了很好的效果,对深度估计任务来说是个很好的参考idea。
现有自监督和监督的深度估计方法都对深度信息的domain存在依赖,而且使用合成的数据简单进行深度回归会存在domain-transfer的问题,这就导致了其使用存在一定的局限性。而在这篇文章中抓住了图像中的结构信息,从而在此基础上进行深度估计,可以说是抓住了图像中的关键信息。

文章的方法首先会使用STE模块将输入的图像进行分解得到两个分量:stype-domain和structure-domain。这里的style-domain是不需要的,后者才是对深度估计有用的,可以见图1的第二列。但是structure-domain中也存在depth-specific和depth-irrelevant的两个分量。对此文章提出了DSA模块用于去产生一个attention map从而进一步对结构信息进行抑制和过滤,从而只剩下depth-specific的信息用于深度估计,见图1的第三列。
2. 方法设计
2.1 pipline
文章方法的整体pipeline见下图所示:
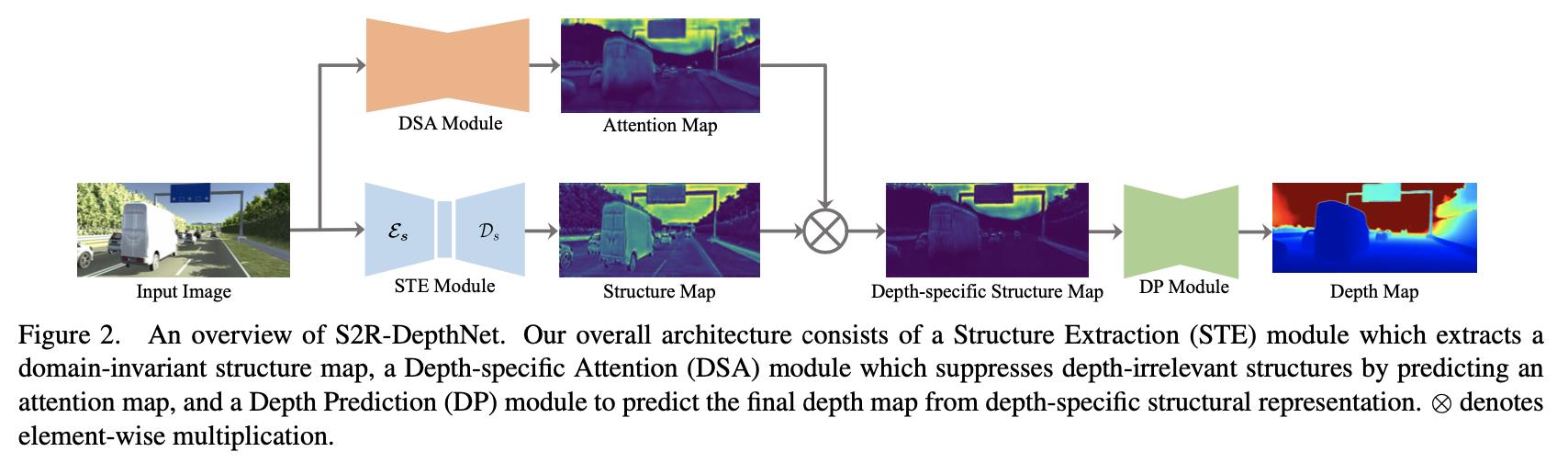
按照之前讲述的过程可以将上的pipeline划分为:STE(
S
\\mathcal{S}
S)/DSA(
A
\\mathcal{A}
A)/DP(
P
\\mathcal{P}
P)三个部分。对应的文章也将整体的训练过程划分为三个阶段:
- 1)训练STE模块中的编码器模块 ϵ s \\epsilon_s ϵs,使用风格迁移网络的训练方式使得其对不同风格的图片通用化,这里涉及到的是image-to-image的迁移(参考:MUNIT: Multimodal UNsupervised Image-to-image Translation,code:MUNIT);
- 2)在训练好编码器模块 ϵ s \\epsilon_s ϵs之后(之后都不再更新其中的参数)与STE中的解码器 D s D_s Ds,以及 P \\mathcal{P} P进行深度估计(这里并没有使用 A \\mathcal{A} A);
- 3)将 A \\mathcal{A} A加入近来与 P \\mathcal{P} P进行深度估计,这里不更新模块 ϵ s \\epsilon_s ϵs和 D s D_s Ds中的参数;
对于这篇文章的解读可以参考:CVPR 2021 | 神经网络如何进行深度估计?
2.2 训练的过程
step1: 编码器
ϵ
s
\\epsilon_s
ϵs的训练
这里编码器是在PBN(painter by number)数据与合成数据(用于训练深度vKITTI)通过迁移学习的方式使得可以编码器对不同风格的图片具有通用性。这里具体的训练过程文章没有给出,提到的supplemental material也没有找见,通过上面的解读文章可以大体看一下它训练的结构:
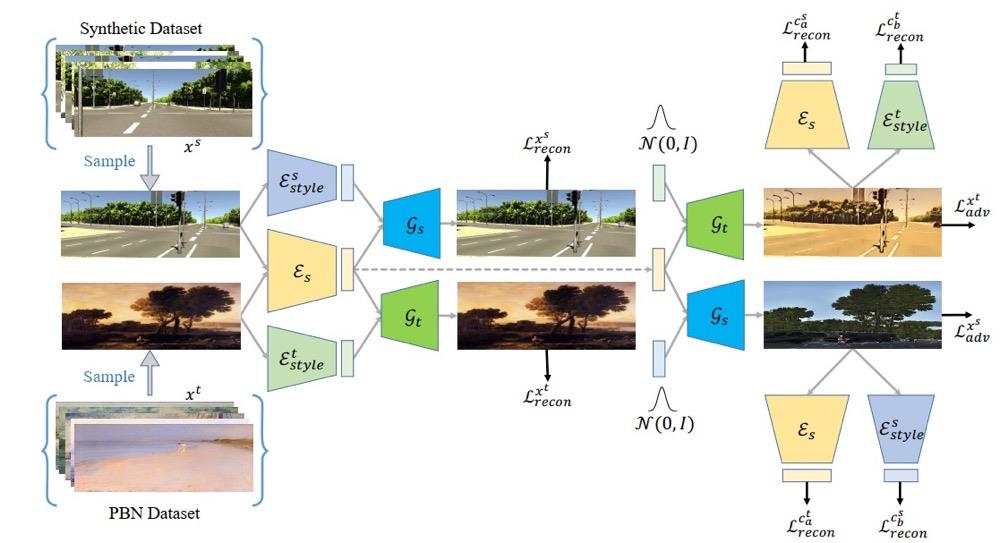
step2:STE和DP部分的训练
这里固化编码器
ϵ
s
\\epsilon_s
ϵs部分的参数,之后通过合成数据训练解码器
D
s
D_s
Ds和DP部分的参数,使用的损失函数为:
L
S
=
∑
p
∣
∣
D
^
(
p
)
−
D
(
p
)
∣
∣
1
+
λ
∑
p
∣
∣
M
s
(
p
)
∣
∣
1
⋅
e
−
β
(
∣
∇
x
D
(
p
)
+
∇
y
D
(
p
)
∣
)
L_{\\mathcal{S}}=\\sum_p||\\hat{D}(p)-D(p)||_1+\\lambda\\sum_p||M_s(p)||_1\\cdot e^{-\\beta(|\\nabla_xD(p)+\\nabla_yD(p)|)}
LS=p∑∣∣D^(p)−D(p)∣∣1+λp∑∣∣Ms(p)∣∣1⋅e−β(∣∇xD(p)+∇yD(p)∣)
其中,
D
^
\\hat{D}
D^是深度预测结果,
p
p
p是像素索引,
∇
x
,
∇
y
\\nabla_x,\\nabla_y
∇x,∇y是求取水平和垂直方向的梯度,
λ
,
β
\\lambda,\\beta
λ,β是超参数,
M
s
M_s
Ms是STE模块输出的结构图(structure map)。
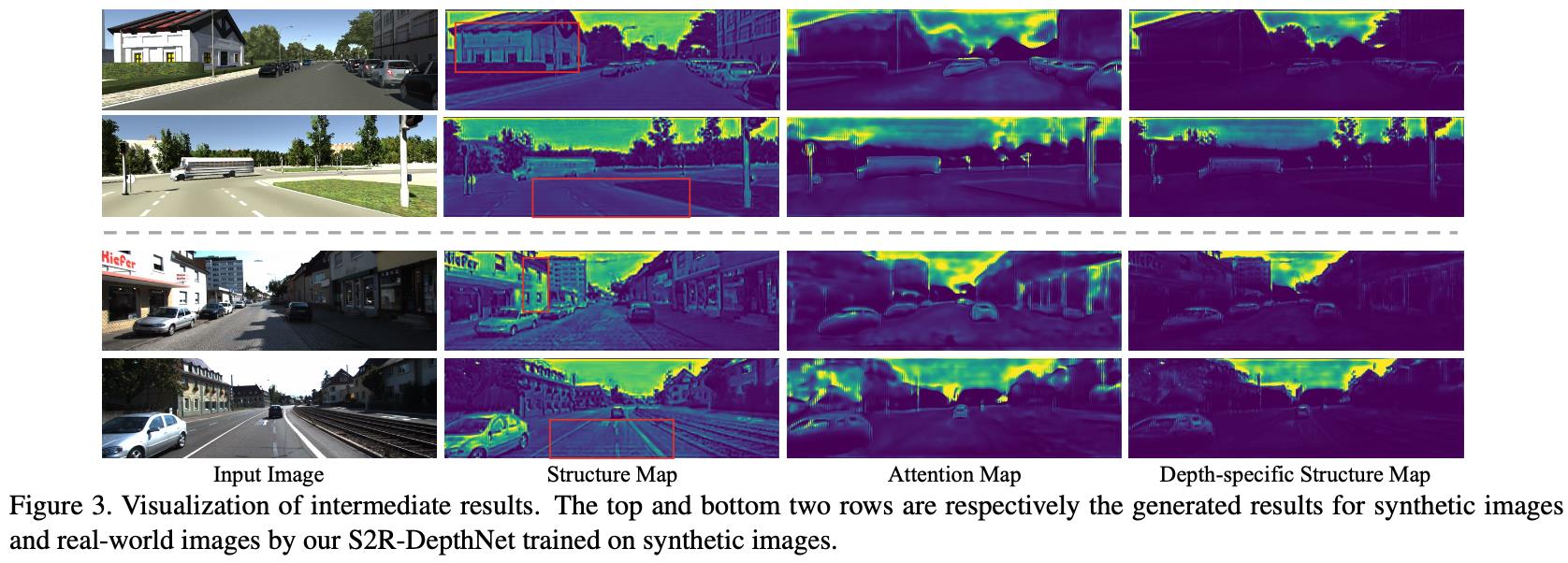
step3:DSA和DP的训练
这里固定STE模块中的参数,之后使用DSA模块生成的attention map对上文中的structure map(
M
a
M_a
Ma)进行优化,也就是下面element-wise相乘的形式:
M
s
a
=
M
s
⊗
M
a
M_{sa}=M_s\\otimes M_a
Msa=Ms⊗Ma
之后使用合成数据集更新参数:
L
A
=
∑
p
∣
∣
D
^
(
p
)
−
D
(
p
)
∣
∣
1
L_{\\mathcal{A}}=\\sum_p||\\hat{D}(p)-D(p)||_1
LA=p∑∣∣D^(p)−D(p)∣∣1
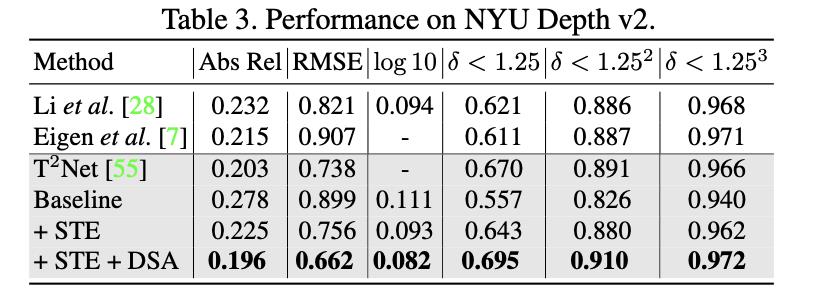
文章的各个模块对最后性能的贡献度,见下面的消融实验结果(baseline为单纯DP模块):
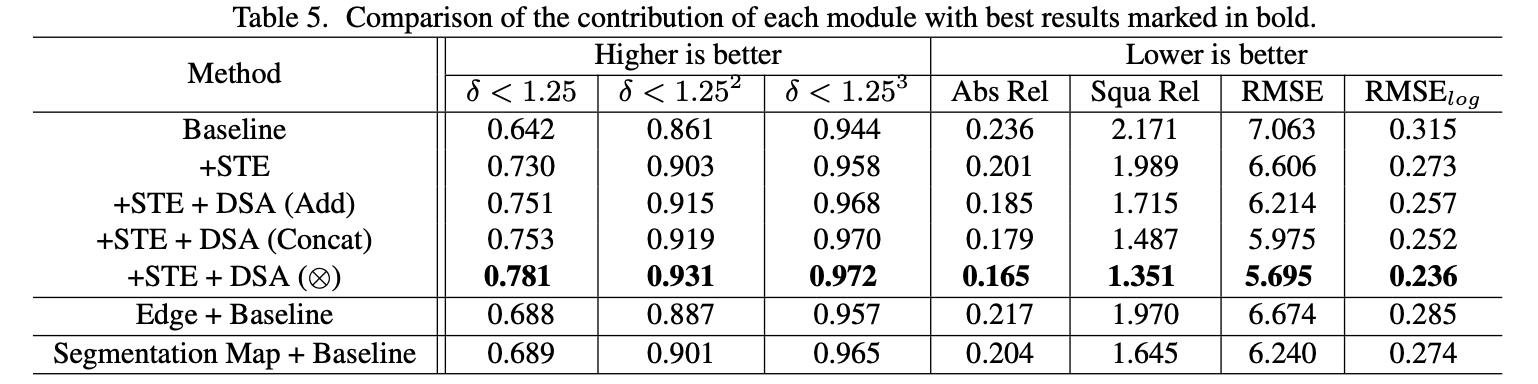
3. 实验结果
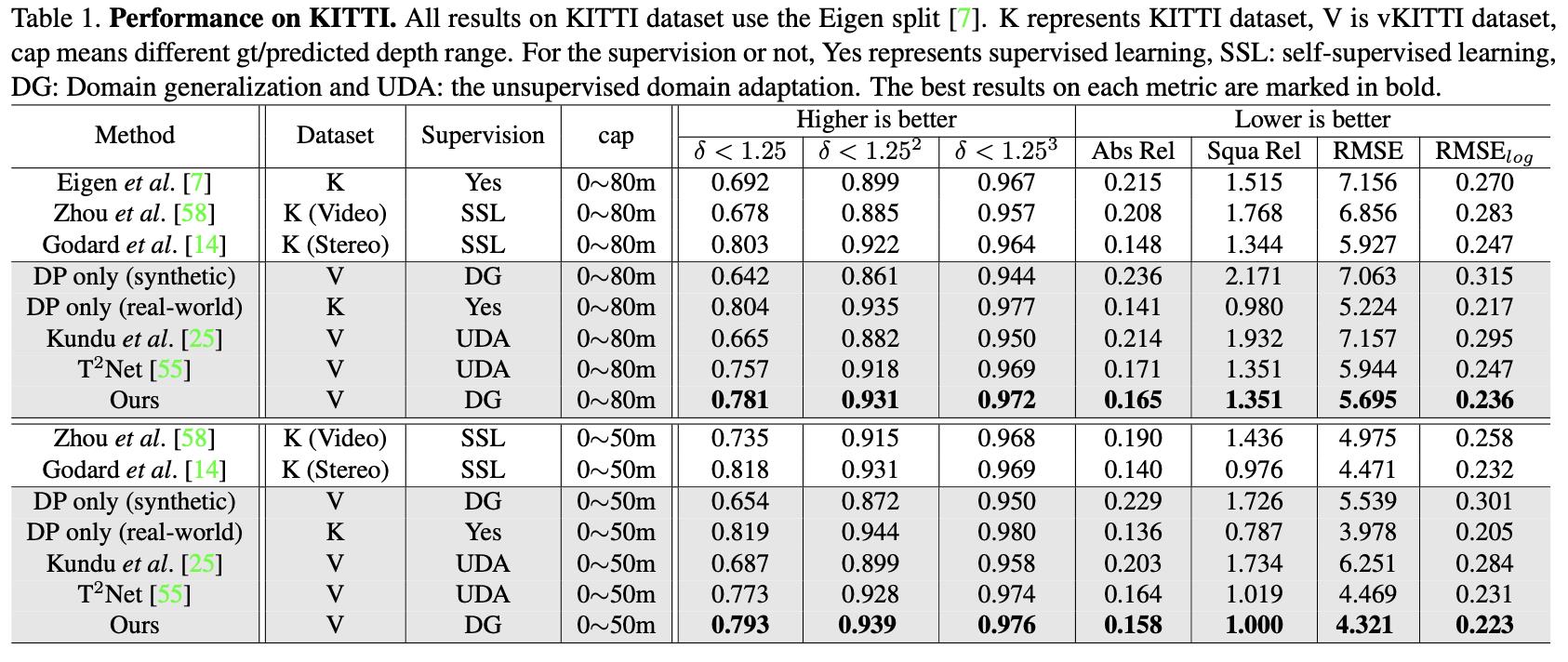
KITTI数据集上的表现:
NYU Depth v2数据集上的表现:
以上是关于《S2R-DepthNet:Learning a Generalizable Depth-specific Structural Representation》论文笔记的主要内容,如果未能解决你的问题,请参考以下文章