MySQL基础-- [DML(数据操纵语言),DQL(数据查询语言)]
Posted 小智RE0
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL基础-- [DML(数据操纵语言),DQL(数据查询语言)]相关的知识,希望对你有一定的参考价值。
目录
DML(数据操纵语言)
数据操作语言DML(Data Manipulation Language).用户通过它可以实现对数据库的基本操作。例如,对表中数据的查询、插入、删除和修改。 在DML中,应用程序可以对数据库作插,删,改,排,检等五种操作。
常用语句: insert插入,delete删除,update修改
(1)插操作:把数据插入到数据库中指定的位置上去,如Append 是在数据库文件的末尾添加记录,而INSERT是在指定记录前添加记录。
(2)删操作:删除数据库中不必再继续保留的一组记录,如DELETE 对数据库中记录作删除标志。PACK是将标有删除标志的记录彻底清除掉。ZAP 是去掉数据库文件的所有记录。
(3)改操作:修改记录或数据库模式,或在原有数据的基础上, 产生新的关系模式和记录,如连接Join操作和投影操作Projection.
(4)排序操作:改变物理存储的排列方式。如SORT命令按指定关键字串把DBF文件中记录排序。从物理存储的观点看,数据库发生了变化,但从逻辑的观点(或集合论观点看),新的关系与排序前是等价的。
(5)检索操作:从数据库中检索出满足条件的数据,它可以是一个数据项, 一个记录或一组记录。如BROWSE单元实现对数据的浏览操作。SELECT选出满足一定条件和范围的记录。
插入数据操作
方式1: INSERT INTO 表名(列1,列2……,列n) VALUES(值1,值2……,值n);
每执行一次插入单行数据.
例如首先是数据库studentmessage_db的创建数据表t_student;将数据表t_student的结构复制到数据表t_student1中,两个表都是空的;
#创建表;
CREATE TABLE t_student(
#学号:int类型,设置主键且自增;
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '学号_主键',
#姓名:最大长度为5的可定长字符串,设置不能为空约束,
NAME VARCHAR(5) NOT NULL COMMENT '姓名',
#性别:长度为1的定长字符串,设置默认值为女;
sex CHAR(1)DEFAULT '女' COMMENT '性别' ,
#生日:日期类型;
birthday DATE COMMENT '生日',
#年级:长度为3的定长字符串,
grade CHAR(3) COMMENT '年级',
#成绩:double类型,数值总长度为3,保留小数后1位,且成绩在0-120之间;
score DOUBLE(3,1) CHECK(score>=0 AND score<=120) COMMENT '成绩',
#手机号:长度为11位定长字符串,设置唯一约束;
phone CHAR(11) UNIQUE COMMENT '手机号',
#注册时间:时间类型,
registertime DATETIME COMMENT '注册时间'
);
将t_student的结构复制到表t_student1;
#将t_student的结构复制到表t_student1;
CREATE TABLE t_student1 LIKE t_student;
对数据表t_student单行插入数据;
单引号’ '或双引号" "都可以表示字符串||||||||
表名中如果不描述列名,则默认向表中的所有列插入数据,值的数量要和列的数量相匹配
在设置当前时间的数据时;可使用NOW( )得到当前时间
#单行插入;
INSERT INTO t_student (id,NAME,sex,birthday,grade,score,phone,registertime) VALUES (181,'张三','男','2008-5-1','一年级',50,'12345678998',NOW());
效果:

方式2: INSERT INTO 表名 set 列名1=值1,…列名n=值n;
单个列名都对应的一个一个设置插入的数据
对数据表t_student用方式2插入数据;
#方式2:单个列名设置数据;
INSERT INTO t_student SET id=182,NAME='李四',sex='男',birthday='2021-6-1',grade='二年级',score=60,phone='12345698745',registertime=NOW();

方式3: INSERT INTO 表名(列1,列2……,列n) VALUES(值1,值2……,值n),(值1,值2……,值n);
同时插入多行数据.
对数据表t_student用方式3插入数据;
#方式3:多行插入;
INSERT INTO t_student (id,NAME,sex,birthday,grade,score,phone,registertime)
VALUES(185,'张三','男','2006-5-27','一年级',50,'12115678998',NOW()),
(186,'杰斯','女','2019-2-1','三年级',80,'12343378998',NOW()),
(187,'咸鱼','男','2018-9-25','五年级',90,'12342278998',NOW()),
(189,'小树人','女','2018-10-5','一年级',20,'12885678998',NOW());
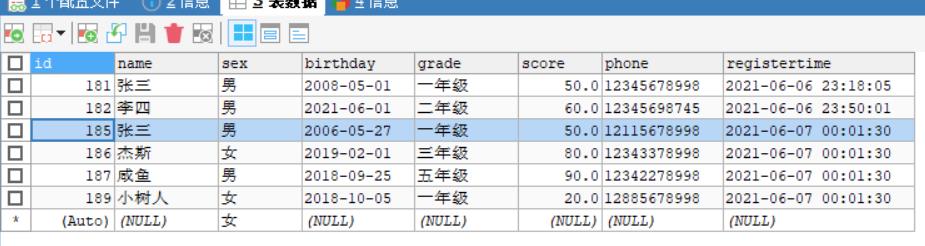
方式4:INSERT INTO 表名(列1,列2……,列n) 查询语句(查询的列数与插入列数匹配);
可以用查询语句将一个表的数据插入到另一个表;注意;查询的列数与插入列数要匹配
对数据表t_student1用方式4插入数据;即将数据表t_student的数据插入t_student1中.
#方式4:
#没有写列名,就默认为全部的列;
INSERT INTO t_student1 SELECT*FROM t_student;
修改数据
UPDATE 表名 SET 列名 = ‘新值’WHERE 条件;
注意:修改表数据时一定要加条件语句,不然的话就会直接去修改每一行数据;
一般都是以主键作为条件语句的;由于主键是具有唯一性;(主键会在数据库中添加索引;就类似于一本书的目录;查找起来也方便)
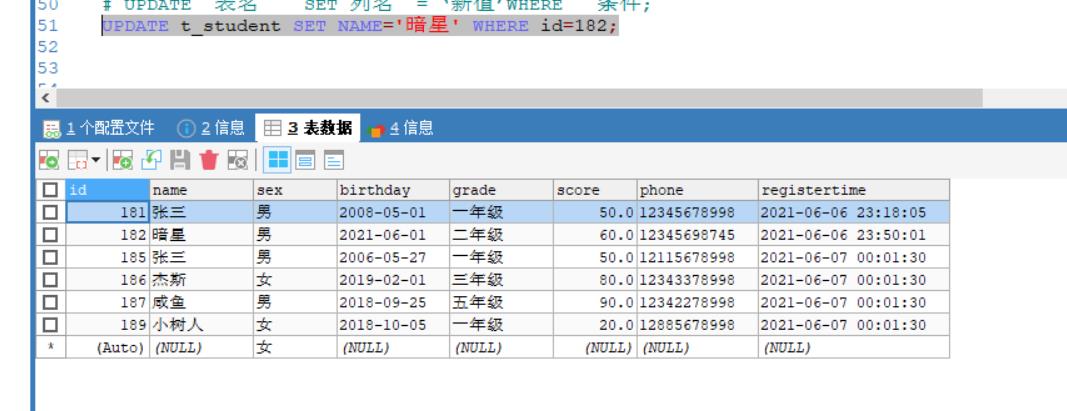
例如:对数据表t_student的id为182的那行数据的name进行更改;
#修改数据;
# UPDATE 表名 SET 列名 = ‘新值’WHERE 条件;
UPDATE t_student SET NAME='暗星' WHERE id=182;
删除数据
对于表中部分数据的删除
DELETE FROM 表名 WHERE 条件
注意:如果不加条件语句就默认删除了表中所有数据
删除数据表所有的数据
TRUNCATE TABLE 表名;清空整张表
DELETE FROM 表名不加条件就直接删除了表中所有数据
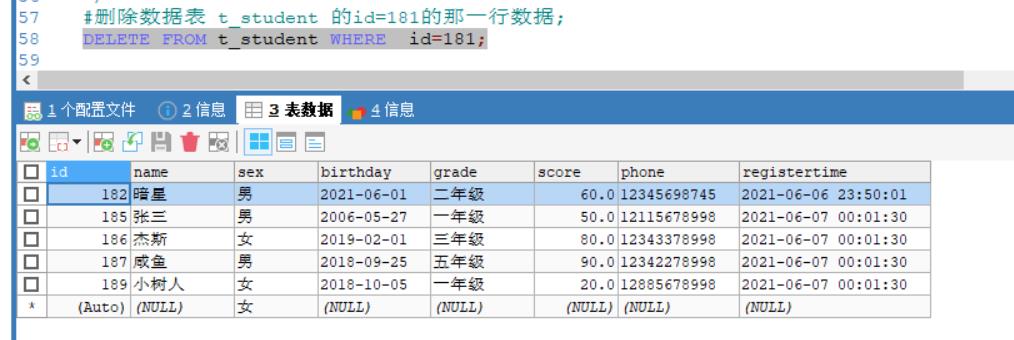
例如:删除数据表 t_student 的id=181的那一行数据;
DELETE FROM t_student WHERE id=181;
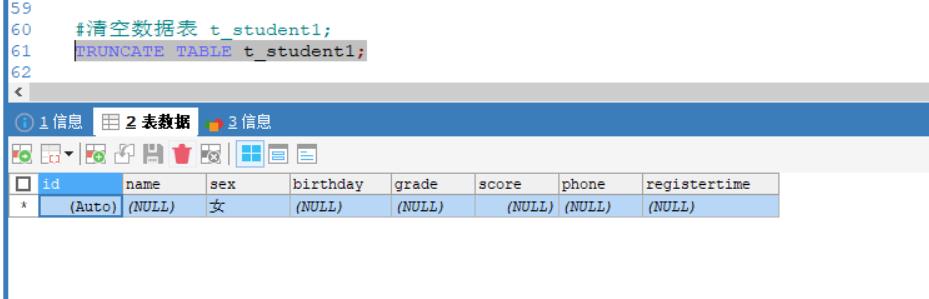
例如:清空数据表 t_student1;
TRUNCATE TABLE t_student1;
DQL(数据查询语言)
DQL数据库查询语言基本结构是由select子句,from子句,where子句组成的查询块
select 字段名(结果的列) ;from 表名或视图名;where 查询条件
可以从一个表中查询数据,也可以从多个表中查询数据.
特点为:
- 查询列表:表中的字段、常量、表达式、函数
- 查询的结果是一个虚拟的表格
,不会对表中的数据进行修改;就相当于查询了需要的数据然后将结果放在一个新的表中,且这个新的表不是存在的;这个表是只读的 - 如果要同时执行多行SQL语句,每行都加分号;执行后的表格是分开的.
查询结果处理
首先学习这个对于查询结果的处理;查询常量值,表达式,函数(单行函数,日期函数,字符函数,数学函数,多行函数);对于列查询;排除重复行;使用的算术运算符.
查询常量值 例如:SELECT 20;
一般不会这样查询的
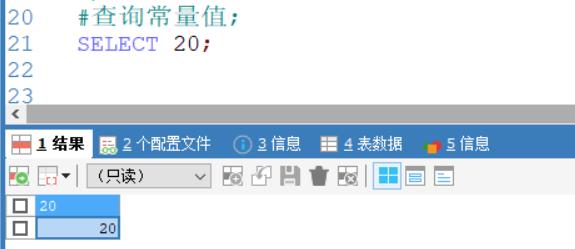
查询表达式:例如: select 20*9;
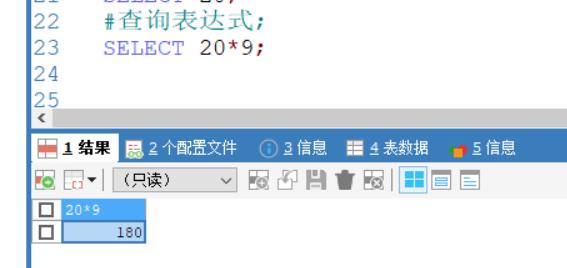
查询函数:select 函数; / 例如 select version( ); 查询版本号
之后会对函数进行分类学习;
SQL 拥有很多可用于计数和计算的内建函数。
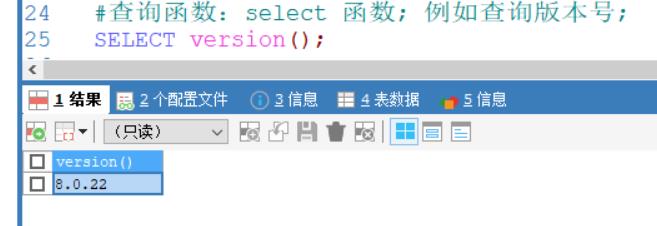
全部列查询: select * from 表名
这里的 * 匹配所有列.
例如查询:数据表t_student;的所有列数据.
SELECT * FROM t_student;
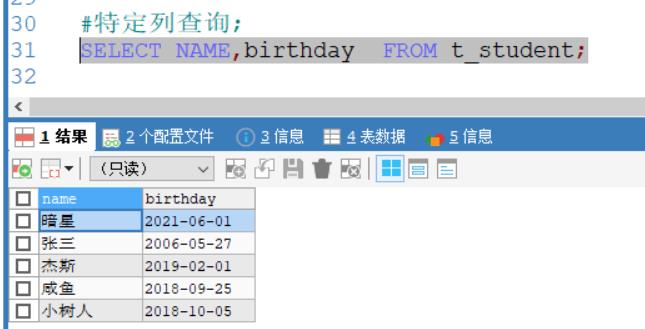
特定列查询:select column1,column2 from 表名
例如查询:数据表t_student;的姓名和生日
SELECT NAME,birthday FROM t_student;
排除重复行: select distinct column1,column2 from table
(重复指的是多行数据的所有列相同;就例如说有个数据表,且只有姓名列和生日列,;其中有两个人姓名相同,生日相同;这两行就是重复数据.)
这主要是对于查询结果的处理;即查询出了一列结果,发现有重复的,就选择用关键字distinct 排除所有重复值.
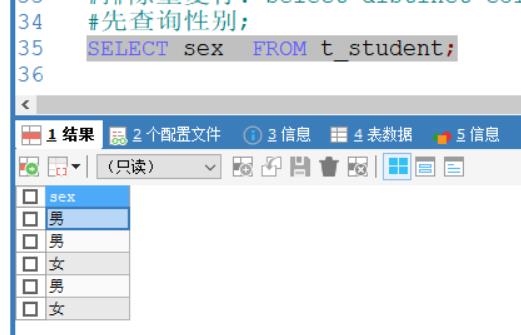
例如:先查询数据表t_student;的性别;
SELECT sex FROM t_student;
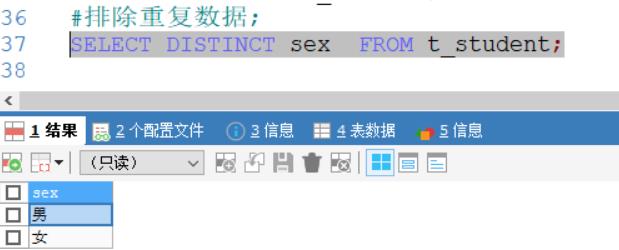
然后排除重复数据
SELECT DISTINCT sex FROM t_student;
算数运算符:+ - * /
使用运算符都是对于数值数据使用的
函数
类似于java中的方法,将一组逻辑语句事先在数据库中定义好
隐藏了实现细节;提高代码的重用性.
调用:select 函数名(实参列表) [from 表];
分类:
单行函数:
对于单行数据进行操作,函数可以嵌套;
单行函数里面有 字符函数,数学函数,日期函数
分组函数:
做统计使用,又称为统计函数、聚合函数、组函数
单行函数
字符函数
length( ):获取参数值的字节个数(
以字节为单位)
char_length( )获取参数值的字符个数(以字符为单位)
空格也算入字符长度
concat(str1,str2,…):拼接字符串
upper( )/lower( ):将字符串变成大写/小写
substring(str操作的字符串,pos开始的位置,length长度);截取字符串; (索引位置从1开始)
instr(str,指定字符):返回指定字符第一次出现的索引(索引从1开始),如果找不到返回0
trim(str):去掉字符串前后的空格或字符,trim(指定字符 from 字符串)
去除1个空格的话,这里的指定字符和from就不写
lpad(str
操作的字符串,length总长度,填充字符):用指定的字符实现左填充将str填充为指定长度;
rpad(str
操作的字符串,length总长度,填充字符):用指定的字符实现右填充将str填充为指定长度
replace(str
操作的字符串,old旧的字符,new新的字符):替换,用指定的字符替换所有的字符.
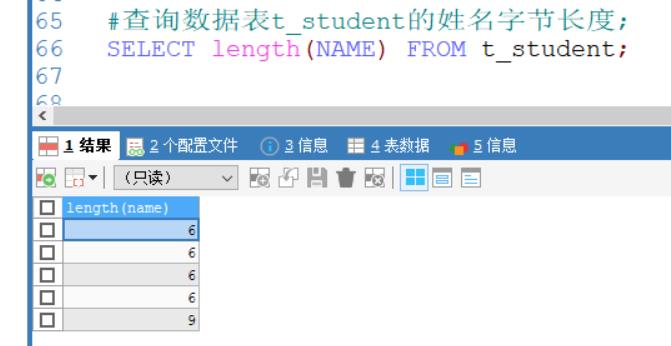
查询数据表t_student的姓名字节长度;
SELECT length(NAME) FROM t_student;
#查询数据表t_student的姓名字符长度;
SELECT char_length(NAME) FROM t_student;
拼接数据表t_student姓名以及生日;
SELECT CONCAT(NAME,birthday) FROM t_student;
由于之前给数据表t_student插入数据时,没有用英文字母;临时插入两个名字JACK以及mark;
将数据表t_student姓名转大写;
SELECT UPPER(NAME) FROM t_student;
数据表t_student姓名转小写;
SELECT LOWER(NAME) FROM t_student;
查询截取数据表t_student手机号前三位;
SELECT SUBSTRING(phone,1,3)FROM t_student;
查询数据表t_student的姓名列中,字符"星"首次出现的索引;如果找不到返回0;
SELECT INSTR(NAME ,'星')FROM t_student;
查询数据表t_student的姓名列去除字符"暗";
SELECT TRIM('暗'FROM NAME) FROM t_student;
查询数据表t_student的姓名列左边填充字符’fortnite’;
SELECT LPAD(NAME,10,'fortnite')FROM t_student;
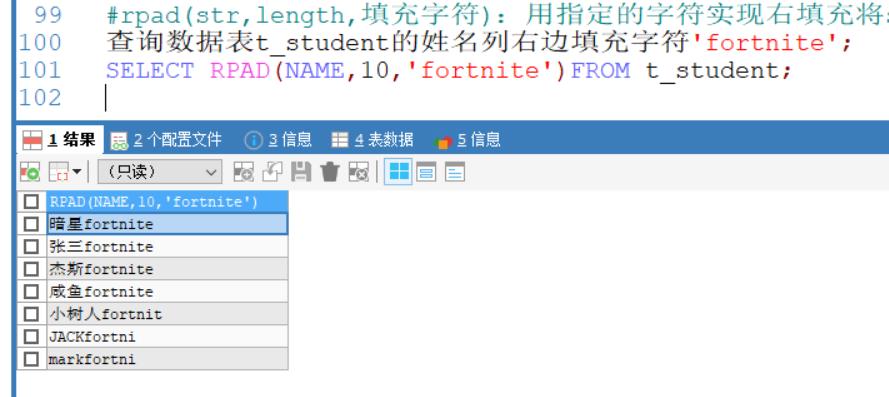
查询数据表t_student的姓名列右边填充字符’fortnite’;
SELECT RPAD(NAME,10,'fortnite')FROM t_student;
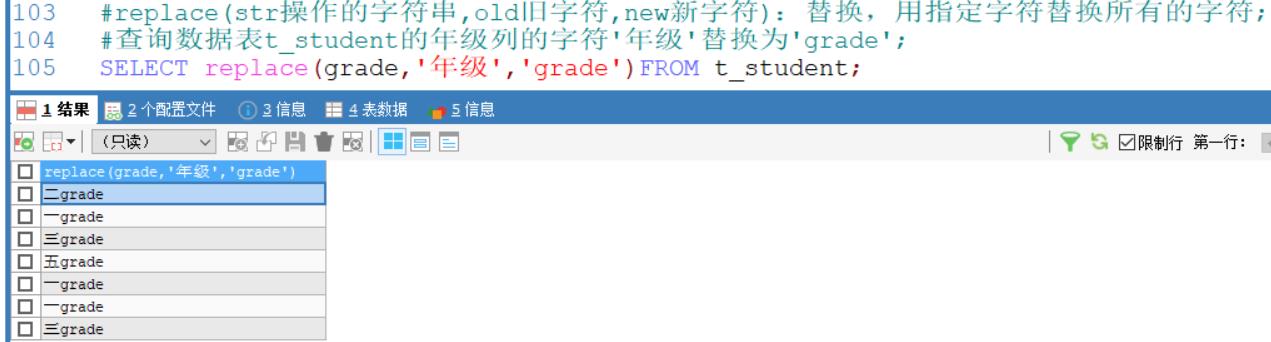
查询数据表t_student的年级列的字符’年级’替换为’grade’;
SELECT replace(grade,'年级','grade')FROM t_student;
逻辑处理
case when 条件语句
case when 条件 then 结果1 else 结果2 end; 可以有多个when
还可以对这个查询的结果的加别名
( case when 条件 then 结果 1 else 结果2 end) ‘别名’
查询对数据表t_student的成绩划分;
SELECT (CASE WHEN score>=60 THEN '好耶' ELSE '不及格' END )'成绩分布' FROM t_student;

加入多个when;(就类似于Java的switch语句)
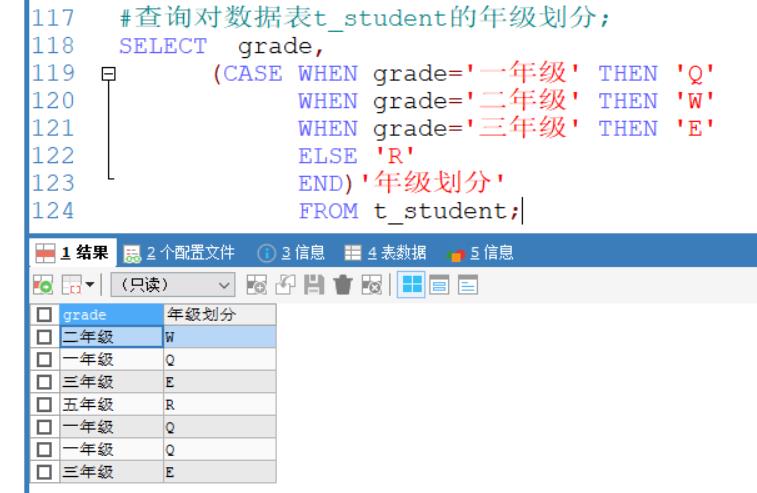
查询对数据表t_student的年级划分;
SELECT grade,
(CASE WHEN grade='一年级' THEN 'Q'
WHEN grade='二年级' THEN 'W'
WHEN grade='三年级' THEN 'E'
ELSE 'R'
END)'年级划分'
FROM t_student;
ifnull(判断是否为空)
ifnull(被检测值,指定的值)函数检测是否为null,如果为null,则返回指定的值,否则返回原本的值.
在逻辑语句结束后也可以加别名;例如 (ifnull(被检测值,默认值)) 别名
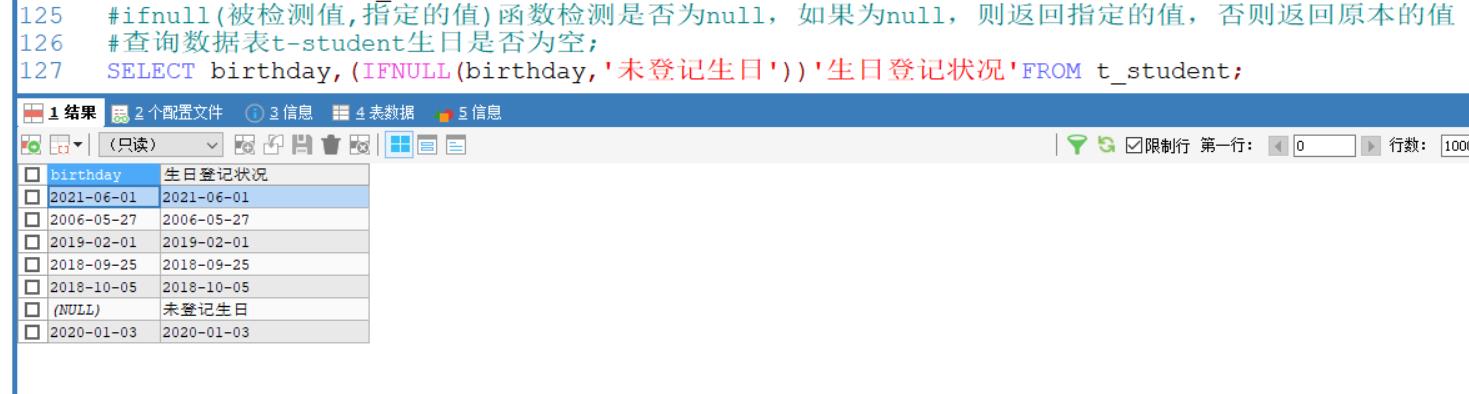
查询数据表t-student生日是否为空;
SELECT birthday,(IFNULL(birthday,'未登记生日'))'生日登记状况'FROM t_student;
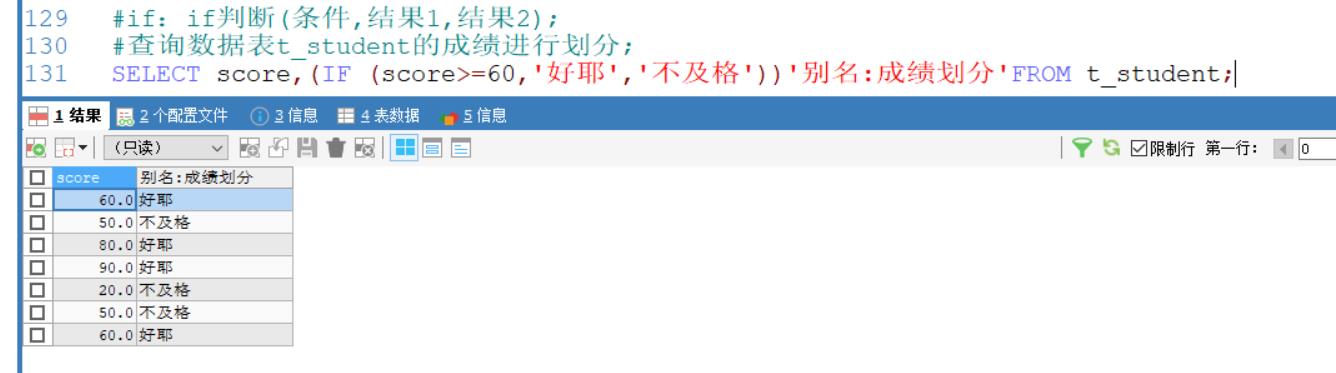
if 判断:
if(条件,结果1
:条件成立执行,结果2:条件不成立执行);
语句结束也可以加别名
查询数据表t_student的成绩进行划分;
SELECT score,(IF (score>=60,'好耶','不及格'))'别名:成绩划分'FROM t_student;
数学函数
数学函数是mysql中常用的函数,主要用于处理数字,包括整形、浮点数等。
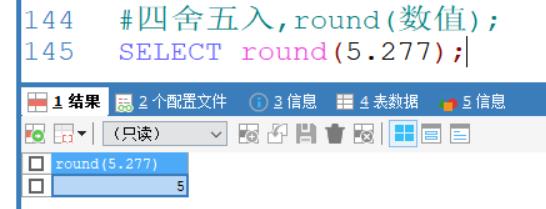
round(数值):四舍五入
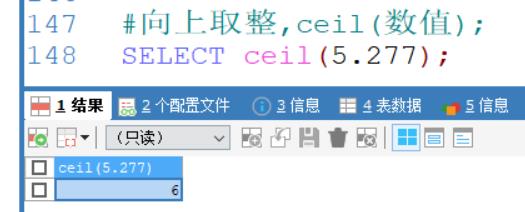
ceil(数值):向上取整,返回()>=该参数的最小整数
floor(数值):向下取整,返回<=该参数的最大整数
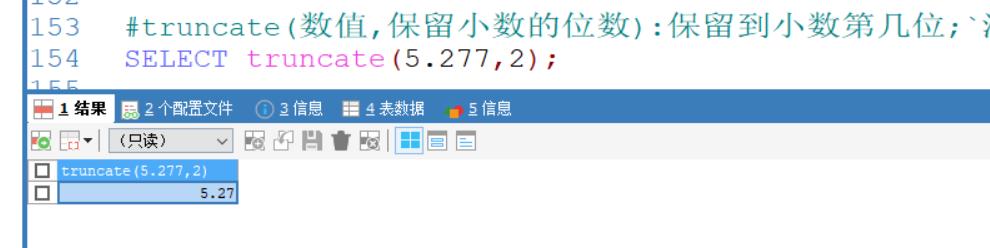
truncate(数值,保留小数的位数):截断,小数点后截断到几位(注意:后面的小数不会进位上去)
mod(被除数,除数):取余数,被除数为正,则为正;被除数为负,则为负
rand():获取随机数,返回0-1之间的随机数(不会为1);
四舍五入,round(数值);
SELECT round(5.277);
向上取整,ceil(数值);
SELECT ceil(5.277);
向下取整,floor(数值);
SELECT floor(5.277);

truncate(数值,保留小数的位数):保留到小数第几位;注意后面的小数不会进位上来;
SELECT truncate(5.277,2);
mod(被除数,除数):取余,被除数为正,则为正;被除数为负,则为负;
SELECT mod(-20,3);

rand():获取随机数,返回0-1之间的随机数(不会取得1);
SELECT rand();
日期函数
日期函数是对于日期的获取,日期的设置以及对日期格式的处理.
now():返回当前系统日期+时间;
curdate():返回当前系统日期,不包含时间;
curtime():返回当前时间,不包含日期;
YEAR(日期),MONTH(日期),DAY(日期) ,HOUR(日期) ,MINUTE(日期) SECOND(日期)
可以获取指定的部分,年、月、日、小时、分钟、秒;
str_to_date(str
需要处理的字符串,format日期格式化的指定格式):将日期格式的字符转换成指定格式的日期;
实际上数据库会进行默认转换
date_format(date
需要处理的日期,format转化的指定格式):将日期转换成指定格式字符串;
datediff(big,small):返回两个日期之间相差的天数;
日期的格式:
| 格式 | 含义 |
|---|---|
| %Y | 年,(4 位 ) |
| %m | 月,数值(00-12) |
| %d | 月的天,数值(00-31) |
| %H | 小时 (00-23) |
| %i | 分钟,数值(00-59) |
| %s | 秒(00-59) |
| %f | 微秒 |
| %T | 时间 24-小时 (hh:mm:ss) |
| %j | 年的天 (001-366) |
| %w | 周的天 (0=星期日, 6=星期六) |
now():返回当前系统日期+时间;
SELECT now();
curdate( ):返回当前系统日期,不包含时间;
SELECT curdate();
curtime():返回当前时间,不包含日期;
SELECT curtime();
YEAR(日期),MONTH(日期),DAY(日期) ,HOUR(日期) ,MINUTE(日期) SECOND(日期)
可以获取指定的部分,年、月、日、小时、分钟、秒;
例如:获取数据表生日列的年份和日期;
SELECT birthday,year(birthday),day(birthday) FROM t_student;
str_to_date(str需要处理的日期,format日期格式化的指定格式):将日期格式的字符转换成指定格式的日期;
SELECT str_to_date('2008-1-1',"%Y-%m-%d");
date_format(date:需要处理的日期,format:转化的指定格式):将日期转换成指定格式字符串;
例如:将数据表t_student的生日列转化为指定格式字符串显示;
SELECT birthday,date_format(birthday,'%Y年%m月%d日')FROM t_student;
datediff(big,small):返回两个日期相差的天数;
例如:计算数据表t_student的生日列距离现在系统日期的相差天数;
SELECT birthday,datediff(now(),birthday)FROM t_student;
分组函数
功能:
用作统计使用,又称为聚合函数或统计函数或组函数(多行数据综合为分类的数据)
分类:
sum 求和、avg 求平均值、max求 最大值、min求 最小值、count 计数(非空)
后面也可以加别名
特点:
1.sum,avg一般用于处理数值型max,min,count可以处理任何类型
2.以上分组函数都忽略null值;自动将null值排除掉
3.可以和distinct搭配实现去重的运算
4.count函数的一般使用count(*)(没有null值的列)用作统计行数;或者用主键统计行数
5.和分组函数一同查询的字段要求是group by后的字段
基本用法
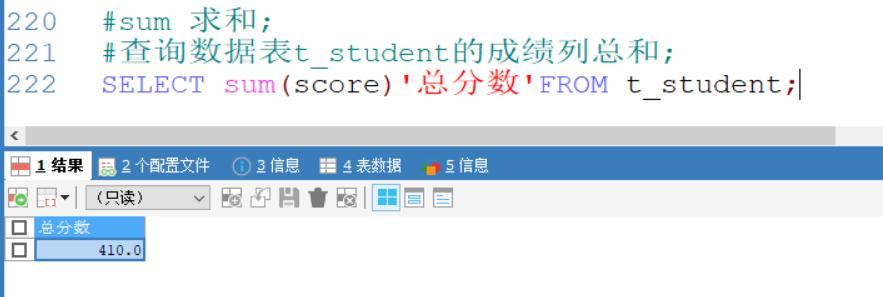
sum 求和
查询数据表t_student的成绩列总和;
SELECT sum(score)'总分数'FROM t_student;
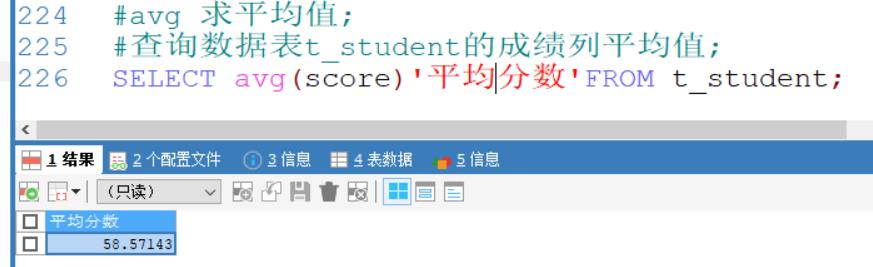
avg 求平均值
查询数据表t_student的成绩列平均值;
SELECT avg(score)'平均分数'FROM t_student;
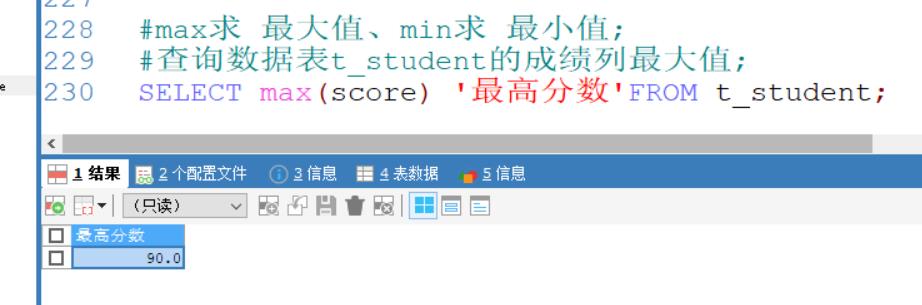
max求 最大值、min求 最小值
查询数据表t_student的成绩列最大值;
SELECT max(score) '最高分数'FROM t_student;
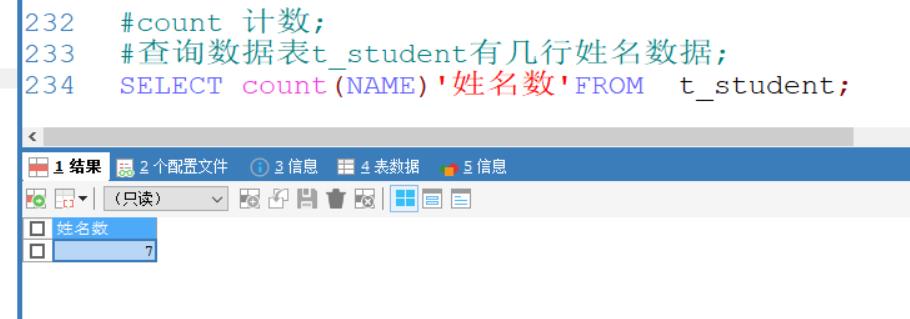
count 计数
查询数据表t_student有几行姓名数据;
SELECT count(NAME)'姓名数'FROM t_student;
可以和distinct搭配实现去重的运算;
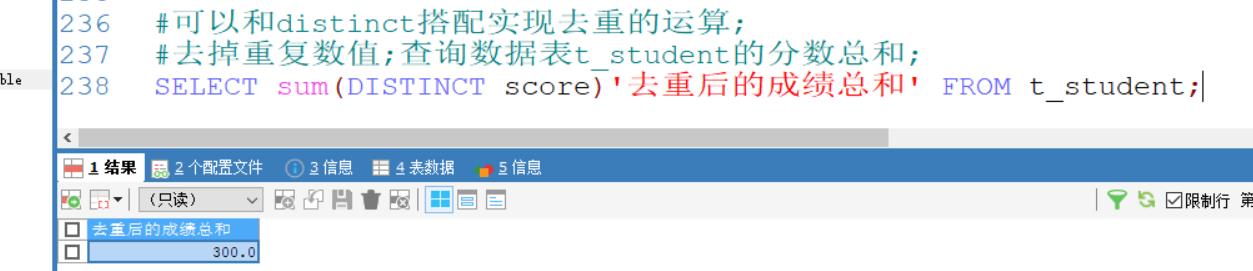
去掉重复数值;查询数据表t_student的分数总和;
SELECT sum(DISTINCT score)'去重后的成绩总和' FROM t_student;
条件查询
使用WHERE 子句,将不满足条件的行数据过滤掉,WHERE 子句紧随 FROM 子句。
语法:select <结果> from <表名> where <条件>
基础查询
条件语句中使用的比较符号;
= (判断是否相等)
!= 或<>(不等于), >(大于) ,<(小于) , >=(大于或等于) , <=(小于或等于)
涉及到逻辑运算时:
and 与(
两个或以上的条件同时成立)
or 或(两个或以上的条件有一个成立)
not 非(不符合所指定条件的)
练习;
#基础条件查询练习;(这里就不指定查询了;用*来获得所有列的数据);
#查询数据表t_student中成绩大于或等于60的;
SELECT * FROM t_student WHERE score>=60;
#查询数据表t_student中成绩大于或等于60的以及小于80的;
SELECT * FROM t_student WHERE score>=60 AND score<80;
#查询数据表t_student中成绩大于或等于60的或者成绩小于30的;
SELECT * FROM t_student WHERE score>=60 OR score<30;
模糊查询
LIKE:
LIKE :匹配于一个模式 一般和通配符搭配使用,可以判断字符型数值或数值型.
通配符:
% (百分号)任意多个字符,包含0个字符
_ (下划线)任意单个字符
一个下划线 _ 表示一个字符
例如:(匹配名字包含某个字符的)LIKE '%字符%';
匹配到第一个指定字符后且长度为3的 ;LIKE '%字符__'(注意两个下划线);
匹配到前面有一个字符且第二个字符为指定的 ;LIKE '_字符%'
例如:对于姓名的匹配;
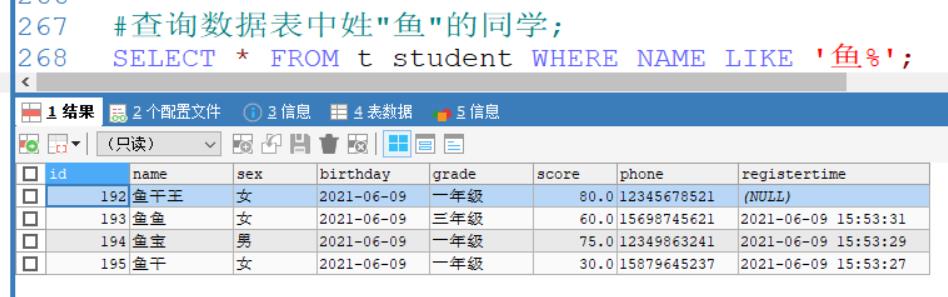
#查询数据表中姓"鱼"的同学;
SELECT * FROM t_student WHERE NAME LIKE '鱼%';
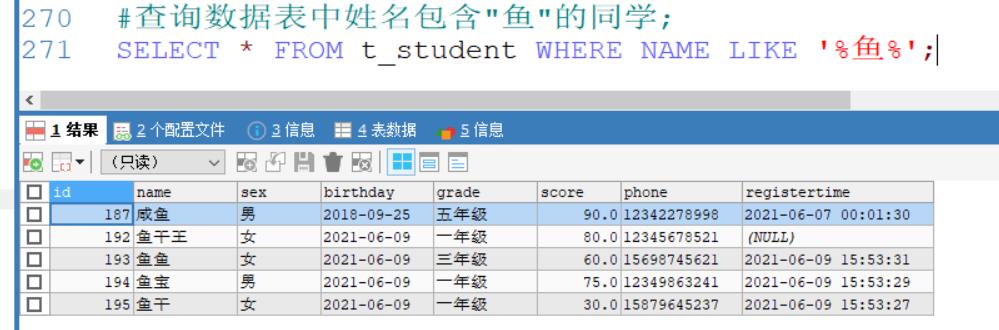
#查询数据表中姓名包含"鱼"的同学;
SELECT * FROM t_student WHERE NAME LIKE '%鱼%';
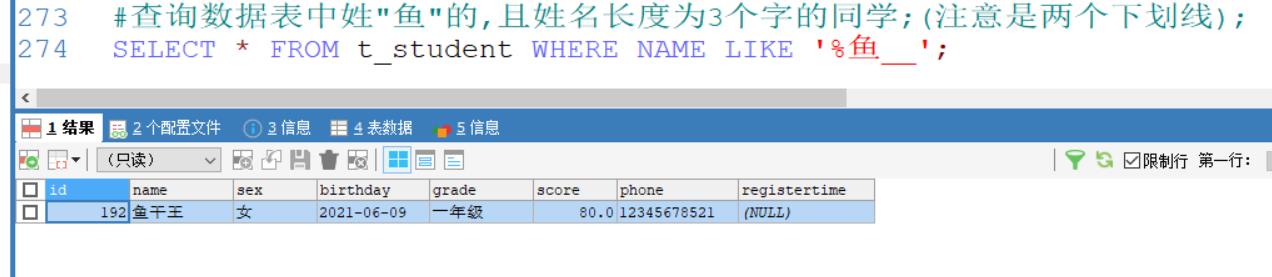
#查询数据表中姓"鱼"的,且姓名长度为3个字的同学;(注意是两个下划线);
SELECT * FROM t_student WHERE NAME LIKE '%鱼__';
between and 两者之间,包含临界值;
即在一个闭区间内.
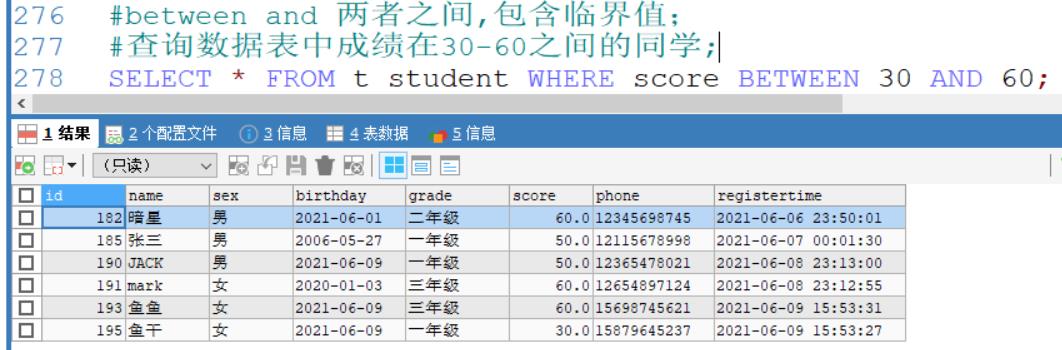
例如:查询数据表中成绩在30-60之间的同学;
SELECT * FROM t_student WHERE score BETWEEN 30 AND 60;
in 判断某字段的值是否属于in列表中的某一项
in ( ) 在列表中的数据;
not in( ) 不在列表中的数据;
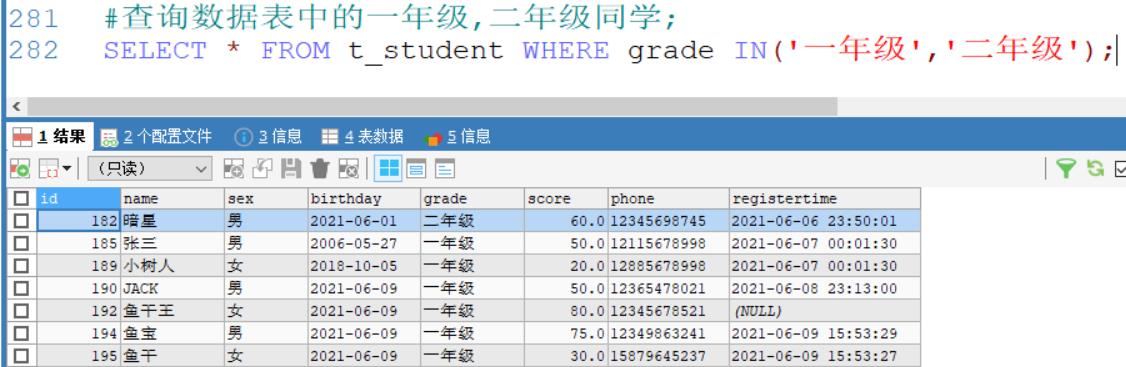
例如:查询数据表中的一年级,二年级同学;
SELECT * FROM t_student WHERE grade IN('一年级','二年级');
IS NULL(为空的)或 IS NOT NULL(不为空的)
例如:
#查询数据表中生日为空值的;
SELECT * FROM t_student WHERE birthday IS NULL;
#查询数据表中生日不为空值的;
SELECT * FROM t_student WHERE birthday IS NOT NULL;
连接查询结果(union ,union all)
将多个SQL查询语句连接合并起来,最后的表统一到一张表;
在合并的时候,SQL语句获得的结果列数要一致,否则会报错;
union 是取唯一值,记录没有重复;并且Union将会按照字段的顺序进行排序;
(UNION会将重复的数据合并)
union all是直接连接,取到得是所有值,记录可能有重复
(UNION ALL只是将两张表合并;重复数据没有合并处理)
1、UNION 的语法:
[SQL 语句 1]
UN以上是关于MySQL基础-- [DML(数据操纵语言),DQL(数据查询语言)]的主要内容,如果未能解决你的问题,请参考以下文章