Apache DolphinScheduler征稿 — Apache DolphinScheduler 快速入门与部署
Posted 盛夏温暖流年
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache DolphinScheduler征稿 — Apache DolphinScheduler 快速入门与部署相关的知识,希望对你有一定的参考价值。
目录
四. Apache DolphinScheduler 单机部署流程
一. Apache DolphinScheduler 背景
2017年,易观在运营自己 6.8Pb 大小、6.02 亿月活、每天近万个调度任务的大数据平台时,受到 ETL (数据仓库技术) 复杂的依赖关系、平台易用性、可维护性及二次开发等方面的问题,技术团队渴望找到一个具有以下功能的数据调度工具:
- 易于使用,开发人员可以通过非常简单的拖拽操作构建ETL过程;
- 不仅对于 ETL 开发人员,无法编写代码的人也可以使用此工具进行 ETL 操作,例如系统管理员和分析师;
- 解决 “复杂任务依赖” 问题,并且可以实时监视 ETL 运行状态;
- 支持多租户;
- 支持许多任务类型:Shell,MR,Spark,Flink,SQL(mysql,postgresql,hive,sparksql,clickhouse等),DataX,Sqoop,Python,Sub_Process,Procedure 等;
- 支持HA和线性可扩展性。
易观技术团队意识到现有开源项目没有能够达到他们要求的,因此决定自行开发这个工具。
他们在2017年底设计了 DolphinScheduler 的主要架构;2018年5月完成第一个内部使用版本,后来又迭代了几个内部版本后,系统逐渐稳定下来。
二. Apache DolphinScheduler 介绍

Apache DolphinScheduler (Incubator,原 Easy Scheduler) 是一个可视化的分布式大数据工作流任务调度系统,DolphinScheduler 致力于“可视化操作工作流(任务)之间的依赖关系,并可视化监控整个数据处理过程”。简称 ”DS” , 中文名 为“小海豚调度”(海豚聪明、人性化,又左右脑可互相换班,终生不用睡觉)。
DolphinScheduler 以有向无环图 (DAG) 的方式将任务组装起来,可实时监控任务的运行状态,同时支持重试、从指定节点恢复失败、暂停及 Kill 任务等操作。
Apache DolphinScheduler 于 17 年在易观数科立项,美国时间 2019 年 8 月 29 号正式通过顶级开源组织 Apache 基金会的投票决议,以全票通过的优秀表现正式成为了 Apache 孵化器项目, 目前已累计有 400+ 公司在生产上使用。
三. Apache DolphinScheduler 特性
高可靠性
去中心化的多 Master 和多 Worker , 自身支持 HA 功能, 采用任务队列来避免过载,不会造成机器卡死;
简单易用
DAG 监控界面,所有流程定义都是可视化,通过拖拽任务完成定制 DAG ,通过 API 方式与第三方系统集成, 一键部署;
丰富的使用场景
支持暂停恢复操作. 支持多租户,更好的应对大数据的使用场景. 支持更多的任务类型,如: Spark, Hive, M/R, Python, Sub_process, Shell;
高扩展性
支持自定义任务类型,调度器使用分布式调度,调度能力随集群线性增长,Master 和 Worker 支持动态上下线;
四. Apache DolphinScheduler 单机部署流程
DolphinScheduler 作为一款开源分布式工作流任务调度系统,可以很好的部署和运行在 Intel 架构服务器环境及主流虚拟化环境下,并支持主流的 Linux 操作系统环境。
1. Linux 操作系统版本要求
| 操作系统 | 版本 |
|---|---|
| Red Hat Enterprise Linux | 7.0 及以上 |
| CentOS | 7.0 及以上 |
| Oracle Enterprise Linux | 7.0 及以上 |
| Ubuntu LTS | 16.04 及以上 |
2. 服务器建议配置
DolphinScheduler 支持运行在 Intel x86-64 架构的 64 位通用硬件服务器平台。对生产环境的服务器硬件配置有以下建议:
| CPU | 内存 | 硬盘类型 | 网络 | 实例数量 |
|---|---|---|---|---|
| 4核+ | 8 GB+ | SAS | 千兆网卡 | 1+ |
如果服务器硬件配置不符合要求,建议升级服务器配置,不然可能因为配置不够而无法启动,不要问我是怎么知道的······
3. 基础软件安装
必装项
- PostgreSQL (8.2.15+) or MySQL (5.7系列) : 两者任选其一, 如 MySQL 则需要 JDBC Driver 5.1.47+;
- JDK (1.8+) : 安装好后在 /etc/profile 下配置 JAVA_HOME 及 PATH 变量;
- ZooKeeper (3.4.6+) ;
ZooKeeper 下载地址:
https://archive.apache.org/dist/zookeeper/
安装步骤可以参考如下链接:
https://segmentfault.com/a/1190000019501252
选装项
- Hadoop (2.6+) or MinIO :如果需要用到资源上传功能,针对单机可以选择本地文件目录作为上传文件夹(此操作不需要部署 Hadoop );当然也可以选择上传到Hadoop or MinIO集群上;
注意:DolphinScheduler 本身不依赖 Hadoop、Hive、Spark,仅是会调用他们的 Client,用于对应任务的运行。
4. 下载二进制 tar.gz 包并安装
下载链接:https://dolphinscheduler.apache.org/zh-cn/download/download.html
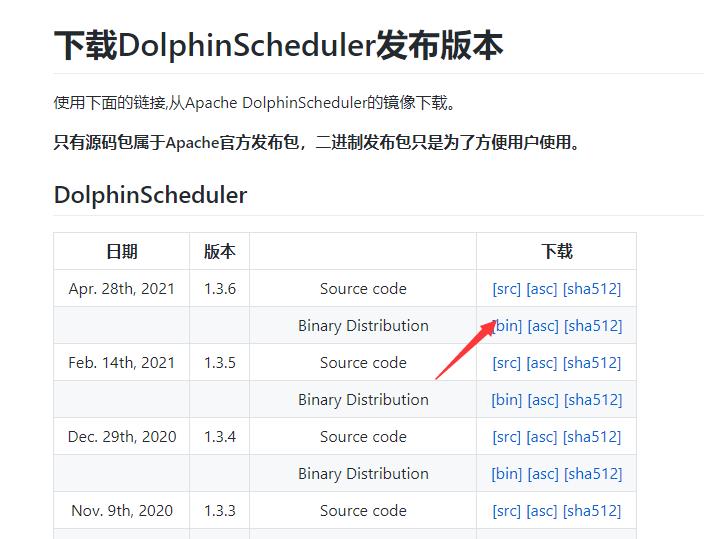
创建部署目录,比如 /opt/dolphinscheduler,将安装包上传至服务器部署目录:
mkdir -p /opt/dolphinscheduler对安装包进行解压:
tar -zxvf apache-dolphinscheduler-1.3.6-bin.tar.gz -C /opt/dolphinscheduler重命名:
mv apache-dolphinscheduler-1.3.6-bin dolphinscheduler-bin5. 创建部署用户并赋予目录操作权限
创建部署用户时,一定要配置 sudo 免密,我们以创建 dolphinscheduler 用户为例。
使用 root 登录后,创建用户:
useradd dolphinscheduler添加密码:
echo "dolphinscheduler" | passwd --stdin dolphinscheduler显示如下结果说明添加密码成功:

配置 sudo 免密:
sed -i '$adolphinscheduler ALL=(ALL) NOPASSWD: NOPASSWD: ALL' /etc/sudoers
sed -i 's/Defaults requirett/#Defaults requirett/g' /etc/sudoers修改目录权限,使得部署用户对 dolphinscheduler-bin 目录有操作权限:
chown -R dolphinscheduler:dolphinscheduler dolphinscheduler-bin之后需要配置 ssh的免密配置。
6. ssh 免密配置
切换到部署用户并配置 ssh 本机免密登录:
su dolphinscheduler
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys注意:正常设置后,dolphinscheduler 用户在执行命令ssh localhost 是不需要再输入密码的;
7. 数据库初始化
进入数据库:
mysql -uroot -p进入数据库命令行窗口后,执行数据库初始化命令,设置访问账号和密码:
CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;给用户授权并刷新(不要忘记替换这里的用户名和密码):
GRANT ALL PRIVILEGES ON dolphinscheduler.* TO '{user}'@'%' IDENTIFIED BY '{password}';
GRANT ALL PRIVILEGES ON dolphinscheduler.* TO '{user}'@'localhost' IDENTIFIED BY '{password}';
flush privileges;创建表和导入基础数据:
(1) 进入当前目录,修改 conf 目录下 datasource.properties 中的下列配置:
cd dolphinscheduler-bin/
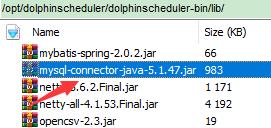
vi conf/datasource.properties(2) 如果选择 MySQL,需要注释掉 PostgreSQL 相关配置, 还需要手动添加 [ mysql-connector-java 驱动 jar ] 包到 lib 目录下,这里下载的是mysql-connector-java-5.1.47.jar:
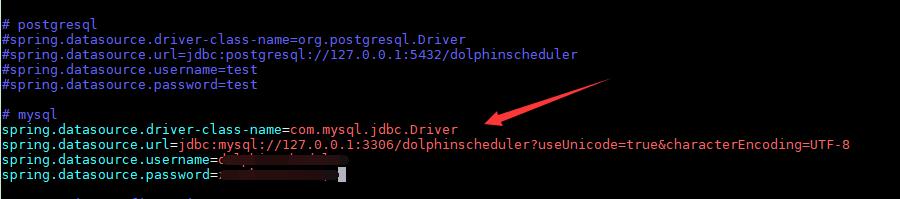
(3) 然后正确配置数据库连接相关信息:
(4) 修改并保存完后,执行 script 目录下的创建表及导入基础数据脚本:
sh script/create-dolphinscheduler.sh 注意: 如果执行上述脚本报 ”/bin/java: No such file or directory“ 错误,请在/etc/profile下配置 JAVA_HOME 及 PATH 变量。
8. 修改运行参数
修改 conf/env 目录下的 dolphinscheduler_env.sh 环境变量(没有用到的可以忽略):
export HADOOP_HOME=/opt/soft/hadoop
export HADOOP_CONF_DIR=/opt/soft/hadoop/etc/hadoop
#export SPARK_HOME1=/opt/soft/spark1
export SPARK_HOME2=/opt/soft/spark2
export PYTHON_HOME=/opt/soft/python
export JAVA_HOME=/opt/soft/java
export HIVE_HOME=/opt/soft/hive
export FLINK_HOME=/opt/soft/flink
export DATAX_HOME=/opt/soft/datax/bin/datax.py
export PATH=$HADOOP_HOME/bin:$SPARK_HOME2/bin:$PYTHON_HOME:$JAVA_HOME/bin:$HIVE_HOME/bin:$FLINK_HOME/bin:$DATAX_HOME:$PATH我们这里这是测试,只保留 JAVA_HOME:
# 可以去环境变量文件里查找 java 路径
export JAVA_HOME=/opt/soft/java
export PATH=$JAVA_HOME/bin:$PATH将jdk软链到 /usr/bin/java 下:
sudo ln -s /opt/soft/java/bin/java /usr/bin/java修改一键部署配置文件 conf/config/install_config.conf中的各参数,特别注意以下参数的配置:
# 这里填 mysql or postgresql
dbtype="mysql"
# 数据库连接地址
dbhost="localhost:3306"
# 数据库名
dbname="dolphinscheduler"
# 数据库用户名,此处需要修改为上面设置的{user}具体值
username="xxx"
# 数据库密码, 如果有特殊字符,请使用\\转义,需要修改为上面设置的{password}具体值
password="xxx"
#Zookeeper地址,单机本机是localhost:2181,记得把2181端口带上
zkQuorum="localhost:2181"
#将DS安装到哪个目录,如: /opt/soft/dolphinscheduler,不同于现在的目录
installPath="/opt/soft/dolphinscheduler"
#使用哪个用户部署,使用第3节创建的用户
deployUser="dolphinscheduler"
# 邮件配置,以qq邮箱为例
# 邮件协议
mailProtocol="SMTP"
# 邮件服务地址
mailServerHost="smtp.qq.com"
# 邮件服务端口
mailServerPort="25"
# mailSender和mailUser配置成一样即可
# 发送者
mailSender="xxx@qq.com"
# 发送用户
mailUser="xxx@qq.com"
# 邮箱密码
mailPassword="xxx"
# TLS协议的邮箱设置为true,否则设置为false
starttlsEnable="true"
# 开启SSL协议的邮箱配置为true,否则为false。注意: starttlsEnable和sslEnable不能同时为true
sslEnable="false"
# 邮件服务地址值,参考上面 mailServerHost
sslTrust="smtp.qq.com"
# 业务用到的比如sql等资源文件上传到哪里,可以设置:HDFS,S3,NONE,单机如果想使用本地文件系统,请配置为HDFS,因为HDFS支持本地文件系统;如果不需要资源上传功能请选择NONE。强调一点:使用本地文件系统不需要部署hadoop
resourceStorageType="HDFS"
# 这里以保存到本地文件系统为例
#注:但是如果你想上传到HDFS的话,NameNode启用了HA,则需要将hadoop的配置文件core-site.xml和hdfs-site.xml放到conf目录下,本例即是放到/opt/dolphinscheduler/conf下面,并配置namenode cluster名称;如果NameNode不是HA,则修改为具体的ip或者主机名即可
defaultFS="file:///data/dolphinscheduler" #hdfs://{具体的ip/主机名}:8020
# 如果没有使用到Yarn,保持以下默认值即可;如果ResourceManager是HA,则配置为ResourceManager节点的主备ip或者hostname,比如"192.168.xx.xx,192.168.xx.xx";如果是单ResourceManager请配置yarnHaIps=""即可
# 注:依赖于yarn执行的任务,为了保证执行结果判断成功,需要确保yarn信息配置正确。
yarnHaIps="192.168.xx.xx,192.168.xx.xx"
# 如果ResourceManager是HA或者没有使用到Yarn保持默认值即可;如果是单ResourceManager,请配置真实的ResourceManager主机名或者ip
singleYarnIp="yarnIp1"
# 资源上传根路径,支持HDFS和S3,由于hdfs支持本地文件系统,需要确保本地文件夹存在且有读写权限
resourceUploadPath="/data/dolphinscheduler"
# 具备权限创建resourceUploadPath的用户
hdfsRootUser="hdfs"
#在哪些机器上部署DS服务,本机选localhost
ips="localhost"
#ssh端口,默认22
sshPort="22"
#master服务部署在哪台机器上
masters="localhost"
#worker服务部署在哪台机器上,并指定此worker属于哪一个worker组,下面示例的default即为组名
workers="localhost:default"
#报警服务部署在哪台机器上
alertServer="localhost"
#后端api服务部署在在哪台机器上
apiServers="localhost"参数一定要配置正确,一一对应着修改。
9. 一键部署
切换到部署用户,执行一键部署脚本:
sh install.sh脚本完成后,会启动以下 5 个服务,使用 jps命令查看服务是否启动 (jps为java JDK自带)
MasterServer ----- master服务
WorkerServer ----- worker服务
LoggerServer ----- logger服务
ApiApplicationServer ----- api服务
AlertServer ----- alert服务
如果以上服务都正常启动,说明自动部署成功。
然而,理想很丰满,现实很骨感,部署一帆风顺基本是不太可能的,在运行 jps 命令后发现,只有两个服务启动了:

查看错误日志,尴尬了,原来是因为服务器空间不够,不过启动了两个服务,起码说明配置过程没有大的问题。

虽然我自己的服务因为客观原因无法启动,但是本着做事有头有尾的原则,剩下的操作流程给大家补全了,可以按照以下步骤走完全程。
10. 登录系统
访问前端页面地址,接口 ip 请自行修改:
http://192.168.xx.xx:12345/dolphinscheduler
这是来自官方访问成功的截图:
11. 启停服务
一键停止集群所有服务
sh ./bin/stop-all.sh一键开启集群所有服务
sh ./bin/start-all.sh启停 Master
sh ./bin/dolphinscheduler-daemon.sh start master-server
sh ./bin/dolphinscheduler-daemon.sh stop master-server
启停 Worker
sh ./bin/dolphinscheduler-daemon.sh start worker-server
sh ./bin/dolphinscheduler-daemon.sh stop worker-server
启停 Api
sh ./bin/dolphinscheduler-daemon.sh start api-server
sh ./bin/dolphinscheduler-daemon.sh stop api-server
启停 Logger
sh ./bin/dolphinscheduler-daemon.sh start logger-server
sh ./bin/dolphinscheduler-daemon.sh stop logger-server
启停 Alert
sh ./bin/dolphinscheduler-daemon.sh start alert-server
sh ./bin/dolphinscheduler-daemon.sh stop alert-server
以上是关于Apache DolphinScheduler征稿 — Apache DolphinScheduler 快速入门与部署的主要内容,如果未能解决你的问题,请参考以下文章