RocketMQ核心原理
Posted gonghaiyu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RocketMQ核心原理相关的知识,希望对你有一定的参考价值。
本文从常见的物理部署结构开始,从启动、MQ接收、MQ消费的角度理解MQ的整个运行过程。本文很多资料来自于RocketMQ官网,感谢大佬们对开源的支持。
RocketMQ Overview
RocketMQ是什么?
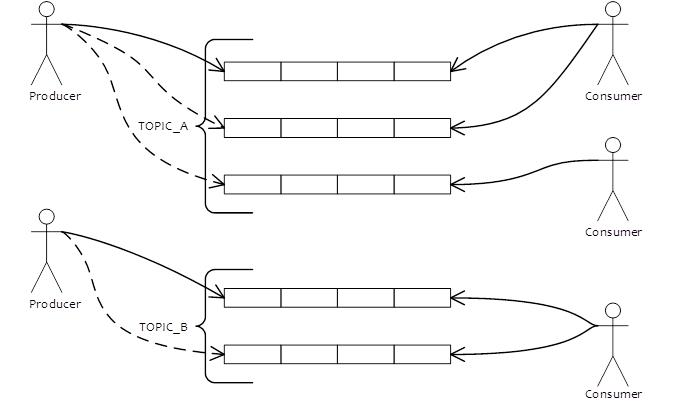
- 是一个队列模型的消息中间件,具有高性能、高可靠、高实时、分布式特点。
- Producer、Consumer、队列都可以分布式。
- Producer 向一些队列轮流发送消息,队列集合称为 Topic,Consumer如果做广播消费,则一个consumer实例消费这个Topic对应的所有队列,如果做集群消费,则多个Consumer实例平均消费这个topic对应的队列集合。
- 能够保证严格的消息顺序
- 提供丰富的消息拉取模式
- 高效的订阅者水平扩展能力
- 实时的消息订阅机制
- 亿级消息堆积能力
- 较少的依赖
从上面的9个特点中说明,用MQ准没错。
RocketMQ物理部署结构
下面先开始部署一套集群玩玩,先说明下该集群的物理结构。
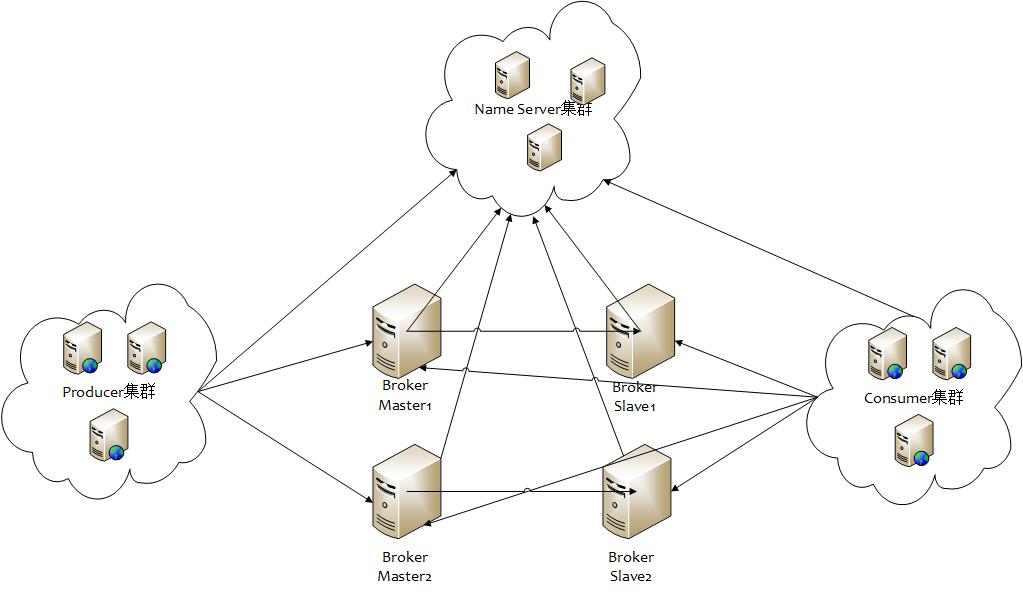
RocketMQ 网络部署特点
Name Server 是一个几乎无状态节点,可集群部署,节点之间无任何信息同步。
Broker 部署相对复杂,Broker 分为 Master 与 Slave,一个 Master 可以对应多个 Slave,但是一个 Slave 只能对应一个 Master,Master 与 Slave 的对应关系通过指定相同的 BrokerName,不同的 BrokerId 来定义,BrokerId为 0 表示 Master,非 0 表示 Slave。Master 也可以部署多个。每个 Broker 与 Name Server 集群中的所有节点建立长连接,定时注册 Topic 信息到所有 Name Server。
Producer 与 Name Server 集群中的其中一个节点(随机选择)建立长连接,定期从 Name Server 取 Topic 路由信息,并向提供 Topic 服务的 Master 建立长连接,且定时向 Master 发送心跳。Producer 完全无状态,可集群部署。
Consumer 与 Name Server 集群中的其中一个节点(随机选择)建立长连接,定期从 Name Server 取 Topic 路由信息,并向提供 Topic 服务的 Master、Slave 建立长连接,且定时向 Master、Slave 发送心跳。Consumer既可以从 Master 订阅消息,也可以从 Slave 订阅消息,订阅规则由 Broker 配置决定。
以上说明了一个Master可对应一个或多个Slave。所有Brocker与NameServer建立长连接,定期向Name Server注册Topic。
运行过程:Producer和Consumer与NameServer建立长连接定期获取Topic。Producer与Master也建立长连接,用来发送心跳。Consumer与Master和Slave都建立长连接并定时发送心跳。Consumer的订阅规则由Broker配置决定。
RocketMQ 逻辑部署结构
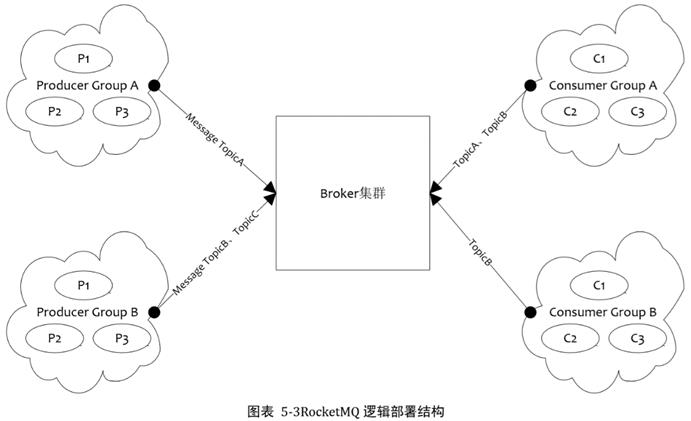
Producer Group
用来表示一个发送消息应用,一个 Producer Group 下包含多个 Producer 实例,可以是多台机器,也可以是一台机器的多个进程,或者一个进程的多个 Producer 对象。一个 Producer Group 可以发送多个 Topic消息,Producer Group 作用如下:
- 标识一类 Producer
- 可以通过运维工具查询这个发送消息应用下有多个 Producer 实例
- 发送分布式事务消息时,如果 Producer 中途意外宕机,Broker 会主动回调 Producer Group 内的任意一台机器来确认事务状态。
Consumer Group
用来表示一个消费消息应用,一个 Consumer Group 下包含多个 Consumer 实例,可以是多台机器,也可以是多个进程,或者是一个进程的多个 Consumer 对象。一个 Consumer Group 下的多个 Consumer 以均摊方式消费消息,如果设置为广播方式,那么这个 Consumer Group 下的每个实例都消费全量数据。
发送消息负载均衡
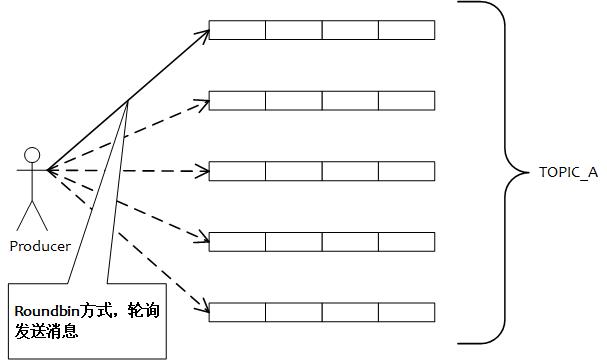
如图所示,5 个队列可以部署在一台机器上,也可以分别部署在 5 台不同的机器上,发送消息通过轮询队列的方式发送,每个队列接收平均的消息量。通过增加机器,可以水平扩展队列容量。
另外也可以自定义方式选择发往哪个队列。
数据存储结构
producer发过来的消息,该怎么存储呢?存储之前,我们有必要说下数据流。
RocketMQ的数据流
下面是单个JVM进程将数据可能存储的地方。通过下面的讲解,可以看到RocketMQ能支持的并发量是很大的。
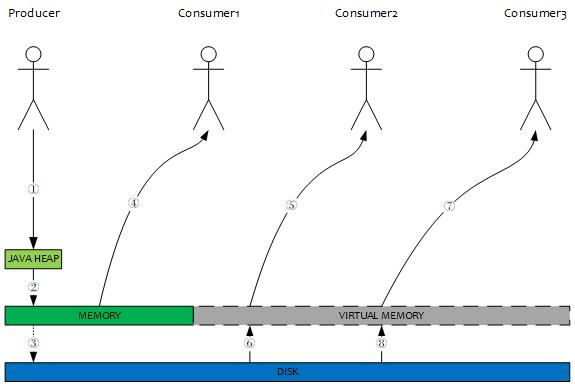
(1). Producer 发送消息,消息从 socket 进入 java 堆。
(2). Producer 发送消息,消息从 java 堆转入 PAGACACHE,物理内存。
(3). Producer 发送消息,由异步线程刷盘,消息从 PAGECACHE 刷入磁盘。
(4). Consumer 拉消息(正常消费),消息直接从 PAGECACHE(数据在物理内存)转入 socket,到达 consumer,不经过 java 堆。这种消费场景最多,线上 96G 物理内存,按照 1K 消息算,可以在物理内存缓存 1 亿条消息。
(5). Consumer 拉消息(异常消费),消息直接从 PAGECACHE(数据在虚拟内存)转入 socket。
(6). Consumer 拉消息(异常消费),由于 Socket 访问了虚拟内存,产生缺页中断,此时会产生磁盘 IO,从磁盘 Load 消息到PAGECACHE,然后直接从 socket 发出去。
(7). 同 5 一致。
(8). 同 6 一致。
RocketMQ在内存或磁盘中的数据结构
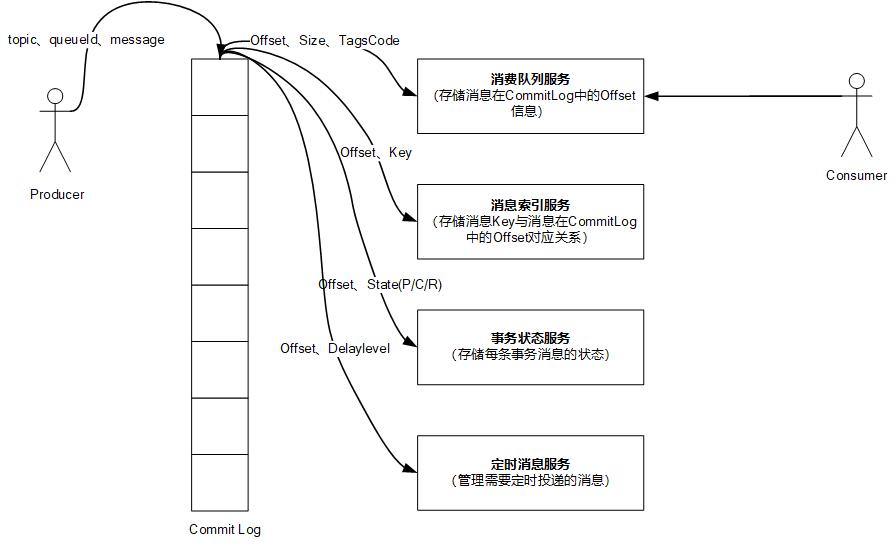
消息队列服务(外部视图)
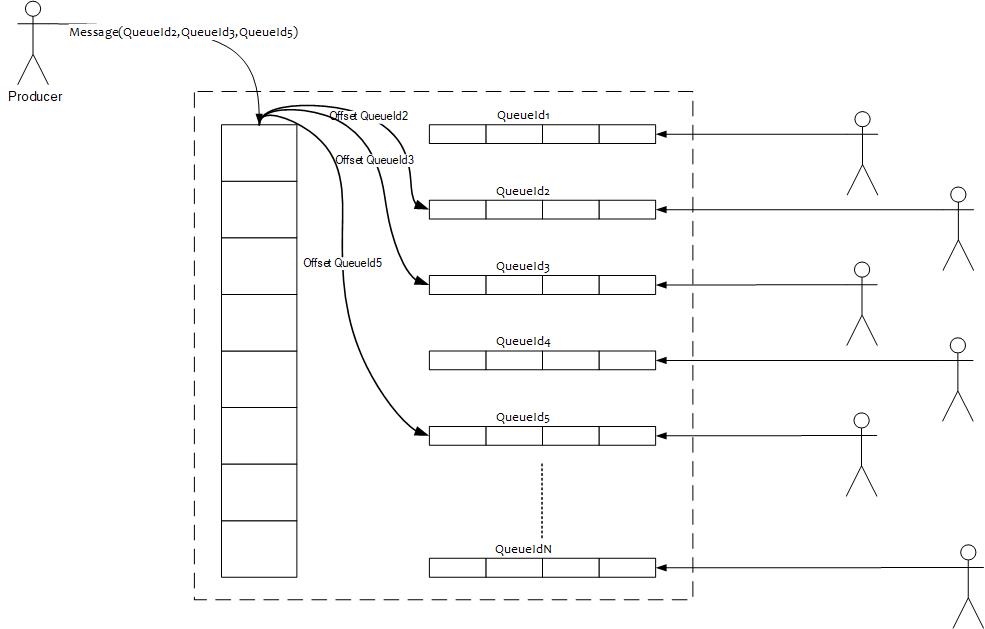
消息队列服务(内部视图)
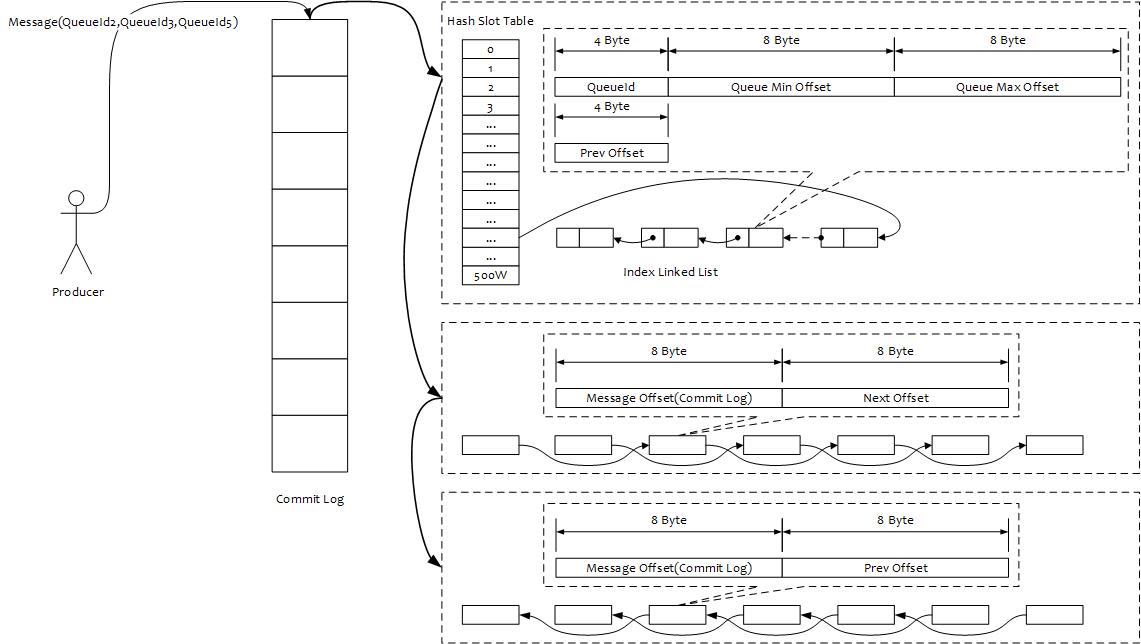
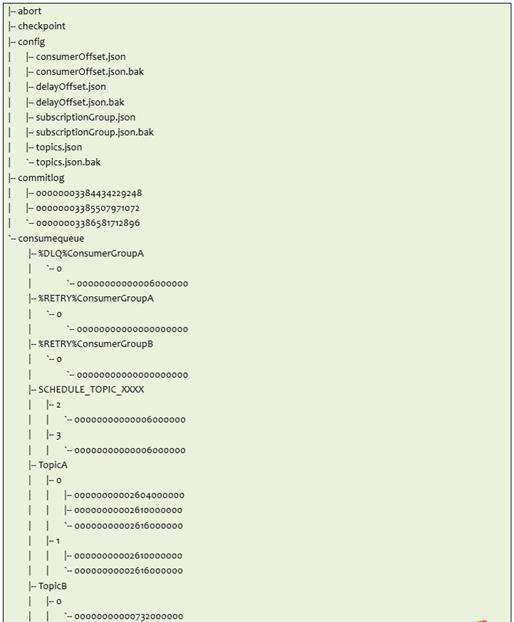
存储目录结构
刷盘策略
RocketMQ 的所有消息都是持久化的,先写入系统 PAGECACHE,然后刷盘,可以保证内存与磁盘都有一份数据,访问时,直接从内存读取。
异步刷盘
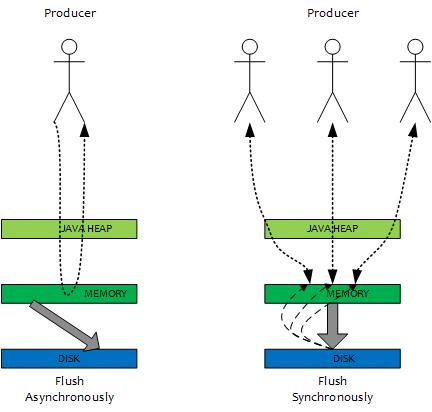
在有 RAID 卡,SAS 15000 转磁盘测试顺序写文件,速度可以达到 300M 每秒左右,而线上的网卡一般都为千兆网卡,写磁盘速度明显快于数据网络入口速度,那么是否可以做到写完内存就向用户返回,由后台线程刷盘呢?
- 由于磁盘速度大于网卡速度,那么刷盘的进度肯定可以跟上消息的写入速度。
- 万一由于此时系统压力过大,可能堆积消息,除了写入 IO,还有读取 IO,万一出现磁盘读取落后情况,会不会导致系统内存溢出,答案是否定的,原因如下:
(1)写入消息到 PAGECACHE 时,如果内存不足,则尝试丢弃干净的 PAGE,腾出内存供新消息使用,策略是 LRU 方式。
(2)如果干净页不足,此时写入 PAGECACHE 会被阻塞,系统尝试刷盘部分数据,大约每次尝试 32 个 PAGE,来找出更多干净 PAGE。
综上,内存溢出的情况不会出现。
同步刷盘
同步刷盘与异步刷盘的唯一区别是异步刷盘写完 PAGECACHE 直接返回,而同步刷盘需要等待刷盘完成才返回,
同步刷盘流程如下:
(1). 写入 PAGECACHE 后,线程等待,通知刷盘线程刷盘。
(2). 刷盘线程刷盘后,唤醒前端等待线程,可能是一批线程。
(3). 前端等待线程向用户返回成功。
消息可靠性
RocketMQ从3.0版本开始支持同步双写,来解决不同情况下的消息丢失问题。
以上是关于RocketMQ核心原理的主要内容,如果未能解决你的问题,请参考以下文章