Linux操作系统——文件I/O - 知其然,知其所以然
Posted 一口Linux
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux操作系统——文件I/O - 知其然,知其所以然相关的知识,希望对你有一定的参考价值。
在操作系统中, 最为复杂同时也最为重要的功能就是文件I/O。 一台PC可以不连接互联网, 但是一定需要程序的载入、文件的打开, 而这些操作与I/O均密不可分。 包括软件开发中, 数据库与I/O的关系密切相关, 有时衡量一个DB的效率, 其实就是在衡量其I/O效率。 理解文件I/O, 就是在理解我们常用应用软件, 如mysql、Redis、nginx、ES、Prometheus等的核心。
1. 处于内核态的系统调用
操作系统的本质就是帮助用户更加高效的管理硬件, 向上提供统一的接口, 向下兼容不同的硬件, 使得用户并不需要关心硬件, 如硬盘的细节, 只需要关心操作系统为我们提供的抽象: 文件系统。 然而引入操作系统的代价就是用户对硬件的所有操作, 例如打开一个文件, 运行一个程序, 均需经由操作系统来完成, 如此以来, 就有了系统调用。
系统调用存在的原因就在于操作系统不允许用户直接访问硬件, 如果用户有此需求, 则需将想要访问的地址与内容告诉操作系统, 由操作系统进行硬件的访问, 最后由操作系统将结果返回给用户。
操作系统也是软件, 也是由一行行的代码所组成, 所以必定运行在内存中, 只不过操作系统所运行的内存受到保护, 用户无法直接对其进行操作而已。 当用户想要打开一个文件时, 将文件路径告知操作系统, 此时操作系统将会接管CPU的执行, 并将CPU的某标识位标记为内核态, 执行一系列的I/O操作, 取出结果并将结果发送给用户内存空间后, 再将CPU的执行权交给用户。 从本质上来看, 系统调用其实就是一次进程切换, 只不过所花费的时间要比普通的进程间切换大得多而已。
接下来将会看到, 为了”对抗”系统调用所带来的巨大代价, 先贤们实现了各种各样增加I/O效率的方式。 但是, 没有哪一种方式能够”一招吃遍天下鲜”, 不同的应用场景会有不同的最佳解决方式。
2. Linux通用I/O模型
Linux为系统用户提供了一些通用的IO函数, 包括open、read、write等方法, 当用户每次调用这些方法时, 都将产生一次系统调用, 此时程序运行由用户态切换至内核态, 内核做完自己应该完成的事情之后, 将结果保存至用户指定的位置中, 并再由内核态切换至用户态, 使用户继续执行下面的代码。
open方法既能打开一个已经存在的文件, 也能创建并打开一个新的文件。 其原型如下:
int open(const char *pathname, int flags, .../* mode_t mode */)具体的方法使用请参见Linux manual page。open方法在成功时将返回该文件的文件描述符, 用于在后续函数调用中指代该文件, 该文件描述符在进程中唯一, 即使打开的是同一个文件, 两者的文件描述符也不相同。
int main() {
int fd = open("hole.txt", O_WDONLY); // 3
int fd2 = open("hole.txt", O_WDONLY); // 4
return 0;
}对于用户自定义的文件, 文件描述符通常都是从3开始, 0、1、2这三个描述符分别代表标准输入、标准输出以及标准错误, 定义于unistd.h头文件中。
/* Standard file descriptors. */
#define STDIN_FILENO 0 /* Standard input. */
#define STDOUT_FILENO 1 /* Standard output. */
#define STDERR_FILENO 2 /* Standard error output. */read系统调用此报告文件描述符fd所指代的打开文件中读取数据, 其定义为:
#include<unistd.h>
ssize_t read(int fd, void *buffer, size_t count);count参数指定最多能读取的字节数, buffer参数提供用来存放数据的内存缓冲区地址(由用户所提供), 缓冲区至少应有count字节。
#define MAX_READ 20
char buffer[MAX_READ + 1]
ssize_t num_read;
num_read = read(STDIN_FILENO, buffer, MAX_READ);
if (num_read == -1)
return -1;
buffer[num_read] = '\\0';
printf("The input data was: %s\\n", buffer);从标准输入中读取数据和从文件中读取数据会有些许差异, 因为在默认情况下, 从终端读取字符会在遇到换行符(\\n)时read调用就会结束, 而对于普通文件, 则不会这样。
现在来进一步地了解read系统调用背后所发生的事情。 当程序调用read方法时, 产生系统调用, 则当前程序执行的状态由用户态切换至内核态, 操作系统将所需要的文件内容读取至内核某缓冲区中。 同时, 由于I/O是一个相对来说代价较大的操作, 为了减少读取磁盘的数据, 操作系统还会额外的读取更多的内容进入内核缓冲区, 下次读取这些内容时, 直接从缓冲区中读取, 不再从磁盘中读取, 从而提升整体效率。 数据进入内核缓冲区后, 内核需要将数据复制到用户缓冲区中, 也就是read方法所传递的void *buffer中。 传输完毕后由内核态切换至用户态, read系统调用完成。
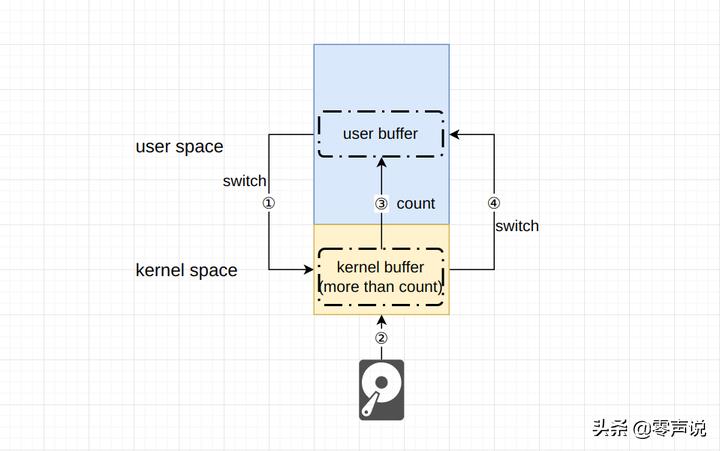
在执行read系统调用时, 总计发生了2次用户态切换, 额外的一次数据复制(kernel to User)。 并且, kernel buffer中保存了多于用户当前所需的数据, 用于加快下一次的read调用。
write系统调用将数据写入一个打开的文件中, 当调用成功时, 返回实际写入文件的字节数。 与read系统调用相同, write调用在返回成功时, 仅是将数据写入到内核缓冲区中, 再由内核寻找适当的时机将该部分数据真正地写入到磁盘中。
采用这一设计可以有效的减少内核必须执行的磁盘传输次数, 因为可能调用10次write系统调用, 内核仅进行一次磁盘写入, 不仅减少了单个write系统调用所需时间, 并且提高了操作系统整体的运作效率。
这一机制所带来的唯一问题就是由于数据在某一时刻仅暂存于内核缓冲区中, 当系统发生断电或者是意外宕机时, 该部分数据就会丢失。 对于数据库等对数据要求非常严格的系统, 这种数据丢失是无法接受的。 所以, 内核额外的提供了fsync等强制刷新数据至磁盘的系统调用。
fsync系统调用将使缓冲区数据和与打开文件描述符fd相关的所有元数据都刷新到磁盘上, 调用fsync会强制使文件处于Synchronized I/O file integrity completion状态。 所以, 当程序想要确保数据完全写入磁盘时, 可在write调用后执行fsync调用, 进行强制刷盘。
3. C标准I/O函数库
上面所提到的open, read等系统调用均有Linux/Unix系统所提供, 如Windows等操作系统并不支持此类调用。 为了解决不同操作系统底层提供的通用I/O函数不同的问题, ANSI C制定了一系列的标准I/O函数, 其目的就是为了解决代码的可移植性问题以及屏蔽I/O细节(缓冲区大小的选择, 文件锁实现等)。
标准I/O函数库中最常用的方法为fopen, fgets, fputs以及printf, fprintf。 fopen和open的作用类似, 以某种模式(只读、只写等)打开一个文件, 唯一不同的是open返回int类型的文件描述符, 而fopen返回FILE类型的指针。
为了更好的理解FILE文件对象, 首先需要了解C标准I/O库的过程。 C标准I/O库的底层实现, 同样是基于Linux提供的通用I/O函数, 只不过标准库对其进行了封装而已。
C标准库除了帮助用户处理平台可移植性问题以外, 还会帮助用户减少系统调用的次数, 但是会额外的增加数据在内存间的复制次数。
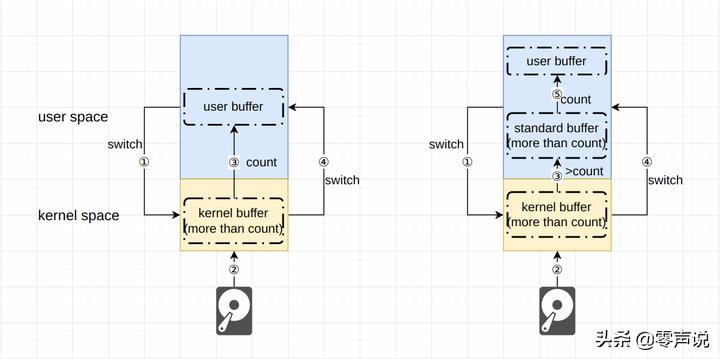
如上图所示,与Linux通用I/O相比, C标准I/O库自身也维护一个类似于内核缓冲的缓冲池, 内核缓冲区的数据并不会直接被复制到用户缓冲区中, 而是复制到标准库缓冲区中。 并且, 所复制的字节数也远大于用户所需要的字节数(count), 当下次进行内容读取时, 直接从标准缓冲区中读取, 而不需要进行系统调用从内核缓冲区中读取。
该方式从整体上减少了系统调用的次数, 额外的增加了一次用户空间的数据复制, 由于标准I/O函数对系统调用进行了二次封装, 所以解决了可移植性问题。
fputc以及fputs分别向所关联的文件流中写入单个字符或者是一串字符。 由于标准IO缓冲区的存在, 调用该方法时仅是将数据写入到C标准IO缓冲区中, 而后C标准库根据相应的条件决定何时执行write系统调用, 将数据写入内核缓冲区。 此后, 内核将决定在适当的时机将数据真正地写入磁盘。
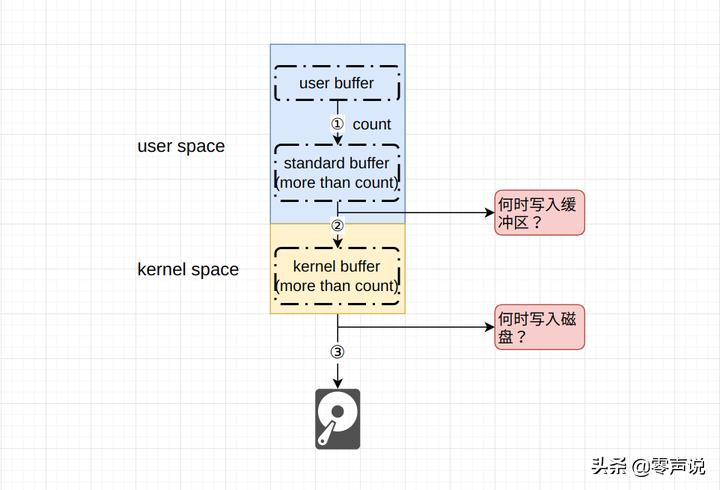
3.1 C标准I/O缓冲
标准IO库提供了3种类型的缓冲: 全缓冲、行缓冲以及不带缓冲。
在全缓冲类型下, C函数库只有在完全填满标准IO缓冲区后才进行实际的IO操作, 磁盘文件通常是全缓冲的。 也就是说, 当程序使用fopen打开一个磁盘文件并调用fputs进行数据写入时, 数据可能仅写入了标准IO缓冲区中。 在随后的fputs调用中, 若C标准IO函数发现缓冲区已满, 则进行一次系统调用, 将数据写入至内核缓冲区中。
在行缓冲区类型下, 在输入和输出中遇到换行符(\\n)时, 标准IO库执行实际的IO操作。 当一个流涉及到终端时(如标准输出), 通常时行缓冲的, 例如printf函数。
不带缓冲则表示只要向标准缓冲区中写入数据, 标准库就会立即进行系统调用, 将数据写入内核缓冲。 标准错误通常是不带缓冲的, 原因在于期望能够尽快的看到错误的产生。
#include<stdio.h>
#include<unistd.h>
#include<fcntl.h>
int main(int *args, char **argv) {
printf("This is printf out | ");
fprintf(stderr, "This is a error output | ");
printf("BiuBiu\\n");
printf("Hello Aean: ");
char *s = "I would have written you a short letter. | ";
write(STDOUT_FILENO, s, 43);
return 0;
}编译并运行上述代码, 将会得到:
This is a error output | This is printf out | BiuBiu
I would have written you a short letter. | Hello Aean:当标准IO函数与系统调用混合使用时, 将会看到与代码期望完全不同的结果。 尽管printf函数在fprintf之前执行, 但由于printf为行缓冲, 而标准错误为不带缓冲, 所以标准错误信息将在标准输出信息打印之前打印。 write函数为系统调用, 输出的时机要优先于不带换行符的标准输出。
标准IO函数库同时也提供了fflush函数, 用于将标准缓冲区的数据强制刷新至内核, 如果我们在printf函数调用后调用fflush, 则会在标准错误输出之前看到输出。
int main(int *args, char **argv) {
printf("This is printf out | ");
fflush(stdout);
fprintf(stderr, "This is a error output | ");
}其结果为:
This is printf out | This is a error output使用过Docker部署Python项目的小伙伴儿可能对环境变量PYTHONUNBUFFERED感到很熟悉, 官方文档解释如下:
Force stdin, stdout and stderr to be totally unbuffered. On systems where it matters, also put stdin, stdout and stderr in binary mode.
简单来说, 在Docker中使用该变量, 能够更快的使日志输出, 并且在容器crash的情况下, 也能看到必要的日志信息。
更详细的解释:
Setting PYTHONUNBUFFERED=TRUE or PYTHONUNBUFFERED=1 (they are equivalent) allows for log messages to be immediately dumped to the stream instead of being buffered. This is useful for receiving timely log messages and avoiding situations where the application crashes without emitting a relevant message due to the message being “stuck” in a buffer. As for performance, there can be some (minor) loss that comes with using unbuffered I/O. To mitigate this, I would recommend limiting the number of log messages. If it is a significant concern, one can always leave buffered I/O on and manually flush the buffer when necessary.
有关Linux通用IO以及C标准IO库的缓冲区, 可用下图清晰总结。
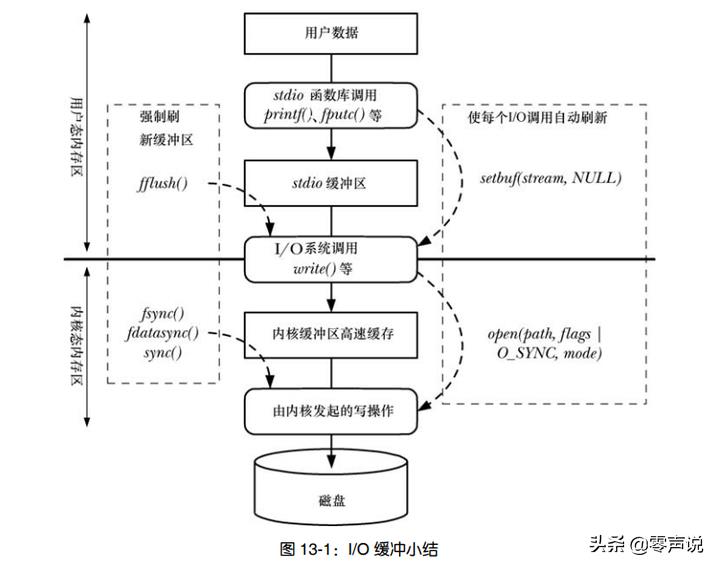
原图来源于Linux/Unix系统编程手册, P200。
4. 内存映射I/O
现代操作系统大多数均采用分段+分页的方式来管理内存空间, 其目的就在于使得每一个进程的地址空间独立, 并且使系统能够运行超过其内存空间总数的各种进程。
分页内存管理的基本思想就是映射, 思想和哈希表基本类似: 将一个大范围的空间映射至一个小范围空间内。
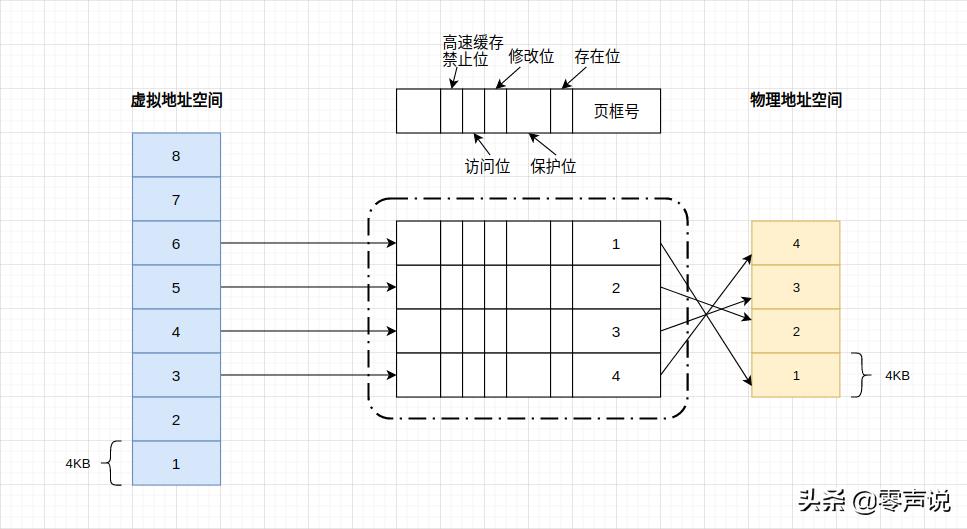
当程序想要访问的虚拟地址没有在页表项建立映射时, 系统将发起一个”缺页异常”, 由操作系统建立页表项并建立虚拟地址页与物理地址页的映射关系。 如此一来, 能够使得不常用的数据或者是内存片段被细粒度地换置至磁盘中, 内存中保留常用的数据。
mmap方法的原理与虚拟内存映射基本相同, 将进程的一部分地址空间与磁盘文件建立映射关系, 将文件当做是内存中的一个数组使用, 减少read, write以及lseek的调用。
需要注意的是, 内存映射一个文件并不会导致整个文件被读取到内存中, 就如同虚拟内存空间不会都在物理地址空间一样, 而是仅仅为需要的文件数据保留映射关系。
import os
import mmap
def memory_map(filename, access=mmap.ACCESS_WRITE):
size = os.path.getsize(filename)
fd = os.open(filename, os.O_RDWR)
return mmap.mmap(fd, size, access=access)
if __name__ == "__main__":
with memory_map('hello.txt') as m:
print(m[0:15])此外,使用内存映射I/O的读写并不一定会比C标准I/O库或者是Linux通用I/O更加高效, 其原因在于虽然mmap减少了用户态的切换以及减少了数据的复制, 但是增加了处理缺页错误、建立页表项的时间, 并且各个平台对于mmap的实现也各有不同, 其优点就在于更加简洁的随机读取以及数据写入。
5. 异步I/O
异步I/O的实现通常会有两种: 当文件可读/可写时, 内核向进程发送一个信号, 或者是内核调用进程提供的回调函数。 在Linux下, AIO有2种实现: 基于线程模拟异步I/O的glibc AIO, 以及由内核实现的Kernel AIO。
对于glibc AIO而言, 是在用户空间使用多线程来模拟实现的, 并不能真正的称之为异步I/O, 但是能够在任意的文件系统、任意的操作系统上运行。
而Kernel AIO采用信号通知的方式实现异步I/O, 只能在Linux操作系统上运行, 基本没有可移植性。 此外, 一个最重要的问题就是Kernel AIO要求用户必须使用O_DIRECT模式打开文件, 即绕过内核高速缓冲区, 直接将数据传递至文件或者是磁盘设备, 这种方式又称为直接I/O(direct I/O)。
对于大多数应用而言, 使用直接I/O可能会大大的降低性能, 并且会有诸多不便之处。 其原因在于内核针对缓冲区高速缓存做了不少优化, 包括按顺序读取, 在成簇磁盘块上执行I/O, 允许访问同一文件的多个进程共享内核缓冲区。 并且, 直接I/O由于直接将数据传输至磁盘, 所以必须遵守磁盘的一些限制, 包括但不限于: 用于传递数据的缓冲区其内存边界必须对齐为块大小的整数倍, 待传输的数据长度必须是块大小的整数倍…
正是因为诸多限制, 不管是glibc AIO, 还是Kernel AIO, 在绝大部分的应用中都未曾使用, 看起来AIO就是专门为数据库应用所提供的实现。
6. Zero Copy(sendfile)
sendfile系统调用用于在两个文件描述符之间传输数据, 在Linux Kernel 2.6.33以前, sendfile只能将数据从一个具体的文件发送到一个socket中。 而在此版本之后, sendfile的接收方可以是任意的文件, 但是输入端只能是存在于虚拟内存空间的文件描述符, socket则不在此列。
方法原型为:
#include <sys/sendfile.h>
ssize_t sendfile (int __out_fd, int __in_fd, off_t *__offset, size_t __count);一个简单的文件复制示例:
#include<fcntl.h>
#include<unistd.h>
#include <sys/stat.h>
#include <sys/sendfile.h>
int get_file_size(char* filename)
{
struct stat statbuf;
stat(filename, &statbuf);
int size = statbuf.st_size;
return size;
}
int main() {
// 省去错误判断
int foo = open("foo.txt", O_RDONLY);
int bar = open("bar.txt", O_WRONLY);
int foo_size = get_file_size("foo.txt");
sendfile(bar, foo, 0, foo_size);
return 0;
}另外需要注意的是, sendfile在文件之间传输数据时, 并不支持O_APPEND flags, 只能覆盖写入。
sendfile系统调用完全在内核空间进行, 数据不会从内核空间拷贝至用户空间, 并且能够得到DMA的硬件支持, 因而速度很快。
7. 总结
对于非数据库类型的应用而言, 文件I/O的可选范围并不广, 即与其花费大量时间调试异步I/O, 不如直接选择C标准库I/O, 因为同时监听成百上千的文件读写并不常见。 对于频繁随机读取和写入的文件而言, 可以使用内存映射I/O来减少lseek的调用, 而sendfile系统调用更多地应用于文件至socket的数据传输。
以上是关于Linux操作系统——文件I/O - 知其然,知其所以然的主要内容,如果未能解决你的问题,请参考以下文章